GreptimeDB
作为云时代基础设施的时序数据库,从第一天开始就积极拥抱云原生技术,将数据库部署在 Kubernetes 上可以提供可伸缩性、自愈能力和简化的部署和管理,从而为应用程序提供了强大的弹性和可靠性。
Helm
是一个用于管理 Kubernetes 应用程序的包管理器,通过使用 Helm Chart,可以轻松地将应用程序打包、配置和部署到 Kubernetes 集群中。
本篇文章将讲解如何使用 Helm Chart 部署分布式 GreptimeDB,并将数据保存在 AWS S3 以及阿里云 OSS 等对象存储上。
配置 Helm Chart 环境
首先需要安装 Helm 工具,可以根据
安装文档
中的说明进行安装。
在部署应用程序之前,需要将
greptime 仓库
添加到 Helm 中,仓库包含了一系列可用的 Helm Charts。使用以下命令将 greptime 仓库添加到 Helm:
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
使用以下命令浏览可用的 Helm Charts:
helm search repo greptime --devel -l
安装 Charts
安装 `etcd`
helm install etcd oci://registry-1.docker.io/bitnamicharts/etcd \
--set replicaCount=1 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
-n default
2.2 安装 `greptimedb-operator`
helm install greptimedb-operator greptime/greptimedb-operator -n default
2.3 安装 `greptimedb-cluster`
helm install mycluster greptime/greptimedb-cluster -n default
要安装特定版本的 Chart,使用以下命令:
helm install mycluster greptime/greptimedb-cluster -n default --version <chart-version>
使用 `kubectl` 命令行工具查看安装的 Pod:
kubectl get po -n default
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 2m18s
etcd-1 1/1 Running 0 2m18s
etcd-2 1/1 Running 0 2m18s
greptimedb-operator-546b5f9656-tz9gn 1/1 Running 0 2m1s
mycluster-datanode-0 1/1 Running 0 32s
mycluster-datanode-1 1/1 Running 0 27s
mycluster-datanode-2 1/1 Running 0 21s
mycluster-frontend-76cbf55687-4drvx 1/1 Running 0 15s
mycluster-meta-6b7974464b-bbt4h 1/1 Running 0 33s
2.4 卸载 `greptimedb-cluster`
helm uninstall mycluster -n default
将数据保存到 AWS S3
helm install mycluster greptime/greptimedb-cluster \
--set storage.s3.bucket="your-bucket" \
--set storage.s3.region="region-of-bucket" \
--set storage.s3.root="/greptimedb-data" \
--set storage.credentials.secretName="s3-credentials" \
--set storage.credentials.accessKeyId="your-access-key-id" \
--set storage.credentials.secretAccessKey="your-secret-access-key"
这里有一些参数,可以替换成你的 S3 信息:
-
bucket:S3 Bucket 名字
-
region:S3 Bucket Region
-
root:数据存储目录,这里设定为 `/greptimedb-data`
-
secretName:S3 Credentials Secret Name
-
accessKeyId:AWS Access Key ID
-
secretAccessKey:AWS Secret Access Key
当 Pod 启动之后,执行测试将数据写入 S3:
kubectl port-forward svc/mycluster-frontend 4002:4002 > a.out &
可以使用 MySQL 协议连接 GreptimeDB:
mysql -h 127.0.0.1 -P 4002
执行建表语句,这里的表名为 `s3_test_table`:
CREATE TABLE s3_test_table (
host STRING,
idc STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host, idc),
TIME INDEX(ts)
);
往 `s3_test_table` 中插入数据:
INSERT INTO s3_test_table
VALUES
("host1", "idc_a", 11.8, 10.3, 10.3, 1667446797450),
("host1", "idc_a", 80.1, 70.3, 90.0, 1667446797550),
("host1", "idc_b", 50.0, 66.7, 40.6, 1667446797650),
("host1", "idc_b", 51.0, 66.5, 39.6, 1667446797750),
("host1", "idc_b", 52.0, 66.9, 70.6, 1667446797850),
("host1", "idc_b", 53.0, 63.0, 50.6, 1667446797950),
("host1", "idc_b", 78.0, 66.7, 20.6, 1667446798050),
("host1", "idc_b", 68.0, 63.9, 50.6, 1667446798150),
("host1", "idc_b", 90.0, 39.9, 60.6, 1667446798250);
登陆 AWS S3 的控制台查看写入的数据:

还可以通过
Dashboard
访问 GreptimeDB:
kubectl port-forward svc/mycluster-frontend 4000:4000 > a.out &
在浏览器访问 `http://localhost:4000/dashboard/query` 浏览 Dashboard,执行 `select *from s3_test_table;` 查看写入的数据:
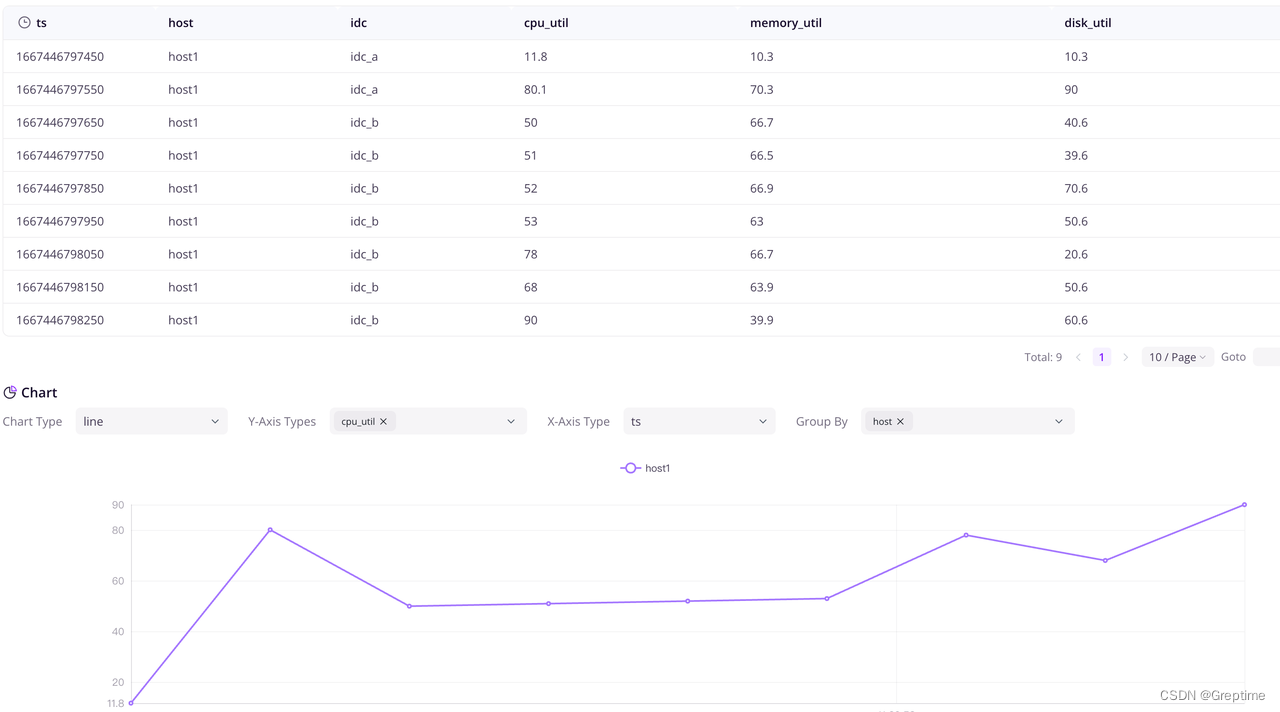
卸载 `greptimedb-cluster`
helm uninstall mycluster -n default
将数据保存到阿里云 OSS
helm install mycluster greptime/greptimedb-cluster -n default \
--set storage.oss.bucket="bucket-name" \
--set storage.oss.region="oss-region" \
--set storage.oss.root="/greptimedb-data" \
--set storage.oss.endpoint="oss-endpoint" \
--set storage.credentials.secretName="oss-credentials" \
--set storage.credentials.accessKeyId="your-access-key-id" \
--set storage.credentials.secretAccessKey="your-secret-access-key"
这里有一些参数,可以替换成你的 OSS 信息:
-
bucket:OSS Bucket 名字
-
region:OSS Bucket Region
-
root:数据存储目录,这里设定为 `/greptimedb-data`
-
secretName:OSS Credentials Secret Name
-
endpoint: OSS Endpoint
-
accessKeyId:AliCloud Access Key ID
-
secretAccessKey:AliCloud Secret Key
当 Pod 启动之后,执行测试将数据写入 OSS:
kubectl port-forward svc/mycluster-frontend 4002:4002 > a.out &
通过 MySQL 协议连接 GreptimeDB:
```shell
mysql -h 127.0.0.1 -P 4002
```
执行建表语句,这里的表名为 `oss_test_table`:
CREATE TABLE oss_test_table (
host STRING,
idc STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host, idc),
TIME INDEX(ts)
);
往 `oss_test_table` 中插入数据:
INSERT INTO oss_test_table
VALUES
("host1", "idc_a", 11.8, 10.3, 10.3, 1667446797450),
("host1", "idc_a", 80.1, 70.3, 90.0, 1667446797550),
("host1", "idc_b", 50.0, 66.7, 40.6, 1667446797650),
("host1", "idc_b", 51.0, 66.5, 39.6, 1667446797750),
("host1", "idc_b", 52.0, 66.9, 70.6, 1667446797850),
("host1", "idc_b", 53.0, 63.0, 50.6, 1667446797950),
("host1", "idc_b", 78.0, 66.7, 20.6, 1667446798050),
("host1", "idc_b", 68.0, 63.9, 50.6, 1667446798150),
("host1", "idc_b", 90.0, 39.9, 60.6, 1667446798250);
查看写入的数据:
mysql> select *from oss_test_table;
+-------+-------+----------+-------------+-----------+-------------------------+
| host | idc | cpu_util | memory_util | disk_util | ts |
+-------+-------+----------+-------------+-----------+-------------------------+
| host1 | idc_a | 11.8 | 10.3 | 10.3 | 2022-11-03 03:39:57.450 |
| host1 | idc_a | 80.1 | 70.3 | 90 | 2022-11-03 03:39:57.550 |
| host1 | idc_b | 50 | 66.7 | 40.6 | 2022-11-03 03:39:57.650 |
| host1 | idc_b | 51 | 66.5 | 39.6 | 2022-11-03 03:39:57.750 |
| host1 | idc_b | 52 | 66.9 | 70.6 | 2022-11-03 03:39:57.850 |
| host1 | idc_b | 53 | 63 | 50.6 | 2022-11-03 03:39:57.950 |
| host1 | idc_b | 78 | 66.7 | 20.6 | 2022-11-03 03:39:58.050 |
| host1 | idc_b | 68 | 63.9 | 50.6 | 2022-11-03 03:39:58.150 |
| host1 | idc_b | 90 | 39.9 | 60.6 | 2022-11-03 03:39:58.250 |
+-------+-------+----------+-------------+-----------+-------------------------+
9 rows in set (0.01 sec)
登陆阿里云 OSS 的控制台查看写入的数据:
总结
本文介绍了通过使用 Helm Chart 部署分布式 GreptimeDB,并配置数据存储在 AWS S3 或阿里云 OSS 的方法,在云原生时代下,此方法不仅提高了数据管理的弹性和可靠性,还简化了部署和管理过程。在上一篇文章中,我们介绍了如何用 Helm Chart 部署单机版 GreptimeDB,欢迎回看。
关于 Greptime 的小知识:
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库 GreptimeDB,格睿云 GreptimeCloud 和可观测工具 GreptimeAI 这三款产品。
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本;GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合;GreptimeAI 为 LLM 量身打造,提供成本、性能和生成过程的全链路监控。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/