目录
1. 连续型变量统计描述
单变量统计描述
1.summary函数
2.psych包中的describe()函数
3.Hmisc包中的describe()函数
4.pastecs包的stat.desc()的函数
分组统计描述
1.doBy包的summaryBy函数(重点学习)
2.函数aggregate()
2.分类变量统计描述
3.基线表格快速绘制
(1)临床资料基线表基本概念和统计方法
(2)绘制基线表实操
1. 连续型变量统计描述
单变量统计描述
1.summary函数
使用
summary
()
函数来获取描述性统计量
(连续&分类变量)
最大值
,
最小值
,
四分位数
和数值型变量的
均值
以及因子向量和逻辑向量的
频数
统计
summary(mtcars$mpg)

优势:
同时可以处理几个变量
的计算
myvars <- c("mpg","hp","wt")
summary(mtcars[myvars])

2.psych包中的describe()函数
可以计算
非缺失值
的数量,
平均数
,
标准差
,
中位数
,
截尾均值
,
绝对中位差
,
最小值
,
最大值
,
值域
,偏度,峰度和平均值的标准误差
library(psych)
describe(mtcars$mpg)
describe(mtcars[myvars]) #也可以同时处理多个变量

3.Hmisc包中的describe()函数
Hmisc包中的describe()函数可返回变量和
观测的数量
、
缺失值
和
唯一值的数目
、Info(关于变量的连续性的统计量),
平均值
、Gmd(基尼均差),
分位数
,以及五个
最大的值
和五个
最小的值
。
library(Hmisc)
Hmisc::describe(mtcars$mpg)
Hmisc::describe(mtcars[myvars]) #也可以同时处理多个变量

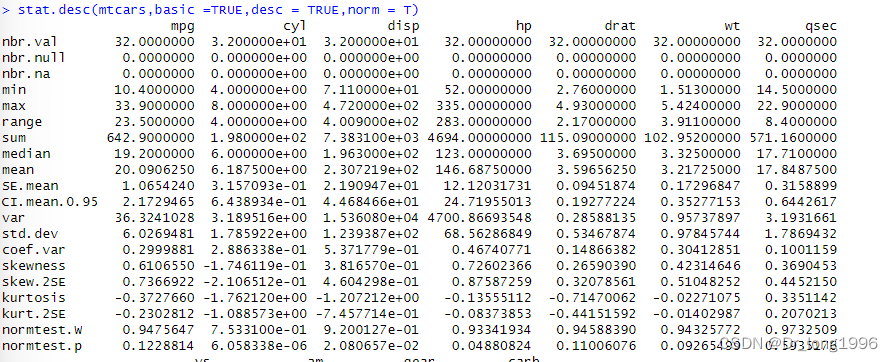
4.pastecs包的stat.desc()的函数
pastecs包中有一个名为stat.desc()的函数,它可以计算种类繁多的描述性统计量。
#install.packages("pastecs")
library(pastecs)
stat.desc(mtcars,basic =TRUE,desc = TRUE,norm = T,p=0.95)
(1)其中的data是一个数据框。
若basic=TRUE(默认值),则计算其中所有值、空值、缺失值的数量,以及最小值、最大值、值域,还有总和。
(2)若desc=TRUE(同样也是默认值),则计算中位数、平均数、平均数的标准误、平均数置信度为95%的置信区间、方差、标准差以及变异系数。
(3)若norm=TRUE(不是默认的),则返回正态分布统计量,包括偏度和峰度(以及它们的统计显著程度)和Shapiro–Wilk正态检验结果。这里使用了p值来计算平均数的置信区间(默认置信度为0.95)
分组统计描述
1.doBy包的summaryBy函数(重点学习)
其格式如下:
summaryBy(var1 + var2 + var3 ~ groupvar1 + groupvar2,data= ?, id=NULL,FUN= ?)
library(doBy)
summaryBy(mpg+wt+qsec~vs,data=mtcars,id=NULL,mean)
summaryBy(mpg+wt+qsec~vs+am,data=mtcars,id=NULL,mean)
~前面为需要计算的连续型变量,~后面为需要分组的分组变量,FUN=需要计算的统计量

还可以通过自定义FUN的内容来扩充每次的计算统计量。如下,
fun1 <- function(x){
c(m=mean(x, na.rm=T), v=var(x, na.rm=T),q=quantile(x, na.rm=T), md = median(x, na.rm=T) ,l=length(x),sd = sd(x,na.rm = T))
}
summaryBy(mpg+wt+qsec~vs,data=mtcars,id=NULL,FUN=fun1)

aggregate(mtcars[myvars],by=list(am=mtcars$am),mean)
am mpg hp wt
1 0 17.14737 160.2632 3.768895
2 1 24.39231 126.8462 2.411000
2.分类变量统计描述
参考链接内容
5.基本统计方法-分类变量的组间比较_分类变量统计方法-CSDN博客
3.基线表格快速绘制
(1)临床资料基线表基本概念和统计方法
临床资料基线表(Clinical Data Baseline Table)是一种常用于临床研究和流行病学研究中的数据表格。
它是研究的起点,通常在开始进行研究时收集和记录的数据。这些数据用于描述研究参与者在研究开始前的初始状态和特征,这个初始状态被称为“基线”。
基线表通常包含以下信息:
-
人口学特征:
参与者的年龄、性别、种族等基本特征;
-
临床特征:
包括参与者的疾病状态、症状和既往病史等;
-
生活方式和行为习惯:
如吸烟史、饮酒习惯、运动频率等;
-
生理测量值:
如身高、体重、血压、生化指标等;
-
疾病评估量表:
用于评估研究参与者的疾病严重程度和症状;
临床资料基线表的描述性统计方法
在绘制临床资料基线表时,可以使用不同的描述性统计方法来总结不同类型的变量。以下是针对常见变量类型的描述性统计推荐方法:
-
连续型变量:
连续型变量是指可以取无限个值的变量,如年龄、体重、血压等。
对于连续型变量,通常使用以下描述性统计:
- 平均值(Mean):
反映变量的中心位置;
- 标准差(Standard Deviation):
反映变量的离散程度;
- 中位数(Median):
中间值,将数据分为两等份;
- 最小值(Minimum)和最大值(Maximum):
描述数据的范围;
- 四分位数(Quartiles):
分为四等份,有25%、50%、75%等。
-
分类型变量:
分类型变量是指只能取有限个离散值的变量,如性别、种族、病情等级等。
对于分类型变量,通常使用以下描述性统计:
- 计数(Count):
各类别出现的次数。
- 百分比(Percentage):
各类别在总样本中所占的比例。
- 众数(Mode):
出现频率最高的类别。
-
有序型变量:
有序型变量是指有一定顺序或等级的变量,但差值不具有数值意义,如疼痛程度等级、教育水平等。
对于有序型变量,可以使用以下描述性统计:
- 中位数(Median):
反映中间值,有序变量的特点是中位数有实际意义。
- 百分位数(Percentiles):
反映数据在有序序列中的位置。
-
二分类变量:
二分类变量是一种特殊的分类型变量,只有两个类别,如是否患病、是否接受治疗等。对于二分类变量,可以使用以下描述性统计:
- 计数(Count):
各类别出现的次数。
- 百分比(Percentage):
各类别在总样本中所占的比例。
绘制临床资料基线表展示组间比较的p值时该如何选择合适的方法呢?
-
连续性变量且符合正态分布、方差齐性:
如果两组数据都是连续性变量,并且符合正态分布且方差齐性,可以选择使用
Student's t-test(独立样本t检验)
。如果有多组间比较,可以使用
方差分析(ANOVA)
,并结合
事后多重比较方法(如Tukey's HSD test)
。
-
连续性变量但不符合正态分布、方差齐性:
如果两组数据都是连续性变量,但不满足正态分布和方差齐性的要求,可以考虑使用非参数检验**,如
Mann-Whitney U检验(Wilcoxon秩和检验)
。对于多组间比较,可以使用
Kruskal-Wallis H检验
,并结合适当的多重比较方法。
-
分类变量:
如果需要比较的是分类变量,如两组间的比例差异,可以使用
卡方检验(χ²检验)
。若分类变量有多个水平,可以使用
Fisher's精确检验
或
拟合优度检验
,并结合多重比较方法。
-
多个连续性变量:
如果需要同时比较多个连续性变量,可以使用
多重回归分析
或
方差分析
。在这种情况下,可以绘制出适当的多个p值,或者使用
Bonferroni校正
来控制多重比较的错误率。

在展示p值时,通常会标明明确的检验方法和显著性水平(例如,p < 0.05),以表明组间差异是否具有统计学意义。另外,为了更全面地理解结果,也可以同时提供置信区间等统计信息。
(2)绘制基线表实操
基线表格示例:

实操:
R语言
tableon
e包绘制临床资料基线表
示例:
使用梅奥诊所原发性胆汁性肝硬化数据集进行演示:
1.加载数据
## 加载梅奥诊所原发性胆汁性肝硬化数据
library(survival)
data(pbc)
## 检查变量
head(pbc)

2. 将分类变量转换为因子变量
## 将分类变量转换为因子变量
varsToFactor <- c("status", "trt", "ascites", "hepato", "spiders", "edema", "stage")
pbc[varsToFactor] <- lapply(pbc[varsToFactor], factor)
03 创建变量列表
## 创建变量列表
dput(names(pbc))
vars <- c("time", "status", "age", "sex", "ascites", "hepato",
"spiders", "edema", "bili", "chol", "albumin",
"copper", "alk.phos", "ast", "trig", "platelet",
"protime", "stage")
04 根据治疗组(trt)创建Table 1
## 根据治疗组(trt)创建Table 1
tableOne <- CreateTableOne(vars = vars, strata = c("trt"), data = pbc)
## 只需输入对象名称,将调用print.TableOne方法
tableOne

`CreateTableOne()`函数用于创建汇总表,用于比较不同组之间的基线特征。
它有多个参数,每个参数的含义和设置方法:
CreateTableOne(
vars,
strata,
data,
factorVars,
includeNA = FALSE,
test = TRUE,
testApprox = chisq.test,
argsApprox = list(correct = TRUE),
testExact = fisher.test,
argsExact = list(workspace = 2 * 10^5),
testNormal = oneway.test,
argsNormal = list(var.equal = TRUE),
testNonNormal = kruskal.test,
argsNonNormal = list(NULL),
smd = TRUE,
addOverall = FALSE
)
1. vars:
要汇总的变量,以字符向量的形式提供。
因子变量将被视为分类变量,数值变量将被视为连续变量。
如果为空,则使用数据集中的所有变量。
2. strata:
分层(分组)变量的名称,以字符向量的形式提供。
如果省略,则返回总体结果而不进行分层。
3. data:
存放变量的数据框。
所有变量(包括vars和strata中的变量)都必须在这个数据框中。
4. factorVars:
要被视为分类变量的数值变量,以字符向量的形式提供。
不包括因子变量,除非需要通过删除空的水平来重新设置它们的水平。如果省略,只有因子变量被视为分类变量。在vars参数中指定的变量也必须在factorVars参数中指定。
5. includeNA:
逻辑值,如果为TRUE,则将缺失值视为常规因子水平,而不是缺失值。
在汇总表中,缺失值将显示为分类变量的最后一个水平。仅对分类变量有效。
6. test:
逻辑值,如果为TRUE,并且存在多个组,则进行组间比较。
7. testApprox:
指定进行大样本近似检验的函数。
默认为chisq.test,不推荐在某些单元格具有小计数(少于5)的情况下使用。
8. argsApprox:
一个带有参数名称的列表,传递给testApprox函数。
默认值为list(correct = TRUE),这对于chisq.test开启连续性校正。
9. testExact:
指定进行精确检验的函数。
默认为fisher.test。如果单元格具有大量数据,可能会由于内存限制而失败。在这种情况下,应该使用基于大样本近似的方法。
10. argsExact:
一个带有参数名称的列表,传递给testExact函数。
默认值为list(workspace = 2*10^5),指定为fisher.test分配的内存空间。
11. testNormal:
指定进行基于正态假设的检验的函数。
默认为oneway.test,当只有两个组时,它等同于t检验。
12. argsNormal:
一个带有参数名称的列表,传递给testNormal函数。
默认值为list(var.equal = TRUE),假定组间方差相等,用于执行普通的方差分析(ANOVA)。
13. testNonNormal:
指定执行非参数检验的函数。
默认为kruskal.test(Kruskal-Wallis秩和检验)。当只有两个组时,它等同于wilcox.test(Mann-Whitney U检验)。
14. argsNonNormal:
一个带有参数名称的列表,传递给testNonNormal函数。
默认值为list(NULL),仅用作占位符。
15. smd:
逻辑值,如果为TRUE,并且存在多个组,则计算所有两两比较的标准化均值差(Standardized Mean Difference)。
16. addOverall:
逻辑值,只在提供strata时使用。如果为TRUE,则在汇总表中添加一个总体列。
标准化均值差和p值的计算仅基于分层列。
05 指定非正态变量
## 指定非正态变量将适当地显示变量,并显示非参数检验的p值。在exact参数中指定变量以获取精确的检验p值。cramVars可用于显示二级分类变量的两个水平。
print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"),
exact = c("status", "stage"), cramVars = "hepato", smd = TRUE)

06 详细总结
## 使用summary.TableOne方法进行详细总结
summary(tableOne)
07 查看
## 只使用$操作符查看分类部分
tableOne$CatTable
summary(tableOne$CatTable)
## 只使用$操作符查看连续部分
tableOne$ContTable
summary(tableOne$ContTable)
导出到excel和word
导出到excel
## 如果您的工作流程包括在撰写稿件时复制到Excel和Word中,您可能会受益于quote参数。这将引用所有内容,以免Excel搞乱了单元格。
# 方法1
tab1Mat <- print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"),
exact = c("status", "stage"), quote = TRUE)
write.csv(tab1Mat, file = "Result1_Table1.csv")
# 方法2
print(tableOne, formatOptions = list(big.mark = ","))
tab1Mat2 <- print(tableOne, showAllLevels = TRUE, quote = FALSE, noSpaces = TRUE, printToggle = FALSE)
write.csv(tab1Mat2, file = "Result2_Table1.csv")
导出到word
## 如果您希望在Word中居中对齐值,请使用noSpaces选项。
print(tableOne, nonnormal = c("bili", "chol", "copper", "alk.phos", "trig"),
exact = c("status", "stage"), quote = TRUE, noSpaces = TRUE)