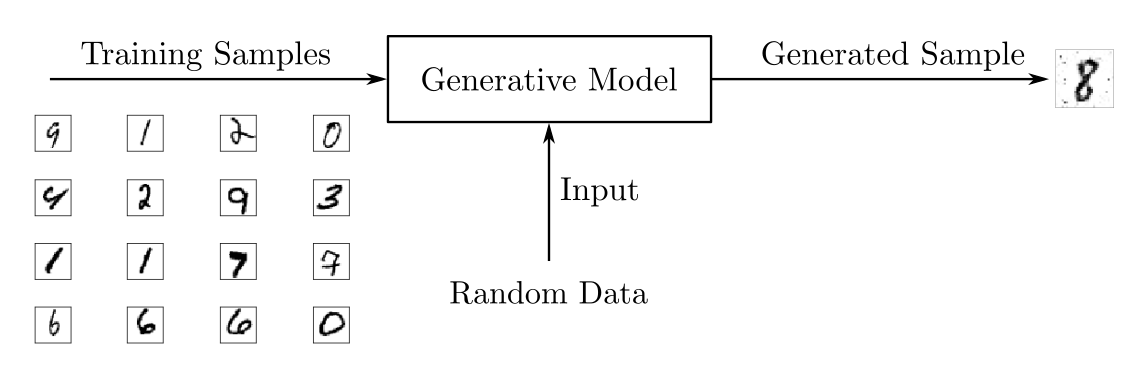
生成对抗网络 (GAN)是神经网络 生成类似于人类生成的材料,例如图像、音乐、语音或文本。
近年来,GAN 一直是一个活跃的研究主题。 Facebook 人工智能研究总监 Yann LeCun 称对抗性训练“过去10年来最有趣的想法” 在机器学习领域。下面,您将在实现自己的两个生成模型之前了解 GAN 的工作原理。
在本教程中,您将学习:
真是个生成模型 是以及它与 a 有何不同判别模型
GAN 是怎样的结构化的 和训练有素的
如何构建你自己的 GAN 使用火炬
如何训练你的 GAN 使用 GPU 和 PyTorch 的实际应用
让我们开始吧!
免费奖金: 关于掌握 Python 的 5 个想法 ,为 Python 开发人员提供的免费课程,向您展示将 Python 技能提升到新水平所需的路线图和思维方式。
什么是生成对抗网络?
生成对抗网络 是可以学习模仿给定数据分布的机器学习系统。它们最初是在 2014 年提出的NeurIPS 论文 由深度学习专家 Ian Goodfellow 和他的同事提出。
GAN 由两个神经网络组成,一个被训练来生成数据,另一个被训练来区分假数据和真实数据(因此模型具有“对抗性”性质)。尽管生成数据的结构的想法并不新鲜,但在图像和视频生成方面,GAN 已经提供了令人印象深刻的结果,例如:
风格迁移使用循环GAN ,它可以对图像执行许多令人信服的风格转换
人脸的生成风格GAN ,如网站上所示此人不存在
考虑生成数据的结构,包括 GAN生成模型 与更广泛研究相比判别模型 。在深入研究 GAN 之前,您将了解这两种模型之间的差异。
判别模型与生成模型
如果您研究过神经网络,那么您遇到的大多数应用程序可能都是使用判别模型 。另一方面,生成对抗网络是不同类别模型的一部分,称为生成模型 .
判别模型是大多数情况下使用的模型监督的 分类 或者回归 问题。作为分类问题的示例,假设您想要训练一个模型来对 0 到 9 的手写数字图像进行分类。为此,您可以使用包含手写数字图像及其相关标签(指示每个数字对应哪个数字)的带标签数据集。图像代表。
在训练过程中,您将使用算法来调整模型的参数。目标是尽量减少损失函数 以便模型学习概率分布 给定输入的输出。训练阶段结束后,您可以使用该模型通过估计输入对应的最可能的数字来对新的手写数字图像进行分类,如下图所示:
您可以将分类问题的判别模型描绘为使用训练数据来学习类之间边界的块。然后,他们使用这些边界来区分输入并预测其类别。用数学术语来说,判别模型学习条件概率P (y |x )的输出y 给定输入x .
除了神经网络之外,其他结构也可以用作判别模型,例如逻辑回归 型号和支持向量机 (SVM)。
然而,像 GAN 这样的生成模型经过训练来描述数据集是如何生成的概率性的 模型。通过从生成模型中采样,您可以生成新数据。虽然判别模型用于监督学习,但生成模型通常与未标记的数据集一起使用,并且可以被视为一种形式无监督学习 .
使用手写数字数据集,您可以训练生成模型来生成新数字。在训练阶段,您将使用某种算法来调整模型的参数,以最小化损失函数并了解训练集的概率分布。然后,通过训练模型,您可以生成新的样本,如下图所示:
为了输出新样本,生成模型通常考虑随机 或随机元素,影响模型生成的样本。用于驱动发电机的随机样本是从潜在空间 其中向量表示生成样本的一种压缩形式。
与判别模型不同,生成模型学习概率P (x )输入数据x ,并且通过输入数据的分布,他们能够生成新的数据实例。
笔记: 生成模型也可以与标记数据集一起使用。当他们这样做时,他们会接受训练来学习概率P (x |y )的输入x 给定输出y 。它们也可以用于分类任务,但一般来说,判别模型在分类方面表现更好。
您可以在文章中找到有关判别性分类器和生成性分类器的相对优缺点的更多信息关于判别式与生成式分类器:逻辑回归和朴素贝叶斯的比较 .
尽管 GAN 近年来受到了很多关注,但它们并不是唯一可以用作生成模型的架构。除了 GAN 之外,还有各种其他生成模型架构,例如:
玻尔兹曼机 变分自动编码器 隐马尔可夫模型 预测序列中下一个单词的模型,例如GPT-2
然而,GAN 最近引起了大多数公众的兴趣,因为令人兴奋的结果 在图像和视频生成中。
现在您已经了解了生成模型的基础知识,您将了解 GAN 的工作原理以及如何训练它们。
生成对抗网络的架构
生成对抗网络由两个神经网络组成的整体结构组成,其中一个称为发电机 另一个称为鉴别器 .
生成器的作用是估计真实样本的概率分布,以提供类似于真实数据的生成样本。反过来,判别器经过训练来估计给定样本来自真实数据而不是由生成器提供的概率。
这些结构被称为生成对抗网络,因为生成器和鉴别器经过训练可以相互竞争:生成器试图更好地欺骗鉴别器,而鉴别器试图更好地识别生成的样本。
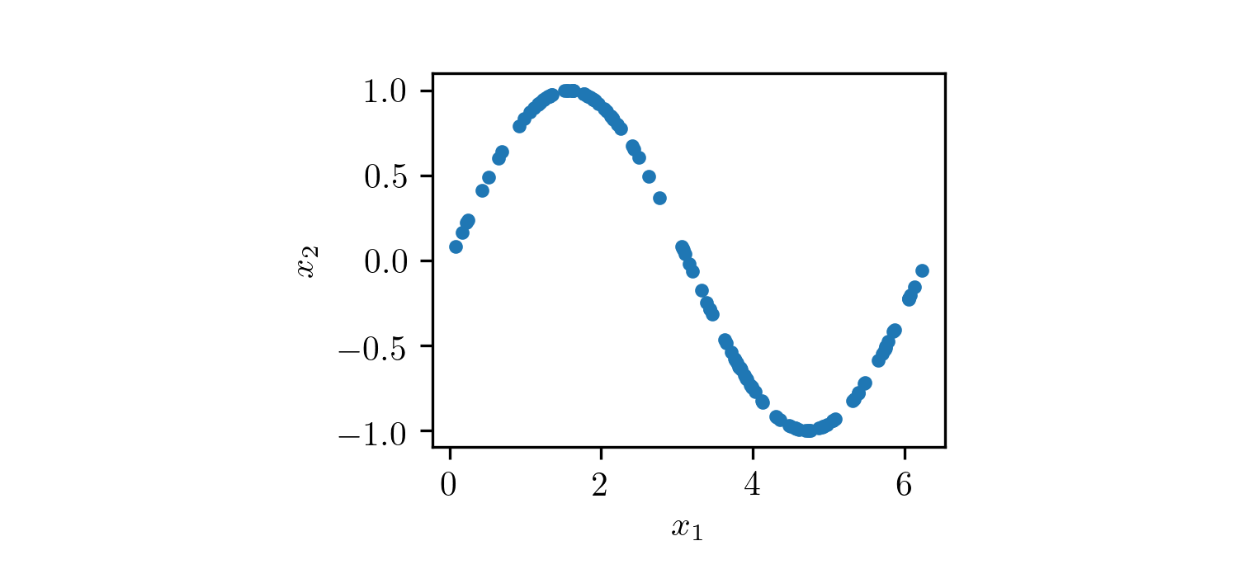
要了解 GAN 训练的工作原理,请考虑一个由二维样本组成的数据集的玩具示例(x ₁, x 2),与x ₁ 在 0 到 2π 的区间内x 2 = 罪(x ₁),如下图所示:
如您所见,该数据集由点 (x ₁, x 2) 位于正弦曲线上,具有非常特殊的分布。用于生成对的 GAN 的整体结构(x̃ ₁, x̃ 2)类似数据集的样本如下图所示:
发电机G 喂养的是随机数据 来自潜在空间,其作用是生成类似于真实样本的数据。在此示例中,您有一个二维潜在空间,以便生成器输入随机 (z ₁, z 2) 配对并需要对其进行转换,以便它们类似于真实的样本。
神经网络的结构G 可以是任意的,允许您使用神经网络作为多层感知器 (MLP),一个卷积神经网络 (CNN),或任何其他结构,只要输入和输出的维度与潜在空间和真实数据的维度匹配即可。
鉴别器D 提供来自训练数据集的真实样本或由G 。它的作用是估计输入属于真实数据集的概率。进行训练以便D 当输入真实样本时输出 1,当输入生成样本时输出 0。
与G ,你可以选择任意的神经网络结构D 只要它尊重必要的输入和输出尺寸。在此示例中,输入是二维的。对于二元鉴别器,输出可以是标量 范围从 0 到 1。
GAN 训练过程由两人组成极小极大 游戏其中D 适合最小化真实样本和生成样本之间的辨别误差,并且G 被调整以最大化概率D 犯错。
尽管包含真实数据的数据集没有被标记,但训练过程D 和G 以有监督的方式进行。在训练的每一步中,D 和G 更新它们的参数。事实上,在原始 GAN 提案 ,参数D 已更新k 次,而参数G 每个训练步骤仅更新一次。但是,为了使训练更简单,您可以考虑k 等于 1。
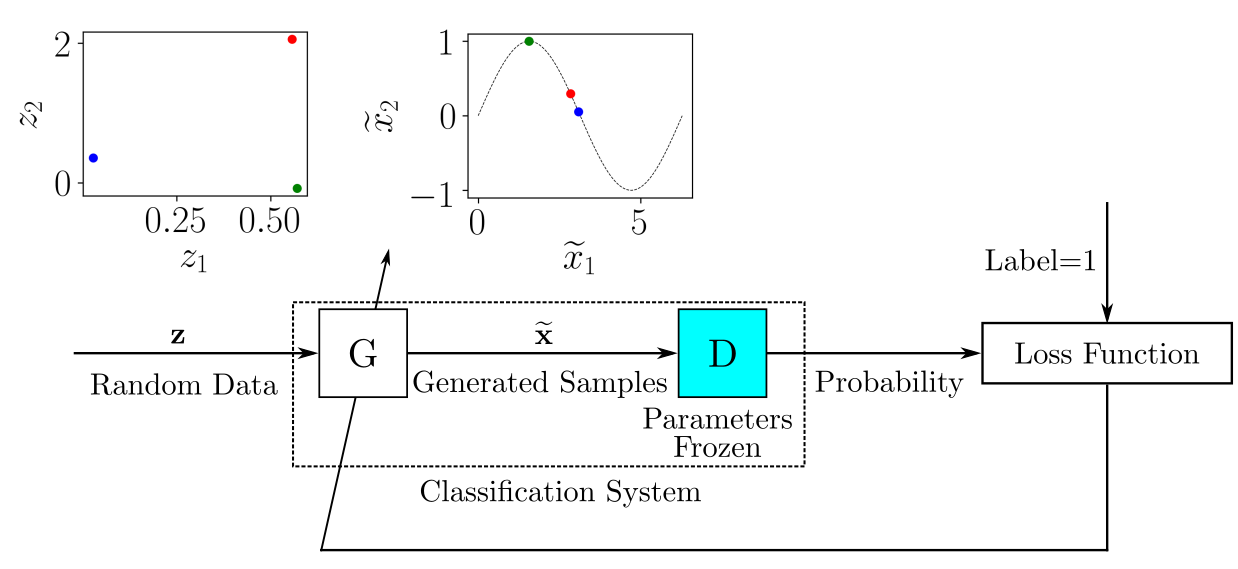
培训D ,在每次迭代中,您将从训练数据中获取的一些真实样本标记为 1,并将由G 为0。这样,就可以使用常规的监督训练框架来更新参数D 为了最小化损失函数,如下图所示:
对于包含标记的真实样本和生成样本的每批训练数据,您更新以下参数D 最小化损失函数。参数后D 已更新,您训练G 产生更好的生成样本。的输出G 连接到D ,其参数保持冻结,如下所示:
您可以想象该系统由以下组成G 和D 作为一个单一分类系统,接收随机样本作为输入并输出分类,在这种情况下可以解释为概率。
什么时候G 做得足够好来愚弄D ,输出概率应接近 1。您还可以在这里使用传统的监督训练框架:训练由以下组成的分类系统的数据集G 和D 将由随机输入样本提供,与每个输入样本关联的标签将为 1。
在训练过程中,作为参数D 和G 已更新,预计生成的样本由G 将更接近真实数据,并且D 区分真实数据和生成数据会遇到更多困难。
现在您已经了解了 GAN 的工作原理,您就可以使用它来实现您自己的了火炬 .
你的第一个 GAN
作为生成对抗网络的第一个实验,您将实现上一节中描述的示例。
要运行该示例,您将使用火炬 库,您可以使用以下命令安装蟒蛇 Python 发行版和康达 包和环境管理系统。要了解有关 Anaconda 和 conda 的更多信息,请查看以下教程在 Windows 上设置 Python 进行机器学习 .
首先,创建一个 conda 环境并激活它:
$ conda create --name gan
$ conda activate gan
激活 conda 环境后,您的提示符将显示其名称,gan。然后您可以在环境中安装必要的包:
$ conda install -c pytorch pytorch = 1 .4.0
$ conda install matplotlib jupyter
自从火炬 是一个非常活跃的开发框架,API 可能会在新版本中发生变化。为了确保示例代码能够运行,您需要安装特定版本1.4.0.
除了 PyTorch 之外,您还将使用Matplotlib 处理情节和Jupyter笔记本 在交互式环境中运行代码。这样做不是强制性的,但它有助于机器学习项目的工作。
要回顾如何使用 Matplotlib 和 Jupyter Notebooks,请查看使用 Matplotlib 进行 Python 绘图(指南) 和Jupyter Notebook:简介 .
打开Jupyter Notebook之前,需要注册condagan环境,以便您可以使用它作为内核创建笔记本。为此,与gan环境激活,运行以下命令:
$ python -m ipykernel install --user --name gan
现在您可以通过运行打开 Jupyter Notebookjupyter notebook。单击创建一个新笔记本New 然后选择gan .
在笔记本内部,首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
在这里,您可以使用以下命令导入 PyTorch 库torch。您还导入nn只是为了能够以更简洁的方式设置神经网络。然后你导入math获取 pi 常量的值,并将 Matplotlib 绘图工具导入为plt照常。
建立一个随机生成器种子 以便可以在任何机器上以相同的方式重复实验。要在 PyTorch 中执行此操作,请运行以下代码:
号码111代表随机种子 用于初始化随机数生成器,随机数生成器用于初始化神经网络的重量 。尽管实验具有随机性,但只要使用相同的种子,就必须提供相同的结果。
现在环境已经设置完毕,您可以准备训练数据了。
准备训练数据
训练数据由对组成 (x ₁, x 2) 这样x 2 由以下值的正弦值组成x ₁ 为x ₁ 在 0 到 2π 的区间内。您可以按如下方式实现:
1 train_data_length = 1024
2 train_data = torch . zeros (( train_data_length , 2 ))
3 train_data [:, 0 ] = 2 * math . pi * torch . rand ( train_data_length )
4 train_data [:, 1 ] = torch . sin ( train_data [:, 0 ])
5 train_labels = torch . zeros ( train_data_length )
6 train_set = [
7 ( train_data [ i ], train_labels [ i ]) for i in range ( train_data_length )
8 ]
在这里,您编写了一个训练集1024对(x ₁, x 2)。在2号线 ,你初始化train_data,维度为的张量1024行和2列,全部包含零。 A张量 是一个多维数组,类似于NumPy 数组 .
In 3号线 ,您使用第一列train_data存储区间内的随机值0到2π。然后,在4号线 ,您将张量的第二列计算为第一列的正弦。
接下来,您需要一个标签张量,这是 PyTorch 的数据加载器所需的。由于 GAN 使用无监督学习技术,因此标签可以是任何东西。毕竟它们不会被使用。
In 5号线 ,你创造train_labels,一个充满零的张量。最后,在第 6 至 8 行 ,你创造train_set作为元组列表,每行train_data和train_labels正如 PyTorch 数据加载器所期望的那样在每个元组中表示。
您可以通过绘制每个点来检查训练数据(x ₁, x ₂):
plt . plot ( train_data [:, 0 ], train_data [:, 1 ], "." )
输出应类似于下图:
和train_set,您可以创建一个 PyTorch 数据加载器:
batch_size = 32
train_loader = torch . utils . data . DataLoader (
train_set , batch_size = batch_size , shuffle = True
)
在这里,您创建一个名为的数据加载器train_loader,这会将数据打乱train_set并返回批次32您将用于训练神经网络的样本。
设置训练数据后,您需要为构成 GAN 的判别器和生成器创建神经网络。在下一节中,您将实现鉴别器。
实施鉴别器
在 PyTorch 中,神经网络模型由继承自的类表示nn.Module,因此您必须定义一个类来创建鉴别器。有关定义类的更多信息,请查看Python 3 中的面向对象编程 (OOP) .
判别器是一个具有二维输入和一维输出的模型。它将从真实数据或生成器接收样本,并提供该样本属于真实训练数据的概率。下面的代码显示了如何创建鉴别器:
1 class Discriminator ( nn . Module ):
2 def __init__ ( self ):
3 super () . __init__ ()
4 self . model = nn . Sequential (
5 nn . Linear ( 2 , 256 ),
6 nn . ReLU (),
7 nn . Dropout ( 0.3 ),
8 nn . Linear ( 256 , 128 ),
9 nn . ReLU (),
10 nn . Dropout ( 0.3 ),
11 nn . Linear ( 128 , 64 ),
12 nn . ReLU (),
13 nn . Dropout ( 0.3 ),
14 nn . Linear ( 64 , 1 ),
15 nn . Sigmoid (),
16 )
17
18 def forward ( self , x ):
19 output = self . model ( x )
20 return output
你用.__init__()构建模型。首先,您需要致电super().__init__()跑步.__init__()从nn.Module。您使用的判别器是一个 MLP 神经网络,使用顺序方式定义nn.Sequential()。它具有以下特点:
第 5 行和第 6 行: 输入是二维的,第一个隐藏层由256神经元与ReLU 激活。
第 8、9、11 和 12 行: 第二和第三隐藏层由128和64分别使用 ReLU 激活神经元。
第 14 行和第 15 行: 输出由单个神经元组成乙状结肠 激活来表示概率。
第 7、10 和 13 行: 在第一、第二和第三隐藏层之后,您使用辍学 避免过拟合 .
最后,你使用.forward()描述如何计算模型的输出。这里,x表示模型的输入,是一个二维张量。在此实现中,输出是通过输入输入获得的x到您定义的模型,无需任何其他处理。
声明鉴别器类后,您应该实例化一个Discriminator目的:
discriminator = Discriminator ()
discriminator代表您已定义并准备好接受训练的神经网络的实例。然而,在实现训练循环之前,您的 GAN 还需要一个生成器。您将在下一节中实现一个。
实现生成器
在生成对抗网络中,生成器是一种模型,它从潜在空间中获取样本作为输入,并生成与训练集中的数据相似的数据。在本例中,它是一个具有二维输入的模型,它将接收随机点(z ₁, z 2),以及必须提供(x̃ ₁, x̃ 2) 与训练数据相似的点。
该实现与您对判别器所做的类似。首先,您必须创建一个Generator继承自的类nn.Module,定义神经网络架构,然后你需要实例化一个Generator目的:
1 class Generator ( nn . Module ):
2 def __init__ ( self ):
3 super () . __init__ ()
4 self . model = nn . Sequential (
5 nn . Linear ( 2 , 16 ),
6 nn . ReLU (),
7 nn . Linear ( 16 , 32 ),
8 nn . ReLU (),
9 nn . Linear ( 32 , 2 ),
10 )
11
12 def forward ( self , x ):
13 output = self . model ( x )
14 return output
15
16 generator = Generator ()
这里,generator代表生成器神经网络。它由两个隐藏层组成16和32神经元,均具有 ReLU 激活和线性激活层2输出中的神经元。这样,输出将由一个具有两个元素的向量组成,这两个元素可以是从负无穷大到无穷大的任何值,这将表示 (x̃ ₁, x̃ ₂).
现在您已经定义了判别器和生成器的模型,您就可以开始训练了!
训练模型
在训练模型之前,您需要设置一些在训练期间使用的参数:
1 lr = 0.001
2 num_epochs = 300
3 loss_function = nn . BCELoss ()
您可以在此处设置以下参数:
1号线 设置学习率(lr),您将使用它来调整网络权重。
2号线 设置纪元数 (num_epochs),它定义了使用整个训练集进行多少次重复训练。
3号线 给变量赋值loss_function到二元交叉熵 功能BCELoss(),这是您将用于训练模型的损失函数。
二元交叉熵函数是训练鉴别器的合适损失函数,因为它考虑二元分类任务。它还适合训练生成器,因为它将其输出提供给鉴别器,鉴别器提供二进制可观察输出。
PyTorch 实现了模型训练的各种权重更新规则torch.optim。您将使用亚当算法 训练鉴别器和生成器模型。使用以下命令创建优化器torch.optim,运行以下行:
1 optimizer_discriminator = torch . optim . Adam ( discriminator . parameters (), lr = lr )
2 optimizer_generator = torch . optim . Adam ( generator . parameters (), lr = lr )
最后,您需要实现一个训练循环,其中将训练样本输入模型,并更新其权重以最小化损失函数:
1 for epoch in range ( num_epochs ):
2 for n , ( real_samples , _ ) in enumerate ( train_loader ):
3 # Data for training the discriminator
4 real_samples_labels = torch . ones (( batch_size , 1 ))
5 latent_space_samples = torch . randn (( batch_size , 2 ))
6 generated_samples = generator ( latent_space_samples )
7 generated_samples_labels = torch . zeros (( batch_size , 1 ))
8 all_samples = torch . cat (( real_samples , generated_samples ))
9 all_samples_labels = torch . cat (
10 ( real_samples_labels , generated_samples_labels )
11 )
12
13 # Training the discriminator
14 discriminator . zero_grad ()
15 output_discriminator = discriminator ( all_samples )
16 loss_discriminator = loss_function (
17 output_discriminator , all_samples_labels )
18 loss_discriminator . backward ()
19 optimizer_discriminator . step ()
20
21 # Data for training the generator
22 latent_space_samples = torch . randn (( batch_size , 2 ))
23
24 # Training the generator
25 generator . zero_grad ()
26 generated_samples = generator ( latent_space_samples )
27 output_discriminator_generated = discriminator ( generated_samples )
28 loss_generator = loss_function (
29 output_discriminator_generated , real_samples_labels
30 )
31 loss_generator . backward ()
32 optimizer_generator . step ()
33
34 # Show loss
35 if epoch % 10 == 0 and n == batch_size - 1 :
36 print ( f "Epoch: { epoch } Loss D.: { loss_discriminator } " )
37 print ( f "Epoch: { epoch } Loss G.: { loss_generator } " )
对于 GAN,您可以在每次训练迭代时更新鉴别器和生成器的参数。正如所有神经网络通常所做的那样,训练过程由两个循环组成,一个循环用于训练时期,另一个循环用于每个时期的批次。在内部循环中,您开始准备数据来训练鉴别器:
2号线: 您从数据加载器中获取当前批次的真实样本并将它们分配给real_samples。请注意,张量的第一个维度的元素数量等于batch_size。这是 PyTorch 中组织数据的标准方式,张量的每一行代表批次中的一个样本。
4号线: 你用torch.ones()创建带有值的标签1对于真实样本,然后将标签分配给real_samples_labels.
第 5 行和第 6 行: 您通过将随机数据存储在中来创建生成的样本latent_space_samples,然后将其输入生成器以获得generated_samples.
7号线: 你用torch.zeros()分配值0到生成的样本的标签,然后将标签存储在generated_samples_labels.
第 8 至 11 行: 您连接真实的和生成的样本和标签并将它们存储在all_samples和all_samples_labels,您将用它来训练鉴别器。
接下来,在第 14 至 19 行 ,你训练鉴别器:
14号线: 在 PyTorch 中,有必要在每个训练步骤中清除梯度以避免累积梯度。你这样做使用.zero_grad().
15号线: 您使用中的训练数据计算鉴别器的输出all_samples.
第 16 行和第 17 行: 您可以使用模型的输出来计算损失函数output_discriminator和标签中all_samples_labels.
18号线: 您计算梯度以更新权重loss_discriminator.backward().
19号线: 您可以通过调用更新鉴别器权重optimizer_discriminator.step().
接下来,在22号线 ,您准备数据来训练生成器。您将随机数据存储在latent_space_samples,行数等于batch_size。您使用两列,因为您提供二维数据作为生成器的输入。
你训练发电机第 25 至 32 行 :
25号线: 您可以使用以下命令清除渐变.zero_grad().
26号线: 你给发电机供电latent_space_samples并将其输出存储在generated_samples.
27号线: 您将生成器的输出输入鉴别器并将其输出存储在output_discriminator_generated,您将使用它作为整个模型的输出。
第 28 至 30 行: 您可以使用存储在中的分类系统的输出来计算损失函数output_discriminator_generated和标签中real_samples_labels,它们都等于1.
第 31 行和第 32 行: 您计算梯度并更新生成器权重。请记住,当您训练生成器时,自创建以来您就保持了鉴别器权重的冻结optimizer_generator第一个参数等于generator.parameters().
最后,关于第 35 至 37 行 ,您在每十个时期结束时显示鉴别器和生成器损失函数的值。
由于本例中使用的模型参数较少,因此训练将在几分钟内完成。在下一节中,您将使用经过训练的 GAN 来生成一些样本。
检查GAN生成的样本
生成对抗网络旨在生成数据。因此,训练过程完成后,您可以从潜在空间中获取一些随机样本并将它们输入生成器以获得一些生成样本:
latent_space_samples = torch . randn ( 100 , 2 )
generated_samples = generator ( latent_space_samples )
然后,您可以绘制生成的样本并检查它们是否类似于训练数据。在绘制之前generated_samples数据,您需要使用.detach()从 PyTorch 计算图中返回一个张量,然后您将用它来计算梯度:
generated_samples = generated_samples . detach ()
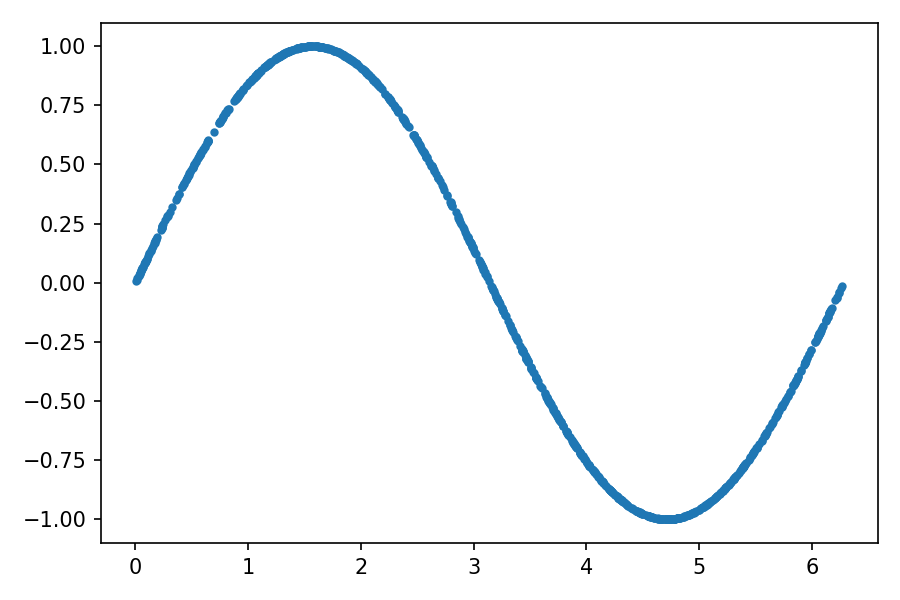
plt . plot ( generated_samples [:, 0 ], generated_samples [:, 1 ], "." )
输出应类似于下图:
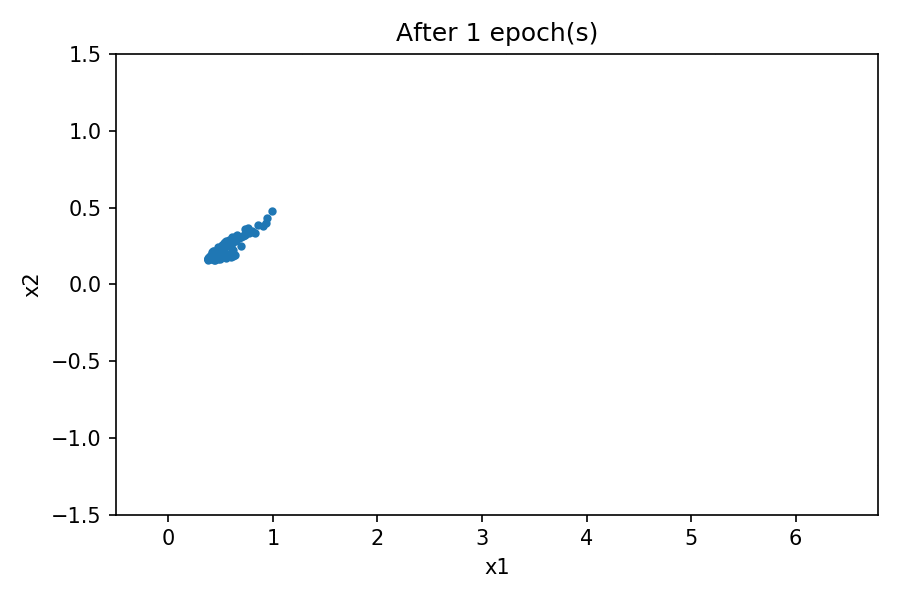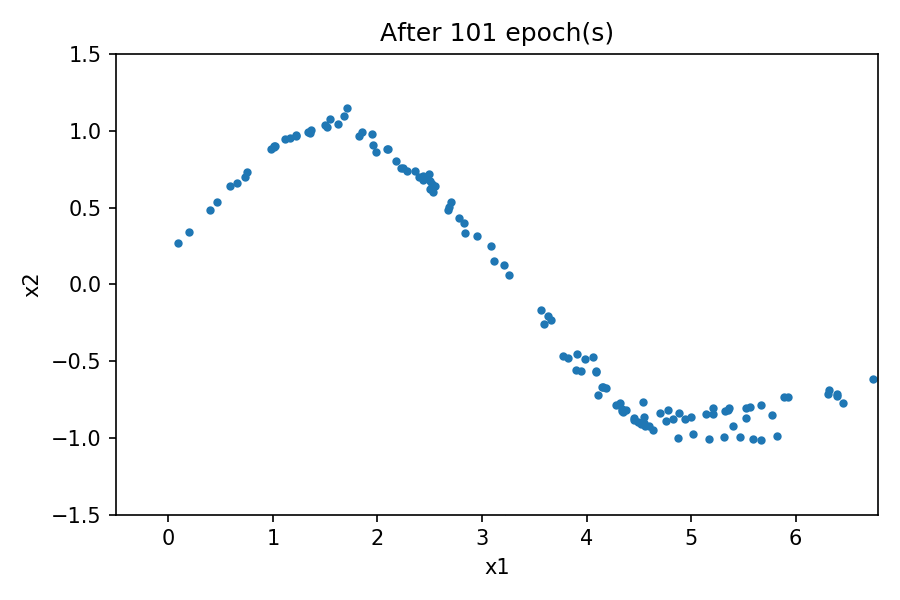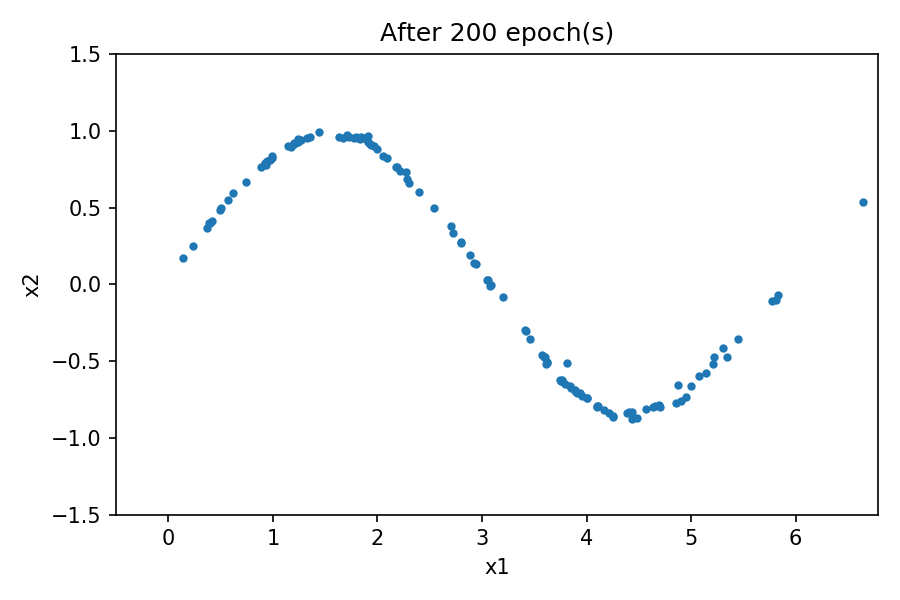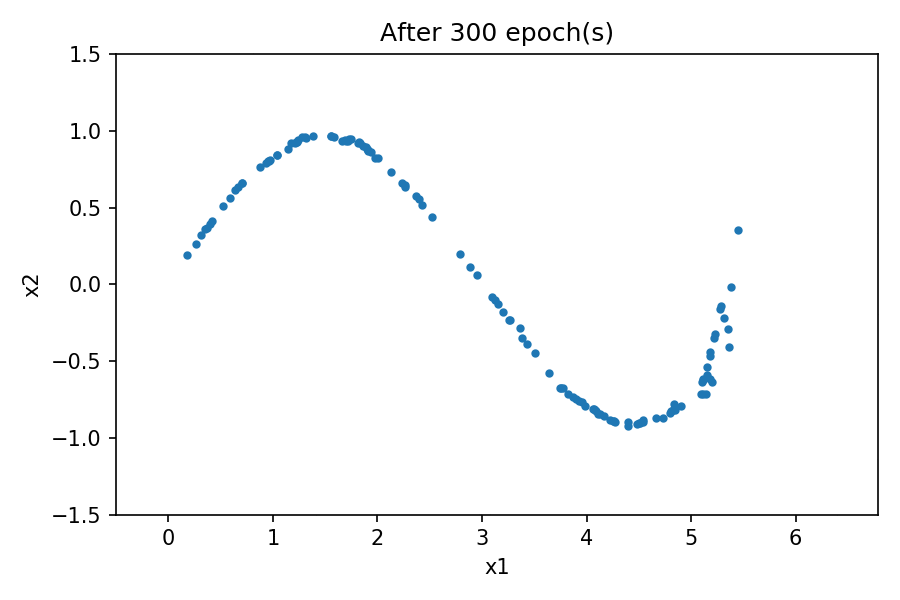
您可以看到生成的数据的分布与真实数据的分布相似。通过使用固定的潜在空间样本张量并在训练过程中的每个时期结束时将其馈送到生成器,您可以可视化训练的演变:
请注意,在训练过程开始时,生成的数据分布与真实数据有很大不同。然而,随着训练的进行,生成器会学习真实的数据分布。
现在您已经完成了生成对抗网络的首次实现,您将使用图像进行更实际的应用程序。
使用 GAN 的手写数字生成器
生成对抗网络还可以生成高维样本,例如图像。在此示例中,您将使用 GAN 生成手写数字的图像。为此,您将使用以下方法训练模型MNIST 数据集 手写数字,包含在火炬视觉 包裹。
首先,您需要安装torchvision在激活的gan康达环境:
$ conda install -c pytorch torchvision = 0 .5.0
同样,您正在使用特定版本的torchvision确保示例代码能够运行,就像您所做的那样pytorch。设置环境后,您可以开始在 Jupyter Notebook 中实现模型。打开它并通过单击创建一个新笔记本New 然后选择gan .
与前面的示例一样,您首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
除了之前导入的库之外,您还需要torchvision和transforms获取训练数据并执行图像转换。
再次设置随机生成器种子以便能够复制实验:
由于此示例使用训练集中的图像,因此模型需要更复杂,参数数量更多。这使得训练过程变慢,运行时每个 epoch 大约需要两分钟CPU 。您需要大约 50 个 epoch 才能获得相关结果,因此使用 CPU 时的总训练时间约为 100 分钟。
为了减少训练时间,您可以使用GPU 训练模型(如果有的话)。但是,您需要手动将张量和模型移动到 GPU 才能在训练过程中使用它们。
您可以通过创建一个来确保您的代码可以在任一设置上运行device指向 CPU 或 GPU(如果可用)的对象:
device = ""
if torch . cuda . is_available ():
device = torch . device ( "cuda" )
else :
device = torch . device ( "cpu" )
稍后你会用到这个device设置应在何处创建张量和模型,使用 GPU(如果可用)。
现在基本环境已经设置好了,接下来就可以准备训练数据了。
准备训练数据
MNIST 数据集由 28 × 28 像素的手写数字 0 到 9 的灰度图像组成。要将它们与 PyTorch 一起使用,您需要执行一些转换。为此,您定义transform,加载数据时要使用的函数:
transform = transforms . Compose (
[ transforms . ToTensor (), transforms . Normalize (( 0.5 ,), ( 0.5 ,))]
)
该函数有两部分:
transforms.ToTensor()
transforms.Normalize()
原始系数由下式给出transforms.ToTensor()范围从 0 到 1,并且由于图像背景是黑色,因此当使用此范围表示时,大多数系数等于 0。
transforms.Normalize()通过减去将系数的范围更改为 -1 到 10.5原始系数并将结果除以0.5。通过这种转换,输入样本中等于 0 的元素数量显着减少,这有助于训练模型。
的论点transforms.Normalize()是两个元组,(M₁, ..., Mₙ)和(S₁, ..., Sₙ), 和n代表数量渠道 的图像。灰度图像(例如 MNIST 数据集中的灰度图像)只有一个通道,因此元组只有一个值。然后,对于每个通道i图像的transforms.Normalize()减去Mᵢ系数并将结果除以Sᵢ.
现在您可以使用加载训练数据torchvision.datasets.MNIST并使用执行转换transform:
train_set = torchvision . datasets . MNIST (
root = "." , train = True , download = True , transform = transform
)
论据download=True确保第一次运行上述代码时,MNIST 数据集将被下载并存储在当前目录中,如参数所示root.
现在您已经创建了train_set,您可以像以前一样创建数据加载器:
batch_size = 32
train_loader = torch . utils . data . DataLoader (
train_set , batch_size = batch_size , shuffle = True
)
您可以使用 Matplotlib 绘制训练数据的一些样本。为了提高可视化效果,您可以使用cmap=gray_r反转颜色图并在白色背景上以黑色绘制数字:
real_samples , mnist_labels = next ( iter ( train_loader ))
for i in range ( 16 ):
ax = plt . subplot ( 4 , 4 , i + 1 )
plt . imshow ( real_samples [ i ] . reshape ( 28 , 28 ), cmap = "gray_r" )
plt . xticks ([])
plt . yticks ([])
输出应该类似于以下内容:
正如您所看到的,有些数字具有不同的手写风格。当 GAN 了解数据的分布时,它还会生成具有不同手写风格的数字。
现在您已经准备好了训练数据,您可以实现判别器和生成器模型。
实现判别器和生成器
在这种情况下,鉴别器是一个 MLP 神经网络,它接收 28 × 28 像素图像并提供该图像属于真实训练数据的概率。
您可以使用以下代码定义模型:
1 class Discriminator ( nn . Module ):
2 def __init__ ( self ):
3 super () . __init__ ()
4 self . model = nn . Sequential (
5 nn . Linear ( 784 , 1024 ),
6 nn . ReLU (),
7 nn . Dropout ( 0.3 ),
8 nn . Linear ( 1024 , 512 ),
9 nn . ReLU (),
10 nn . Dropout ( 0.3 ),
11 nn . Linear ( 512 , 256 ),
12 nn . ReLU (),
13 nn . Dropout ( 0.3 ),
14 nn . Linear ( 256 , 1 ),
15 nn . Sigmoid (),
16 )
17
18 def forward ( self , x ):
19 x = x . view ( x . size ( 0 ), 784 )
20 output = self . model ( x )
21 return output
要将图像系数输入 MLP 神经网络,您需要矢量化 以便神经网络接收向量784系数。
矢量化发生在第一行.forward(),作为调用x.view()转换输入张量的形状。在这种情况下,输入的原始形状x是 32 × 1 × 28 × 28,其中 32 是您设置的批量大小。转换后的形状为x变为 32 × 784,每行代表训练集图像的系数。
要使用 GPU 运行鉴别器模型,您必须实例化它并将其发送到 GPU.to()。要在有可用 GPU 时使用 GPU,您可以将模型发送到device您之前创建的对象:
discriminator = Discriminator () . to ( device = device )
由于生成器将生成更复杂的数据,因此有必要增加潜在空间输入的维度。在这种情况下,生成器将被输入 100 维输入,并提供具有 784 个系数的输出,这些系数将被组织成表示图像的 28 × 28 张量。
这是完整的生成器模型代码:
1 class Generator ( nn . Module ):
2 def __init__ ( self ):
3 super () . __init__ ()
4 self . model = nn . Sequential (
5 nn . Linear ( 100 , 256 ),
6 nn . ReLU (),
7 nn . Linear ( 256 , 512 ),
8 nn . ReLU (),
9 nn . Linear ( 512 , 1024 ),
10 nn . ReLU (),
11 nn . Linear ( 1024 , 784 ),
12 nn . Tanh (),
13 )
14
15 def forward ( self , x ):
16 output = self . model ( x )
17 output = output . view ( x . size ( 0 ), 1 , 28 , 28 )
18 return output
19
20 generator = Generator () . to ( device = device )
In 12号线 ,你使用双曲正切函数 Tanh()作为输出层的激活,因为输出系数应在 -1 到 1 的区间内。20号线 ,您实例化生成器并将其发送到device使用 GPU(如果可用)。
现在您已经定义了模型,您将使用训练数据来训练它们。
训练模型
要训练模型,您需要定义训练参数和优化器,就像在上一个示例中所做的那样:
lr = 0.0001
num_epochs = 50
loss_function = nn . BCELoss ()
optimizer_discriminator = torch . optim . Adam ( discriminator . parameters (), lr = lr )
optimizer_generator = torch . optim . Adam ( generator . parameters (), lr = lr )
为了获得更好的结果,您可以降低上一个示例的学习率。您还可以将纪元数设置为50以减少训练时间。
训练循环与上一示例中使用的非常相似。在突出显示的行中,您将训练数据发送到device使用 GPU(如果可用):
1 for epoch in range ( num_epochs ):
2 for n , ( real_samples , mnist_labels ) in enumerate ( train_loader ):
3 # Data for training the discriminator
4 real_samples = real_samples . to ( device = device )
5 real_samples_labels = torch . ones (( batch_size , 1 )) . to (
6 device = device
7 )
8 latent_space_samples = torch . randn (( batch_size , 100 )) . to (
9 device = device
10 )
11 generated_samples = generator ( latent_space_samples )
12 generated_samples_labels = torch . zeros (( batch_size , 1 )) . to (
13 device = device
14 )
15 all_samples = torch . cat (( real_samples , generated_samples ))
16 all_samples_labels = torch . cat (
17 ( real_samples_labels , generated_samples_labels )
18 )
19
20 # Training the discriminator
21 discriminator . zero_grad ()
22 output_discriminator = discriminator ( all_samples )
23 loss_discriminator = loss_function (
24 output_discriminator , all_samples_labels
25 )
26 loss_discriminator . backward ()
27 optimizer_discriminator . step ()
28
29 # Data for training the generator
30 latent_space_samples = torch . randn (( batch_size , 100 )) . to (
31 device = device
32 )
33
34 # Training the generator
35 generator . zero_grad ()
36 generated_samples = generator ( latent_space_samples )
37 output_discriminator_generated = discriminator ( generated_samples )
38 loss_generator = loss_function (
39 output_discriminator_generated , real_samples_labels
40 )
41 loss_generator . backward ()
42 optimizer_generator . step ()
43
44 # Show loss
45 if n == batch_size - 1 :
46 print ( f "Epoch: { epoch } Loss D.: { loss_discriminator } " )
47 print ( f "Epoch: { epoch } Loss G.: { loss_generator } " )
某些张量不需要显式发送到 GPUdevice。情况就是这样generated_samples在11号线 ,自此以来它已经被发送到可用的 GPUlatent_space_samples和generator之前已发送至 GPU。
由于此示例具有更复杂的模型,因此训练可能需要更多时间。完成后,您可以通过生成一些手写数字样本来检查结果。
检查GAN生成的样本
要生成手写数字,您必须从潜在空间中获取一些随机样本并将其输入生成器:
latent_space_samples = torch . randn ( batch_size , 100 ) . to ( device = device )
generated_samples = generator ( latent_space_samples )
绘制generated_samples,如果数据在 GPU 上运行,则需要将数据移回 CPU。为此,您只需调用.cpu()。正如您之前所做的那样,您还需要调用.detach()在使用 Matplotlib 绘制数据之前:
generated_samples = generated_samples . cpu () . detach ()
for i in range ( 16 ):
ax = plt . subplot ( 4 , 4 , i + 1 )
plt . imshow ( generated_samples [ i ] . reshape ( 28 , 28 ), cmap = "gray_r" )
plt . xticks ([])
plt . yticks ([])
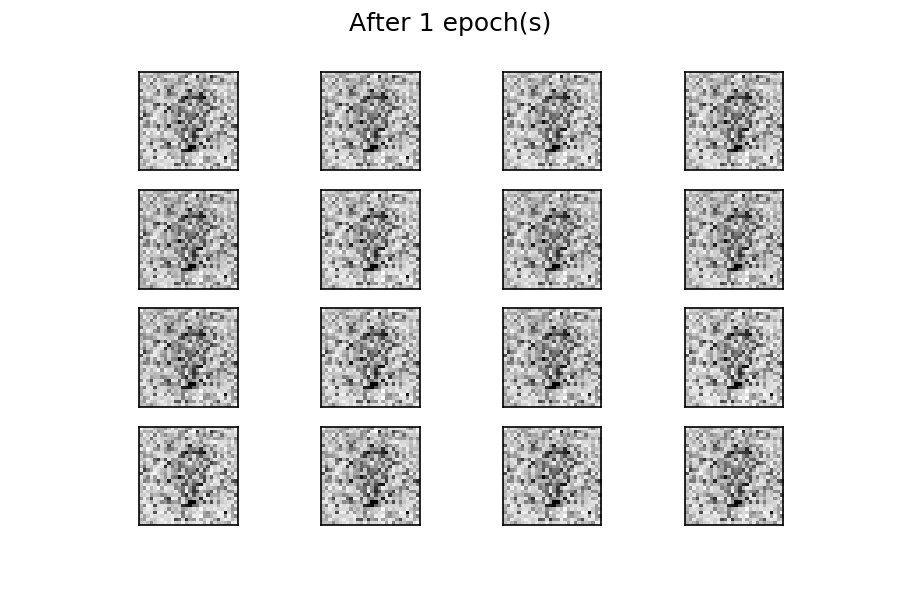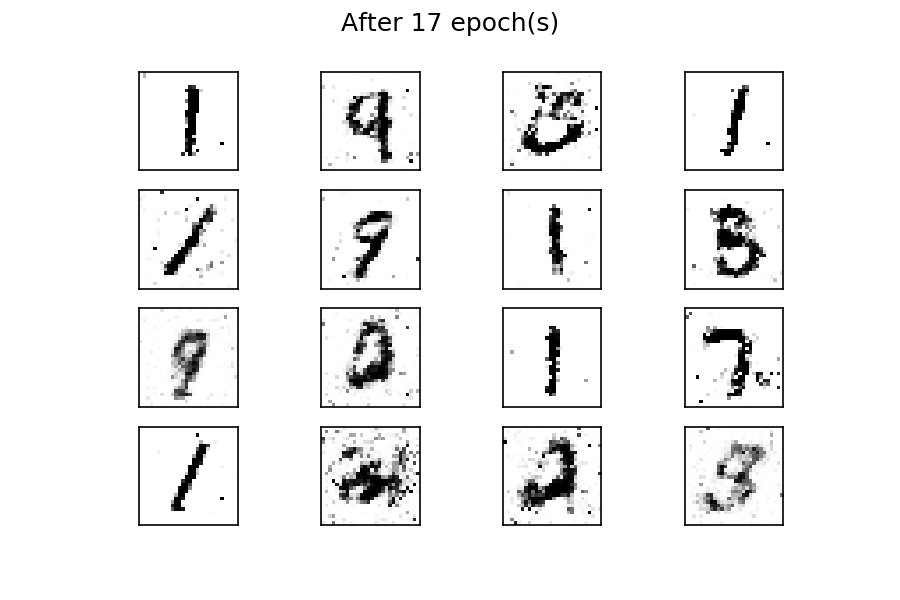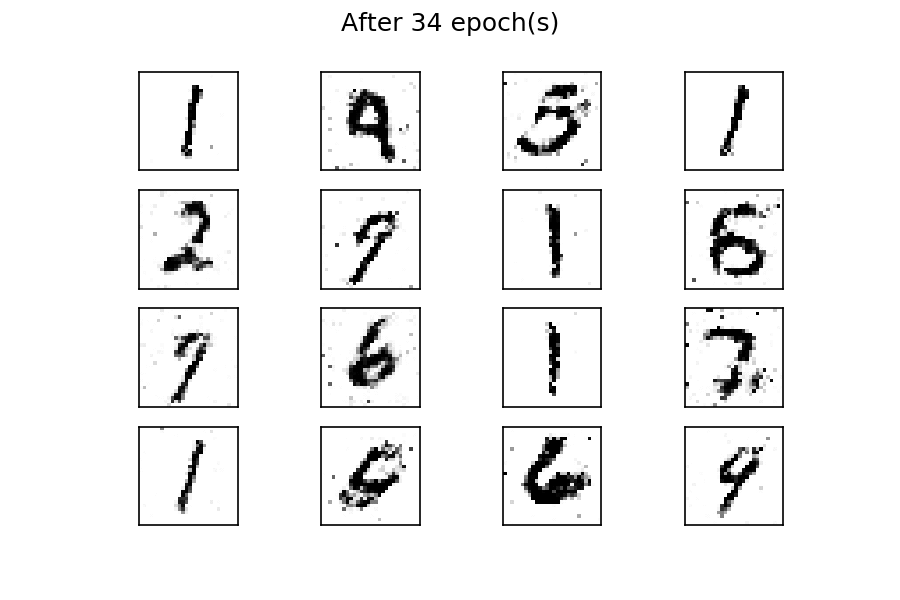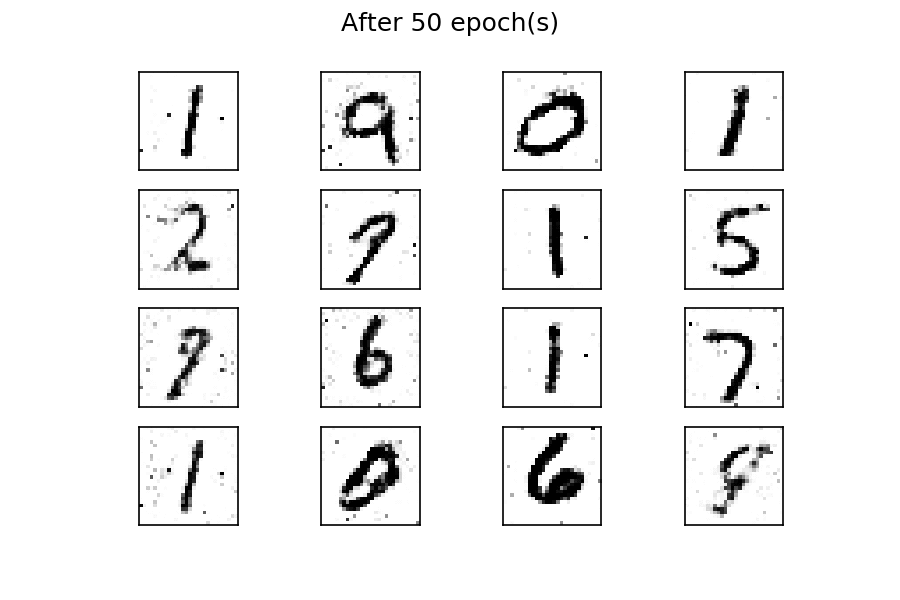
输出应该是类似于训练数据的数字,如下图所示:
经过五十个 epoch 的训练,有几个生成的数字与真实的数字相似。您可以通过考虑更多的训练周期来改善结果。与前面的示例一样,通过使用固定的潜在空间样本张量并在训练过程中每个时期结束时将其馈送到生成器,您可以可视化训练的演变:
您可以看到,在训练过程开始时,生成的图像是完全随机的。随着训练的进行,生成器学习真实数据的分布,并且在大约二十个时期,一些生成的数字已经类似于真实数据。
结论
恭喜!您已经学习了如何实现自己的生成对抗网络。您首先通过一个玩具示例来了解 GAN 结构,然后再深入研究生成手写数字图像的实际应用程序。
您看到,尽管 GAN 很复杂,但像 PyTorch 这样的机器学习框架通过提供自动微分 以及简单的 GPU 设置。
在本教程中,您学习了:
之间有什么区别歧视性的 和生成的 楷模
生成对抗网络是如何产生的结构化的 和训练有素的
如何使用类似的工具火炬 和一个GPU 实施和训练 GAN 模型
GAN 是一个非常活跃的研究课题,近年来提出了一些令人兴奋的应用。如果您对该主题感兴趣,请关注技术和科学文献以检查新的应用想法。
进一步阅读
现在您已经了解了使用生成对抗网络的基础知识,您可以开始研究更复杂的应用程序。以下书籍是加深知识的好方法:
GAN 的实际应用:利用生成对抗网络进行深度学习 由 Jakub Langr 和 Vladimir Bok 撰写,更详细地介绍了该主题,包括最近的应用,例如循环GAN 用于执行风格转换。
生成深度学习:教机器绘画、写作、作曲和玩耍 大卫·福斯特 (David Foster) 调查了生成对抗网络和其他生成模型的实际应用。
值得一提的是,机器学习是一门广泛的学科,除了生成对抗网络之外,还有很多不同的模型结构。有关机器学习的更多信息,请查看以下资源:
在 Windows 上设置 Python 进行机器学习 使用 Python 和 Keras 进行实用文本分类 使用 Python 进行传统人脸检测 在 OpenCV + Python 中使用颜色空间进行图像分割 Python 语音识别终极指南 使用协同过滤构建推荐引擎
机器学习的世界里有很多东西需要学习。继续学习,如有任何问题或评论,请随时在下面留下!