论文标题:ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
论文作者:Chuang Gan, Jeremy Schwartz, Seth Alter, Damian Mrowca, Martin Schrimpf, James Traer, Julian De Freitas, Jonas Kubilius, Abhishek Bhandwaldar, Nick Haber, Megumi Sano, Kuno Kim, Elias Wang, Michael Lingelbach, Aidan Curtis, Kevin Feigelis, Daniel M. Bear, Dan Gutfreund, David Cox, Antonio Torralba, James J. DiCarlo, Joshua B. Tenenbaum, Josh H. McDermott, Daniel L.K. Yamins
论文原文:https://arxiv.org/abs/2007.04954
论文出处:NeurIPS 21
论文被引:202(12/18/2023)
论文代码:https://github.com/threedworld-mit/tdw
项目主页:https://www.threedworld.org/
Abstract
我们介绍 ThreeDWorld (TDW),这是一个交互式多模态物理仿真平台。TDW 可在丰富的3D环境中模拟高保真感官数据以及移动智能体(mobile agent)和物体之间的物理交互。其独特性能包括:
-
1)逼真的实时图像渲染;
-
2)具有用于高质量渲染的材质的物体和环境库,以及允许用户自定义资源库的例程;
-
3)高效构建新环境类别的生成程序;
-
4)高保真音频渲染;
-
5)各种材料类型(包括布、液体和可变形物体)的逼真物理交互;
-
6)一系列 avatar 类型,用作具身人工智能智能体,并且可定制;
-
7)对人类与 VR 设备交互的支持。
TDW 的 API 可让多个智能体在模拟中进行交互,并返回一系列代表世界状态的传感器和物理数据
。我们将介绍 TDW 在计算机视觉、机器学习和认知科学新兴研究方向上的初步实验,包括多模态物理场景理解、物理动力学预测、多智能体交互、像孩子一样学习的模型,以及人类和神经网络的注意力研究。
1 Introduction
人工智能研究的一个长期目标是设计出能够与世界互动的机器智能体,无论是在家里、战场上还是在外太空提供帮助。这类人工智能系统必须
学会从物理角度感知和理解周围的世界,以便能够操纵物体和制定执行任务的计划
。开发此类智能体并为其设定基准的一大挑战是训练智能体的逻辑困难。
机器感知系统通常是在人类费力标注的大型数据集上进行训练的,而新任务往往需要新的数据集,获取这些数据集的成本很高
。而用于与世界交互的机器人系统则面临着更大的挑战——在真实世界环境中通过试验和错误进行训练的速度很慢,因为每次试验都是实时进行的,而且成本高昂,如果错误对训练环境造成破坏,还有可能带来危险。因此,越来越多的人开始关注使用模拟器来开发和基准化人工智能和机器人学习模型[25, 47, 36, 38, 49, 11, 42, 50, 7]。
世界模拟器原则上可以大大加快人工智能系统的开发。有了虚拟世界中的虚拟智能体,训练就不必受到实时性的限制,也不会因出错(如掉落物品或撞墙)而付出代价。此外,通过合成生成场景,研究人员可以完全控制数据的生成,完全访问所有生成参数,包括质量等人类观察者不易察觉、因此难以标注的物理量。因此,
机器感知系统可以在一些任务上进行训练,而这些任务并不适合传统的大量标注真实世界数据的方法
。原则上,世界模拟器还可以模拟各种各样的环境,这对于避免过拟合至关重要。
在过去的几年中,针对具身人工智能(embodied AI),场景理解(scene understanding)和物理推理(physical inference)等领域的特定研究问题,推出了各种各样的模拟环境。模拟器促进了下述方面的研究。
-
导航,如 Habitat [38],iGibson [48]
-
机器人操纵,如 Sapien [50]
-
具身学习,如 AI2Thor [25]
这些模拟器在计算机视觉和机器人学领域带来了许多挑战,其影响力可见一斑。现有的模拟器各有所长,但由于它们在设计时往往考虑到了特定的使用情况,因此也在不同方面受到了限制。
原则上,一个系统可以在一个模拟器中进行视觉训练,在另一个模拟器中进行导航训练,在第三个模拟器中进行物体操作训练。不过,切换平台对研究人员来说成本很高
。

ThreeDWorld(TDW)是一个通用虚拟世界仿真平台,支持物体与智能体之间的多模态物理交互。TDW 设计用于人工智能的一系列关键领域,包括
感知、交互和导航,目标是在单个模拟器中实现这些领域的训练
。与现有的模拟环境不同的是,它
结合了高保真视频和音频渲染、逼真的物理效果和单一灵活的控制器
。
在本文中,我们将介绍 TDW 平台及其主要特点,以及几个示例应用,以说明其在人工智能研究中的应用。这些应用包括:
-
1)在与 ImageNet 相当的 TDW 图像分类数据集上训练的学习视觉特征表示,可用于细粒度图像分类和物体检测任务;
-
2)通过 TDW 音频撞击合成生成的撞击声合成数据集,用于测试材料和质量分类,利用 TDW 处理复杂物理碰撞和非刚性变形的能力;
-
3)经过训练的智能体可预测新环境中的物理动态;
-
4)TDW 支持多个智能体,可实现复杂的多智能体交互和社交行为;
-
5)将 VR 中的人类观察者与神经网络智能体进行注意力对比实验。
Related Simulation Environments
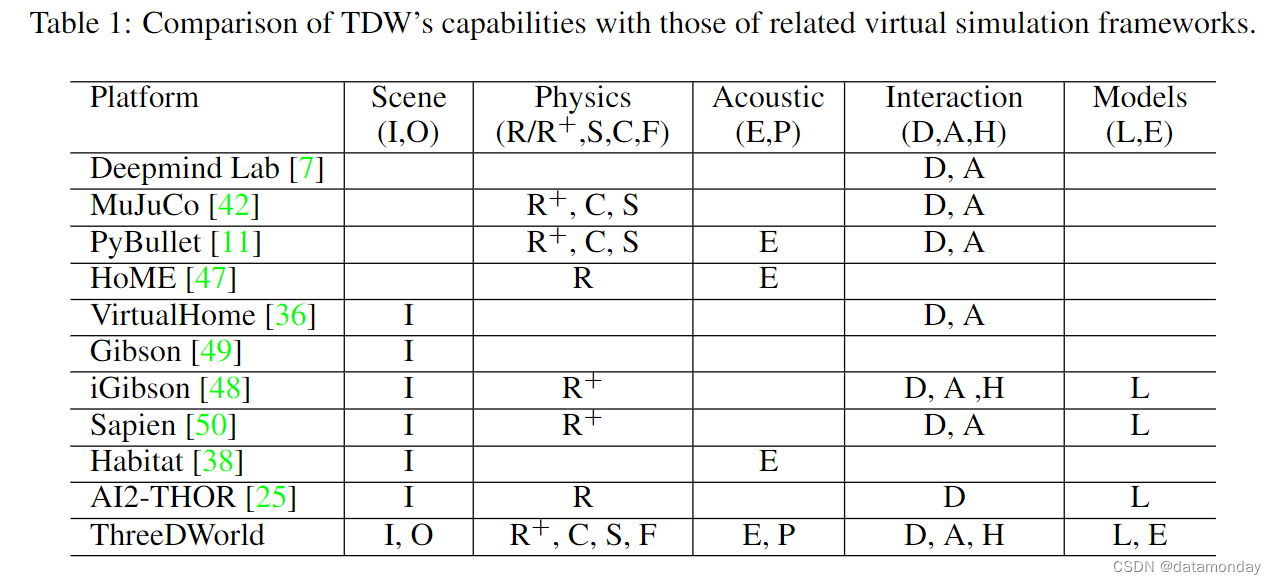
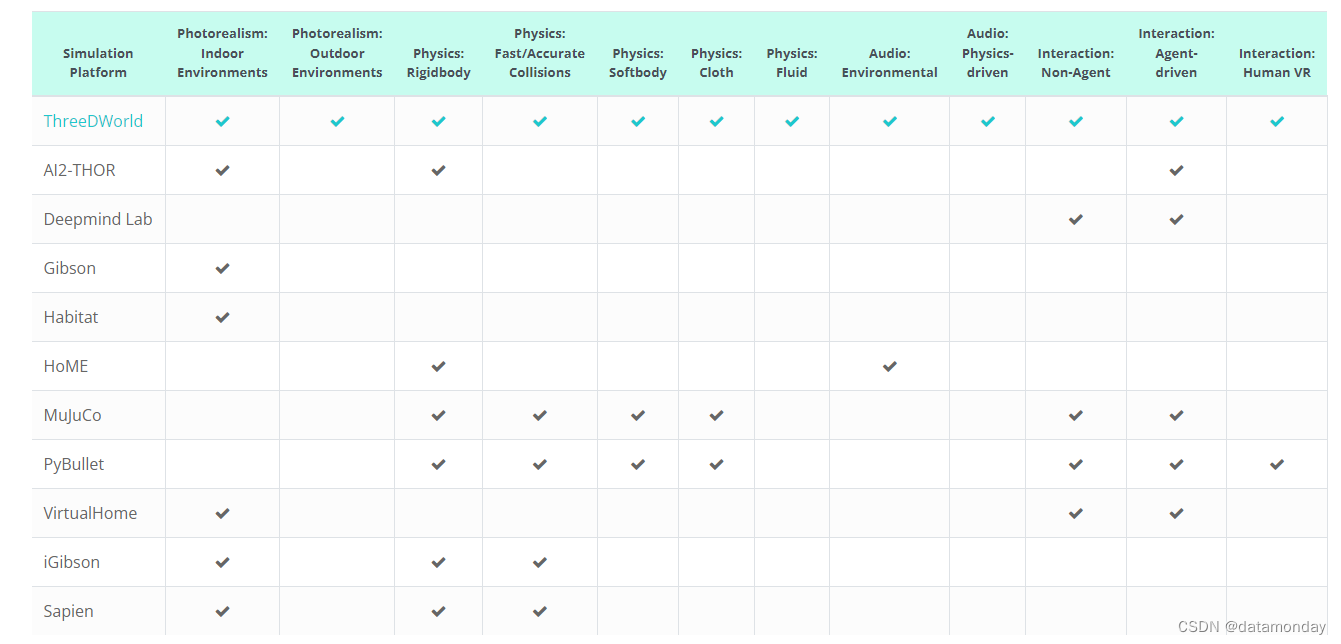
Summary: Table 1 shows TDW differs from these frameworks in its support for different types of:
-
Photorealistic scenes: indoor (I) and outdoor (O)
-
Physics simulation: just rigid body ® or improved fast-but-accurate rigid body (R+), soft body (S), cloth © and fluids (F)
-
Acoustic simulation: environmental (E) and physics-based §
-
User interaction: direct API-based (D), agent-based (A) and human-centric using VR (H)
-
Model library support: built-in (L) and user-extensible (E)
TDW 与许多其他现有仿真环境的
不同之处在于,它可以支持多种潜在用例
。表 1 简要比较了 TDW 与现有环境的特点。这些环境包括:
-
AI2-THOR[25]
-
HoME[47]
-
VirtualHome[36]
-
Habitat[38]
-
Gibson[49]
-
iGibson[48]
-
Sapien[50]
-
PyBullet[11]
-
MuJuCo[42]
-
Deepmind Lab[7]
TDW 的独特之处在于它支持:
-
a) 对室内和室外环境进行近乎逼真的实时渲染;
-
b) 基于物理的模型,可通过物体与物体之间的交互生成情景声音(图 1h);
-
c) 用自定义物体配置程序化创建自定义环境;
-
d) 由于独特地结合了高分辨率物体几何和快速但精确的高分辨率刚体物理(表 1 中用 "R+"表示),物体之间的交互非常逼真;
-
e) 基于英伟达 Flex 引擎的复杂非刚体物理;
-
f) 一系列用户可选的化身智能体;
-
g) 用户可扩展的模型库。
2 ThreeDWorld Platform
2.1 Design Principles and System Overview
Design Principles
我们的核心贡献是将几个现有的实时高级物理引擎集成到一个框架中,该框架还能生成高质量的视觉和听觉渲染效果。在进行整合时,我们遵循了三个设计原则:
-
集成应具有灵活性。也就是说,用户应能轻松设置各种物理场景,将任何类型的物体放置在任何状态下的任何位置,并提供可控的物理参数。这样,研究人员就能创建具有高度可变情况的物理相关基准,同时还能对这些情况生成近乎逼真的渲染。
-
物理引擎应涵盖各种各样的物体交互。我们通过无缝集成 PhysX(优秀的刚体模拟器)和 Nvdia Flex(用于非刚性和刚性-非刚性交互的最先进的多材料模拟器)来实现这一目标。
-
应该有一个大型的高质量资产库,其中包含精确的物理描述符以及逼真的刚性和非刚性材料类型,使用户能够利用物理引擎的强大功能,轻松制作出有趣、有用的物理场景。
System Overview
TDW 模拟由两个基本组件组成:
-
i) 生成器(Build),这是一个在 Unity3D 引擎上运行的编译可执行文件,负责图像渲染、音频合成和物理模拟;
-
ii) 控制器(Controller),这是一个与生成器通信的外部 Python 接口。用户可以通过它定义自己的任务,使用包含 200 多条命令的应用程序接口。
模拟运行遵循一个循环,其中包括:
-
1)控制器向构建程序发送命令;
-
2)构建程序执行这些命令,并将仿真输出数据发送回控制器。
与其他仿真平台不同的是,TDW 的 API 命令可以组合成列表,并在单个时间步内发送给构建器,从而可以仿真任意复杂的行为
。研究人员可以使用这一核心应用程序接口作为基础,在此基础上构建更高级别的,特定于应用的应用程序接口 “层”,从而大大缩短开发时间,实现广泛的不同用例。
2.2 Photo-realistic Rendering
TDW 使用 Unity 的底层游戏引擎技术进行图像渲染,并添加了自定义照明方法,以实现室内和室外场景近乎逼真的渲染质量。
Lighting Model
TDW 使用两种类型的照明:
-
一种是模拟太阳直射光的单一光源
-
另一种是利用高动态范围(HDRI)图像的 “skybox” 提供的间接环境照明
详见图 1(a-c)和附录。对虚拟相机还进行了其他后期处理,包括曝光补偿、色调映射和动态景深(示例)。
3D Model Library
为了最大限度地控制图像质量,我们创建了一个由高分辨率3D模型优化而成的三维模型资产库。这些模型使用基于物理的渲染(PBR)材料,以物理上正确的方式对光线做出反应。该库包含约 2500 个物体,按 Wordnet 词组分类,涵盖 200 个类别,包括家具、电器、动物、车辆和玩具等。我们的材料库包含 10 个类别的 500 多种材料,其中许多是从真实世界的材料中扫描而来。
Procedural Generation of New Environments
在 TDW 中,运行时虚拟世界或场景是利用3D模型库资产创建的。环境模型(内部或外部)以各种方式填充物体模型,从完全程序化(即基于规则)到按主题组织(即明确脚本)。TDW 不限制哪些模型可用于哪些环境,因此场景配置的数量和类型不受限制。
2.3 High-fidelity Audio Rendering
多模态渲染是 TDW 的一个独特方面,我们的音频引擎既能生成物理驱动的撞击声,也能进行混响和空间化声音模拟。
Generation of Impact Sounds
TDW 的 PyImpact 是一个使用模态合成生成撞击声的 Python 库[43]。PyImpact 使用材料类型等物理事件信息,以及碰撞物体的速度、法向量和质量来合成撞击时播放的声音(示例)。这种 “往返” 过程是实时的。合成功能目前正在扩展,以包括刮擦和滚动声音[1]。
Environmental Audio and Reverberation
对于放置在室内环境中的声音,TDW 结合使用 Unity 的内置音频和 Resonance Audio 的 3D 空间化技术,通过与头部相关的传递函数提供实时音频传播、高质量模拟混响和方向提示。声音会根据距离衰减,并可能被物体或环境几何体遮挡。混响会随着空间的几何形状、应用于墙壁、地板和天花板的虚拟材料以及固体物体(如家具)所占房间容积的百分比而自动变化。
2.4 Physical Simulation
在 TDW 中,物体行为和交互由物理引擎处理。TDW 现在集成了两个物理引擎,既支持刚体物理,也支持更先进的软体、布料和流体模拟。
Rigid-body physics

Unity 的刚体物理引擎 (PhysX) 处理涉及刚体间碰撞的基本物理行为。为了实现精确而高效的碰撞,我们使用了强大的 V-HACD 算法[31]来计算每个库物体网格周围的 “形状拟合” 凸壳碰撞器,以简化碰撞计算(见图 2)。此外,物体的质量会在导入时根据其体积和材料密度自动计算出来。不过,也可以使用应用程序接口命令,按每个物体动态调整质量或摩擦力,以及视觉材料外观,从而实现视觉外观与物理行为的潜在分离(例如,物体看起来像混凝土,但弹跳起来像橡胶)。
Advanced Physics Simulations
TDW 的第二个物理引擎(Nvidia Flex)使用基于粒子的表示方法来管理不同物体类型之间的碰撞。TDW 支持刚体、软体(可变形)、布料和流体模拟,如图 1(d)所示。这种统一的表示法有助于机器学习模型使用底层物理和渲染图像,通过与世界中的物体交互来学习世界的物理和视觉表示法。
2.5 Interactions and Agents
TDW 提供了三种与 3D 物体交互的模式:
-
1)使用 API 命令直接控制物体行为。
-
2)通过人工智能智能体进行间接控制。
-
3)人类用户在虚拟现实(VR)中进行直接交互。
Direct Control
TDW 中的默认物体行为完全基于物理,通过 API 中的命令实现;没有任何脚本动画。使用基于物理的命令,用户可以通过施加给定大小和方向的脉冲力来移动物体。
Agents
人工智能智能体有几种类型:
-
用于生成第一人称渲染图像、分割和深度图的非实体摄像头。
-
基本的具身智能体,其化身(avatars)是几何原型,如球体或胶囊,可在环境中移动,通常用于算法原型开发。
-
更复杂的化身具有用户定义的物理结构和相关的物理映射行动空间。例如,TDW 的 Magnebot 是一个复杂的机器人躯体,完全由物理驱动,其关节臂的末端为 9-DOF 末端执行器(图 1e)。通过使用其高级 API 中的命令,如 reach_for(目标位置)和 grasp(目标物体),Magnebot 可以打开箱子或拿起和放置物体。
此外,作为实现模拟与现实转换的第一步,
研究人员还可以将标准 URDF 机器人规范文件导入 TDW,并使用 Fetch、Sawyer 或 Baxter 等实际机器人类型作为具身智能体
。
智能体可以在环境中移动,同时对物理做出响应,利用物理驱动的铰接功能改变物体或场景状态,或者与场景中的其他智能体进行交互(图 1f)。
Human Interactions with VR devices
TDW 还支持用户使用 VR 直接与 3D 物体进行交互。用户看到的是自己双手的三维呈现,它能追踪自己双手的动作(图 1g)。利用应用程序接口命令,物体可被 “抓取”,这样,物体与虚拟手之间的任何碰撞都允许用户拿起、放置或扔出物体(示例)。这一功能可以收集人类行为数据,并允许人类与虚拟化身进行交互。
3 Example Applications
3.1 Visual and Sound Recognition Transfer
我们定量研究了使用 TDW 生成的图像和音频数据学习到的特征表征在真实世界场景中的迁移情况。
Visual recognition transfer
我们生成了一个规模与 ImageNet 相当的 TDW 图像分类数据集;通过将 TDW 的 2,000 个物体模型中的一个随机放置在随机条件(天气、时间)的环境中,并将随机放置的虚拟摄像头对准物体拍摄快照,生成了 130 万张图像(详情见附录)。
我们分别在 ImageNet [12]、SceneNet [19]、AI2-Thor [25] 和 TDW 图像数据集上预训练了四个 ResNet-50 模型 [20]。我们直接下载了 ImageNet [12] 和 SceneNet [19] 的图像进行模型训练。为了进行公平比较,我们还使用控制器创建了一个包含 130 万张图像的 AI2-THOR 数据集,该控制器可捕捉场景中的随机图像,并根据 ImageNet synset ID 对其分割掩码进行分类。然后,我们使用飞机[30]、鸟类[44]、CUB[45]、汽车[26]、狗[23]、花卉[34]和食物数据集[8],通过对下游细粒度图像分类任务进行微调来评估学习到的表征。我们使用 ResNet-5- 网络结构作为所有视觉感知迁移实验的骨干。在预训练中,我们将初始学习率设为 0.1,并进行余弦衰减和 100 轮训练。然后,我们将预训练的权重作为初始化权重,并在细粒度图像识别任务中进行微调,使用 0.01 的余弦衰减初始学习率,并在细粒度图像识别数据集上训练 10 个历时。表 2 显示,从 TDW 生成的图像中学习到的特征表征大大优于从 SceneNet [ 19 ] 或 AI2-Thor [ 25 ] 中学习到的特征表征,并已开始接近从 ImageNet 中学习到的特征表征的质量。这些实验表明,尽管仍有大量工作要做,但 TDW 已经在模仿使用大规模真实世界数据集进行模型预训练方面迈出了有意义的一步。使用更大的转换器架构[13 ]和更多 TDW 生成的图像可能会进一步缩小与 Imagenet 预训练模型在物体识别任务上的差距。我们已经开源了完整的图像生成代码库,以支持未来类似方向的研究。
Sound recognition transfer
我们还创建了一个音频数据集,以测试从撞击声中对材料进行分类的能力。我们录制了 300 个不同材料(纸板、木材、金属、陶瓷和玻璃;每种材料有 4 到 15 种不同的物体)的声音片段,每种材料都受到从 2 到 75 厘米高处掉落的精选颗粒(木材、塑料、金属;每种材料的颗粒大小不一)的撞击。与物体相比,小球本身产生的共振声微不足道,但由于每个小球优先激发不同的共振模式,因此撞击声取决于小球的质量和材料、撞击的位置和力度,以及共振物体的材料、形状和大小[43](更多视频示例)。
鉴于其他因素的可变性,从该数据集中进行材料分类并非易事。我们在 TDW 和 sound-20K 数据集[53] 的模拟音频上训练了材料分类模型。我们测试了它们对真实世界音频中的物体材料进行分类的能力。我们将原始音频波形转换为声音频谱图表示法,并将其输入在 AudioSet[18]上预先训练好的 VGG-16。在进行物体分类训练时,我们将初始学习率设为 0.01,并采用余弦衰减法进行 50 轮训练。如表 3 所示,在 TDW 音频数据集上训练的模型比在 Sound20k 数据集上训练的模型提高了 30% 以上的准确率。这种改进可能是因为 TDW 产生的声音比 Sound20K 更多样化,可以防止网络过度适应合成音频集的特定特征。

Multi-modal physical scene understanding
我们使用 TDW 图形引擎、物理模拟和 2.3 节所述的声音合成技术,生成物体掉落在平面(桌面和长凳)上的视频和撞击声。这些表面被渲染成 5 种材料之一的视觉外观。物体和材料外观以及轨迹和弹性等物理特性的高度变化,使网络无法记住特征(例如,物体在金属上的反弹力大于纸板)。训练集和测试集具有相同的材料和质量类别。不过,测试集视频中的物体、桌子、运动模式和撞击声都与训练集视频中的不同。在所有视频中,掉落物体的身份、大小、初始位置和初始角动量都是随机的,以确保每个视频都有独特的运动和反弹模式。桌子的形状、大小和方向以及表面纹理渲染(例如,木桌可以渲染为 “雪松”、“松木”、“橡木”、“柚木” 等)都是随机的,以确保每张桌子的外观都是独一无二的。PyImpact 使用共振模式的随机采样来创建撞击声,因此每个视频中的撞击声都具有独特的时空结构。
对于纯视觉基线,我们使用在 ImageNet 上预先训练好的 ResNet-18 从每个视频帧中提取视觉特征,并对 25 个视频帧进行平均池化,从而得到 2048-d 的特征向量。对于纯音频基线,我们将原始音频波形转换为声音频谱图,并将其作为在 AudioSet 上预先训练的 VGG-16 的输入。然后,每个音频片段都被表示为一个 4096-d 的特征向量。然后,我们将纯视觉特征、纯声音特征以及视觉和声音特征的组合作为输入,输入到经过材料和质量分类训练的 2 层 MLP 分类器中。结果(表 4)显示,在这两项分类任务中,音频比视频更具诊断性,但最佳性能需要视听(即多模态)信息,这突出了现实多模态渲染的实用性。
3.2 Training and Testing Physical Dynamics Understanding
模仿人类对物理的直观理解的可变前向预测器对于基于深度学习的模型规划和控制应用具有重要意义 [28 , 4 , 32 , 16 , 5 , 10 , 2 , 39 , 14 , 15 , 35, 51]。虽然为计算机图形学构建的传统物理引擎(如 PhysX 和 Flex)取得了长足进步,但这些程序通常都是硬连线的,因此很难应用于真实世界中机器人遇到的新物理情况,而且将其集成到更大的可学习系统中也具有挑战性。因此,创建用于直观物理预测的端到端可微分神经网络是一个重要的研究领域。然而,学习物理预测器的质量和可扩展性一直受到限制,部分原因是无法获得有效的训练数据。因此,这一领域为 TDW 提供了一个引人注目的用例,凸显了其先进的物理模拟能力。
Advanced Physical Prediction Benchmark

more video examples: https://drive.google.com/file/d/1o6M3eXp13bipC9xA3q4PFSaRQkc9rjp4/view
我们利用 TDW 平台创建了一个全面的 Pysion 基准,用于训练和评估物理逼真的前向预测算法[6]。
该数据集包含大量不同的物理场景轨迹,包括来自视觉、深度、音频和力传感器的所有数据,每帧的高级语义标签信息,以及所有情况下的潜在生成参数和代码控制器
。该数据集远远超越了 IntPhys [37] 等现有的相关基准,提供了大量复杂的真实世界物体几何形状、照片般逼真的纹理以及各种刚性、软体、布料和流体材料。图 3 显示了该数据集中的示例场景,这些场景被分为若干子集,突出了物理场景理解中的重要问题,包括:
-
物体持久性(Object Permanence):物体永恒性是人类直观物理学的核心特征[41],智能体必须学会物体在离开视线后仍然存在。
-
阴影(Shadows):TDW 的照明模型允许智能体同时区分物体的内在属性(如反射率、纹理)和外在属性(物体呈现的颜色),这对于理解外观会随环境变化而变化,而基本物理属性不会变化的道理至关重要。
-
滑动与滚动(Sliding vs Rolling): 预测物体滚动与滑动之间的区别,对于成年人来说是件容易的事,但这需要一个复杂的物理心智模型。智能体必须了解物体的几何形状如何影响运动,以及摩擦力的一些基本方面。
-
稳定性(Stability): 现实世界中的大多数任务都需要了解物体的稳定性和平衡性。在模拟框架中,物体的相互作用会预先确定稳定的结果,与此不同,使用 TDW,智能体可以学习了解几何形状和质量分布如何受到重力的影响。
-
简单碰撞(Simple Collisions): 智能体必须了解动量和几何如何影响碰撞,才能知道物体接触时发生的情况会影响我们与它们的交互。
-
复杂碰撞(Complex Collisions): 动量和高分辨率物体几何图形有助于智能体理解大型表面(如物体)可以参与碰撞,但不太可能移动。
-
悬垂与折叠(Draping & Folding): 通过模拟布料和刚体的不同行为,TDW 可让智能体了解软材料会根据与之接触的物体的不同而被操纵成不同的形态。
-
浸没(Submerging): 流体行为与实体物体行为不同,流体呈现容器形状和物体置换流体的交互对于许多现实世界的任务非常重要。
Training a Learnable Intuitive Physics Simulator
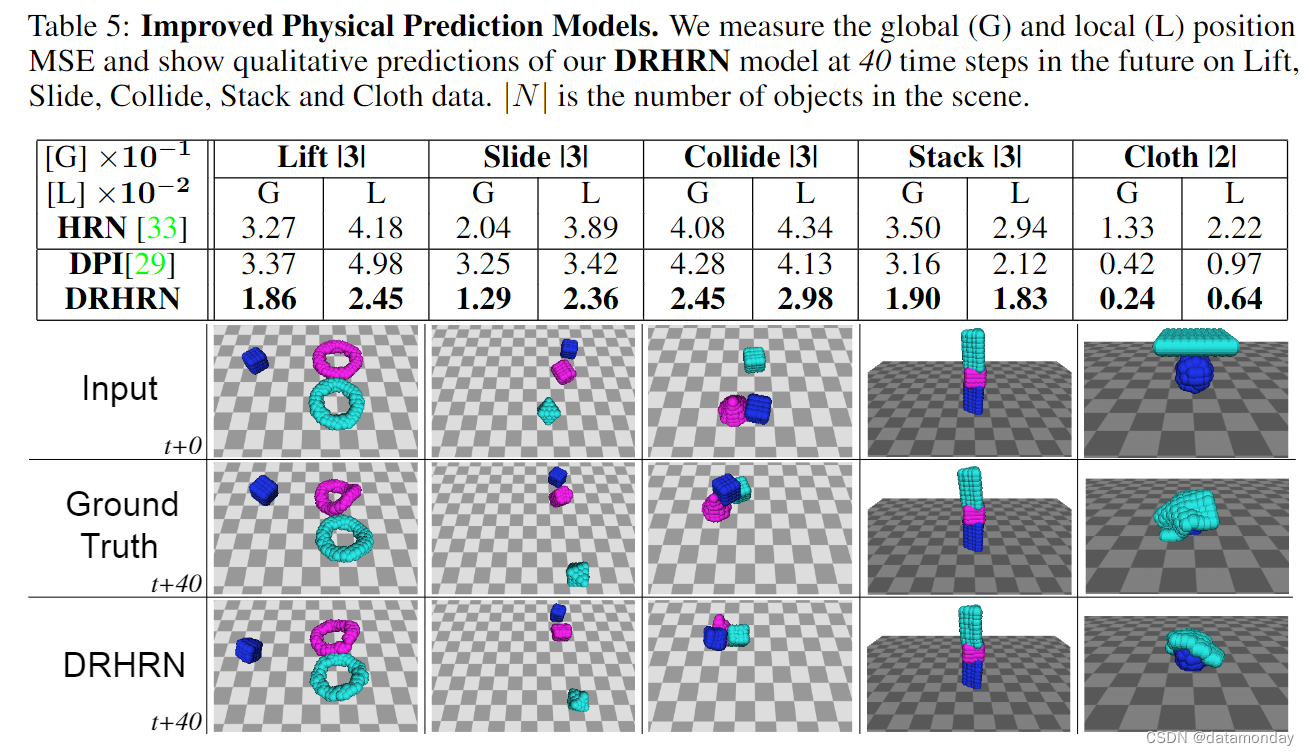
分层关系网络(HRN)是最近发表的一种基于分层图卷积的端到端可微分神经网络,可以学习预测这种表示法中的物理动态[33]。HRN 依赖于基于部件的分层物体表示法,涵盖了多种类型的三维物体,包括任意刚性几何形状、可变形材料、布料和流体。在此,我们在 TDW 生成的大规模物理数据上训练 HRN,作为 TDW 物理仿真能力的概念验证。在 HRN 的基础上,我们还引入了新的动态递归 HRN(DRHRN)(网络详情见附录),利用 TDW 数据集生成过程的额外能力,改进了物理预测结果。
Experimental settings
为了评估 HRN 和 DRHRN 的准确性和通用性,我们使用了高级物理理解基准中的一个场景子集。我们使用不同形状(碗、圆锥、立方体、哑铃、八面体、五边形、平面、柱面、棱柱、环形、球形)和材料(布、硬质、软质)的物体来构建以下场景:
-
1)lift subset,物体被升起后落回地面。
-
2)slide subset,物体在摩擦力作用下被水平推到表面上。
-
3)collide subset,物体相互碰撞。
-
4)stack subset,其中物体(不)稳定地堆叠在一起。
-
5)cloth subset,在这个子集中,一块布被丢在一个物体上,或者被放在下面并被抬起。
前四个场景中都放置了三个物体,因为至少需要三个物体才能学习间接的物体交互(如堆叠)。每个子集由 256 帧轨迹组成,其中 350 帧用于训练(约 90,000 个状态),40 帧用于测试(约 10,000 个状态)。
在给定两个初始状态的情况下,对每个模型进行训练,以每 50 毫秒的间隔预测下一个(多个)未来状态。我们对所有训练子集一次性训练模型,并分别对测试子集进行评估。我们测量粒子在全局和局部物体坐标中的预测位置与真实位置之间的均方误差(MSE)。全局 MSE 量化物体位置的正确性。局部 MSE 评估预测物体形状的准确性。我们对未来 40 帧的预测进行评估。如需更直观地了解训练和测试设置,请点击此
视频链接
。
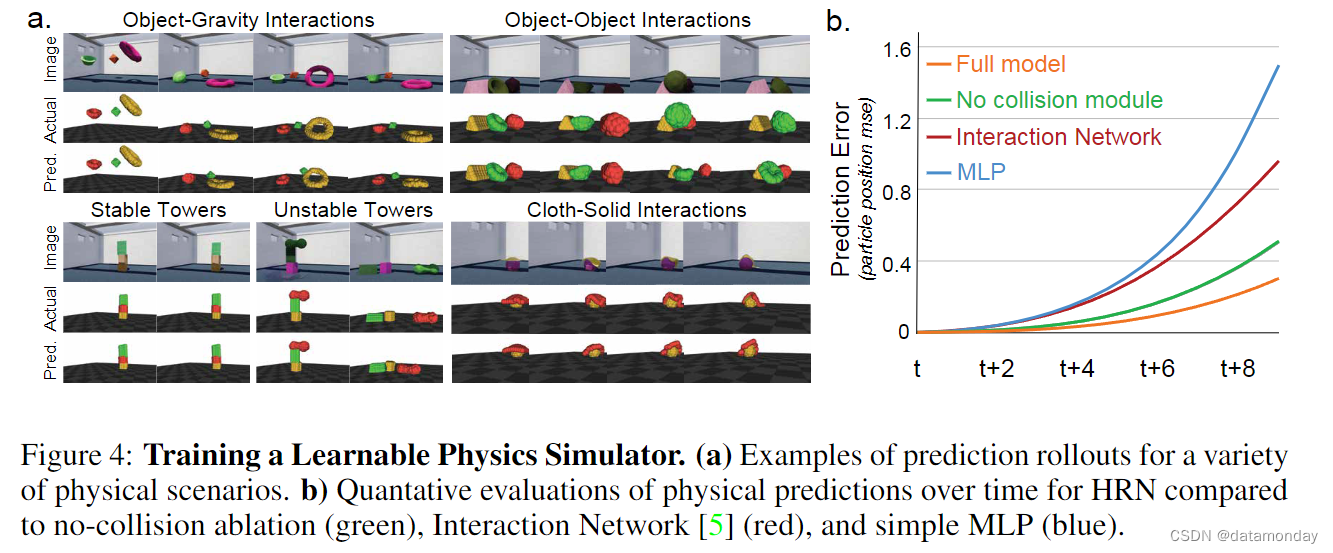
Prediction Results
我们首先复制了 HRN 与更简单的物理预测基线模型的比较结果。与最初的工作一样,我们发现 HRN 优于没有碰撞检测或灵活分层场景描述的基线模型(图 4)。然后,我们将 DRHRN 与强确定性物理预测基线进行比较,包括上述的 HRN 和 DPI [ 29 ],后者使用了不同的分层信息传递顺序和硬编码的刚性形状保持约束。我们在 Tensorflow 中重新实现了这两个基线,以便进行直接比较。表 5 列出了 DRHRN 的比较结果。DRHRN 在所有场景下的表现都明显优于 HRN 和 DPI。它实现了更低的局部 MSE,这表明它能更好地保持形状,而我们确实能在图像中观察到这一点。所有预测结果在物理上都是可信的,没有不自然的变形(更多视频结果)。
3.3 Social Agents and Virtual Reality
社交互动是人类生活的一个重要方面,但也是目前人工智能和机器人学方法特别有限的一个领域。因此,能够模拟和模仿社交行为并从社交互动中高效学习的人工智能智能体是尖端技术发展的一个重要领域。
Task Definition
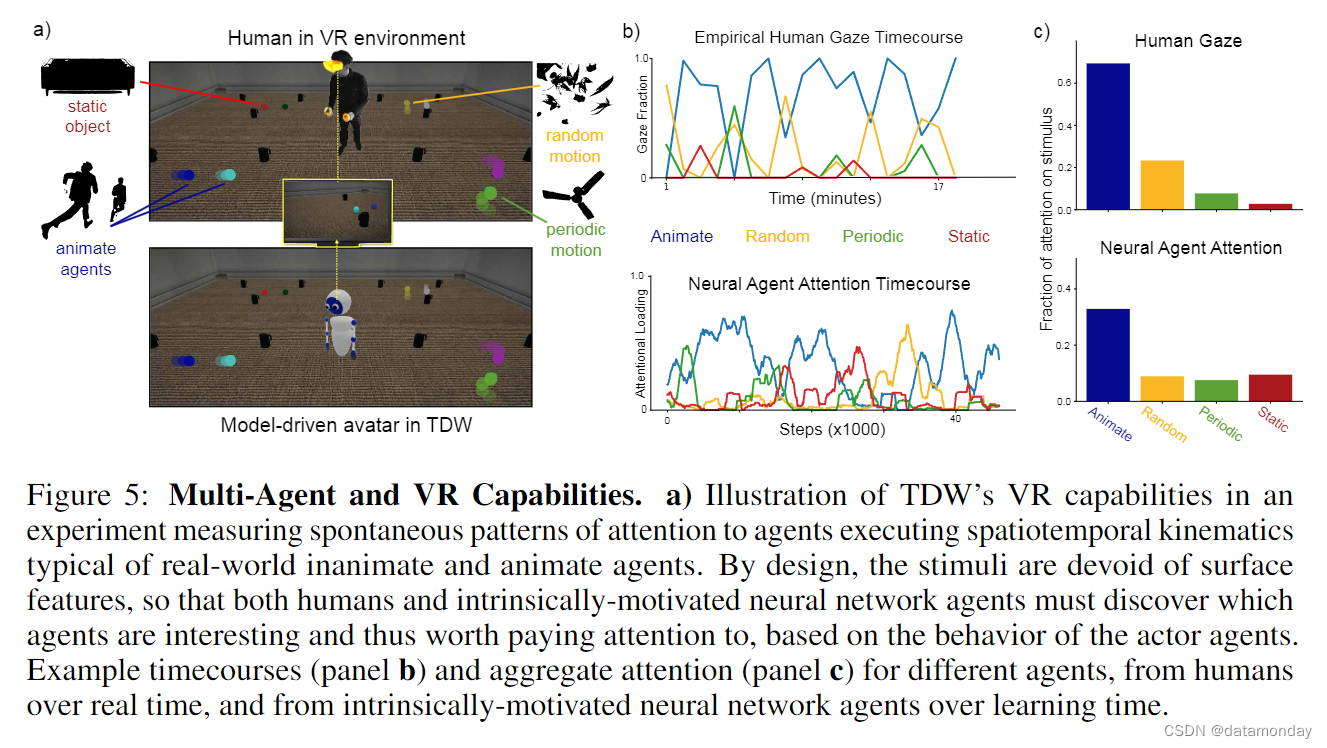
利用 TDW 多智能体应用程序接口的灵活性,我们创建了各种多智能体交互设置(图 1f)。其中包括将一个 "观察者 "智能体与多个受不同控制的 "行为者 "智能体一起放置在一个有多个无生命物体的房间里的场景(图 5a)。行为智能体由硬编码或交互式策略控制,可实施物体操作、追逐和隐藏以及动作模仿等行为。在这种情况下,人类观察者只是被要求看他们想看的任何东西,而我们的虚拟观察者则力求最大限度地提高其预测同一显示屏中演员行为的能力,并根据 “好奇心进展”[3] 这一指标分配其注意力,该指标旨在估计哪些观察最有可能提高观察者预测演员行为的能力。主要的问题是,这种好奇心驱动的学习形式是否会自然而然地产生注意力模式,从而反映出人类在实验中首次探索同一场景时如何分配注意力。
Experiments
耐人寻味的是,在最近的研究中,这些具有社会好奇心的智能体已被证明在产生更好的预测结果方面优于各种现有的替代好奇心指标,无论是在最终性能方面还是在大幅降低学习智能体行为模式所需的样本复杂性方面都是如此 [24 ]。TDW 中的虚拟现实集成使人类能够直接观察和操纵响应虚拟环境中的物体。图 5 展示了一项实验,研究人类观察者在有多个动画智能体和静态物体的环境中表现出的注意力模式[22, 17]。观察者佩戴由 GPU 驱动的 Oculus Rift S,同时观看包含多个机器人的虚拟显示屏。来自 Oculus 的头部运动被映射到 TDW 中的传感器摄像头上,摄像头图像与图像分割物体的元数据配对,以确定人们注视的是哪一组机器人。有趣的是,具有社会好奇心的神经网络智能体所产生的总体注意力注视模式与在 VR 环境中测量的人类成年人的注视模式非常相似(图 5b),这是因为智能体发现了动画固有的相对 “趣味性”,而没有将其构建到网络架构中[24]。这些结果只是 TDW 广泛的 VR 功能在连接人工智能和人类行为方面的一个例证。
4 Future Directions
我们正在积极开发机器人系统集成和可衔接物体交互的新功能,以实现更高层次的任务规划和执行。
-
可衔接物体。目前,只有少数 TDW 物体可通过用户交互进行修改,我们正在积极扩大支持此类行为的库模型数量,包括可打开盖子的容器、可移动抽屉的柜子和带功能把手的门。
-
仿人智能体。与可操作物体进行交互或执行精细运动控制任务(如拼图),需要智能体拥有完全铰接的身体和双手。我们计划开发一套能够满足这些要求的仿人机器人类型,其身体运动由动作捕捉数据驱动,并配有独立的手势控制系统,用于手部和手指关节的精细运动控制。
-
机器人系统集成。在模块化应用程序接口分层方法的基础上,我们设想开发额外的超高层应用程序接口层,以解决特定的物理交互场景。我们还在探索创建一个 PyBullet [11] 包装器,通过将 PyBullet API 命令转换为 TDW 中的类似命令,在系统之间复制物理行为。