深度学习实验八:对自有图片数据集进行预测标注并可视化预测结果
一、实验目的
1.整理并上传“实验六”自有数据集到“AI识虫比赛”
2.调试并运行YOLOv3模型对自有数据进行目标检测
二、实验环境
python 3.7、PaddlePaddle 2.3.2、GPU A100 40GB
三、实验内容
1.上传自有数据集“poultry”
本数据集提供了100张图片,其中训练集77张,验证集11,测试集12张。包含三种家禽,分别是chicken、duck和goose。包含了图片(.png)和标注(.xml)。
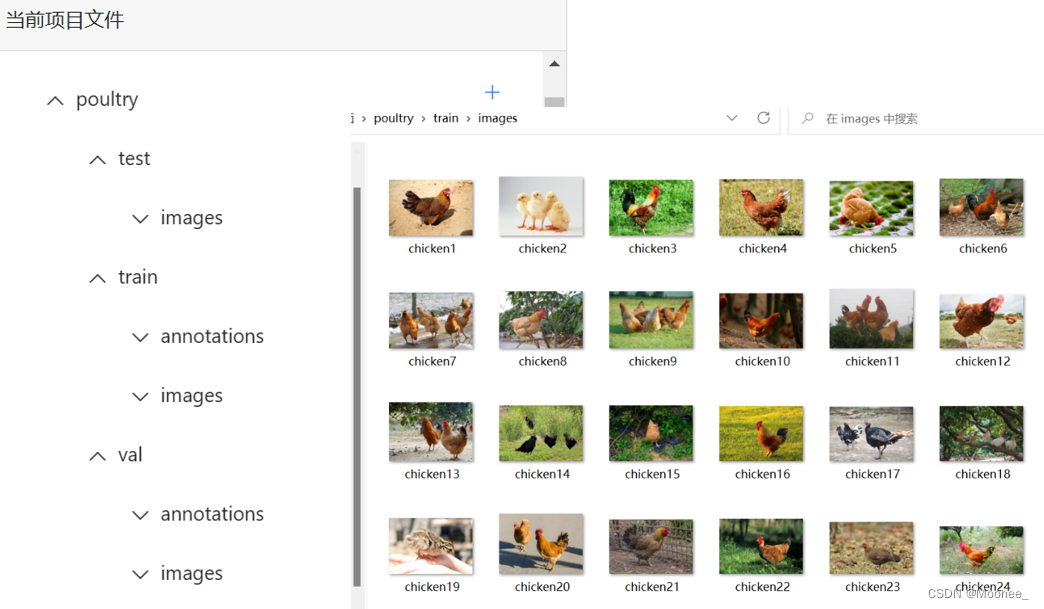
(数据集具体目录结构已在实验六https://blog.csdn.net/Moonee_/article/details/134252184中体现,此处不再赘述。)


解压数据集:
2.启动训练
运行train.py文件:

3.启动评估
4.计算精度指标

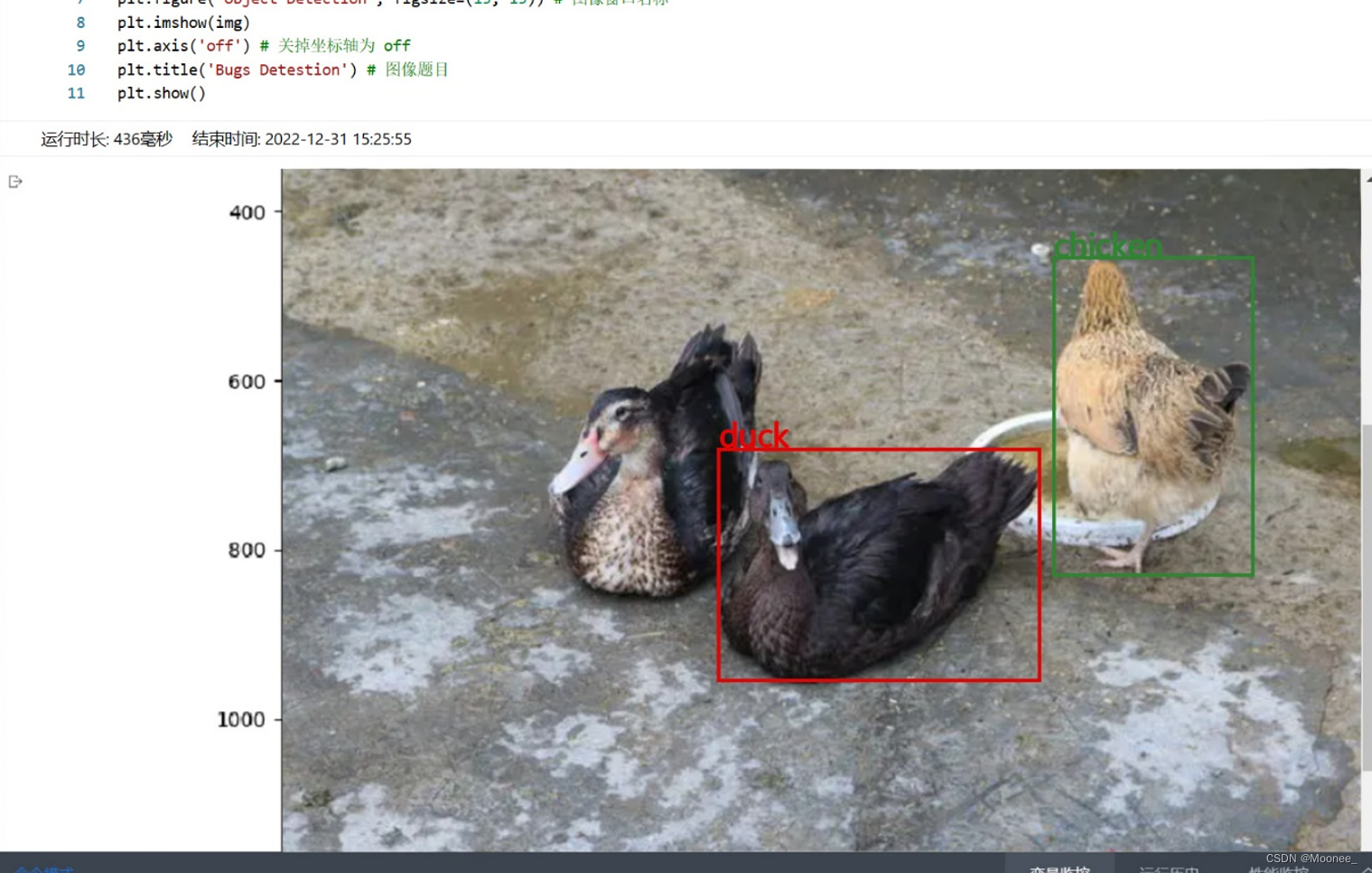
5.预测单张图片并可视化预测结果
四、实验小结
关于训练技巧的总结:
①微调预训练参数
在大型数据集上充分训练过的卷积具有更好的特征提取能力,所以利用预训练迁移可以大大减小训练的时间,使损失下降得更快,同时还能更容易找到最优空间。
②学习率调整策略
学习率的变化决定了网络的优化时间和优化方向,初期网络搜索空间较大,如果学习率过大会导致损失发散,无法收敛到好的极值点。
③标签平滑
标签平滑其实是一种正则化策略,降低网络对标签置信度的依赖,这对有漏标、错标数据具有很好地适应性。
④逐层精调,减少网络搜索空间
网络搜索空间越大,训练时间越久,优化难度越高。因此,通过预训练微调,然后再通过冻结网络层进行精调,可以减小网络的搜索空间,从而降低优化的难度。
⑤数据增广的配合
⑥减小动量
⑦不要忘记验证集
参考内容: https://blog.csdn.net/LittleKlein/article/details/104578627 飞桨AI
Studio - 人工智能学习与实训社区 (baidu.com)