正式读研之后看的第一篇文献。本着“只有记录下来的才是自己的”这一原则,记录一下。
论文提出的方法用来解决多元一次方程组中系数矩阵为下三角的情况(Lx = b中,L为下三角矩阵)
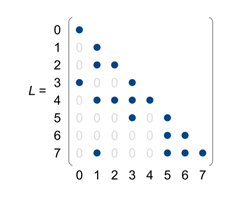
如上图所示,对应的方程组如下“
a(0,0)x0 = b0
a(1,1)x1 = b1
a(2,1)x1 + a(2,2)x2 = b2
...
a(4,1)x1+a(4,2)x2+a(4,3)x3+a(4,4)x4 = b4
...
可以看到x0和x1可以直接得解,而x2必须等待x1计算完成之后才可以计算,同理x4必须等待x1,x2,x3计算完成以后才能开始计算。如果用x->y表示y必须等待x计算完成之后才能开始计算,则可得下图
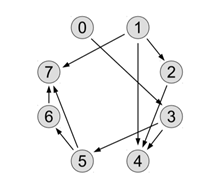
对这张解的顺序图进行拓扑排序,对不同层进行level标记,则可得下图

可以看到,0和1可同时得解,之后解3和2,以此类推,最后解7。也就是说,处于同级level的元素不存在顺序关系,可被同时计算。处于不同level的元素必须满足计算顺序。所以程序总体上说是按照level串行进行,同层level并行进行。上述把解放到不同level的方法就是level scheduling。由于需要提前对解的顺序图进行拓扑排序,分析level顺序、哪些元素可以被并行处理,程序运行起来还需要进行同步控制,保证整体计算的串行进行,这样代价是很大的。
而论文中提出的无同步(Synchronization-Free)做到了不必同步。方法是等待。在上例中,由于计算x2必须在计算x1之后进行,那么就让计算x2元素的线程等待x1计算完成之后再开始计算x2。
那怎么才能知道和自己相关的元素有没有被计算完成呢(如x2需要知道x1是否被计算完)?论文中提出了使用入度这一方法,当一个点在解的顺序图中的入度减为0以后,说明它的前驱节点已经全部计算完,这个结点可以计算。例如x1计算完成之后,则需要更新x2的入度-1;x3计算完后则需要更新x4和x5的入度。这里更新其他元素这一步也可以并行来做,如x3对x4和x5的更新 。
总体思想就是这样,一些细节看完代码再说,下面是算法代码

可以看到,算法主要分两个state,先是并行求不同点的入度(line3-7,preprocessing_state),然后在solve_state先是等待相关联元素先计算完(line11-13),再计算自身元素(line14),然后更新被关联元素(line15-24)。left_sum和row_idx等变量的含义查看算法的串行版本和矩阵的CSC存储格式即可。
这里要特别注意的是,1)算法第10行和第15行其实是动态并行,也就是多级并行,这里实现两级并行的手段是第一级并行(等待并计算自身负责元素)用wrap级并行,第二级并行(更新当前计算元素的后继节点入度)用thread级并行。为什么要这么设计呢?这就设计到cuda的特性了,执行指令的最小单位是wrap而不是thread,所以wrap内不同线程使用自旋锁的话会趋于死锁。设想第一级并行如果用了thread级并行,且都在一个wrap里,那么即便0号进程计算完了,也不会更新1号进程的负责元素的入度,因为同一个wrap内的线程是腿绑在一起往前跑的。1号进程不能跑完循环体执行到13行代码,那0号进程也别想走到13行代码,更别提通知1号进程,让1号进程开始计算,所以就要把不同元素的计算放到不同的wrap里面。2)第二级并行,同个wrap内的32个thread通知不同的后继节点,需要注意的就是这里只有32个进程可以用,假如待更新入度的后继节点多于32个,就只能循环利用这32个进程,也就是让wrap内的0号进程去通知第33个后继节点。
算法还在内存方面做了优化,使用了共享内存加速程序的计算,变量名字以s_开头的全部是共享内存,以d_开头的是设备内存。第17行对同片元素(即被同块线程处理元素)进行判断,如果是同片元素,那么更新同片变量(18、19行),如果不是,则更新非同片元素值(21、22行)。
注:代码的3-7行进行入度统计,由于自身元素也算作入度,所以11行入度减为1即可。
附(算法的串行版本):

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)