在 Python 中,一般情况下我们可能直接用自带的 logging 模块来记录日志,包括我之前的时候也是一样。在使用时我们需要配置一些 Handler、Formatter 来进行一些处理,比如把日志输出到不同的位置,或者设置一个不同的输出格式,或者设置日志分块和备份。但其实个人感觉 logging 用起来其实并不是那么好用,其实主要还是配置较为繁琐。
常见使用
首先看看 logging 常见的解决方案吧,我一般会配置输出到文件、控制台和 Elasticsearch。输出到控制台就仅仅是方便直接查看的;输出到文件是方便直接存储,保留所有历史记录的备份;输出到 Elasticsearch,直接将 Elasticsearch 作为存储和分析的中心,使用 Kibana 可以非常方便地分析和查看运行情况。
所以在这里我基本会对 logging 做如下的封装写法:
import logging
import sys
from os import makedirs
from os.path import dirname, exists
from cmreslogging.handlers import CMRESHandler
loggers = {}
LOG_ENABLED = True
LOG_TO_CONSOLE = True
LOG_TO_FILE = True
LOG_TO_ES = True
LOG_PATH = './runtime.log'
LOG_LEVEL = 'DEBUG'
LOG_FORMAT = '%(levelname)s - %(asctime)s - process: %(process)d - %(filename)s - %(name)s - %(lineno)d - %(module)s - %(message)s'
ELASTIC_SEARCH_HOST = 'eshost'
ELASTIC_SEARCH_PORT = 9200
ELASTIC_SEARCH_INDEX = 'runtime'
APP_ENVIRONMENT = 'dev'
def get_logger(name=None):
"""
get logger by name
:param name: name of logger
:return: logger
"""
global loggers
if not name: name = __name__
if loggers.get(name):
return loggers.get(name)
logger = logging.getLogger(name)
logger.setLevel(LOG_LEVEL)
if LOG_ENABLED and LOG_TO_CONSOLE:
stream_handler = logging.StreamHandler(sys.stdout)
stream_handler.setLevel(level=LOG_LEVEL)
formatter = logging.Formatter(LOG_FORMAT)
stream_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
if LOG_ENABLED and LOG_TO_FILE:
log_dir = dirname(log_path)
if not exists(log_dir): makedirs(log_dir)
file_handler = logging.FileHandler(log_path, encoding='utf-8')
file_handler.setLevel(level=LOG_LEVEL)
formatter = logging.Formatter(LOG_FORMAT)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
if LOG_ENABLED and LOG_TO_ES:
es_handler = CMRESHandler(hosts=[{'host': ELASTIC_SEARCH_HOST, 'port': ELASTIC_SEARCH_PORT}],
auth_type=CMRESHandler.AuthType.NO_AUTH,
es_index_name=ELASTIC_SEARCH_INDEX,
index_name_frequency=CMRESHandler.IndexNameFrequency.MONTHLY,
es_additional_fields={'environment': APP_ENVIRONMENT}
)
es_handler.setLevel(level=LOG_LEVEL)
formatter = logging.Formatter(LOG_FORMAT)
es_handler.setFormatter(formatter)
logger.addHandler(es_handler)
loggers[name] = logger
return logger
定义完了怎么使用呢?只需要使用定义的方法获取一个 logger,然后 log 对应的内容即可:
logger = get_logger()
logger.debug('this is a message')
运行结果如下:
DEBUG - 2019-10-11 22:27:35,923 - process: 99490 - logger.py - __main__ - 81 - logger - this is a message
我们看看这个定义的基本实现吧。首先这里一些常量是用来定义 logging 模块的一些基本属性的,比如 LOG_ENABLED 代表是否开启日志功能,LOG_TO_ES 代表是否将日志输出到 Elasticsearch,另外还有很多其他的日志基本配置,如 LOG_FORMAT 配置了日志每个条目输出的基本格式,另外还有一些连接的必要信息。这些变量可以和运行时的命令行或环境变量对接起来,可以方便地实现一些开关和配置的更换。
然后定义了这么一个 get_logger 方法,接收一个参数 name。首先该方法拿到 name 之后,会到全局的 loggers 变量里面查找,loggers 变量是一个全局字典,如果有已经声明过的 logger,直接将其获取返回即可,不用再将其二次初始化。如果 loggers 里面没有找到 name 对应的 logger,那就进行创建即可。创建 logger 之后,可以为其添加各种对应的 Handler,如输出到控制台就用 StreamHandler,输出到文件就用 FileHandler 或 RotatingFileHandler,输出到 Elasticsearch 就用 CMRESHandler,分别配置好对应的信息即可。
最后呢,将新建的 logger 保存到全局的 loggers 里面并返回即可,这样如果有同名的 logger 便可以直接查找 loggers 直接返回了。
在这里依赖了额外的输出到 Elasticsearch 的包,叫做 CMRESHandler,它可以支持将日志输出到 Elasticsearch 里面,如果要使用的话可以安装一下:
pip install CMRESHandler
其 GitHub 地址是:https://github.com/cmanaha/python-elasticsearch-logger,具体的使用方式可以看看它的官方说明,如配置认证信息,配置 Index 分隔信息等等。
好,上面就是我之前常用的 logging 配置,通过如上的配置,我就可以实现将 logging 输出到三个位置,并可以实现对应的效果。比如输出到 Elasticsearch 之后,我就可以非常方便地使用 Kibana 来查看当前运行情况,ERROR Log 的比例等等,如图所示:
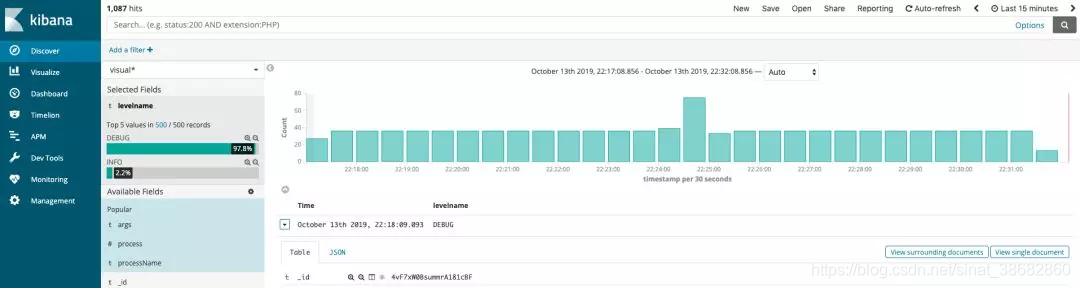
也可以在它的基础上做更进一步的统计分析。
loguru
上面的实现方式已经是一个较为可行的配置方案了。然而,我还是会感觉到有些 Handler 配起来麻烦,尤其是新建一个项目的很多时候懒得去写一些配置。即使是不用上文的配置,用最基本的几行 logging 配置,像如下的通用配置:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006 寻找有志同道合的小伙伴,
互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import logging
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
我也懒得去写,感觉并不是一个优雅的实现方式。
有需求就有动力啊,这不,就有人实现了这么一个库,叫做 loguru,可以将 log 的配置和使用更加简单和方便。
下面我们来看看它到底是怎么用的吧。
安装
首先,这个库的安装方式很简单,就用基本的 pip 安装即可,Python 3 版本的安装如下:
pip3 install loguru
安装完毕之后,我们就可以在项目里使用这个 loguru 库了。
基本使用
那么这个库怎么来用呢?我们先用一个实例感受下:
from loguru import logger
logger.debug('this is a debug message')
看到了吧,不需要配置什么东西,直接引入一个 logger,然后调用其 debug 方法即可。
在 loguru 里面有且仅有一个主要对象,那就是 logger,loguru 里面有且仅有一个 logger,而且它已经被提前配置了一些基础信息,比如比较友好的格式化、文本颜色信息等等。
上面的代码运行结果如下:
2019-10-13 22:46:12.367 | DEBUG | __main__:<module>:4 - this is a debug message
可以看到其默认的输出格式是上面的内容,有时间、级别、模块名、行号以及日志信息,不需要手动创建 logger,直接使用即可,另外其输出还是彩色的,看起来会更加友好。
以上的日志信息是直接输出到控制台的,并没有输出到其他的地方,如果想要输出到其他的位置,比如存为文件,我们只需要使用一行代码声明即可。
例如将结果同时输出到一个 runtime.log 文件里面,可以这么写:
from loguru import logger
logger.add('runtime.log')
logger.debug('this is a debug')
很简单吧,我们也不需要再声明一个 FileHandler 了,就一行 add 语句搞定,运行之后会发现目录下 runtime.log 里面同样出现了刚刚控制台输出的 DEBUG 信息。
上面就是一些基本的使用,但这还远远不够,下面我们来详细了解下它的一些功能模块。
详细使用
既然是日志,那么最常见的就是输出到文件了。loguru 对输出到文件的配置有非常强大的支持,比如支持输出到多个文件,分级别分别输出,过大创建新文件,过久自动删除等等。
下面我们分别看看这些怎样来实现,这里基本上就是 add 方法的使用介绍。因为这个 add 方法就相当于给 logger 添加了一个 Handler,它给我们暴露了许多参数来实现 Handler 的配置,下面我们来详细介绍下。
首先看看它的方法定义吧:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006 寻找有志同道合的小伙伴,
互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def add(
self,
sink,
*,
level=_defaults.LOGURU_LEVEL,
format=_defaults.LOGURU_FORMAT,
filter=_defaults.LOGURU_FILTER,
colorize=_defaults.LOGURU_COLORIZE,
serialize=_defaults.LOGURU_SERIALIZE,
backtrace=_defaults.LOGURU_BACKTRACE,
diagnose=_defaults.LOGURU_DIAGNOSE,
enqueue=_defaults.LOGURU_ENQUEUE,
catch=_defaults.LOGURU_CATCH,
**kwargs
):
pass
看看它的源代码,它支持这么多的参数,如 level、format、filter、color 等等。
sink
另外我们还注意到它有个非常重要的参数 sink,我们看看官方文档:https://loguru.readthedocs.io/en/stable/api/logger.html#sink,可以了解到通过 sink 我们可以传入多种不同的数据结构,汇总如下:
•sink 可以传入一个 file 对象,例如 sys.stderr 或者 open(‘file.log’, ‘w’) 都可以。
•sink 可以直接传入一个 str 字符串或者 pathlib.Path 对象,其实就是代表文件路径的,如果识别到是这种类型,它会自动创建对应路径的日志文件并将日志输出进去。
•sink 可以是一个方法,可以自行定义输出实现。
•sink 可以是一个 logging 模块的 Handler,比如 FileHandler、StreamHandler 等等,或者上文中我们提到的 CMRESHandler 照样也是可以的,这样就可以实现自定义 Handler 的配置。
•sink 还可以是一个自定义的类,具体的实现规范可以参见官方文档。
所以说,刚才我们所演示的输出到文件,仅仅给它传了一个 str 字符串路径,他就给我们创建了一个日志文件,就是这个原理。
format、filter、level
下面我们再了解下它的其他参数,例如 format、filter、level 等等。
其实它们的概念和格式和 logging 模块都是基本一样的了,例如这里使用 format、filter、level 来规定输出的格式:
logger.add('runtime.log', format="{time} {level} {message}", filter="my_module", level="INFO")
删除 sink
另外添加 sink 之后我们也可以对其进行删除,相当于重新刷新并写入新的内容。
删除的时候根据刚刚 add 方法返回的 id 进行删除即可,看下面的例子:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006 寻找有志同道合的小伙伴,
互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from loguru import logger
trace = logger.add('runtime.log')
logger.debug('this is a debug message')
logger.remove(trace)
logger.debug('this is another debug message')
看这里,我们首先 add 了一个 sink,然后获取它的返回值,赋值为 trace。随后输出了一条日志,然后将 trace 变量传给 remove 方法,再次输出一条日志,看看结果是怎样的。
控制台输出如下:
2019-10-13 23:18:26.469 | DEBUG | __main__:<module>:4 - this is a debug message
2019-10-13 23:18:26.469 | DEBUG | __main__:<module>:6 - this is another debug message
日志文件 runtime.log 内容如下:
2019-10-13 23:18:26.469 | DEBUG | __main__:<module>:4 - this is a debug message
可以发现,在调用 remove 方法之后,确实将历史 log 删除了。
这样我们就可以实现日志的刷新重新写入操作。
rotation 配置
用了 loguru 我们还可以非常方便地使用 rotation 配置,比如我们想一天输出一个日志文件,或者文件太大了自动分隔日志文件,我们可以直接使用 add 方法的 rotation 参数进行配置。
我们看看下面的例子:
logger.add('runtime_{time}.log', rotation="500 MB")
通过这样的配置我们就可以实现每 500MB 存储一个文件,每个 log 文件过大就会新创建一个 log 文件。我们在配置 log 名字时加上了一个 time 占位符,这样在生成时可以自动将时间替换进去,生成一个文件名包含时间的 log 文件。
另外我们也可以使用 rotation 参数实现定时创建 log 文件,例如:
logger.add('runtime_{time}.log', rotation='00:00')
这样就可以实现每天 0 点新创建一个 log 文件输出了。
另外我们也可以配置 log 文件的循环时间,比如每隔一周创建一个 log 文件,写法如下:
logger.add('runtime_{time}.log', rotation='1 week')
这样我们就可以实现一周创建一个 log 文件了。
retention 配置
很多情况下,一些非常久远的 log 对我们来说并没有什么用处了,它白白占据了一些存储空间,不清除掉就会非常浪费。retention 这个参数可以配置日志的最长保留时间。
比如我们想要设置日志文件最长保留 10 天,可以这么来配置:
logger.add('runtime.log', retention='10 days')
这样 log 文件里面就会保留最新 10 天的 log,妈妈再也不用担心 log 沉积的问题啦。
compression 配置
loguru 还可以配置文件的压缩格式,比如使用 zip 文件格式保存,示例如下:
logger.add('runtime.log', compression='zip')
这样可以更加节省存储空间。
字符串格式化
loguru 在输出 log 的时候还提供了非常友好的字符串格式化功能,像这样:
logger.info('If you are using Python {}, prefer {feature} of course!', 3.6, feature='f-strings')
这样在添加参数就非常方便了。
Traceback 记录
在很多情况下,如果遇到运行错误,而我们在打印输出 log 的时候万一不小心没有配置好 Traceback 的输出,很有可能我们就没法追踪错误所在了。
但用了 loguru 之后,我们用它提供的装饰器就可以直接进行 Traceback 的记录,类似这样的配置即可:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:857662006 寻找有志同道合的小伙伴,
互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
@logger.catch
def my_function(x, y, z):
return 1 / (x + y + z)
我们做个测试,我们在调用时三个参数都传入 0,直接引发除以 0 的错误,看看会出现什么情况:
my_function(0, 0, 0)
运行完毕之后,可以发现 log 里面就出现了 Traceback 信息,而且给我们输出了当时的变量值,真的是不能再赞了!结果如下:
> File "run.py", line 15, in <module>
my_function(0, 0, 0)
└ <function my_function at 0x1171dd510>
File "/private/var/py/logurutest/demo5.py", line 13, in my_function
return 1 / (x + y + z)
│ │ └ 0
│ └ 0
└ 0
ZeroDivisionError: division by zero
因此,用 loguru 可以非常方便地实现日志追踪,debug 效率可能要高上十倍了?
另外 loguru 还有很多很多强大的功能,这里就不再一一展开讲解了,更多的内容大家可以看看 loguru 的官方文档详细了解一下:https://loguru.readthedocs.io/en/stable/index.html。
看完之后,是时候把自己的 logging 模块替换成 loguru 啦!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)