前言
NeurIPS2023《OpenMask3D:Open-Vocabulary 3D Instance Segmentation》
论文地址:
https://openmask3d.github.io/static/pdf/openmask3d.pdf
https://openmask3d.github.io/?utm_source=catalyzex.com
https://blog.csdn.net/Yong_Qi2015/article/details/134410955
https://www.bilibili.com/video/BV1j
图 1
目前看到的大部分关于这个工作的介绍叫“开放词汇3D实例分割”,实例上这个工作里面是直接用 Mask3D 所训好的实例分割模型来做实例分割的,这个工作的重点个人认为是怎么把这些分割结果和那些文本描述建立联系,所以我这里的标题叫“三维场景特殊点云分割”,来跟 Mask3D 这类重点做实例分割。
关于 Mask3D 的内容可以看我的另一篇文章:
【论文阅读】【3D场景点云分割】Mask3D: Mask Transformer for 3D Semantic Instance Segmentation-CSDN博客
论文十问
Q1论文试图解决什么问题?
表面上是开放词汇三维实例分割,实际上是三维场景的实例(已分割好)如何更好地与文本描述相关联。
Q2这是否是一个新的问题?
目前我了解到这算是一个新问题。
Q3这篇文章要验证一个什么科学假设?
有三维实例对应高质量的二维 mask 就可以建立起三维实例和文本描述之间的大致对应关系。
出发点
开放词汇三维实例分割任务:输入一个实例描述,即可定位到场景里与这个文本描述最相关的实例。之前的工作是基于三维点的特征。这个工作是基于实例特征,更侧重于实例级别的任务。
贡献
我们引入开放词汇 3D 实例分割任务,其中识别与给定文本查询相似的对象实例
我们提出了 OpenMask3D,这是第一个以零样本方式执行开放词汇 3D 实例分割的方法
我们进行实验以提供有关设计选择的见解,这对于开发开放词汇 3D 实例分割模型非常重要
核心(一句话总结)
输入三维场景,对每个分割好的实例,选出较好的 2d 视图,sam分割得到 2d 图像掩码并进行裁剪,送入 clip 模型,以此得到每个 3d 实例对应的 clip 空间特征,作为桥梁联通了三维实例和文本query,这样就可以输入文本来查询三维场景对应的实例。
文章解读(创新点对应的方法细节)
1. 摘要
我们介绍了开放词汇 3D 实例分割的任务。当前的 3D 实例分割方法通常只能从训练数据集中注释的预定义封闭类集中识别对象类别。这导致现实世界的应用程序受到严重限制,在现实世界的应用程序中,人们可能需要执行由与各种对象相关的新颖的开放词汇查询引导的任务。最近,出现了开放词汇 3D 场景理解方法,通过学习场景中每个点的可查询特征来解决这个问题。虽然这种表示可以直接用于执行语义分割,但现有方法无法分离多个对象实例。在这项工作中,我们解决了这一限制,并提出了 OpenMask3D,这是一种用于开放词汇 3D 实例分割的零样本方法。在预测的与类别无关的 3D 实例掩模的指导下,我们的模型通过基于 CLIP 的图像嵌入的多视图融合来聚合每个掩模的特征。ScanNet200 和 Replica 上的实验和消融研究表明,OpenMask3D 优于其他开放词汇方法,尤其是在长尾分布上。定性实验进一步展示了 OpenMask3D 基于描述几何、可供性和材料的自由格式查询来分割对象属性的能力。
2. 方法
图 2
OpenMask3D 模型如图 2 所示。给定场景中捕获的一组 RGB-D 图像以及重建的场景点云 ①OpenMask3D 可以预测 3D 实例掩模及其关联的每个掩模特征表示,这可以用于基于开放词汇概念的实例查询 ④我们的 OpenMask3D 有两个主要构建块:②类不可知掩码提议头和③掩码特征计算模块 。与类无关的掩码提议头预测点云中点的二进制实例掩码。掩模特征计算模块利用预先训练的 CLIP 视觉语言模型来计算每个掩模的有意义且灵活的特征。对于每个建议的实例掩模,掩模特征计算模块首先选择3D对象实例高度可见的视图。随后,在每个选定的视图中,该模块计算由 3D 实例掩模的投影引导的 2D 分割掩模,并使用 SAM 模型细化 2D 掩模。接下来,采用 CLIP 编码器来获得包围计算出的 2D 掩模的多尺度图像裁剪的图像嵌入。然后将这些图像级嵌入在选定的帧中聚合,以获得掩模特征表示。
本方法的关键新颖之处在于它遵循面向实例掩码的方法,这与通常计算单点特征的现有 3D 开放词汇场景理解模型相反。面向点特征的模型具有固有的局限性,特别是在识别对象实例方面。模型旨在通过引入一个框架来克服此类限制,该框架采用与类无关的实例掩码并聚合每个对象实例的信息特征。
本方法将室内场景中捕获的 RGB-D 图像集合以及场景的重建点云表示作为输入(假设已知相机参数)。
2.1 与类别无关的掩码提案
方法的第一步涉及生成 M 个与类别无关的 3D 掩模建议。获取到实例分割的预测结果(只有二进制实例掩码,无语义信息)
“这里作者直接用训练完的Mask3D 方法来进行实例分割预测”
2.2 掩模特征计算模块
掩模特征计算模块旨在为从与类无关的掩模提议模块获得的每个预测实例掩模计算与任务无关的特征表示。该模块的目的是计算可用于查询开放词汇概念的特征表示。由于本方法打算利用 CLIP 文本图像嵌入空间并最大限度地保留有关长尾或新颖概念的信息,因此本方法仅依靠 CLIP 视觉编码器来提取图像特征,并在此基础上构建掩模特征。
“作者这里的意思就是想获取一个表征实例的桥梁特征,在三维实例和文本之间建立联系”。
掩模特征计算模块由几个步骤组成: (1)每个实例掩码建议,本方法首先计算 RGB-D 序列的每个帧中对象实例的可见性,并选择具有最大可见性的前 k 个视图; (2)计算每个选定帧中的 2D 对象掩模,然后使用该掩模获得多尺度图像裁剪,以提取有效的 CLIP 特征; (3)图像裁剪通过 CLIP 视觉编码器,以获得对每个裁剪和每个选定视图进行平均池化的特征向量,从而得到最终的掩模特征表示
图 3
2.2.1 图像选择
获取所提出的对象实例的代表性图像对于提取准确的 CLIP 特征至关重要。为了实现这一目标,本方法设计了一种策略,为 M 个预测实例中的每一个选择有代表性的子集图片(图 3,a),然后从中提取 CLIP 特征。特别是,本方法设计的策略根据每个视图 j 中每个掩模
“出现这个实例的每一帧里面,算一个这个视角下的此实例的可见3d点数目,越多越好,除以这些帧的最大值就得到一个0-1的值,代表分数”。
分数 top k的图片就是要选的图片。
2.2.2 2D 掩模计算和多尺度裁剪
本节将解释基于上一步中选择的帧计算 CLIP 特征的方法 给定掩模的选定帧,我们的目标是找到从中提取特征的最佳图像裁剪,如图 3b 所示。简单地考虑掩模的所有投影点通常会导致边界框不精确且有噪声,很大程度上受到异常值的影响。 为了解决这个问题,我们使用与类别无关的 2D 分割模型 SAM,它可以输入一组点然后预测得到 2D 掩模以及掩模置信度得分。
SAM 对输入点集敏感。因此,为了从 SAM 获得具有高置信度分数的高质量掩模,作者从 RANSAC 算法中获得灵感,并按照算法 1 中所述进行操作。
算法 1
从投影点中采样
“就是重复多次 sam,选出最高得分的,本质上这里没有更大的优化”。
接下来,我们使用生成的掩模 m2D * 生成所选图像的 L = 3 多级裁剪。这使我们能够通过融入更多来自周围环境的上下文信息来丰富功能。
“3个等级大小的裁剪,就像图 3b 里面中间那 3 张图,对应显示器的 3 种裁剪图”。
2.2.3 CLIP 特征提取和掩模特征聚合
对于每个实例掩码,我们通过选择 top-k 视图并获得 L 多级裁剪来收集 k × L 图像,然后将收集到的图像裁剪通过 CLIP 视觉编码器,以提取 CLIP 嵌入空间中的图像特征,如图 3c 所示。 然后,我们聚合从与给定实例掩模相对应的每个裁剪中获得的特征,以获得平均每个掩模 CLIP 特征(图 3d)。计算出的特征与任务无关,并且可以通过使用我们用于编码图像的相同 CLIP 模型对给定文本或基于图像的查询进行编码,用于各种基于实例的任务。
“这里终于完成了终极目的,得到代表实例的特征”。
3. 实验结果
因为 OpenScene 只生成每点特征向量(没有基于实例的聚合),不太好直接和本方法比较。因此作者对每个实例掩码中的点特征进行平均扩展,来更新 OpenScene,和本方法比较。
语义类别分配说明
本方法并不直接预测每个实例掩码的语义类别标签。而是为每个实例计算与任务无关的特征向量,该向量可用于执行语义标签分配。 就是 CLIP 模型为每个语义类语句“场景中的{}”计算文本嵌入特征,然后本方法的实例特征和其之间算相似度,来判断此实例是哪个语义。
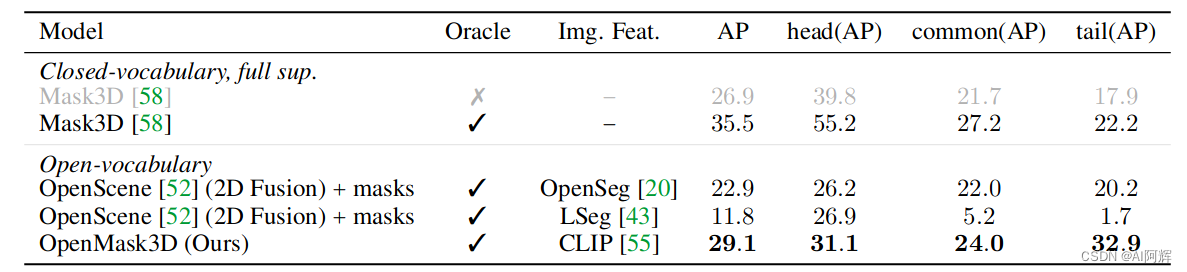
3D封闭词汇实例分割结果
在 ScanNet200 和 Replica 数据集上定量评估封闭词汇实例分割任务方法。表中提供了封闭词汇表实例分割结果。
虽然这种差距对于头部类别和普通类别来说更为突出,但对于尾部类别来说差异不太明显。这一结果是预期的,因为 Mask3D 受益于使用来自 ScanNet200 数据集的封闭类标签集的完全监督。这里和 OpenScene 的对比结果表明了该方法的优秀。 以实例为中心的方法 OpenMask3D 是专为开放词汇 3D 实例分割任务而设计的,与其他采用点中心特征表示的开放词汇方法相比,表现出更强的性能。图 5 还说明了特征表示之间的差异。
“OpenMask3d 用的是 Mask3D给的实例结果,但是语义结果是前面<语义类别分配说明>那里提到的,通过 clip 特征来关联得到的,而Mask 3D 是直接预测出实例的语义结果,所以上面的指标结果有差异”。
开放词汇的泛化能力
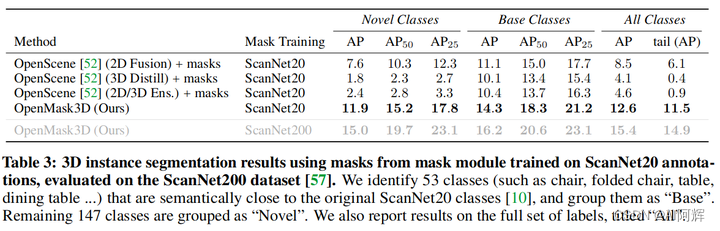
我们的目标是研究我们的方法在训练过程中所看到的类别之外的数据上的泛化效果。另外,我们的目标是分析我们的方法对分布外(OOD)数据的推广效果如何,例如来自另一个数据集 Replica 的场景。为了证明我们方法的泛化能力,我们进行了一系列实验。首先,当我们使用在 20 个原始 ScanNet 类上训练的掩模预测器中的与类无关的掩模时,我们分析了模型的性能,并在 ScanNet200 数据集上进行评估。为了评估我们的模型在“看不见的”类别上的表现,我们将 ScanNet200 标签分为两个子集:基础类和新颖类。
没见过的类别
我们确定了在语义上与原始 ScanNet20 类别相似的 ScanNet200 类别(例如椅子和折叠椅、桌子和餐桌),从而产生了 53 个类别。我们将与 ScanNet20 中任何类都不相似的所有剩余对象类分组为“新颖”。报告已见(“基础”)类、未见(“新”)类和所有类的结果:
没见过的数据
在第二个实验中,作者使用在 ScanNet200 上训练的掩模预测器来评估 OpenMask3D 对来自 Replica 的数据的性能。
该实验的结果如表 2 所示,表明 OpenMask3D 确实可以泛化到未见过的类别以及 OOD 数据。 OpenMask3D 使用在较小的对象集上训练的掩模预测器模块,似乎在泛化到各种设置方面表现得相当好。
消融实验
多尺度裁剪和 2D SAM
这个实验的目的是为了证明获得给定对象实例的更准确图像裁剪,可以获得更高的性能。
假如实例 mask 更准确
Oracle 代表的是拿 gt mask 代替预测的实例(Mask3d 里面这些实例的语义结果是拿其本来预测最匹配的实例的语义来选定的) 结果在长尾类别上的结果,本方法还超过了 Mask3d。
“OpenMask3d 的特征计算方法是没有接受任何额外数据的训练”。
定性结果
本方法能对常见分割数据集中可能不存在的给定查询对象进行分割,此外,其还可以成功识别颜色、纹理、情景上下文等对象属性。
“因为 OpenMask3d 对实例提取的特征是 CLIP 编码的,可以和文本关联”。
局限
使用 Oracle 掩模进行的实验表明,3D 掩模提案的质量还有改进的空间,这将在未来的工作中解决。此外,由于每个掩模特征源自图像,因此它们只能对相机平截头体中可见的场景上下文进行编码,缺乏对完整场景以及所有场景元素之间的空间关系的全局理解。最后,系统评估开放词汇能力的评估方法仍然是一个挑战。封闭词汇评估虽然对于初步评估很有价值,但无法揭示所提出模型的开放词汇潜力的真实程度
4. 结论
我们提出了 OpenMask3D,这是第一个开放词汇 3D 实例分割模型,可以在给定任意文本查询的情况下识别 3D 场景中的对象实例。这超出了现有 3D 语义实例分割方法的能力,这些方法通常经过训练以从封闭词汇表中预测类别。借助 OpenMask3D,我们突破了 3D 实例分割的界限。我们的方法能够在描述对象属性(例如语义、几何、可供性、材料属性和情境上下文)的开放词汇查询的指导下,分割给定 3D 场景中的对象实例。凭借其零样本学习功能,OpenMask3D 能够分割给定查询对象的多个实例,这些实例可能不存在于训练封闭词汇表实例分割方法的常见分割数据集中。这为以更全面、更灵活的方式理解 3D 场景并与之交互开辟了新的可能性。我们鼓励研究界探索开放词汇方法,将不同模式的知识无缝整合到一个统一且连贯的空间中。
总结
这个工作对于我们来说还是有一定的启发的:怎么利用好先有的大模型,来完成一个有一定实际意义的任务,这是有一定价值的。