摘要
传统的图卷积网络关注于如何高效的探索不同阶跳数(hops)的邻居节点的信息。但是目前的基于GCN的图网络模型都是构建在固定邻接矩阵上的即实际图的一个拓扑视角。当数据包含噪声或者图不完备时,这种方式会限制模型的表达能力。由于数据的测量或者收集会不可避免的会出现错误,因此基于固定结构的图模型表达能力是不充分的。本文提出了基于注意力机制的多视图图卷积网络,将拓扑结构的多个视图和基于注意力的特征聚合策略引入到图卷积中。MAGCN输入多个可靠的拓扑结构,这些结构一般是对应任务给定的结构或者使用经典图构造方法生成的。这样做更有可能为下游任务生成好的表示。
引言
图神经网络尤其是GCN在图数据上取得了很好的效果但是几乎所有的这些方法都是基于预先给定的一个固定的邻接矩阵的,即一个单一视角的图拓扑结构。由于邻接矩阵和理想的关系矩阵之间存在差异,基于单视图的图模型的表达能力受到限制。举个栗子,在Cora数据集中,节点表示表示文章或者文档,节点之间的边是文章之间的实际引用关系。然而很多情况下,两篇论文a和b可能涉及完全不同的主题,但因为论文a中开发的算法在b中用于特殊应用而产生了引用关系。但是论文a和论文b的关键词属性特征完全不同。如果仅根据这种引用关系(跨类连边)构造的拓扑结构进行邻域特征聚合,会导致两个类别不同的节点特征互相融合,从而导致误分类。这意味着除了给定的邻接矩阵外(基于引用关系),还可能有其他的视角可以更好的表示节点之间的关系,比如论文的关键词属性特征的相似性关系。
如何在给定的若干拓扑结构上执行消息传递便是本文要解决的问题。本文的最初想法是对于给定的任务,理想的图拓扑结构预先是不知道的,当前给定的邻接矩阵只是理想关系矩阵的估计,不可避免的会有一定程度的信息丢失。因此,多个邻接矩阵表示一个图的多个视角肯定更加可靠,因为他们提供了更加可靠的节点关系。
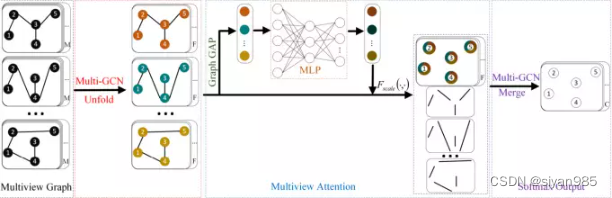
首先,给定多个邻接矩阵表示图结构的不同视角,multi-GCN对每个视图使用一个普通的GCN得到节点在不同视图下的表示。然后使用多图注意力模块自适应的融合多个结点级的表示。节点在不同视图中的注意力权重通过将各个视图的池化向量作为MLP的输入来学习得到。最终,在得到融合后的节点表示后,使用融合模块利用各个视图的拓扑结构为每个节点学习新的表示。
理论分析
-
GCN表达能力的上界分析

-
引入多视图的必要性

通过引入多个增强的视图,可以使视图表达的综合关系更加逼近理想的关系矩阵。
-
GCN与MAGCN的上界分析

定理三表明在给定适当的注意力系数后,MAGCN可以以更高的概率逼近理想误差。
模型结构
Pn表示从隐式的完备空间S’中生成的视图,根据信息论,视图Pn与空间S’包含的信息量S之间的条件互信息大于等于一个正的参数。如下公式表示了在给定其他视图后Pn和S之间共享的贡献信息。
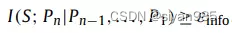
可以看到,每个视图包含了完备空间中的一部分信息,很自然会想到利用多个拓扑结构学习图上的表示。
本文提出的模型主要分为三个模块分别为多视图表示学习模块,多视图融合模块和分类模块。
1)多视图表示学习模块
不同于传统的GCN只能处理单一的视图,Multi-GCN为每个视图设置一个GCN编码器学习不同视图上的表示信息。

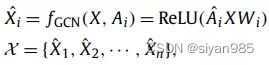
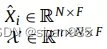
其中Ai表示第i个视图的邻接矩阵,X表示节点的特征矩阵。
2)多图注意力融合模块
在分析不同视图对最终结果的影响时,需要设置权重系数调节各个视图中节点表示的权重。本文采用图池化的方式,对学习到的节点表示采用平均池化的方式为每个视图计算出一个全局的图表示xi。
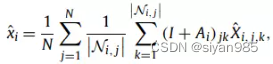
然后将得到的图表示输入到MLP中计算视图级的权重系数C,最后将各个视图的节点表示按照权重进行求和。
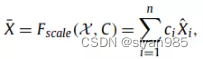
3)分类模块
在得到融合后的节点表示后,需要将节点映射到与节点类别数目一致的维度。本文通过multi-gcn,利用不同的拓扑结构将节点映射到对应类别上。
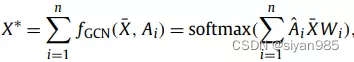
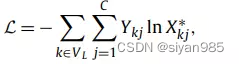
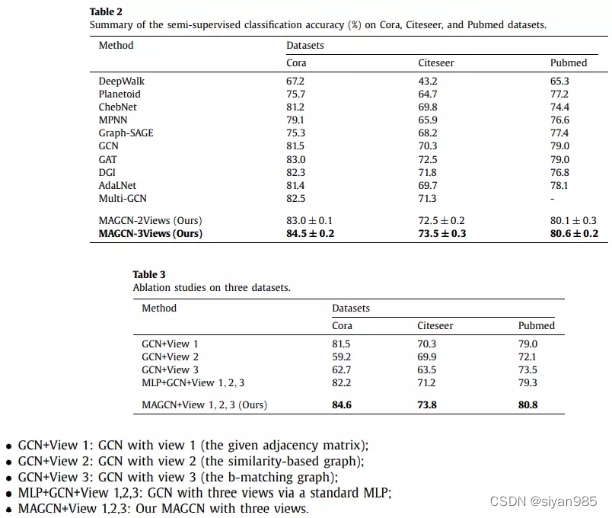
实验
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)