本节将使用ResNet实现CIFAR-10数据集分类。
7.2.1 CIFAR-10
数据集简介
CIFAR-10数据集共有60000幅彩色图像,这些图像是32×32像素的,分为10个类,每类6000幅图。这里面有50000幅用于训练,构成了5个训练批,每一批10000幅图;另外10000幅图用于测试,单独构成一批。测试批的数据取自100类中的每一类,每一类随机取1000幅图。抽剩下的就随机排列组成训练批。注意,一个训练批中的各类图像的数量并不一定相同,总的来看,训练批每一类都有5000幅图,如图7-9所示。

图7-9 CIFAR-10数据集
读者自行搜索CIFAR-10数据集下载地址,进入下载页面后,选择下载方式,如图7-10所示。

图7-10 下载方式
由于PyTorch 2.0采用Python语言编程,因此选择python version版本下载。下载之后解压缩,得到如图7-11所示的几个文件。
图7-11 得到的文件
data_batch_1 ~ data_batch_5 是划分好的训练数据,每个文件中包含10000幅图片,test_batch是测试集数据,也包含10000幅图片。
读取数据的代码如下:
import pickle
def load_file(filename):
with open(filename, 'rb') as fo:
data = pickle.load(fo, encoding='latin1')
return data
首先定义读取数据的函数,这几个文件都是通过pickle产生的,所以在读取的时候也要用到这个包。返回的data是一个字典,先来看这个字典里面有哪些键。
data = load_file('data_batch_1')
print(data.keys())
输出结果如下:
dict_keys([ 'batch_label', 'labels', 'data', 'filenames' ])
具体说明如下:
-
batch_label:对应的值是一个字符串,用来表明当前文件的一些基本信息。
-
labels:对应的值是一个长度为10000的列表,每个数字取值范围为0~9,代表当前图片所属的类别。
-
data:10000×3072的二维数组,每一行代表一幅图片的像素值。
-
filenames:长度为10000的列表,里面每一项是代表图片文件名的字符串。
完整的数据读取函数如下。
import pickle
import numpy as np
import os
def get_cifar10_train_data_and_label(root=""):
def load_file(filename):
with open(filename, 'rb') as fo:
data = pickle.load(fo, encoding='latin1')
return data
data_batch_1 = load_file(os.path.join(root, 'data_batch_1'))
data_batch_2 = load_file(os.path.join(root, 'data_batch_2'))
data_batch_3 = load_file(os.path.join(root, 'data_batch_3'))
data_batch_4 = load_file(os.path.join(root, 'data_batch_4'))
data_batch_5 = load_file(os.path.join(root, 'data_batch_5'))
dataset = []
labelset = []
for data in [data_batch_1, data_batch_2, data_batch_3, data_batch_4, data_batch_5]:
img_data = (data["data"])
img_label = (data["labels"])
dataset.append(img_data)
labelset.append(img_label)
dataset = np.concatenate(dataset)
labelset = np.concatenate(labelset)
return dataset, labelset
def get_cifar10_test_data_and_label(root=""):
def load_file(filename):
with open(filename, 'rb') as fo:
data = pickle.load(fo, encoding='latin1')
return data
data_batch_1 = load_file(os.path.join(root, 'test_batch'))
dataset = []
labelset = []
for data in [data_batch_1]:
img_data = (data["data"])
img_label = (data["labels"])
dataset.append(img_data)
labelset.append(img_label)
dataset = np.concatenate(dataset)
labelset = np.concatenate(labelset)
return dataset, labelset
def get_CIFAR10_dataset(root=""):
train_dataset, label_dataset = get_cifar10_train_data_and_label(root=root)
test_dataset, test_label_dataset = get_cifar10_train_data_and_label(root=root)
return train_dataset, label_dataset, test_dataset, test_label_dataset
if __name__ == "__main__":
train_dataset, label_dataset, test_dataset, test_label_dataset = get_CIFAR10_dataset(root="../dataset/cifar-10-batches-py/")
train_dataset = np.reshape(train_dataset,[len(train_dataset),3,32,32]). astype(np.float32)/255.
test_dataset = np.reshape(test_dataset,[len(test_dataset),3,32,32]). astype(np.float32)/255.
label_dataset = np.array(label_dataset)
test_label_dataset = np.array(test_label_dataset)
其中的root参数是下载数据解压后的目录,os.join函数将其组合成数据文件的位置。最终返回训练文件、测试文件以及它们对应的label。由于我们提取出的文件数据格式为[-1,3072],因此需要重新对数据维度进行调整,使之适用模型的输入。
7.2.2
基于ResNet的CIFAR-10数据集分类
前面章节中,我们对ResNet模型以及CIFAR-10数据集做了介绍,本小节将使用前面定义的ResNet模型进行分类任务。
在7.2.1节中已经介绍了CIFAR-10数据集的基本构成,并讲解了ResNet的基本模型结构,接下来直接导入对应的数据和模型即可。完整的模型训练如下:
import torch
import resnet
import get_data
import numpy as np
train_dataset, label_dataset, test_dataset, test_label_dataset = get_data.get_CIFAR10_dataset(root="../dataset/cifar-10-batches-py/")
train_dataset = np.reshape(train_dataset,[len(train_dataset),3,32,32]). astype(np.float32)/255.
test_dataset = np.reshape(test_dataset,[len(test_dataset),3,32,32]). astype(np.float32)/255.
label_dataset = np.array(label_dataset)
test_label_dataset = np.array(test_label_dataset)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = resnet.resnet18() #导入ResNet模型
model = model.to(device) #将计算模型传入GPU硬件等待计算
model = torch.compile(model) #PyTorch 2.0的特性,加速计算速度
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定优化函数
loss_fn = torch.nn.CrossEntropyLoss()
batch_size = 128
train_num = len(label_dataset)//batch_size
for epoch in range(63):
train_loss = 0.
for i in range(train_num):
start = i * batch_size
end = (i + 1) * batch_size
x_batch = torch.from_numpy(train_dataset[start:end]).to(device)
y_batch = torch.from_numpy(label_dataset[start:end]).to(device)
pred = model(x_batch)
loss = loss_fn(pred, y_batch.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() # 记录每个批次的损失值
# 计算并打印损失值
train_loss /= train_num
accuracy = (pred.argmax(1) == y_batch).type(torch.float32).sum().item() / batch_size
#2048可根据读者GPU显存大小调整
test_num = 2048
x_test = torch.from_numpy(test_dataset[:test_num]).to(device)
y_test = torch.from_numpy(test_label_dataset[:test_num]).to(device)
pred = model(x_test)
test_accuracy = (pred.argmax(1) == y_test).type(torch.float32).sum().item() / test_num
print("epoch:",epoch,"train_loss:", round(train_loss,2),";accuracy:",round(accuracy,2),";test_accuracy:",round(test_accuracy,2))
在这里使用训练集数据对模型进行训练,之后使用测试集数据对其输出进行测试,训练结果如图7-12所示。
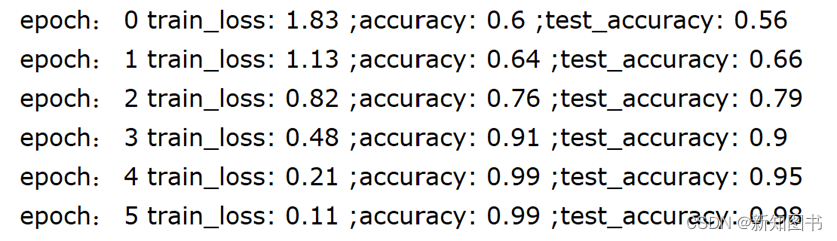
图7-12 训练结果
可以看到,经过5轮后,模型在训练集的准确率达到0.99,在测试集的准确率也达到0.98,这是一个较好的成绩,可以看到模型的性能达到较高水平。
其他层次的模型请读者自行尝试,根据读者自己不同的硬件设备,模型的参数和训练集的batch_size都需要作出调整,具体数值请根据需要对它们进行设置。
本文节选自《从零开始大模型开发与微调:基于PyTorch与ChatGLM》,获出版社和作者授权共享。
