朴素贝叶斯(Naive Bayesian)是最为广泛使用的分类方法,它以概率论为基础,是基于贝叶斯定理和特征条件独立假设的分类方法。
-
- 一 概述
- 1 简介
- 2 条件概率与贝叶斯定理
- 3 朴素贝叶斯分类的原理
- 4 朴素贝叶斯分类的流程和优缺点
- 二Python算法实现
- 1 根据文档词汇表构建词向量
- 2 运用词向量计算概率
- 3 运用分类器函数对文档进行分类
- 三 实例使用朴素贝叶斯过滤垃圾邮件
- 四实例使用朴素贝叶斯分类器从个人广告中获取区域倾向
一、 概述
1.1 简介
朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它通过特征计算分类的概率,选取概率大的情况进行分类,因此它是基于概率论的一种机器学习分类方法。因为分类的目标是确定的,所以也是属于监督学习。
Q1:什么是基于概率论的方法?
通过概率来衡量事件发生的可能性。概率论和统计学恰好是两个相反的概念,统计学是抽取部分样本进行统计来估算总体的情况,而概率论是通过总体情况来估计单个事件或者部分事情的发生情况。因此,概率论需要已知的数据去预测未知的事件。
例如,我们看到天气乌云密布,电闪雷鸣并阵阵狂风,在这样的天气特征(F)下,我们推断下雨的概率比不下雨的概率大,也就是
p(下雨)>p(不下雨)
,所以认为待会儿会下雨。这个从经验上看对概率进行判断。
而气象局通过多年长期积累的数据,经过计算,今天下雨的概率
p(下雨)=85%,p(不下雨)=15%
,同样的,
p(下雨)>p(不下雨)
,因此今天的天气预报肯定预报下雨。这是通过一定的方法计算概率从而对下雨事件进行判断。
Q2:朴素贝叶斯,朴素在什么地方?
之所以叫朴素贝叶斯,因为它简单、易于操作,基于特征独立性假设,假设各个特征不会相互影响,这样就大大减小了计算概率的难度。
1.2 条件概率与贝叶斯定理
(1)概率论中几个基本概念
事件交和并:
A和B两个事件的交,指的是事件A和B同时出现,记为
A∩B
;
A和B两个事件的并,指的是事件A和事件B至少出现一次的情况,记为
A∪B
。
互补事件:事件A的补集,也就是事件A不发生的时候的事件,记为
Ac
。这个时候,要么A发生,要么
Ac
发生,
P(A)+P(Ac)=1
。
条件概率(conditional probability):
某个事件发生时另外一个事件发生的概率,如事件B发生条件下事件A发生的概率:
P(A|B)=P(A∩B)P(B)
概率的乘法法则(multiplication rule of probability):
P(A∩B)=P(A)P(B|A)orP(A∩B)=P(B)P(A|B)
独立事件交的概率:
两个相互独立的事件,其交的概率为:
P(A∩B)=P(A)P(B)
更多概率论基本概念,参见:
概率论基本概念
(2)贝叶斯定理(Bayes’s Rule):
如果有k个互斥且有穷个事件
B1,B2⋅⋅⋅,Bk
,并且,
P(B1)+P(B2)+⋅⋅⋅+P(Bk)=1
和一个可以观测到的事件A,那么有:
P(Bi|A)=P(Bi∩A)P(A)=P(Bi)P(A|Bi)P(B1)P(A|B1)+P(B2)P(A|B2)+⋅⋅⋅+P(Bk)P(A|Bk)
p(A)
:事件A发生的概率;
p(A∩B)
:事件A 和事件B同时发生的概率
p(A|B)
:表示事件A在事件B发生的条件下发生的概率,
1.3 朴素贝叶斯分类的原理
朴素贝叶斯基于条件概率、贝叶斯定理和独立性假设原则
(1)首先,我们来看条件概率原理:
基于概率论的方法告诉我们,当只有两种分类时:
如果
p1(x,y)>p2(x,y)
,那么分入类别1
如果
p1(x,y)<p2(x,y)
,那么分入类别2
(2)其次,贝叶斯定理
同样的道理,引入贝叶斯定理,有:
p(ci|x,y)=p(x,y|ci)p(ci)p(x,y)
其中,
x,y
表示特征变量,
ci
表示分类,
p(ci|x,y)
即表示在特征为
x,y
的情况下分入类别
ci
的概率,因此,结合条件概率和贝叶斯定理,有:
- 如果
p(c1|x,y)>p(c2|x,y)
,那么分类应当属于
c1
;
- 如果
p(c1|x,y)<p(c2|x,y)
,那么分类应当属于
c2
;
贝叶斯定理最大的好处是可以用已知的三个概率去计算未知的概率,而如果仅仅是为了比较
p(ci|x,y)和p(cj|x,y)
的大小,只需要已知两个概率即可,分母相同,比较
p(x,y|ci)p(ci)
和
p(x,y|cj)p(cj)
即可。
(3)特征条件独立假设原则
朴素贝叶斯最常见的分类应用是对文档进行分类,因此,最常见的特征条件是文档中,出现词汇的情况,通常将词汇出现的特征条件用词向量
ω
表示,由多个数值组成,数值的个数和训练样本集中的词汇表个数相同。
因此,上述的贝叶斯条件概率公式可表示为:
p(ci|ω)=p(ω|ci)p(ci)p(ω)
前面提到朴素贝叶斯还有一个假设,就是基于
特征条件独立的假设,也就是我们姑且认为词汇表中各个单词独立出现,不会相互影响,因此,
p(ω|ci)
可以将
ω
展开成独立事件概率相乘的形式,因此:
p(ω|ci)=p(w0|ci)p(w1|ci)p(w2|ci)......p(wN|ci)
这样,计算概率就简单太多了。
1.4 朴素贝叶斯分类的流程和优缺点
(1)分类流程
1.数据准备:收集数据,并将数据预处理为数值型或者布尔型,如对文本分类,需要将文本解析为词向量
2.训练数据:根据训练样本集计算词项出现的概率,训练数据后得到各类下词汇出现概率的向量
3. 测试数据:用测试样本集去测试分类的准确性
(2) 优缺点
1. 监督学习,需要确定分类的目标
2. 对缺失数据不敏感,在数据较少的情况下依然可以使用该方法
3. 可以处理多个类别 的分类问题
4. 适用于标称型数据
5. 对输入数据的形势比较敏感
6. 由于用先验数据去预测分类,因此存在误差
二、Python算法实现
以在线社区的留言板评论为例,运用朴素贝叶斯分类方法,对文本进行自动分类。
构造一些实验样本,包括已经切分词条的文档集合,并且已经分类(带有侮辱性言论,和正常言论)。为了获取方便,在bayes.py中构造一个loadDataSet函数来生成实验样本。
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec=[0,1,0,1,0,1]
return postingList,classVec
2.1 根据文档词汇表构建词向量
(1)构建词汇表生成函数creatVocabList:
def createVocabList(dataSet):
vocabSet=set([])
for document in dataSet:
vocabSet=vocabSet|set(document)
return list(vocabSet)
(2)对输入的词汇表构建词向量
def setOfWords2Vec(vocabList,inputSet):
returnVec=zeros(len(vocabList))
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]=1
else: print('the word:%s is not in my Vocabulary!'% word)
return returnVec
这种构建词向量的方法,只记录了每个词是否出现,而没有记录词出现的次数,这样的模型叫做词集模型,如果在词向量中记录词出现的次数,没出现一次,则多记录一次,这样的词向量构建方法,被称为词袋模型,下面构建以一个词袋模型的词向量生成函数bagOfWord2VecMN:
def bagOfWords2VecMN(vocabList,inputSet):
returnVec=[0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)]+=1
return returnVec
- 测试,对词向量生成函数进行测试,在控制台输入如下命令:
In [105]: import bayes
...:
In [106]: listPosts,listClasses=bayes.loadDataSet()
...:
In [107]: myVocabList=bayes.createVocabList(listPosts)
...:
In [108]: myVocabList
...:
Out[108]:
['I','quit', 'him', 'licks', 'food', 'problems', 'how', 'help', 'mr', 'my', 'take', 'posting', 'stupid', 'has', 'steak', 'buying', 'dalmation', 'flea', 'cute', 'park', 'please', 'dog', 'worthless', 'to', 'garbage','love', 'is', 'so', 'maybe', 'ate', 'stop', 'not']
In [109]: bayes.setOfWords2Vec(myVocabList,listPosts[0])
...:
Out[109]: array([ 0., 0., 0., ..., 0., 0., 0.])
In [110]: bayes.setOfWords2Vec(myVocabList,listPosts[1])
...:
Out[110]: array([ 0., 0., 1., ..., 0., 0., 1.])
2.2 运用词向量计算概率
再看前文提到的朴素贝叶斯的原理,要计算词向量
ω=(ω0,ω1,ω2,...ωN,)
,落入
ci
类别下的概率:
p(ci|ω)=p(ω|ci)p(ci)p(ω)
p(ci)
好求,用样本集中,
ci
的数量/总样本数即可
p(ω|ci)
由于各个条件特征相互独立且地位相同,
p(ω|ci)=p(w0|ci)p(w1|ci)p(w2|ci)......p(wN|ci)
,可以分别求
p(w0|ci),p(w1|ci),p(w2|ci),......,p(wN|ci)
,从而得到
p(ω|ci)
。
而求
p(ωk|ci)
也就变成了求在分类类别为
ci
的文档词汇表集合中,单个词项
ωk
出现的概率,也就是
p(ωk|ci)=ωk在ci中出现的次数ci中词总数
因此计算出现概率大致有这么一些流程:
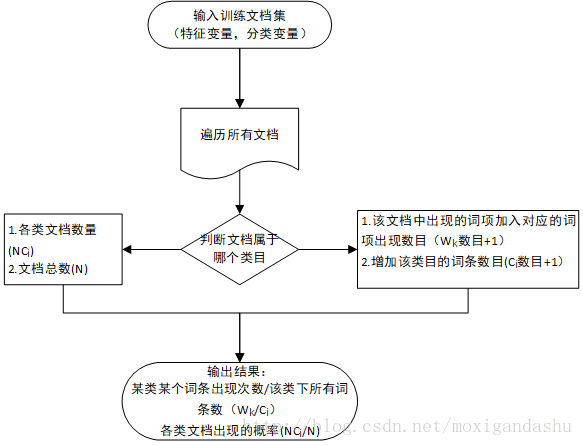
是用Python代码实现,创建函数TrainNB:
def trainNB0(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix)
numWord=len(trainMatrix[0])
pAbusive=sum(trainCategory)/len(trainCategory)
p0Num=zeros(numWord);p1Num=zeros(numWord)
p0Demon=0;p1Demon=0
for i in range(numTrainDocs):
if trainCategory[i]==0:
p0Num+=trainMatrix[i]
p0Demon+=sum(trainMatrix[i])
else:
p1Num+=trainMatrix[i]
p1Demon+=sum(trainMatrix[i])
p0Vec=p0Num/p0Demon
p1Vec=p1Num/p1Demon
return p0Vec,p1Vec,pAbusive
解释:
1.pAbusive=sum(trainCategory)/len(trainCategory),表示文档集中分类为1的文档数目,累加求和将词向量中所有1相加,len求长度函数则对所有0和1进行计数,最后得到分类为1的概率
2.p0Num+=trainMatrix[i];p0Demon+=sum(trainMatrix[i]),前者是向量相加,其结果还是向量,trainMatrix[i]中是1的位置全部加到p0Num中,后者是先求和(该词向量中词项的数目),其结果是数值,表示词项总数。
3.p0Vec=p0Num/p0Demon,向量除以数值,结果是向量,向量中每个元素都除以该数值。
- 测试:对构建的朴素贝叶斯分类器训练函数进行测试,在python(个人使用的是ipython)提示符中输入:
In [111]: reload(bayes)
...:
Out[111]: <module 'bayes' from 'G:\\Workspaces\\MachineLearning\\bayes.py'>
In [112]: listPosts,listClasses=bayes.loadDataSet()
...:
In [113]: myVocabList=bayes.createVocabList(listPosts)
...:
In [114]: trainMat=[]
...:
In [115]: for postinDoc in listPosts:
...: trainMat.append(bayes.setOfWords2Vec(myVocabList,postinDoc))
...:
...:
In [116]: p0v,p1v,pAb=bayes.trainNB0(trainMat,listClasses)
...:
In [117]: pAb
...:
Out[117]: 0.5
In [118]: p0v
...:
Out[118]:
array([ 0.04166667, 0. , 0.08333333, ..., 0.04166667,
0.04166667, 0. ])
In [119]: p1v
...:
Out[119]:
array([ 0. , 0.05263158, 0.05263158, ..., 0. ,
0.05263158, 0.05263158])
In [121]: p0v[25]
Out[121]: 0.041666666666666664
In [122]: p1v[25]
Out[122]: 0.0
In [124]: p0v[12]
Out[124]: 0.0
In [125]: p1v[12]
Out[125]: 0.15789473684210525
从结果我们看到,侮辱性文档出现的概率是0.5,词项’love’在侮辱性文档中出现的概率是0,在正常言论中出现的概率是0.042;词项‘stupid’在正常言论中出现的概率是0,在侮辱性言论中出现的规律是0.158.
- 算法漏洞:
- 乘积为0
我们看到,当某分类下某词项出现频次为0时,其概率也是0,因此在计算
p(w0|ci)p(w1|ci)p(w2|ci)......p(wN|ci)
会因为其中某个的概率为0而全部是0。
为了避免这样的情况发生,我们将所有词项出现的频次都初始化为1,某类所有词项数量初始化为2。 - 因子太小导致结果溢出问题
由于
p(w0|ci)p(w1|ci)p(w2|ci)......p(wN|ci)
中每个因子都很小,所有因子相乘,特别是因子数量多的时候,会导致结果溢出,从而得到错误的数据
避免溢出问题的发生,可以使用求自然对数的方法,自然对数和原本的数值同增同减,不会有任何损失,因此不会影响求得的概率结果。
因此,将朴素贝叶斯分类器函数修改为:
def trainNB1(trainMatrix,trainCategory):
numTrainDocs=len(trainMatrix)
numWord=len(trainMatrix[0])
pAbusive=sum(trainCategory)/len(trainCategory)
p0Num=ones(numWord);p1Num=ones(numWord)
p0Demon=2;p1Demon=2
for i in range(numTrainDocs):
if trainCategory[i]==0:
p0Num+=trainMatrix[i]
p0Demon+=sum(trainMatrix[i])
else:
p1Num+=trainMatrix[i]
p1Demon+=sum(trainMatrix[i])
p0Vec=log(p0Num/p0Demon)
p1Vec=log(p1Num/p1Demon)
return p0Vec,p1Vec,pAbusive
2.3 运用分类器函数对文档进行分类
前文概率论讲到,计算文档在各类中的概率,取较大者作为该文档的分类,所以构建分类函数classifyNB:
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1=sum(vec2Classify*p1Vec)+log(pClass1)
p0=sum(vec2Classify*p0Vec)+log(1-pClass1)
if p1>p0:
return 1
else:
return 0
说明:
p1=sum(vec2Classify*p1Vec)+log(pClass1) 的数学原理是ln(a*b)=ln(a) +ln(b)
接下来构造几个样本,来测试分类函数:
def testingNB():
listPosts,listClasses=loadDataSet()
myVocabList=createVocabList(listPosts)
trainMat=[]
for postinDoc in listPosts:
trainMat.append(setOfWords2Vec(myVocabList,postinDoc))
p0V,p1V,pAb=trainNB1(trainMat,listClasses)
testEntry=['love','my','dalmation']
thisDoc=setOfWords2Vec(myVocabList,testEntry)
print(testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry=['stupid','garbage']
thisDoc=array(setOfWords2Vec(myVocabList,testEntry))
print(testEntry,'classified as:',classifyNB(thisDoc,p0V,p1V,pAb))
In [126]: reload(bayes)
...:
Out[126]: <module 'bayes' from 'G:\\Workspaces\\MachineLearning\\bayes.py'>
In [127]: bayes.testingNB()
...:
['love', 'my', 'dalmation'] classified as: 0
['stupid', 'garbage'] classified as: 1
三、 实例:使用朴素贝叶斯过滤垃圾邮件
文件夹spam和ham中各有25封txt文档形式的邮件正文,两个文件夹分别分类为1和0,如打开ham中2.txt文件,其内容为:
Yay to you both doing fine!
I'm working on an MBA in Design Strategy at CCA (top art school.) It's a new program focusing on more of a right-brained creative and strategic approach to management. I'm an 1/8 of the way done today!
现在,利用这些文档,进行朴素贝叶斯分类算法训练和测试:
def textParser(bigString):
import re
listOfTokens=re.split(r'\W*',bigString)
return [tok.lower() for tok in listOfTokens if len(tok)>2]
def spanTest():
docList=[];classList=[];fullText=[]
for i in range(1,26):
wordList=textParser(open('machinelearninginaction/Ch04/email/spam/%d.txt'%i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList=textParser(open('machinelearninginaction/Ch04/email/ham/%d.txt'%i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList=createVocabList(docList)
trainingSet=list(range(50));testSet=[]
for i in range(10):
randIndex=int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[];trainClasses=[]
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList,docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pAb=trainNB1(trainMat,trainClasses)
errorCount=0
for docIndex in testSet:
wordVector=setOfWords2Vec(vocabList,docList[docIndex])
if classifyNB(wordVector,p0V,p1V,pAb) != classList[docIndex]:
errorCount+=1
print('classification error',docList[docIndex])
print('the error rate is:',float(errorCount)/len(testSet))
利用该样本集合中的数据样本,随机选取一部分作为训练样本集,剩余部分作为测试样本集,这样的方法称为留存交叉验证
In [131]: bayes.spanTest()
...:
classification error ['home', 'based', 'business', 'opportunity', 'knocking', 'your', 'door', 'don抰', 'rude', 'and', 'let', 'this', 'chance', 'you', 'can', 'earn', 'great', 'income', 'and', 'find', 'your', 'financial', 'life', 'transformed', 'learn', 'more', 'here', 'your', 'success', 'work', 'from', 'home', 'finder', 'experts']
the error rate is: 0.1
D:\Tools\ANACONDA\lib\re.py:212: FutureWarning: split() requires a non-empty pattern match.
return _compile(pattern, flags).split(string, maxsplit)
可以看到测试的错误率为0.1,并且输出了分类错误的文档中的词项。多次执行上述函数进行测试,发现错误率会变化。
四、实例:使用朴素贝叶斯分类器从个人广告中获取区域倾向
我们利用Python库中中的Universal Feed Parser来获取数据,首先需要引入包feedparser:import feedparser,如果没有需要安装,比较简单的方法是使用pip进行安装。
def calcMostFreq(vocabList,fullText):
import operator
freqDict={}
for word in vocabList:
freqDict[word]=fullText.count(word)
sortedFreq=sorted(freqDict.items(),key=operator.itemgetter(1),reverse=True)
return sortedFreq[:20]
def localWords(feed1,feed0):
import feedparser
docList=[];classList=[];fullText=[]
minLen=min(len(feed1['entries']),len(feed0['entries']))
for i in range(minLen):
wordList=textParser(feed1['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList=textParser(feed0['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList=createVocabList(docList)
top30words=calcMostFreq(vocabList,fullText)
for pairW in top30words:
if pairW[0] in vocabList:
vocabList.remove(pairW[0])
trainSet=list(range(2*minLen))
testSet=[]
for i in range(20):
randIndex=int(random.uniform(0,len(trainSet)))
testSet.append(trainSet[randIndex])
del(trainSet[randIndex])
trainMat=[];trainClasses=[]
for docIndex in trainSet:
trainMat.append(bagOfWords2VecMN(vocabList,docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam=trainNB1(trainMat,trainClasses)
errorCount=0
for docIndex in testSet:
wordVector=bagOfWords2VecMN(vocabList,docList[docIndex])
if classifyNB(wordVector,p0V,p1V,pSpam) !=classList[docIndex]:
errorCount+=1
print('the error rate is:',float(errorCount)/len(testSet))
return vocabList,p0V,p1V
说明:
1.为什么要去除频次最高的词项:因为出现频次高的词项很多是没有意义的冗余和辅助性内容,不移除这些词汇,使用朴素贝叶斯分类算法,其错误率会显著高一些
- 另外一个方法,是从词表中删除辅助词,这个需要删除的词表被称为停用词表,这个网站列出了多门语言,如英文、中文等语言中的停用词表。
In [132]: import feedparser
...:
In [133]: ny=feedparser.parse('https://newyork.craigslist.org/stp/index.rss')
...:
In [134]: sf=feedparser.parse('https://sfbay.craigslist.org/stp/index.rss')
...:
In [135]: vocabList,pSF,pNY=bayes.localWords(ny,sf)
...:
the error rate is: 0.45
D:\Tools\ANACONDA\lib\re.py:212: FutureWarning: split() requires a non-empty pattern match.
return _compile(pattern, flags).split(string, maxsplit)
In [136]: vocabList,pSF,pNY=bayes.localWords(ny,sf)
...:
the error rate is: 0.3
D:\Tools\ANACONDA\lib\re.py:212: FutureWarning: split() requires a non-empty pattern match.
return _compile(pattern, flags).split(string, maxsplit)
(2)显示最具表征性的词汇
def getTopWords(ny,sf,t=-6.0):
import operator
vocabList,p0V,p1V=localWords(ny,sf)
topNY=[];topSF=[]
for i in range(len(p0V)):
if p0V[i]>t:topSF.append((vocabList[i],p0V[i]))
if p1V[i]>t:topNY.append((vocabList[i],p1V[i]))
sortedSF=sorted(topSF,key=lambda x: x[1],reverse=True)
print('SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF')
for item in sortedSF:
print(item[0])
sortedNY=sorted(topNY,key=lambda pair: pair[1],reverse=True)
print('NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY')
for item in sortedNY:
print(item[0])
In [143]: bayes.getTopWords(ny,sf,-4.5)
the error rate is: 0.4
SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF
guy
know
talk
friendship
married
maybe
going
single
out
male
NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY
day
out
meet
chat
seeking
year
time
stocks
well
now
woman
kik
company
work
D:\Tools\ANACONDA\lib\re.py:212: FutureWarning: split() requires a non-empty pattern match.
return _compile(pattern, flags).split(string, maxsplit)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)