题目描述
给出两个字符串 s_1s1 和 s_2s2,若 s_1s1 的区间 [l, r][l,r] 子串与 s_2s2 完全相同,则称 s_2s2 在 s_1s1 中出现了,其出现位置为 ll。
现在请你求出 s_2s2 在 s_1s1 中所有出现的位置。
定义一个字符串 ss 的 border 为 ss 的一个非 ss 本身的子串 tt,满足 tt 既是 ss 的前缀,又是 ss 的后缀。
对于 s_2s2,你还需要求出对于其每个前缀 s's′ 的最长 border t't′ 的长度。
输入格式
第一行为一个字符串,即为 s_1s1。
第二行为一个字符串,即为 s_2s2。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s_2s2 在 s_1s1 中出现的位置。
最后一行输出 |s_2|∣s2∣ 个整数,第 ii 个整数表示 s_2s2 的长度为 ii 的前缀的最长 border 长度。
输入输出样例
输入 #1复制
ABABABC
ABA
输出 #1复制
1
3
0 0 1
说明/提示
样例 1 解释
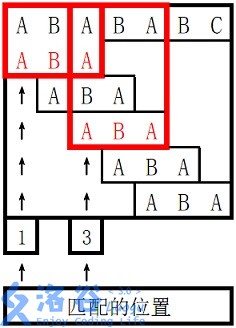
。
对于 s_2s2 长度为 33 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 11。
数据规模与约定
本题采用多测试点捆绑测试,共有 3 个子任务。
- Subtask 1(30 points):|s_1| \leq 15∣s1∣≤15,|s_2| \leq 5∣s2∣≤5。
- Subtask 2(40 points):|s_1| \leq 10^4∣s1∣≤104,|s_2| \leq 10^2∣s2∣≤102。
- Subtask 3(30 points):无特殊约定。
对于全部的测试点,保证 1 \leq |s_1|,|s_2| \leq 10^61≤∣s1∣,∣s2∣≤106,s_1, s_2s1,s2 中均只含大写英文字母。
题目输出的第二部分不同于书上的next数组或nextval数组,题目要求输出的border意思是,到第i个字符时前后缀的相似度(前缀与后缀有一个长度的相同部分则border【i】=1这样子)。
大话数据结构上的next数组每个位置的值代表的是在当前字符前面的部分前后缀的相似度,而这道题我们要的是包括当前字符以及往前前后缀的相似度,那么我们可以加一个字符a(题目说s1,s2 中均只含大写英文字母所以加一个小写字母不会影响判断),然后输出的值全部向后移动一位,即输出的循环这样写: for(int i=2; i<=l2+1; i++),并且当next【i】不等于0时,要将数据减一,因为k的值是这样来的:如果前后缀一个字符相等,则k=2,两个则k=3,n个则k=n+1。
刚开始写的代码一直ac70:
//ac70
#include<bits/stdc++.h>
using namespace std;
char s[1100000],t[1100000];
int l1,l2;
int nextval[1100000];
int nextt[1100000];
//求模式串T的next函数修正值并存入数组nextval
void get_nextval()
{
int i=1,k=0;
nextval[1]=0;
t[l2+1]='a';
while(i < l2+1)
{
if(k == 0||t[i] == t[k])//t[i]表示后缀的单个字符,t[k]表示前缀的单个字符
{
++i;
++k;
nextt[i]=k;
if(t[i]!=t[k])
nextval[i]=k;
else
nextval[i]=nextval[k];
}
else
k=nextval[k];
}
}
void Index_KMP(int pos)
{
int i=pos,j=1;
get_nextval();//求到的模式串T的nextval值被存入next数组中
while(i<=l1 && j<=l2)
{
if(j == 0 || s[i] == t[j])
{
++i;
++j;
}
else
{
j=nextval[j];
}
}
if(j > l2)//如果文本串中都已经匹配到t了
{
cout<<i-l2<<endl;
Index_KMP(i-1);
}
}
int main()
{
scanf("%s%s",s+1,t+1);//从下标为1的位置开始存
l1=strlen(s+1);//从下标为一的位置往后算元素个数
l2=strlen(t+1);
Index_KMP(1);
for(int i=2; i<=l2+1; i++)
{
if(nextt[i]!=0)
cout<<nextt[i]-1<<" ";
else
cout<<nextt[i]<<" ";
}
return 0;
}
错误的两个样例中我下载了一个查看 然后我发现问题在于这里的递归有问题。


该测试样例貌似是文本字符串为1000000个A,模板字符串为1000个A
当前面部分全部相同时,我的代码不能够接着下一个字符比对
然后我就把递归改成了Index_KMP(pos+1),但是我又发现这样子会导致部分样例重复查找到同一个相同部分的情况。
然后我发现转换next数组的方法过于冗杂,可以直接求出borad形式的“next数组”并在与文本字符串匹配时运用,相似度数组输出时能够直接正常输出无需改动后。
因为长度用l1和l2储存了也无需从下标为1开始存储,就直接输入字符串赋值给s和t即可。

那么按照相似的原理就要把 i=1;k=0:变成 i=0;k=-1;原本的next_[1]=0,改为next_[0]=-1,还有if判断中的k==0改为k==-1(都减了一!因为我们要让相似度值往前移动一位所以计算时也要把各个值往前移一位)其他部分无需改变。
void get_next()
{
int i=0,k=-1;
next_[0]=-1;
while(i<l2)
{
if(k==-1||t[i]==t[k])
{
++k;
++i;
nextval[i]=k;
if(t[i]!=t[k])
next_[i]=k;
else
next_[i]=next_[k];
}
else
k=next_[k];//若字符不同,则k值回溯
}
}
匹配文本串的过程,每当匹配成功一段之后我们还得继续比对判断,这时我们要改变j的值可以避免之前那个代码遇到的问题

最终输出的相似度也无需做任何改变直接输出即可

(其中全局变量设置部分我也进行了改进,因为题目给出的数据范围为1000000,我们要设置多个数组,范围都在1000000以上,每次都写很麻烦,就可以宏定义一个M 1100000,方便程序编写和改动)
ac代码:
#include<bits/stdc++.h>
using namespace std;
#define M 1100000
char s[M],t[M];
int nextval[M];
int next_[M];//nextval的优化数组
int l1,l2;
void get_next()
{
int i=0,k=-1;
next_[0]=-1;
while(i<l2)
{
if(k==-1||t[i]==t[k])
{
++k;
++i;
nextval[i]=k;
if(t[i]!=t[k])
next_[i]=k;
else
next_[i]=next_[k];
}
else
k=next_[k];//若字符不同,则k值回溯
}
}
void index_KMP()
{
int i=0;
int j=0;
get_next();
while(i<l1)
{
if(j==-1||s[i]==t[j])
{
++i;
++j;
}
else
j=next_[j];
if(j==l2)
{
printf("%d\n",i-l2+1);
j=next_[j];//j值回溯到合适的位置
}
}
}
int main()
{
cin>>s>>t;
l1=strlen(s);
l2=strlen(t);
index_KMP();
for(int i=1; i<=l2; i++)
cout<<nextval[i]<<" ";
return 0;
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)