克隆你的声音,可能只需要5秒钟:MockingBird实现AI拟声
- 0. 引
- 1. 背景
- 2. 环境搭建
- 2.1 安装pytorch
- 2.2 安装ffmpeg
- 2.3 下载MockingBird源码
- 2.4 安装requirements
- 2.5. 下载预训练模型
- 3. 运行MockingBrid
-
- 4. 录音->合成语音
- 5. 效果优化
- 6. 结论:
- 博主热门文章推荐:

0. 引
老铁们好,今天Howie介绍一个AI语音克隆算法项目MockingBird,号称仅需要你的一段声音,仅需5秒钟,就可以根据任意文字,克隆出你新的声音,听起来,就像你在说这段文字一样?。还让人真假难辨?
那岂不是, 一个骗子不看话术,改看兵法了?

虽然听起来恐怖如斯, 但真实情况是什么样的?AI拟声真的可以以假乱真,并且实现方式简单至极?
(注:因为CSDN blog不支持上传语音内容,有兴趣听AI拟音语音的小伙伴,请关注微信公众号同名文章: https://mp.weixin.qq.com/s/AHvdj88kHbjitL8UuvCehg)
试想一下,在夜深人静的夜晚,你接到一通电话。说了几句以为是骗子就直接挂断了,心里暗骂就这还能骗到本大爷??然而,之后一段时间,以你的声音发出的借钱/诈骗电话,却传遍了你的朋友圈。。 细思极恐~

这不是演习,无论微信语音/电话,还是视频中的声音,只要骗子得到了你的一段声音;就可以通过AI算法,学习并模拟你的声音,然后合成任意一段话术,比如“借钱”,转发给你的亲友,实施诈骗。。
那么问题来了,有一天你收到电话,虽然只有只言片语,但听起来声音却和老板或亲友“一模一样”,声称情况紧急要打钱?
到底该不该相信?
到底要不要打钱?

切入正题,下面我们来真正实践下AI拟声项目,来看看上面的情况是否属实?。。
1. 背景
继“AI换脸”,“眼见不实” 刷屏之后,AI换声/拟声技术也受到大量关注。
AI换声/拟声技术,是指利用AI模型学习声音特征,比如(一个人的声音音色,音调,语速)等特征,通过语音合成技术,重新生成新的声音。
就类似于大家熟知的变声器,只不过变的是某人的真人声音,达到"以假乱真"。
MockingBird是基于Github项目: Real-Time-Voice-Cloning 修改的中文语音支持版本,号称能在5秒内克隆语音以实时生成任意语音,地址
- GitHub:https://github.com/babysor/MockingBird
- GitCode:https://gitcode.net/mirrors/babysor/MockingBird/
项目实现的核心论文是基于:SV2TTS (Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis)
论文地址:https://arxiv.org/pdf/1806.04558.pdf
实现上主要分为三个模块(三个单独的pt模型):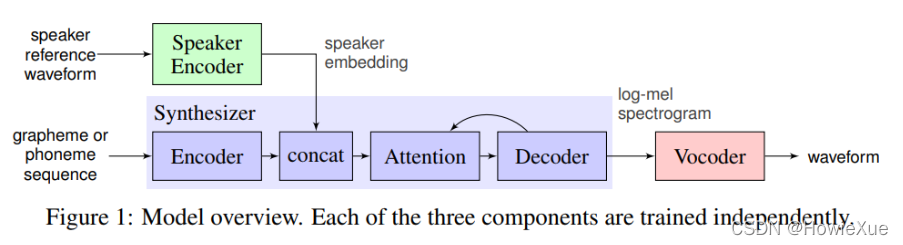
Encoder 会提取的输入声音的音色向量,是确保输出声音相似度的关键所在

- Synthesizer:Sequence-to-sequence synthesizer,将Text文本转换成mel-spectrogram梅尔频谱图

Encoder模块提取的说话人音色向量,会作为speaker embedding,融合入Synthesizer Encoder的输出结果(concat),然后基于Attention,将目标文本转换成mel-spectrogram
- Vocoder: 使用WaveNet vocoder, 将mel-spectrogram转换成时域的声音waveform

最终通过Vocoder模块将mel-spectrogram转换成声音的waveform,播放出来。
总结来说,整个算法模块通过Encoder获取说话声音的音色(输入语音),然后使用Synthesizer和Vocoder根据输入文字实现TTS(text-to-speech)合成语音(输出语音)
该项目的Reference如下:

2. 环境搭建
开始搭建运行环境,建议使用Anaconda,可参加之前博文:最新Anaconda3的安装配置及使用教程(详细过程)
2.1 安装pytorch
这里我直接pip安装的CPU版本
pip3 install torch torchvision torchaudio
如果有GPU可以安装CUDA版:

torch安装完成:

2.2 安装ffmpeg
打开ffmpeg org 官网,https://ffmpeg.org/download.html#get-packages

选择相应平台即可下载l
- 下载地址1:https://www.gyan.dev/ffmpeg/builds/
- 下载地址2:https://github.com/BtbN/FFmpeg-Builds/releases
下载后,把bin 目录放到系统环境变量中
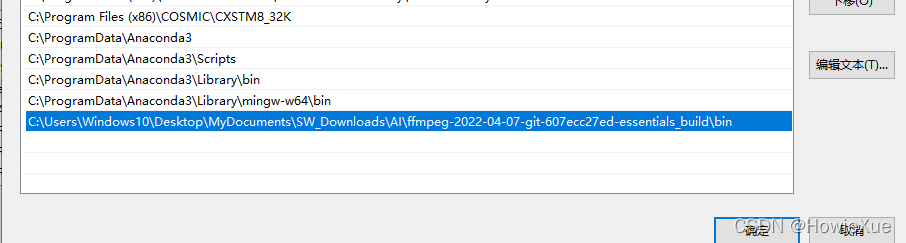
cmd查看下,ffmpeg安装完成:
- ffmpeg -version

2.3 下载MockingBird源码
直接git clone即可
git clone https://github.com/babysor/MockingBird.git
clone完毕,源码目录结构如下:
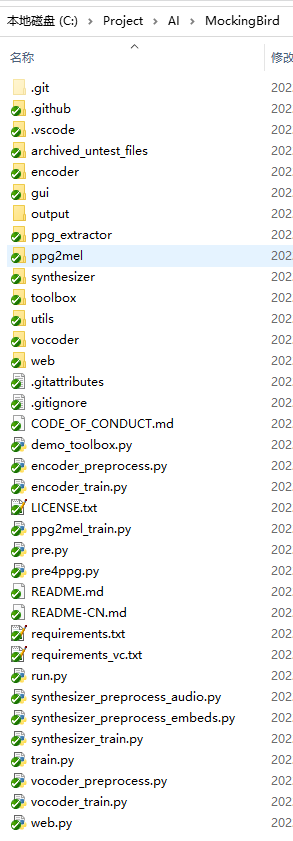
2.4 安装requirements
进入源码目录,安装requirements
pip install -r requirements.txt
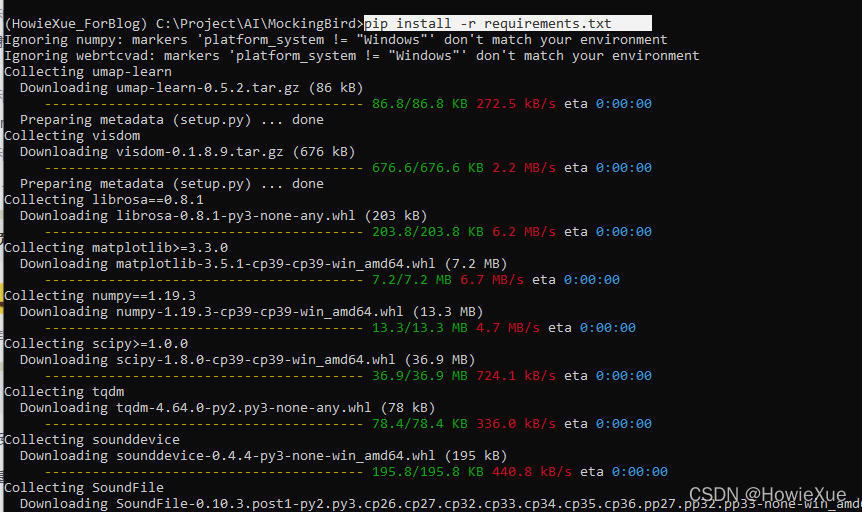
然后安装webrtcvad
pip install webrtcvad-wheels

2.5. 下载预训练模型
在synthesizer目录下创建一个saved_models文件夹,下载预训练模型后放入到该目录中即可
https://github.com/babysor/MockingBird 下载时在Github上找最新的版本即可:
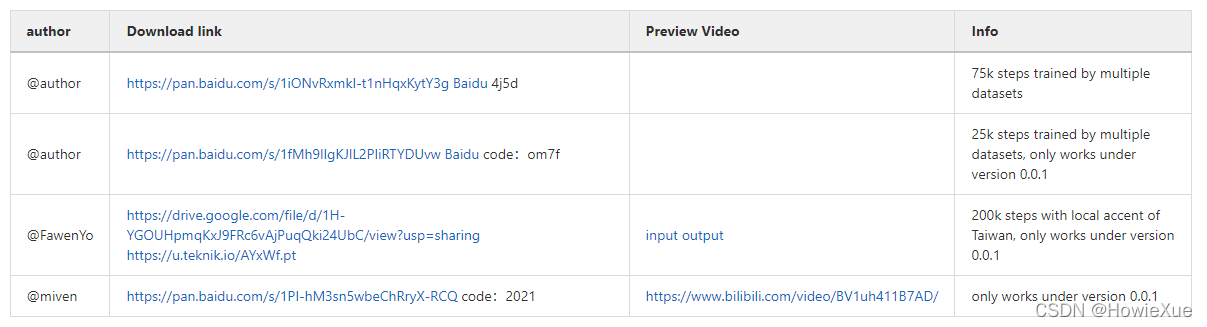
这里我下载了4个 synthesizer model:
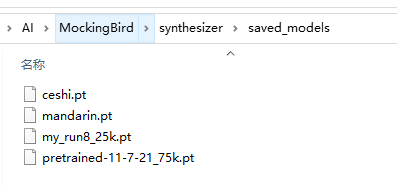
同时也检查下encoder 和vocoder 的saved_models目录是否有pt模型,如果没有需要检查代码版本
3. 运行MockingBrid
3.1 运行Web版
python web.py
运行时如果 synthesizer model是0,则检测下上一步下载的model路径
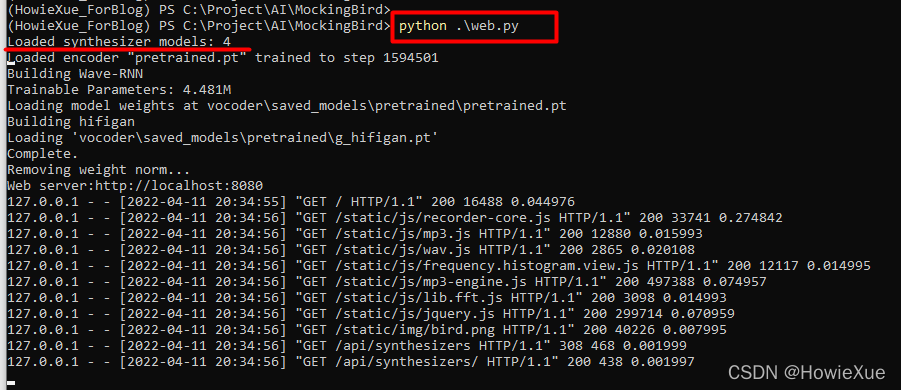
会在localhost 8080启动服务:

web.py:
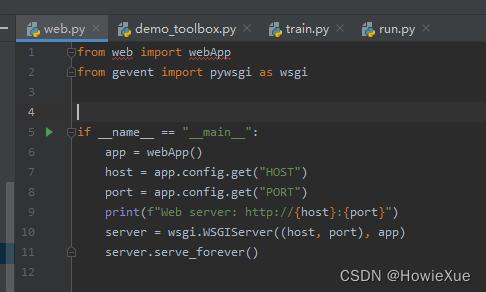
但web版本功能使用上不太方便,还是推荐使用下面的toolbox
3.2 运行Toolbox版
先直接运行demo_toolbox.py
python demo_toolbox.py
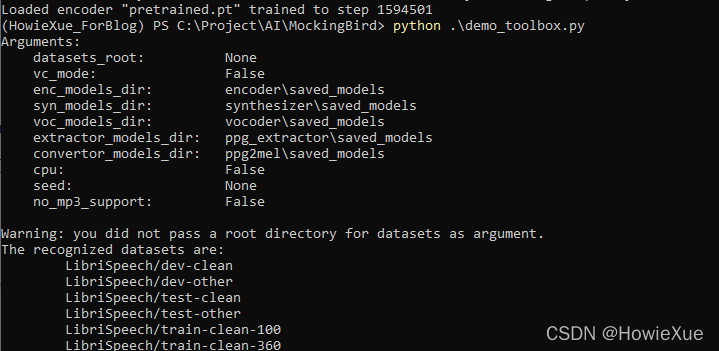
启动后GUI是这样的
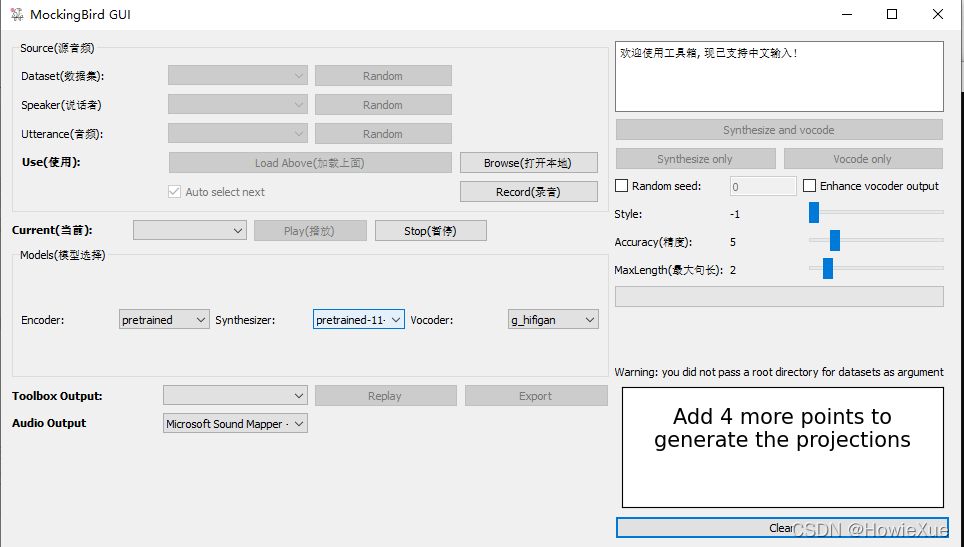
使用说明:
如果有数据集可以运行:
python demo_toolbox.py vc -d <datasets_root>
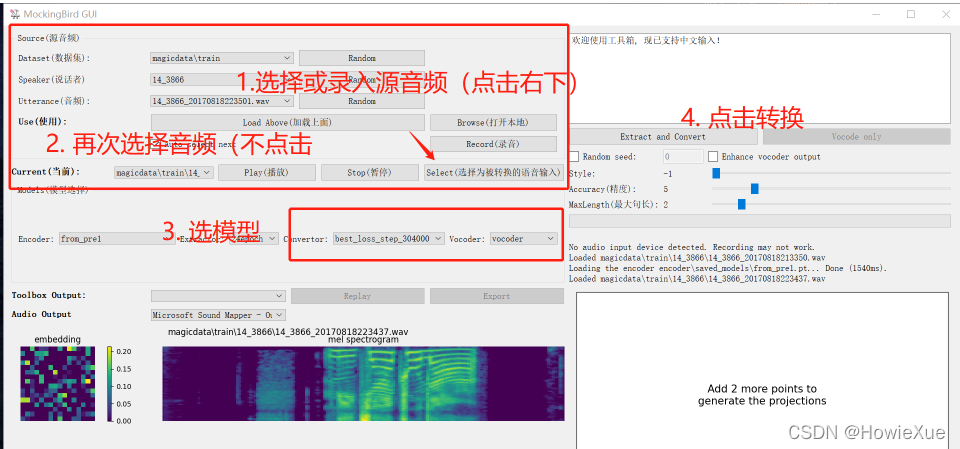
4. 录音->合成语音
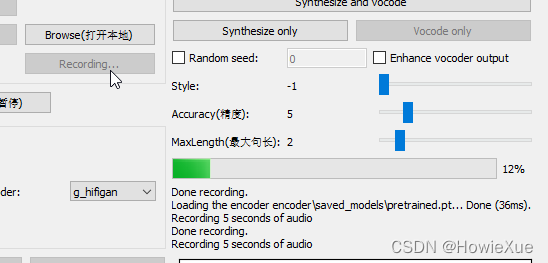
如果有录音wav文件,可以点击Browse打开本地录音,如果没有可以点击Recording当场录制(会录制5秒电脑音频)
本地录音也最在10s以下,注意尽量保持录音环境没有多余噪音,而且只有一个声音。 说话间隔也保持正常,尽量不要使用语气词。
最简单的就是念一行文字
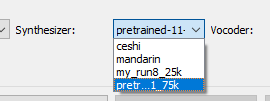
注意选择相应的model:
录好一段声音后,即可在文本框输入要合成的文字,点击Synthesize and vocode ,
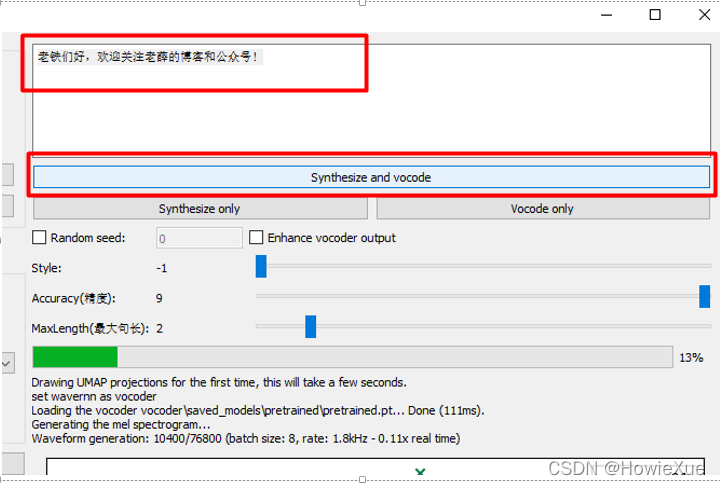
等待一段时间,进度条和log可以显示进度,完成后即可输出结果并自动播放合成的声音:
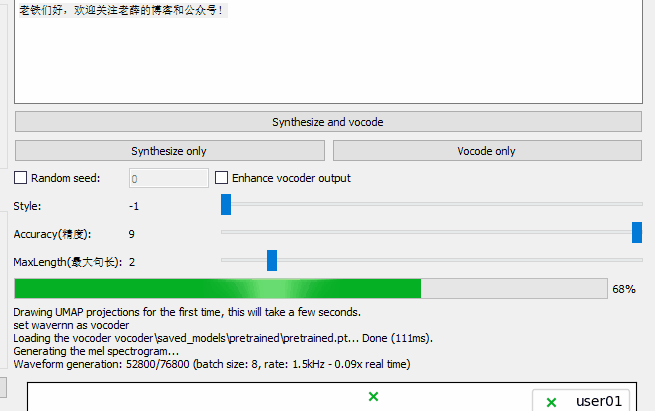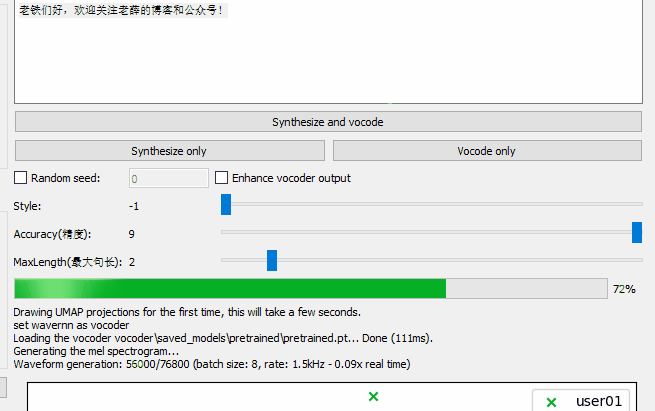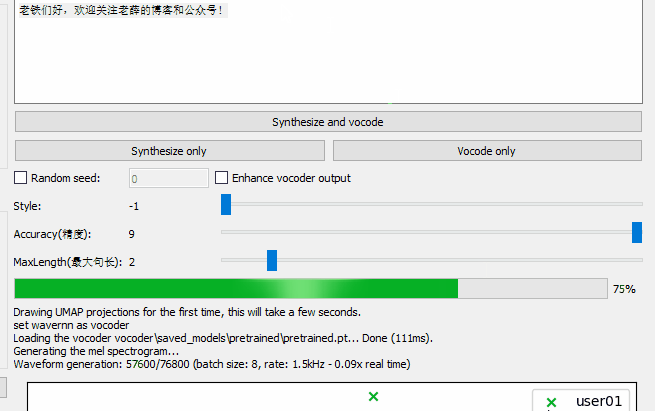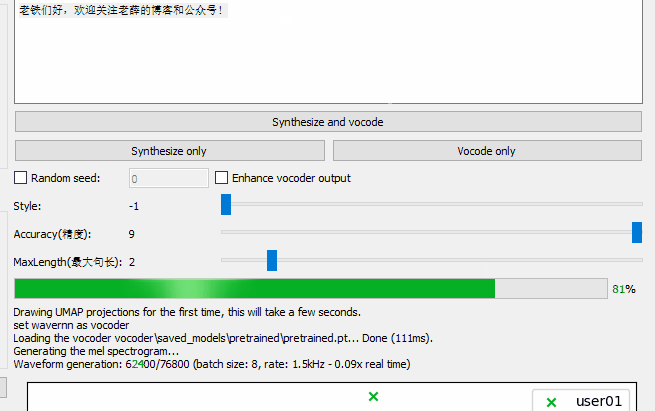
输入和输出的音频都可以在下拉框选择,而且可以点击replay、export进行播放、导出生成的语音

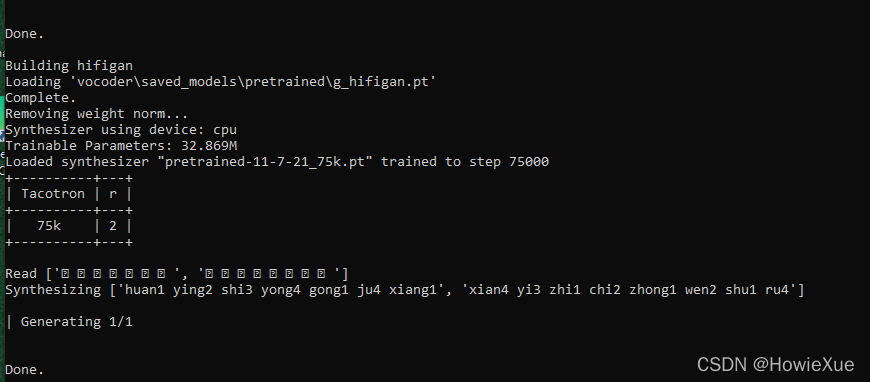
合成过程可以看到log:

5. 效果优化
如果输出的声音效果不好,比如电音严重,可以尝试下面方式优化
- 使用更精确的Synthesize model ,或利用数据集迁移学习继续训练
- 将vocoder从hifiGAN切换到pretrained 或wavernn_pretrained:
- 优化输入录音,比如提升说话清晰度、减少噪音、保持语调等。
通过查看mel spectrogram梅尔频谱图,就可有看到语音合成的效果:
好的频谱图纹理清晰,间隔分明(和真实语音匹配度高),例如下面就是好的频谱图


而差的频谱图就相反,例如:


**小技巧:**在使用中,可以先使用Synthesize ,查看梅尔图,如果效果好,再进行Vocode
如果想自己找数据集使用train.py训练,可以参考:
https://vaj2fgg8yn.feishu.cn/docs/doccn7kAbr3SJz0KM0SIDJ0Xnhd
支持的数据集有:
- aidatatang_200zh :http://www.openslr.org/62/
- magicdata:http://www.openslr.org/68/
- aishell3:http://www.openslr.org/93/
没有GPU的话Training需谨慎。
调优技巧可参考:https://zhuanlan.zhihu.com/p/425692267
6. 结论:
在不重新训练Model的情况下,直接运用MockingBird算法,只依靠十几秒左右的录音,虽然可以合成比较“相似”的声音,但听起来和原音还是有所区别,熟悉的人还是能够很快听出来。
- 生成的声音与正常人声高度相似,调试好的话,基本上听不出来是AI合成声音
我听起来合成的就是一个正常人的声音,感觉起码比那些骚扰电话的AI机器声音 要好很多
- 合成速度够快,仅需10秒左右的原音,输出上来讲,5s左右即可生成任意话术的语音,而且普通话比较标准,
普通话不好的(像我这种),在制作视频/语音讲解的时候,可以考虑使用这个生成语音解说,比自己录的效果要好。。
- 如果收集到一个人的足够多的声音数据,重新针对性的训练Mocking Bird,利用MockingBird是可以合成极高相似度的声音的,足以让人“耳听不实”。
但这样的训练/调参/声音数据处理,就不是简单就可以实现的了,而且MockingBird作者使用的aidatatang_200zh、magicdata、aishell3数据集,是目前最大的三个开源中文语音训练数据集,目前来看也比较全面了
所以简单操作,还是骗不过亲人们的
下面有机会Howie可以深入研究解读下MockingBird和Real-Time-Voice-Cloning的源码,这里面的东西非常多,并且很多是当前语音领域先进的理论/技术的工程应用。。。

博主热门文章推荐:
一篇读懂系列:
- 一篇读懂无线充电技术(附方案选型及原理分析)
- 一篇读懂:Android/iOS手机如何通过音频接口(耳机孔)与外设通信
- 一篇读懂:Android手机如何通过USB接口与外设通信(附原理分析及方案选型)
LoRa Mesh系列:
- LoRa学习:LoRa关键参数(扩频因子,编码率,带宽)的设定及解释
- LoRa学习:信道占用检测原理(CAD)
- LoRa/FSK 无线频谱波形分析(频谱分析仪测试LoRa/FSK带宽、功率、频率误差等)
网络安全系列:
- ATECC508A芯片开发笔记(一):初识加密芯片
- SHA/HMAC/AES-CBC/CTR 算法执行效率及RAM消耗 测试结果
- 常见加密/签名/哈希算法性能比较 (多平台 AES/DES, DH, ECDSA, RSA等)
- AES加解密效率测试(纯软件AES128/256)–以嵌入式Cortex-M0与M3 平台为例
嵌入式开发系列:
- 嵌入式学习中较好的练手项目和课题整理(附代码资料、学习视频和嵌入式学习规划)
- IAR调试使用技巧汇总:数据断点、CallStack、设置堆栈、查看栈使用和栈深度、Memory、Set Next Statement等
- Linux内核编译配置(Menuconfig)、制作文件系统 详细步骤
- Android底层调用C代码(JNI实现)
- 树莓派到手第一步:上电启动、安装中文字体、虚拟键盘、开启SSH等
- Android/Linux设备有线&无线 双网共存(同时上内、外网)
AI / 机器学习系列:
- AI: 机器学习必须懂的几个术语:Lable、Feature、Model…
- AI:卷积神经网络CNN 解决过拟合的方法 (Overcome Overfitting)
- AI: 什么是机器学习的数据清洗(Data Cleaning)
- AI: 机器学习的模型是如何训练的?(在试错中学习)
- 数据可视化:TensorboardX安装及使用(安装测试+实例演示)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)