计算机硬件的五大单元
在介绍计算机硬件基础之前,我们必须了解一下计算机硬件的五大单元,注意这里说的是硬件的五大单元并不是计算机五大单元。
输入设备
无论是计算机五大单元还是计算机硬件的五大单元,这其中必须包含的东西肯定是输入设备,在计算机日常使用中,输入设备无非就是将我们需要的数据传给计算机的媒介,输入设备常见的由鼠标、键盘、游戏手柄等。
输出设备
输出设备顾名思义就是显示计算机处理数据的媒介,例如显示屏、打印机等都是输出设备。
算术逻辑单元
在介绍算数逻辑单元之前,我们必须了解一下什么是CPU,CPU是一个具有特定的功能的一个芯片,每个CPU都包含一堆的指令集。算术逻辑单元就是CPU的一部分,它负责程序的运算以及逻辑判断。
控制单元
同样的控制单元也是CPU的一部分,它负责协调各个周边的组件和各个单元的工作。
主存(内存)
由上文我们都知道CPU是负责各种复杂的运算工作和组件之间的调度协调,那么问题来了,运算过程中势必需要数据,那么数据又要从哪里来呢?答案就是内存,内存就是CPU获取数据来源。但是很多读者肯定又要疑问,我们日常使用电脑的时候,数据不都是存储在硬盘中嘛?为什么CPU不去硬盘获取数据而是需要从主存中获取呢?
答案很简单,CPU处理数据速度非常块,但是磁盘将数据传输给CPU的时候却要非常久,所以为了能够将加快数据传输到CPU的速度以便CPU能够快速完成计算,所以我们就在硬盘和CPU之间搭建了一个重要的组件,内存。有了内存作为中介,使得CPU获取数据的速度会相对快一些,保证CPU的执行效率,从而避免因为数据传输过漫而导致的CPU空转。所以内存常被我们称为主存,而硬盘等设备都被称为辅存。
总结一下上文的描述,我们就可以得到下图所示的内存结构:
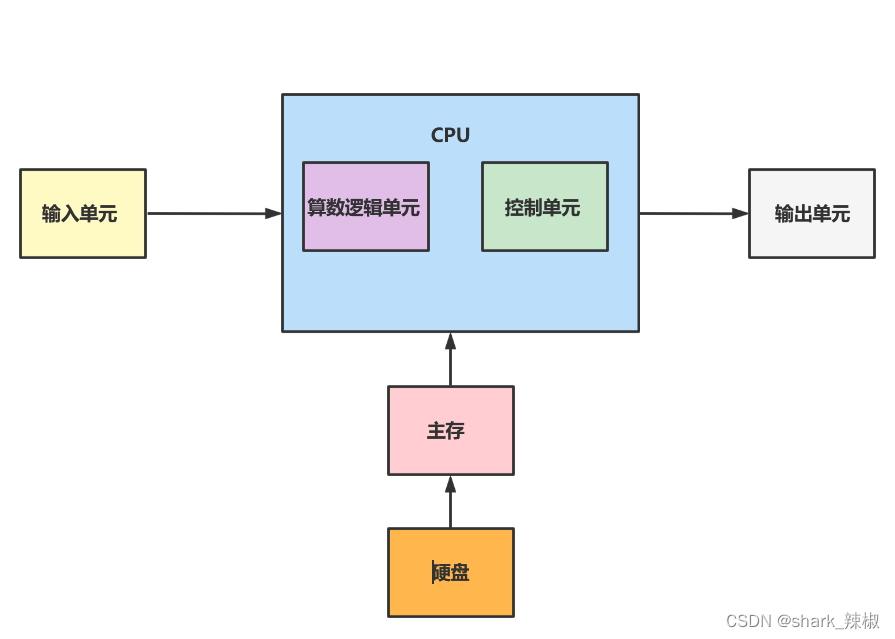
CPU架构初探
精简指令集(RISC)
CPU是包含特定指令集的芯片,而指令集大概可以分为精简指令集和复杂指令集,精简指令集特点很明显。指令所能处理的动作非常简单,并且执行效率极高,常用的常见就是导航系统、网络设备(路由器、交换机)等。
复杂指令集(CISC)
我们日常计算机所用x86架构所用的CPU就是包含复杂指令集的CPU,它所能处理的动作可以是非常复杂,所以执行效率相对精简指令集而言会低一些。常见的CISC微指令就是AMD,Intel这些。需要补充一点,之所以我们管现代所用的计算机结构叫x86的原因也正是因为Intel早年开发的一些列CPU代号都是86结尾。
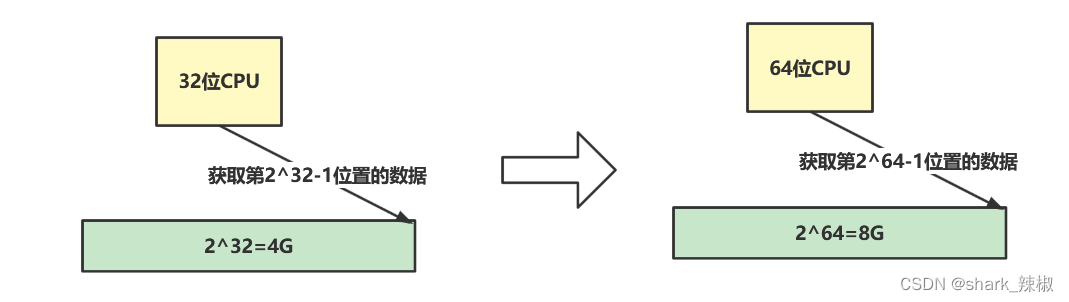
随着CPU的不断发展,计算机也从原来的32位发展到现在的64位,这就意味着CPU一次可以读写的数据也从原来的32位变为现代的64位,也意味着所能表示的内存地址从原来的4g变为8g。
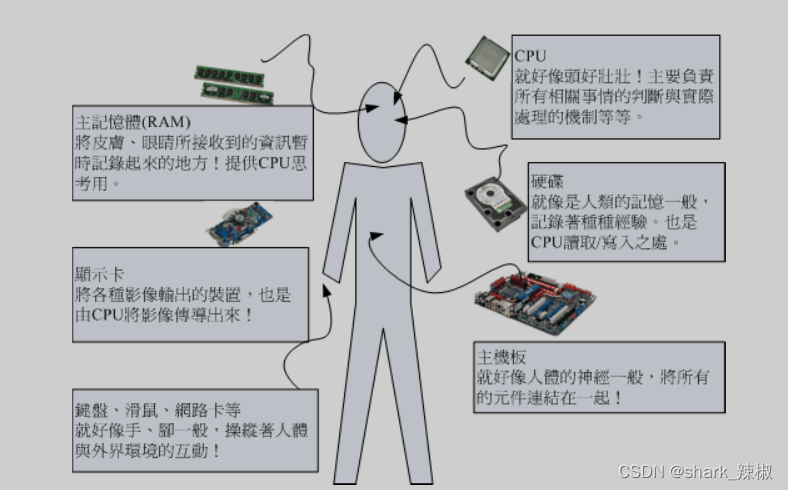
用人的构建来理解计算机的运作流程
了解了计算机硬件的组成部分,我们就可以通过人的构建来了解一下计算机的工作流程,我们都知道人是通过大脑进行思考和处理外界的传递的数据的,计算机中的CPU也是同理,他就好比计算机的大脑,通过CPU计算机就是将主存传入的数据进行运算,并交由输出单元传送出去。
人脑进行运算的数据有可能是从五官感知到的,也可能是从自己的记忆中拿到的。而主存就好比人类五官所感知到的记忆。这些数据可能是临时传入也可能是从硬盘中获取的,正是因为主存的存在,计算机才能快速的得到数据,并将数据交由CPU进行思考和处理。
人类对于日常工作处理所需要的数据大部分都来自记忆,而记忆是长期存储的数据。计算机也一样的,硬盘就扮演着存储长期数据的角色,当计算机需要某些数据的时候,主存就会去硬盘中获取这些数据交给CPU处理。
知道了数据处理的地方,那么我就该知道新的数据是从何处进行输入输出的,正如人类一样,人类是通过五官感知外界。而计算机则是通过输入和输出设备完成数据的运输,输入设备可以是鼠标、键盘等。输出设备可以是打印机、显示屏等。
有了计算组件、数据运输组件,那么我们也需要这些组件交互的渠道,人类是通过神经来连接这些组件的。而计算机则是通过主板将这些组件结合起来。
计算机上常用的计算单位
容量单位
容量单位的进率都是1024,但是bit和byte的进率是8。
1T=1024G
1G=1024M
1M=1024K
1K=1024Byte
1Byte=8bit
速度单位
速度单位最常见的就是网络速度,例如我们日常购买宽带时运营商都会告知宽带为百兆带宽。实际上百兆带宽就是100Mbps,这里的b是bit,所以换算成byte,百兆带宽的实际速度为100/8=12.5Mbyte
计算机设备硬件组成探究
聊到计算机组成我们基本是以AMD或者Intel两个主流派系,两者在历史长河中互相学习,架构已经非常类似了。
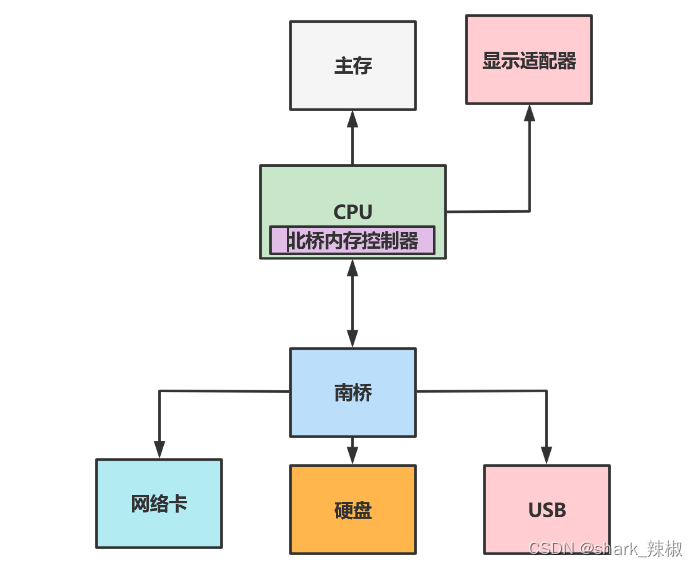
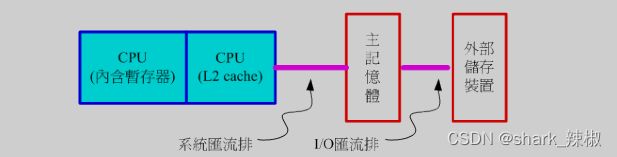
早期的主板会将结构分为南北两个部分,北桥负责桥接各种读取速度块的组件,例如主存、CPU、显示适配器等。而南桥负责桥接较慢的装置接口,例如硬盘、网络卡、usb等。
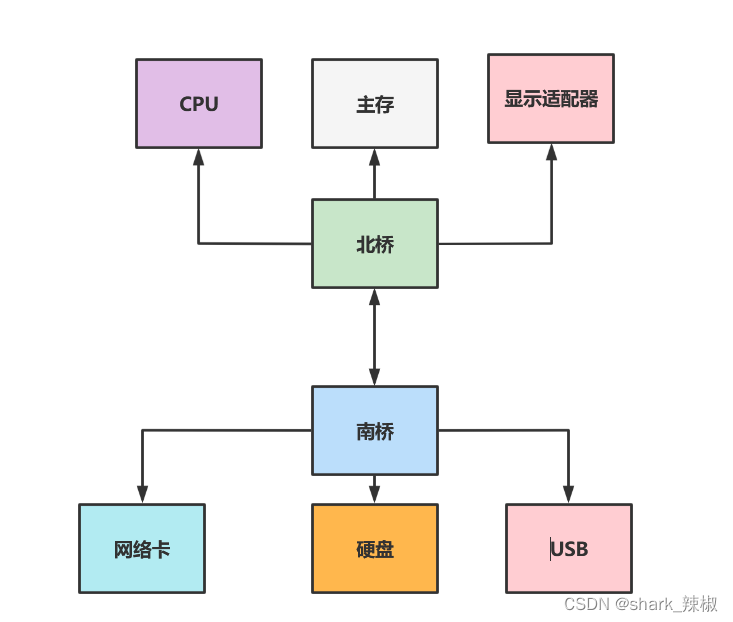
于是这就引发了一个问题,北桥的CPU要和主存交互时都需要经过北桥,这就会大大占用北桥的带宽,造成其他组件传输效率降低,于是CPU就被改进了,原本北桥中的内存控制器被放置到CPU中,所以现如今的CPU和主存交互都无需经过北桥这一环,传输效率自然高效许多。所以如今的x86计算机架构如下所示
CPU详解
我们以华硕主机来聊聊CPU这个东西,如图所示,这个插槽就是CPU的插槽,我们都知道使用不同的指令集CPU的执行效率都会有所不同,但是在同款CPU性能比较下(注意是同款CPU哦),频率也是CPU性能的一个重要指标,例如一个CPU的执行频率为 3.6GHz,这就代表着这个CPU的一秒可以执行3.6*10^3次的工作。

上文我们也提到了,早年的CPU和主存是通过北桥来交互数据的,但是CPU的执行效率远远高于主存的传输速度,所以为了平衡这一点,北桥还设置了一个叫FSB的东西来连接两者。并且为了适配CPU和其他组件的交互速度,CPU还将自己传输分为内频和外频。外频的速度适配外部组件的传输速度,内频则是CPU自己的速度,通过所以早年的CPU可以说是自己内部速度非常快,而外部还在不紧不慢和其他组件缓慢交互。
所以早年我们还会提到一个叫超频的概念,例如我们当前CPU外频率为300MHz,倍频为9,那么CPU的内频就是300*9≈3GHz。假如所以有些计算机硬件发烧友为了能够提高CPU的内频速度,会将外频率速度提高例如将外频率提高为500MHz,那么内频则被提高为4.5GHz,但是这么快的速度确实非正常设置,很可能会导致主机运行时出现宕机的情况。
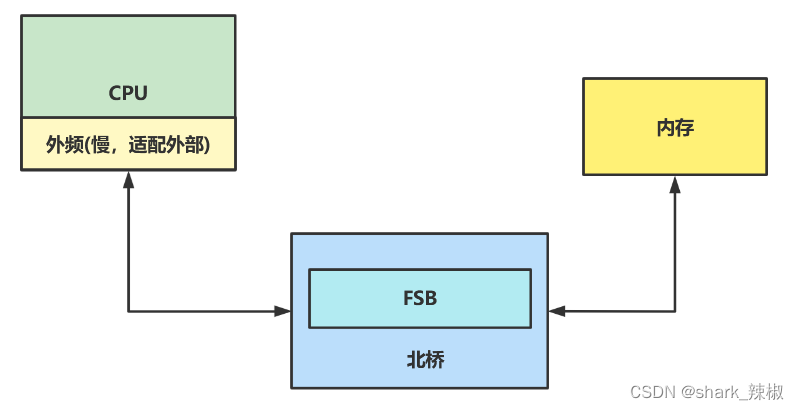
上述情况随着时代的发展,Intel使用DMI技术,AMD使用 Hyper Transport,使得CPU和主存以及其他组件交互都无需经过北桥了,所以现在的CPU都是自动超频的。
而另外一个参考指标则是CPU的核心数,现代计算机中一个CPU可能封装不止一个核心,这就使得一个CPU拥有两个核心一起帮忙运算,处理数据的速度自然快很多。
而影响CPU性能的指标也来自于外界,我们都知道CPU的数据都是从主存中获取的,而CPU和主存之间数据传入也是通过内存控制的FSB(前段总线传输速度)。假如内存控制芯片对主存的工作频率为1600Mz,以64位计算机而言,那么CPU最快带宽为1600Mhz64位8byte=12.8Gbyte/s
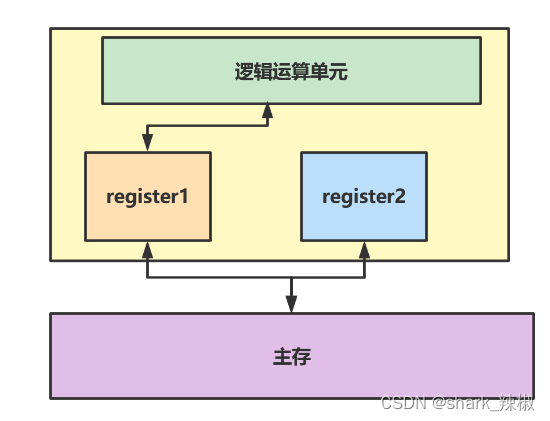
最后关于CPU性能我们还需要提示一个叫超线程的概念,我们都知道CPU运行速度非常之快,但是面对主存中大量的任务却无法及时的获取并处理完,这就使得CPU处在一个很尴尬的境地。对此设计者们就提出一个超线程的概念,这个概念与操作系统多任务切换类似,就是将CPU内部的register分成两个,让程序分别使用这俩缓存器,这俩缓存器会先后争抢CPU运算单元执行权。这就是使得当一个缓存器使用逻辑运算单元时,另一个缓存器就会去主存获取数据,两个齐头并进的工作着,执行效率就会高很多。
假如我们的CPU由4个核心,那么若开启超线程,那么逻辑上可能就有8个核心哦。
关于CPU信息,我们可以在Linux系统上键入以下命令查看
more /proc/cpuinfo
以笔者的云服务器为例,我们可以看到以下内容
# 逻辑处理器唯一标识符
processor : 0
# 代表处理器类型,下面这段配置就代表这个cpu为英特尔的
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
stepping : 1
microcode : 0x1
cpu MHz : 2499.994
cache size : 40960 KB
physical id : 0
# siblings 和cpu cores之间有一个对应关系,如果siblings 是cpu cores的两倍,那就说明当前cpu支持超线程,反之就有可能是CPU不支持超线程或者说超线程的功能未开启
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 20
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant
_tsc rep_good nopl nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c r
drand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsav
eopt arat
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit
bogomips : 4999.98
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
当然若想查看当前系统物理cpu个数,可键入以下命令
more /proc/cpuinfo |grep 'physical id'|sort
以笔者为例,当前服务器就会输出以下信息,这就意为着笔者的服务器为有16个物理CPU
physical id : 0
physical id : 10
physical id : 12
physical id : 14
physical id : 16
physical id : 18
physical id : 2
physical id : 20
physical id : 22
physical id : 24
physical id : 26
physical id : 28
physical id : 30
physical id : 4
physical id : 6
physical id : 8
若我们想查看每个CPU内核个数,我们可以键入以下命令
more /proc/cpuinfo |grep 'cpu cores'
可以看到笔者使用的服务器的CPU都是单核心的
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
cpu cores : 1
我们也可以键入以下命令查看逻辑CPU个数以及超线程个数的总和,通过输出可知我们知道最终总数为16
cat /proc/cpuinfo | grep "processor" | wc -l
16
内存详解
上文已经说明了CPU和主存决定的计算机执行效率,所以我们再来聊聊内存,内存一般都是一条条芯片,以华硕主机为例子,他会被插在下图所示的插槽中,对于个人计算机而言,需要处理的数据都必须加载到内存中才能被执行,而且内存中的数据如果没有及时报错的话,关机后就会消失。

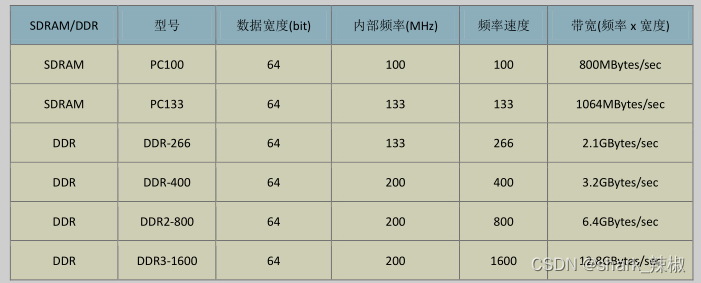
而内存SD RAM和DDR RAM两种情况,如下图,他们的带宽都是频率*宽度/8,可以看到DDR的频率比较高所以带宽也相对大些,现在主流的主存都是使用DDR4的内存了。
除此之外,内存还需要考虑的另一个因素就是容量,只有足够大的容量还能保证从辅存中读取的数据会在处理前呆在内存中,不会因为内存不足而被置换出去,直到被CPU执行。从上文我们也看到内存插槽有4个,之所以有这么多就是因为通过增加插槽数目可以增加更多的内存条,从而提高容量的通信也增加了通道,假如一支内存只有64位,那么两条内存条带宽就会达到128位。那么容量就是16G了。
现代计算机为了保证常用数据会快速被响应执行,就在CPU中增加了一个二级缓存,所以当从主存读取的数据执行完成后,有可能会滞留在CPU二级缓存中,二级缓存的执行速度和CPU是一样的,这就是使得计算机的执行性能再次提高。
有一段重要的程序BIOS,他存储的计算机的硬件信息以及开机设备等选择项,他原本是存在ROM(只读存储器)中,他是一个会挥发性内存,所有数据都会长期保留在内存中且不会修改,但是现代计算机发展速度太快了,这种做法带来了很大的不便,所以为了能够修改这段程序,BIOS现在一般都存到闪存(flash)或者EEPROM中。
显示适配器
显示适配器又称为VGA,因为显示的图形图像的颜色会占用内存,所以显示适配器的容量就会决定图像显示的质量。
而且现如今社会,大量的3D特效出现,这些特效都是需要运算的,早年我们会将运算的任务交给CPU处理,但是CPU实在太忙碌了,所以显示适配器的厂商如今都会在显示适配器中内嵌一个加速芯片来完成运算,这就是所谓的GPU。

除此之外,显示适配器也也需要和CPU等组件进行沟通,所以数据的传输效率也决定的显示的效率,先主流的显示适配器的规格如下,基本都是采用pcie,这就使得传输速度也是杠杠的。
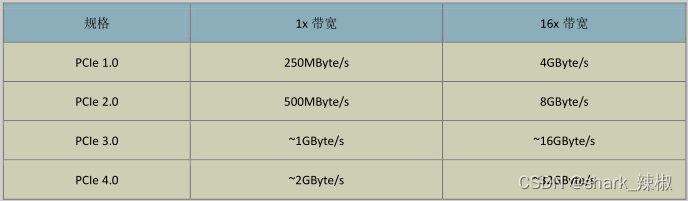
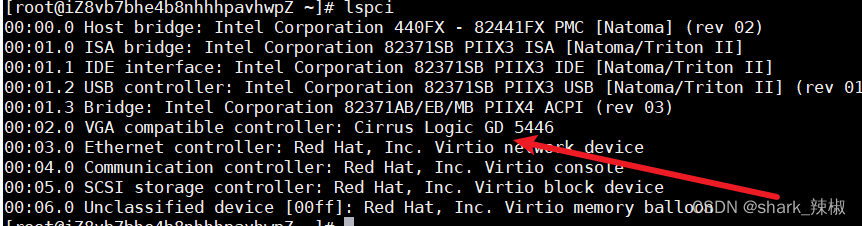
所以,如果我们需要看到pcie规格所对应的显示适配器的信息,我们完全可以键入以下命令查看
lspci
可以看到笔者服务器所对应的显示适配器为Cirrus Logic GD 5446这个型号的
硬盘与存储设备
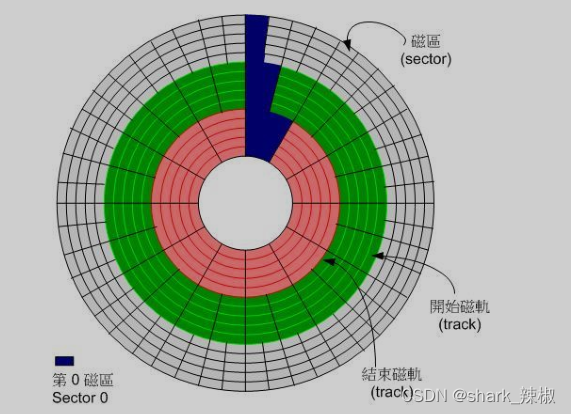
最后就是硬盘了,早期的辅存设备就是硬盘,如下所示

他对数据的读写都是通过转动磁头来进行的,而且因为磁盘外圈大的原因,所以这种硬盘写数据都是从外往内写的
同样的磁盘传输速度也是非常重要的,传统磁盘连接界面包括有 SATA, SAS, IDE 与 SCSI 等等,但如今
SATA已将IDE取代,而SAS已将SCSI 取代。如下图所示,这就是SATA的插槽
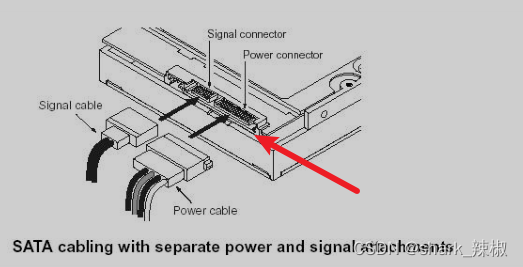
不同版本的SATA传输速度如下

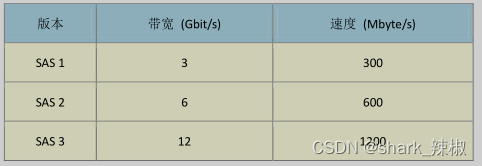
虽然SAS传输速度比SATA好,但碍于价格过于昂贵,所以个人计算机不常用,对此我们对SAS速度做个了解就好了
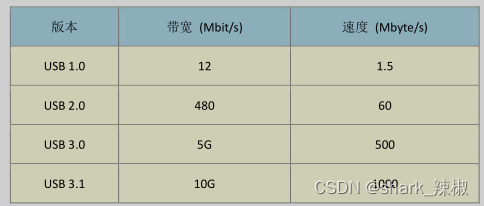
USB相比大家都知道了,这里我们也就做个简单的介绍
最后我们就来介绍主流的辅存设备了,固态硬盘(SDD),如今的电脑基本都是使用固态硬盘的,与传统磁盘不同的是,他不需要马达以及转动获取数据,他都是透过内存随机存取的。所以读取速度基本没有延迟,如今的笔记本基本都是使用固态硬盘了。在2016年的时候Intel顶级的ssd已经可以达到500Mbyte/s,这已经可以比肩SATA3了。更何况今日呢?所以传统磁盘已主键被淘汰,我们日常使用个人计算机的基本都是使用SSD了。
关于这些辅存设备信息,我们同样可以使用lspci查看,如下所示,这就笔者服务上所能看到的usb接口、SATA接口等各个接口对应的设备信息。
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.1 IDE interface: Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II]
00:01.2 USB controller: Intel Corporation 82371SB PIIX3 USB [Natoma/Triton II] (rev 01)
00:01.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 03)
00:02.0 VGA compatible controller: Cirrus Logic GD 5446
00:03.0 Ethernet controller: Red Hat, Inc. Virtio network device
00:04.0 Communication controller: Red Hat, Inc. Virtio console
00:05.0 SCSI storage controller: Red Hat, Inc. Virtio block device
00:06.0 Unclassified device [00ff]: Red Hat, Inc. Virtio memory balloon
参考文献
鸟哥的Linux私房菜
循序渐进Linux(第2版)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)