voc旋转标注数据转dota类型
- voc2dota.py
- ListFilesToTxt.py
- roxml_to_dota.py
在cv领域数据集的标注过程中,用labelImg工具我们可以对数据进行标注,标注生成的voc类型的xml框一般是如下格式:(bndbox)(x1,y1,x2,y2)

但是在标注的过程中,往往会遇到使用水平的矩形框无法完整地框出类别的特征的情况,这会导致无用特征的冗余。
在dota类型的标注中,就能解决这个问题:
我们可以定义三个类型的bbox:HBB,OBB,POLY
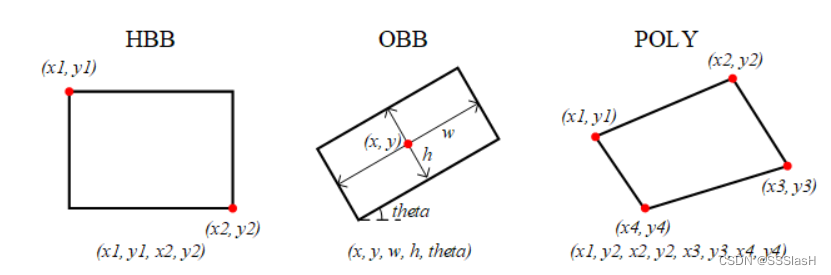
HBB由左上点和右下点表示。 HBB 的最后一个维度应该是 4。
OBB由中心点(x, y)、宽度(w)、高度(h) 和θ 表示。宽度是较长边的长度。高度是较短边的长度。Theta 是长边和 x 轴之间的角度。 OBB 的最后一个维度应该是 5。
POLY由四点坐标表示。这些点的顺序无关紧要,但相邻的点应该是POLY的一侧。 POLY的最后一个维度应该是8
很明显,普通的xml标注文件属于HBB类型。而在旋转目标检测中,我们如果用到labelImg2来标注旋转的矩形框:

以及他生成的xml标注文件:

很明显,格式产生了变化
(robndbox)(cx,cy,w,h)
为了统一使用,我们可以将两种格式的框统一转成dota格式的txt文件(也就是poly格式)
他的格式一般是这样:

————数字分别对应从左上角开始顺时针旋转的四个点坐标
接下来直接附上voc转dota的代码,适用于xml混合bndbox和robndbox的情况:
voc2dota.py
import math
import shutil
import os
import numpy as np
import xml.etree.ElementTree as ET
dataset_dir = r'/home/xiaopeng/dataset/test_oriented/1/img'
ana_dir = r'/home/xiaopeng/dataset/test_oriented/1/xml'
save_dir = r'/home/xiaopeng/dataset/test_oriented/1/dota_txt'
train_img_dir = r'/home/xiaopeng/dataset/test_oriented/1/imgSets/test.txt'
f1 = open(train_img_dir, 'r')
train_img = f1.readlines()
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc;
yoff = yp - yc;
cosTheta = math.cos(theta)
sinTheta = math.sin(theta)
pResx = cosTheta * xoff + sinTheta * yoff
pResy = - sinTheta * xoff + cosTheta * yoff
return str(int(xc + pResx)), str(int(yc + pResy))
def rota(x, y, w, h, a):
x0, y0 = rotatePoint(x, y, x - w / 2, y - h / 2, -a)
x1, y1 = rotatePoint(x, y, x + w / 2, y - h / 2, -a)
x2, y2 = rotatePoint(x, y, x + w / 2, y + h / 2, -a)
x3, y3 = rotatePoint(x, y, x - w / 2, y + h / 2, -a)
return x0, y0, x1, y1, x2, y2, x3, y3
for img in train_img:
shutil.copy(os.path.join(dataset_dir, img[:-1] + '.jpg'),
os.path.join(save_dir, 'images', img[:-1] + '.jpg'))
xml_file = open(os.path.join(ana_dir, img[:-1] + '.xml'), encoding='utf-8')
tree = ET.parse(xml_file)
root = tree.getroot()
with open(os.path.join(save_dir, 'labelTxt', img[:-1] + '.txt'), 'w') as f:
for obj in root.iter('object'):
cls = obj.find('name').text
box = obj.find('robndbox')
if(box!=None):
x_c = float(box.find('cx').text)
y_c = float(box.find('cy').text)
h = float(box.find('h').text)
w = float(box.find('w').text)
theta = float(box.find('angle').text)
bdx = rota(x_c, y_c, w, h, theta)
x1=bdx[0]
y1=bdx[1]
x2=bdx[2]
y2=bdx[3]
x3=bdx[4]
y3=bdx[5]
x4=bdx[6]
y4=bdx[7]
f.write("{} {} {} {} {} {} {} {} {} 0\n".format(str(x1), str(y1), str(x2), str(y2), str(x3), str(y3), str(x4), str(y4), cls))
else:
box1=obj.find('bndbox')
xmin = int(box1[0].text)
ymin = int(box1[1].text)
xmax = int(box1[2].text)
ymax = int(box1[3].text)
f.write("{} {} {} {} {} {} {} {} {} 0\n".format(xmin,ymax,xmax,ymax,xmax,ymin,xmin,ymin,cls))
生成目录下所有文件名的txt文件代码:
ListFilesToTxt.py
def ListFilesToTxt(dir, file, wildcard, recursion):
exts = wildcard.split(" ")
for root, subdirs, files in os.walk(dir):
for name in files:
for ext in exts:
if (name.endswith(ext)):
file.write(name.split('.')[0] + "\n")
break
if (not recursion):
break
def Test():
dir = "/home/xiaopeng/dataset/test_oriented/1/split_class/Rough yarn/img"
outfile = "/home/xiaopeng/dataset/test_oriented/1/split_class/Rough yarn/test.txt"
wildcard = ".txt .exe .dll .lib .jpg"
file = open(outfile, "w")
if not file:
print("cannot open the file %s for writing" % outfile)
ListFilesToTxt(dir, file, wildcard, 0)
file.close()
if __name__ == '__main__':
Test()
***———————————***2022.6.30更新
之前的voc转dota代码我自己用了之后觉得不好用,对于旋转角度比较小的情况,旋转框往往转换不出来。
在借鉴别人脚本的基础上,进行了改进,分享给大家。只需要下面一个脚本便可实现xml格式转dota格式:
roxml_to_dota.py
import os
import xml.etree.ElementTree as ET
import math
def edit_xml(xml_file):
"""
修改xml文件
:param xml_file:xml文件的路径
:return:
"""
tree = ET.parse(xml_file)
objs = tree.findall('object')
for ix, obj in enumerate(objs):
x0 = ET.Element("x0")
y0 = ET.Element("y0")
x1 = ET.Element("x1")
y1 = ET.Element("y1")
x2 = ET.Element("x2")
y2 = ET.Element("y2")
x3 = ET.Element("x3")
y3 = ET.Element("y3")
if (obj.find('robndbox') == None):
obj_bnd = obj.find('bndbox')
obj_xmin = obj_bnd.find('xmin')
obj_ymin = obj_bnd.find('ymin')
obj_xmax = obj_bnd.find('xmax')
obj_ymax = obj_bnd.find('ymax')
xmin = float(obj_xmin.text)
ymin = float(obj_ymin.text)
xmax = float(obj_xmax.text)
ymax = float(obj_ymax.text)
obj_bnd.remove(obj_xmin)
obj_bnd.remove(obj_ymin)
obj_bnd.remove(obj_xmax)
obj_bnd.remove(obj_ymax)
x0.text = str(xmin)
y0.text = str(ymax)
x1.text = str(xmax)
y1.text = str(ymax)
x2.text = str(xmax)
y2.text = str(ymin)
x3.text = str(xmin)
y3.text = str(ymin)
else:
obj_bnd = obj.find('robndbox')
obj_bnd.tag = 'bndbox'
obj_cx = obj_bnd.find('cx')
obj_cy = obj_bnd.find('cy')
obj_w = obj_bnd.find('w')
obj_h = obj_bnd.find('h')
obj_angle = obj_bnd.find('angle')
cx = float(obj_cx.text)
cy = float(obj_cy.text)
w = float(obj_w.text)
h = float(obj_h.text)
angle = float(obj_angle.text)
obj_bnd.remove(obj_cx)
obj_bnd.remove(obj_cy)
obj_bnd.remove(obj_w)
obj_bnd.remove(obj_h)
obj_bnd.remove(obj_angle)
x0.text, y0.text = rotatePoint(cx, cy, cx - w / 2, cy - h / 2, -angle)
x1.text, y1.text = rotatePoint(cx, cy, cx + w / 2, cy - h / 2, -angle)
x2.text, y2.text = rotatePoint(cx, cy, cx + w / 2, cy + h / 2, -angle)
x3.text, y3.text = rotatePoint(cx, cy, cx - w / 2, cy + h / 2, -angle)
obj_bnd.append(x0)
obj_bnd.append(y0)
obj_bnd.append(x1)
obj_bnd.append(y1)
obj_bnd.append(x2)
obj_bnd.append(y2)
obj_bnd.append(x3)
obj_bnd.append(y3)
tree.write(xml_file, method='xml', encoding='utf-8')
def rotatePoint(xc, yc, xp, yp, theta):
xoff = xp - xc;
yoff = yp - yc;
cosTheta = math.cos(theta)
sinTheta = math.sin(theta)
pResx = cosTheta * xoff + sinTheta * yoff
pResy = - sinTheta * xoff + cosTheta * yoff
return str(int(xc + pResx)), str(int(yc + pResy))
def totxt():
xml_path = '/home/xiaopeng/dataset/test_oriented/3/split/for-try (copy)'
out_path = '/home/xiaopeng/dataset/test_oriented/3/split/try_txt/'
files = os.listdir(xml_path)
for file in files:
tree = ET.parse(xml_path + os.sep + file)
root = tree.getroot()
name = file.strip('.xml')
output = out_path + name + '.txt'
file = open(output, 'w')
objs = tree.findall('object')
for obj in objs:
cls = obj.find('name').text
box = obj.find('bndbox')
x0 = int(float(box.find('x0').text))
y0 = int(float(box.find('y0').text))
x1 = int(float(box.find('x1').text))
y1 = int(float(box.find('y1').text))
x2 = int(float(box.find('x2').text))
y2 = int(float(box.find('y2').text))
x3 = int(float(box.find('x3').text))
y3 = int(float(box.find('y3').text))
file.write("{} {} {} {} {} {} {} {} {} 0\n".format(x0, y0, x1, y1, x2, y2, x3, y3, cls))
file.close()
print(output)
if __name__ == '__main__':
dir = "/home/xiaopeng/dataset/test_oriented/3/split/for-try (copy)"
filelist = os.listdir(dir)
for file in filelist:
edit_xml(os.path.join(dir, file))
totxt()
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)