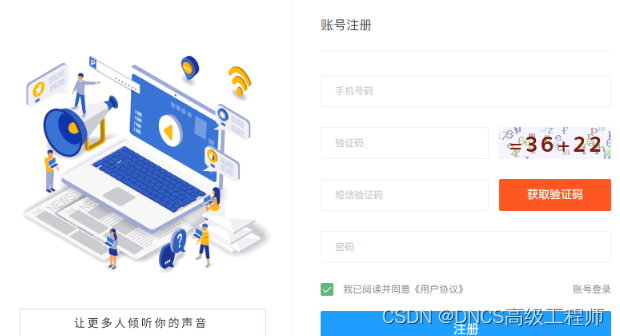
如图,我们在使用python自动化的时候经常会遇到很多各式各样的验证码。这个是一个数字加法的验证码。
干扰项里包含完整的数字、字母信息,普通的OCR识别可能不是很准确。
但是不管怎们样,咱们先把必要的环境搭建起来,试一下Tesseract的识别结果吧。
1、安装Tesseract:
首先需要下载Tesseract的安装包 官方网址:https://digi.bib.uni-mannheim.de/tesseract/,网上的教程很多推荐安装名称里不带dev的正式版,据说更稳定
配置Tesseract:
安装完毕之后需要配置一下环境变量,分为两步:
1、在path里加入安装路径,及安装路径内的tessdata文件夹路径。
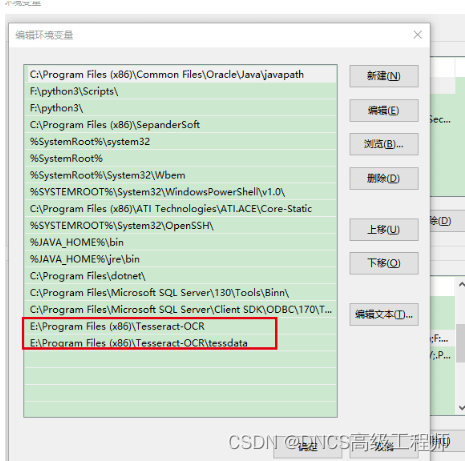
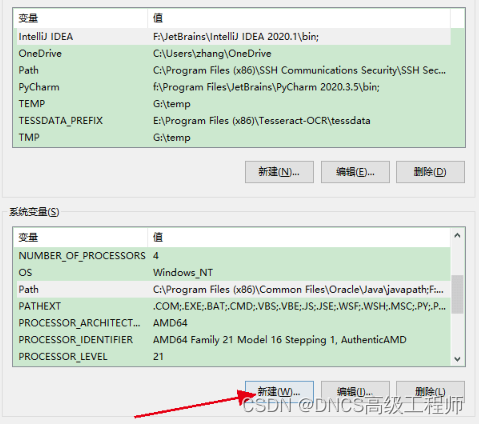
2、新建系统变量{TESSDATA_PREFIX:E:\Program Files (x86)\Tesseract-OCR\tessdata} 这里变量名是固定的TESSDATA_PREFIX,值是刚刚提到的安装路径内下一级tessdata文件夹的完整路径
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)