前言
大家好,我是小哈。
本小节中,我们将学习如何通过 Mybatis Plus 实现 MySQL 批量插入数据。
什么是批量插入?优势在哪里?
先抛出一个问题:假设老板给你下了个任务,向数据库中添加 100 万条数据,并且不能耗时太久!
通常来说,我们向 MySQL 中新增一条记录,SQL 语句类似如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('犬小哈0', 0, 1);
如果你需要添加 100 万条数据,就需要多次执行此语句,这就意味着频繁地与数据库建立链接,必然导致网络 IO 开销巨大,并且每一次数据库执行 SQL 都需要进行解析、优化等操作。
幸运的是,MySQL 支持一条 SQL 语句可以批量插入多条记录,格式如下:
INSERT INTO `t_user` (`name`, `age`, `gender`) VALUES ('犬小哈0', 0, 1), ('犬小哈1', 0, 1), ('犬小哈3', 0, 1);
和常规的 INSERT 语句不同的是,VALUES 支持多条记录,通过 , 逗号隔开。这样,可以实现一次性插入多条记录。
数据量不多的情况下,常规 INSERT 和批量插入性能差距不大,但是,一旦数量级上去后,执行耗时差距就拉开了,在后面我们会实测一下它们之间的耗时对比。
表与实体类
先创建一个测试表 t_user, 执行脚本如下:
DROP TABLE IF EXISTS user; CREATE TABLE `t_user` ( `id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NULL DEFAULT NULL COMMENT '年龄', `gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男', PRIMARY KEY (`id`) ) COMMENT = '用户表';
再定义一个名为 User 实体类:
TIP: @Data 是 Lombok 注解,偷懒用的,加上它即可免写繁杂的 getXXX/setXXX 相关方法,不了解的小伙伴可自行搜索一下如何使用。
Mybatis Plus 伪批量插入
在前面《新增数据》 小节中,我们已经知道了 Mybatis Plus 内部封装的批量插入 savaBatch() 是个假的批量插入,示例代码如下:
List<User> users =new ArrayList<>();
for (int i = 0; i < 5; i++) { User user = new User(); user.setName("犬小哈" + i); user.setAge(i); user.setGender(1); users.add(user); }
通过打印实际执行 SQL , 我们发现还是一条一条的执行 INSERT:
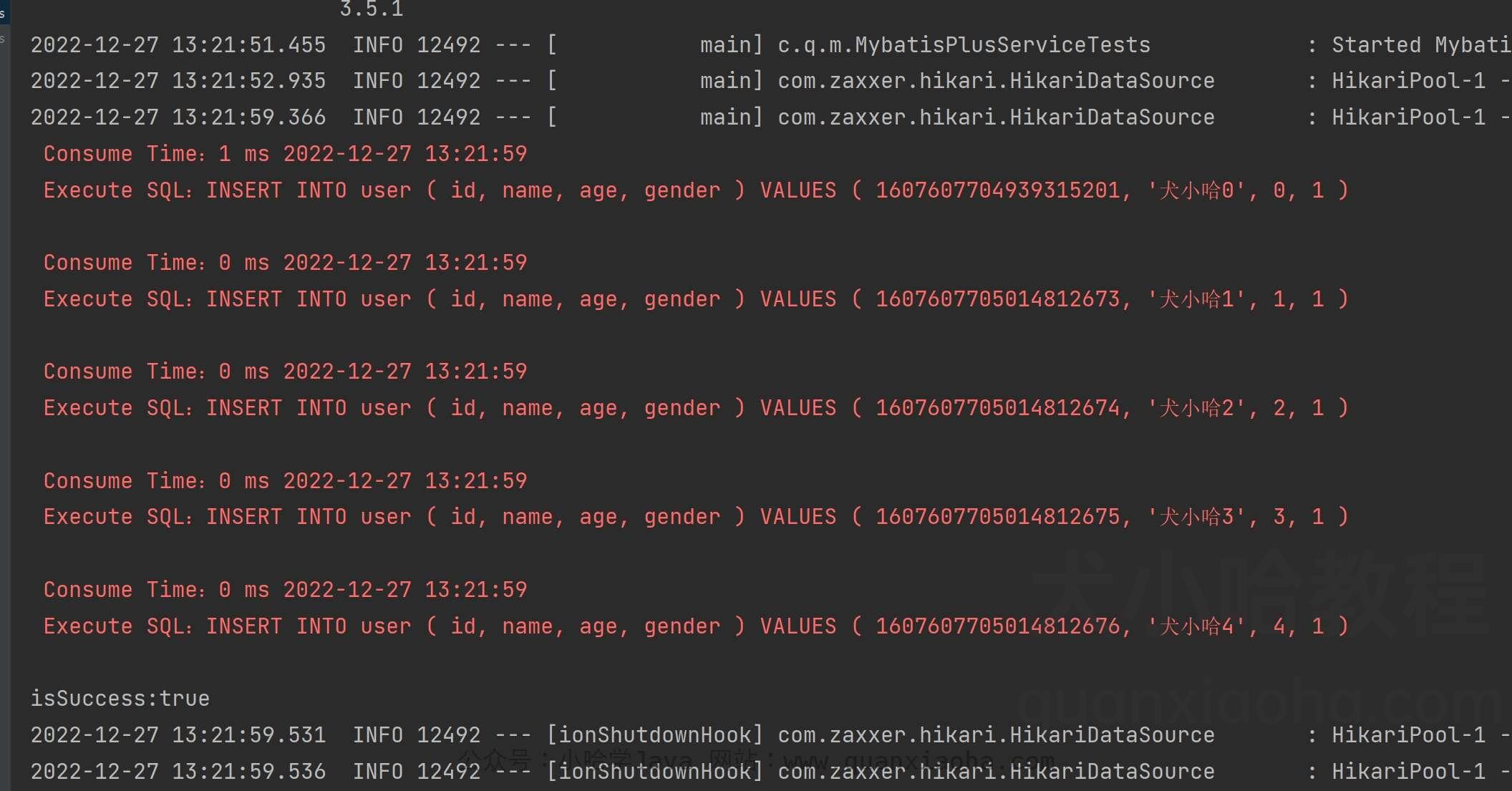
并且还带着大家看了内部实现的源码,这种方式比起自己 for 循环一条一条 INSERT 插入数据性能要更高,原因是在会话这块做了优化,虽然实际执行并不是真的批量插入。
利用 SQL 注入器实现真的批量插入
接下来,小哈就手把手带你通过 Mybatis Plus 框架的 SQL 注入器实现一个真的批量插入。
示例项目结构
先贴一张示例项目的结构:
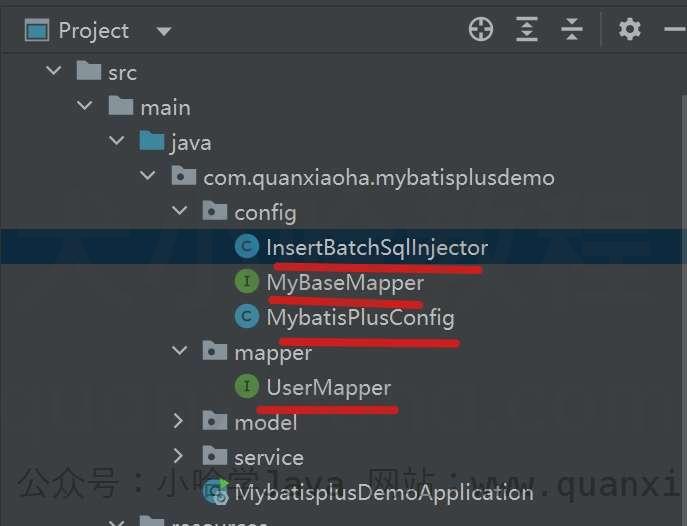
注意看我红线标注的部分,主要关注这 4 个类与接口。
新建批量插入 SQL 注入器
在工程 config 目录下创建一个 SQL 注入器 InsertBatchSqlInjector :
说说 InsertBatchSomeColumn
InsertBatchSomeColumn 是 Mybatis Plus 内部提供的默认批量插入,只不过这个方法作者只在 MySQL 数据测试过,所以没有将它作为通用方法供外部调用,注意看注释:
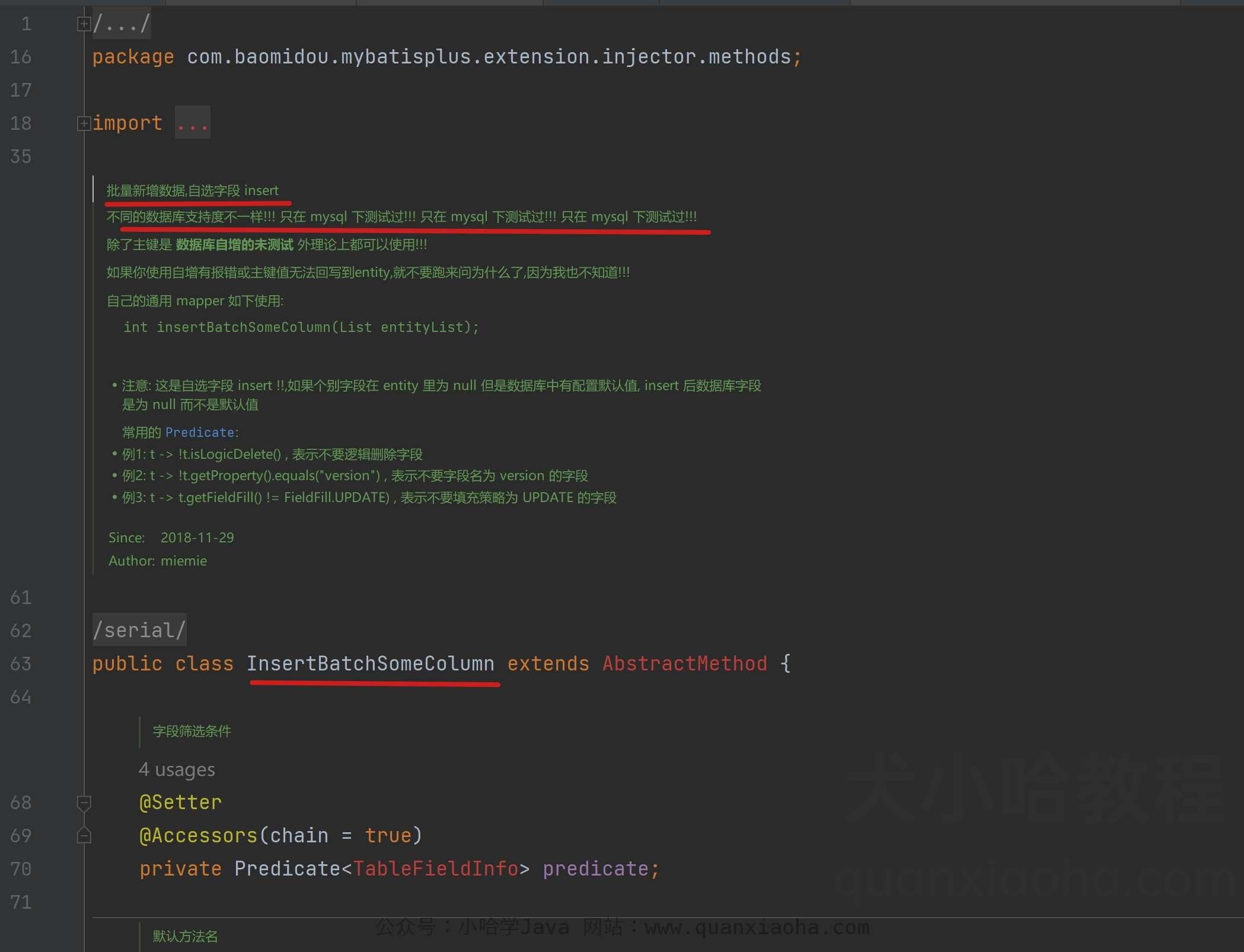
源码复制出来,如下:
配置 SQL 注入器
在 config 包下创建 MybatisPlusConfig 配置类:
新建 MyBaseMapper
在 config 包下创建 MyBaseMapper 接口,让其继承自 Mybatis Plus 提供的 BaseMapper, 并定义批量插入方法:
注意:方法名必须为 insertBatchSomeColumn, 和 InsertBatchSomeColumn 内部定义好的方法名保持一致。
新建 UserMapper
在 mapper 包下创建 UserMapper 接口,注意继承刚刚自定义的 MyBaseMapper, 而不是 BaseMapper :
测试批量插入
完成上面这些工作后,就可以使用 Mybatis Plus 提供的批量插入功能了。我们新建一个单元测试,并注入 UserMapper :
@Autowired
private UserMapper userMapper;
单元测试如下:
@Test
void testInsertBatch() {
List<User> users = new ArrayList<>(); for (int i = 0; i < 3; i++) { User user = new User(); user.setName("犬小哈" + i); user.setAge(i); user.setGender(1); users.add(user); } userMapper.insertBatchSomeColumn(users); }
控制台实际执行 SQL 如下:
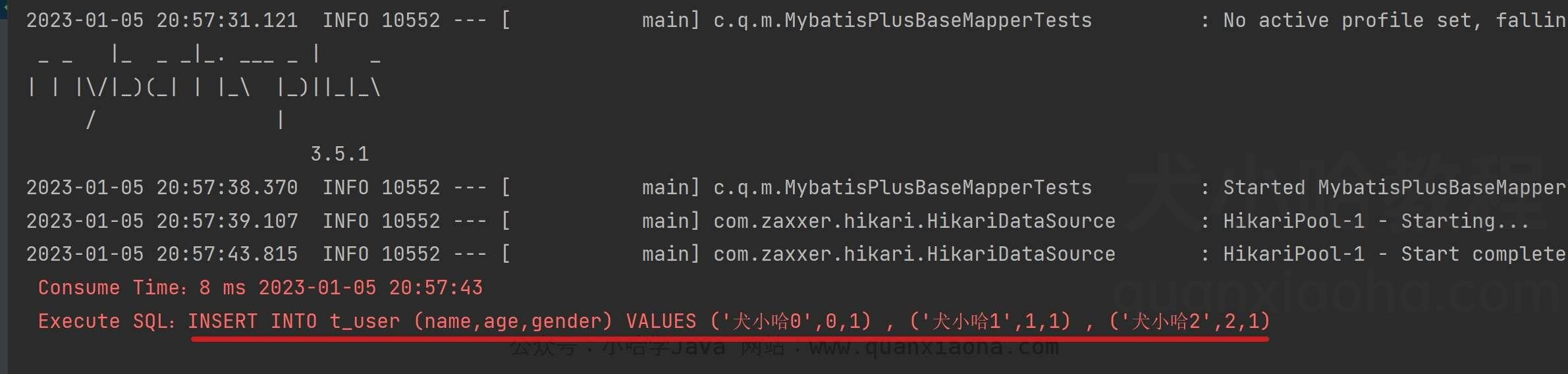
可以看到这次是真实的批量插入了,舒服了~
性能对比
我们来测试一下插入 105000 条数据,分别使用 for 循环插入数据、savaBatch() 伪批量插入、与真实批量插入三种模式,看看耗时差距多少。
小哈这里的机器配置如下:

for 循环插入
单元测试代码如下:
@Test
void testInsert1() {
savaBatch() 伪批量插入
单元测试代码如下:
@Test
void testInsert2() {
真实批量插入
注意,真实业务场景下,也不可能会将 10 万多条记录组装成一条 SQL 进行批量插入,因为数据库对执行 SQL 大小是有限制的(这个数值可以自行设置),还是需要分片插入,比如取 1000 条执行一次批量插入,单元测试代码如下:
@Test
void testInsertBatch1() {
耗时对比
| 方式 | 总耗时 |
|---|
for 循环插入 | 722963 ms, 约 12 分钟 |
savaBatch() 伪批量插入 | 95864 ms, 约一分钟30秒左右 |
| 真实批量插入 | 6320 ms, 约 6 秒 |
耗时对比非常直观,在大批量数据新增的场景下,批量插入性能最高。
结语
本小节中,我们学习了如何通过 Mybatis Plus 的 SQL 注入器实现真实的批量插入,同时最后还对比了三种不同方式插入 10 万多数据的耗时,很直观的看到在海量数据场景下,批量插入的性能是最强的。