这里介绍一种名为DeepCache的无需训练的方法,它利用了去噪过程中模型深层特征的相似性,通过缓存(Cache)来避免重新计算网络中的深层特征,仅计算网络的浅层,从而减少计算量。实验展示了DeepCache相较于需要重新训练的现有剪枝和蒸馏方法的优越性,以及它与当前采样技术例如DDIM,PLMS的兼容性。 无损加速扩散模型!无训练、无成本的AI神器开源
简介

近几年,Diffusion Models在图像合成领域获得了前所未有的关注。在序列式的生成过程中,多步的计算和庞大的模型尺寸会带来相当大的成本。而传统的模型压缩技术,例如剪枝、蒸馏通常又涉及到重新训练,导致了额外的成本和可行性上的挑战。本文介绍了一种名为DeepCache的
无需训练
的方法,它利用了去噪过程中模型深层特征的相似性,通过缓存(Cache)来避免重新计算网络中的深层特征,仅计算网络的浅层,从而减少计算量。在没有任何额外训练的情况下,这种策略使得Stable Diffusion v1.5的速度提升了2.3倍,CLIP分数仅下降了0.05;而LDM-4-G的速度提升了4.1倍,且FID在ImageNet仅下降0.22。实验展示了DeepCache相较于需要重新训练的现有剪枝和蒸馏方法的优越性,以及它与当前采样技术例如DDIM,PLMS的兼容性。DeepCache目前支持Stable Diffusion v1.5/v2.1/XL等主流扩散模型。
DeepCache: Accelerating Diffusion Models for Free
Xinyin Ma, Gongfan Fang, Xinchao Wang Learning and Vision Lab, National University of Singapore
论文:https://arxiv.org/abs/2312.00858
代码:github.com/horseee/DeepCache
项目主页:https://horseee.github.io/Diffusion_DeepCache/
方法

图1:扩散模型多步计算中的深层特征冗余
特征冗余
:扩散模型的合成是一个多步的序列过程,在每一步中我们都要完整执行一次模型的前馈计算。然而,研究者发现在相近的步骤中(例如第20步和第19步),模型的深层特征变化十分微小,这就引入了一个新的探索问题,即是否需要反复地计算这些特征。在这一基础上,本文进一步分析了三种主流模型:LDM-4-G,DDPM,Stable Diffusion中的特征相似性,如图1(b)所示,相邻时间步均呈现出了高度的特征相似性。这种冗余现象启发了一种新的加速方式,即本文提出的DeepCache。
算法核心
:DeepCache的核心想法是避免重复计算冗余的深层特征,因此算法的整体框架非常简洁。如图2所示,我们在部分步骤执行完整的网络计算,并缓存深层特征;而在其他步骤仅计算浅层特征,并利用缓存直接得到结果。这一过程允许我们跳过网络中的大部分层,从而显著降低计算量。通过的实验可以发现,Diffusion Models中的绝大多数层都可以借助DeepCache进行跳过,同时不影响最终的生成质量。
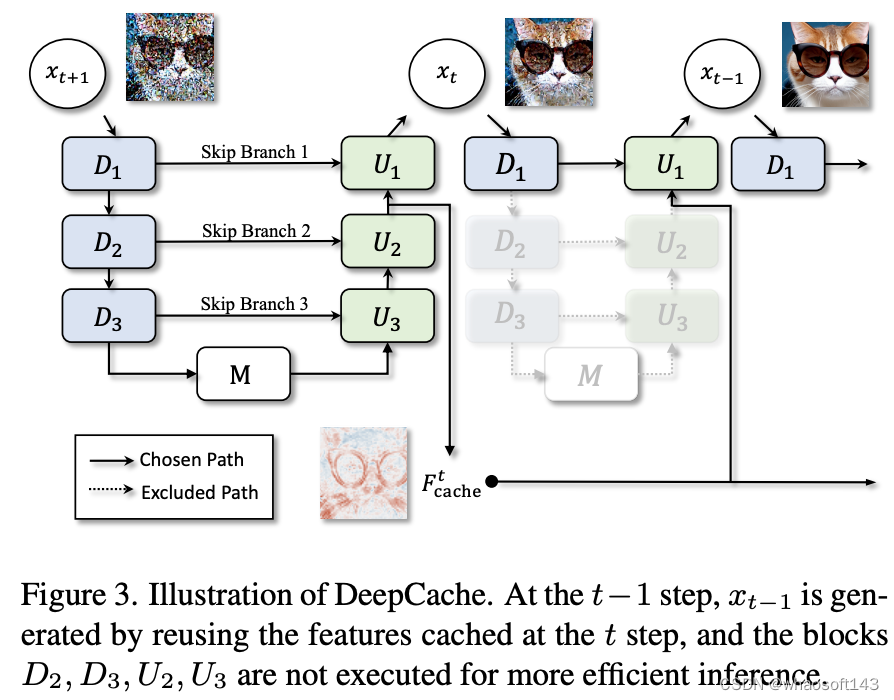
图2:DeepCache方法示意图
Uniform与Non-Uniform加速策略
:基于上述基本框架,我们可以很自然地拓展出Uniform和非Uniform的加速策略。Uniform加速策略采用了1:N的计算分配,即1步完整计算获得缓存,N步快速计算得到结果。例如在Stable Diffusion上,我们采用1:5的加速策略可以得到2.3倍实际速度提升,同时性能几乎无损。在另一方面,非Uniform策略则具有更大的设计空间。先前提到,网络中不同步骤之间存在特征冗余,然而这种冗余的分布是有所差异的。Non-Uniform策略则针对特征冗余的特点,给高冗余步骤分配更少的Cache更新次数,给低冗余区域分配更多的Cache更新,这会带来显著的性能提升。
实验
定量分析
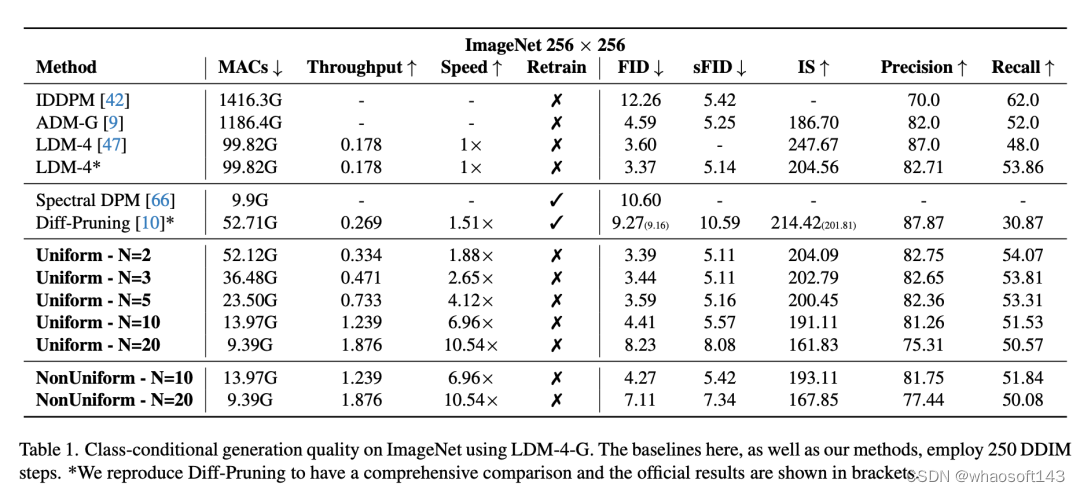
本文在Stable Diffusion, LDM (ImageNet),DDPM (CIFAR, LSUN)等主流模型上进行深入验证。
LDM - ImageNet
:例如在ImageNet上,我们的算法能够不依赖任何额外训练,实现几乎无损的压缩加速效果。例如基于1:2的加速策略,我们的方法实现了和剪枝方法略优的加速比(DeepCache1.88x对比剪枝1.51x),得到了更优的FID指标(DeepCache3.39对比剪枝9.27)。除此以外,DeepCache可以自由地权衡加速比和性能,例如提高缓存的间隔我们可以将加速比提升到10倍,此时算法的FID指标依然优于基于小规模训练的压缩方法(剪枝、蒸馏)。另外,引入非均匀的Non-Uniform策略,我们可以以同样的加速比,得到更优的图像质量。
Stable Diffusion
:在Stable Diffusion v1.5模型上,我们使用了CLIP Score对生成质量进行评估。并比较了压缩模型(DeepCache)与压缩步数(采样加速方法PLMS)的性能。减少采样步数是扩散模型加速中的一种主流方法,与本文提出的压缩模型策略是相互适配的。DeepCache展现出了和减少采样步数相似的加速性能,例如2.15倍加速的DeepCache甚至能取得优于步数减少一半的PLMS算法。

更多CIFAR, LSUN Church, LSUN Bedroom的结果可见论文实验部分。
分析实验
Cache策略分析
:我们进一步分析了Stable Diffusion上不同Cache策略带来的加速效果,可以看到Non-Uniform策略往往能够提供最有的加速速率以及CLIP Score。但是相对来说1:N Uniform的加速方法是一种通用且实现简洁的技术,且仅有一个超参数N。在1:N的Uniform加速策略中,我们可以自由调整N,即缓存间隔来提升模型速度。本文可视化了N从2到8的设置下,生成图像的视觉效果。可以明显的看到,随着Cache间隔N逐渐增大,图片的内容会逐渐变化,但仍然能够维持整体视觉质量。


可视化
下图可视化了Stable Diffusion v1.5, LDM (ImageNet), DDPM (LSUN Church & Bedroom)等模型的生成效果,上图是原始模型生成结果,下图是DeepCache加速后的模型生成结果,具体的加速比可见图片标题。 whaosoft
aiot
http://143ai.com


代码实现
DeepCache算法的核心思想非常简单,本文提供了Stable Diffusion v1.5/v2.1以及Stable Diffusion XL的代码实现,具体可见:
https://github.com/horseee/DeepCache
算法在使用体验上与原始的Diffusers pipline几乎完全一致。我们仅需要用DeepCache提供的Pipeline替换Diffusers库的Pipeline,即可实现扩散模型加速。