1 物理内存
1.1 物理内存概述
1.2 直接使用物理内存的问题
1.2.1 多进程地址布局困难
1.2.2 进程地址空间小
1.2.3 程序链接不统一
2 虚拟内存
2.1 引入虚拟内存的目的
2.2 局部性原理与虚拟内存
2.3 虚拟内存到物理内存的映射
2.3.1 概述
2.3.2 页面分配与映射
2.4 页表结构
2.4.1 概述
2.4.2 页表
2.4.3 页目录表
2.4.4 虚拟地址翻译过程
3 页面换入换出
4 内存的段式管理与页式管理
4.1 段式管理
4.1.1 特征
4.1.2 优点
4.1.3 缺点
4.2 页式管理
4.2.1 特征
4.2.2 优点
4.3 使用现状
5 内存布局
5.1 抽象内存布局
5.1.1 内存布局组成
5.1.2 磁盘程序段与内存程序段
5.2 IA-32 + Linux的进程内存布局
5.3 Intel 64 + Linux的进程内存布局
5.3.1 使用部分地址线
5.3.2 canonical address
1 物理内存
1.1 物理内存概述
1. 物理内存由多个连续的存储单元组成,每个单元称为一个字节
2. 每个字节有一个唯一的物理地址(Physical Address,PA),地址编码从0开始
3. 在早期的体系结构中(e.g. X86实模式),程序直接使用物理地址。也就是说,程序中每个数据存储在内存中的位置,都由程序员负责
1.2 直接使用物理内存的问题
1.2.1 多进程地址布局困难
由于系统中存在多个进程,每个进程分配多少内存、如何保证指令中访问内存地址的正确性并且与其他进程不冲突,都需要程序员完成。相当于将linker和loader的工作全部交给程序员手动完成
1.2.2 进程地址空间小
由于是多个进程共享物理内存,所以需要对每个进程可使用的物理内存区域进行分配,因此每个进程的地址空间都很小(最大也不会超过当前可使用的物理内存)
1.2.3 程序链接不统一
1. 对于程序而言,链接地址和运行地址需要一致,才能确保程序中的地址相关操作正确执行
2. 由于进程被分配在不同的物理地址运行,所以在链接时需要指定相应的链接地址。或者说,程序需要加载到链接地址处运行
说明:上述情况是针对没有分段机制的处理器而言的,对于有分段机制的处理器(e.g. X86),程序可以使用统一的链接方式(e.g. 程序中的每个段都从0地址开始链接),此时程序中使用相对于段起始位置的偏移地址而不是使用绝对地址
在加载程序时,将程序中不同的段加载到当前空闲的物理内存中,之后用段寄存器记录段的物理起始地址,即可以实现程序的重定位
相关内存可参考X86汇编语言从实模式到保护模式01:处理器、内存和指令_麦小兜的博客-CSDN博客 chapter 2,相关加载器的实现可参考X86汇编语言从实模式到保护模式07:硬盘和显卡的访问控制_麦小兜的博客-CSDN博客
2 虚拟内存
2.1 引入虚拟内存的目的
虚拟内存的出现,就是为了解决直接使用物理内存的问题
1. 使得每个进程有不依赖物理内存大小的虚拟地址空间,这个空间可以比可用的物理内存大得多
2. 使得每个进程的虚拟地址空间是私有的、独立的,与其他进程的虚拟地址空间相互隔离,这就解决了多进程之间地址冲突的问题
3. 由于虚拟地址空间是进程独占的,可以任意使用,因此可以将变量和函数分配地址的任务交给链接器自动安排
也就是说,每个进程的虚拟地址空间布局是相同的,因此链接器可以按统一的方式链接不同程序
2.2 局部性原理与虚拟内存
处理器和操作系统是基于局部性原理(Principle of locality)为程序员虚拟化了一层内存,也就是虚拟内存。局部性原理有如下2方面,
1. 时间局部性:被访问过一次的内存地址很可能在不远的将来会被再次访问
2. 空间局部性:如果一个内存地址被访问过,那么与他临近的地址在不远的将来也很可能会被访问
从局部性原理就可以得出结论:无论一个进程占用的内存资源有多大,在任一时刻,他需要的物理内存都是很少的
在这个推论的基础上,处理器只要为每个进程保留很少的物理内存就可以保证进程的正常执行
2.3 虚拟内存到物理内存的映射
2.3.1 概述
1. 任何虚拟内存中的的数据,最终还是要保存在真实的物理内存中。也就是说,虚拟内存需要映射到物理内存
2. 虚拟内存的大小远大于物理内存的大小
3. 基于局部性原理,处理器和操作系统只将当前使用的虚拟内存映射到物理内存
2.3.2 页面分配与映射
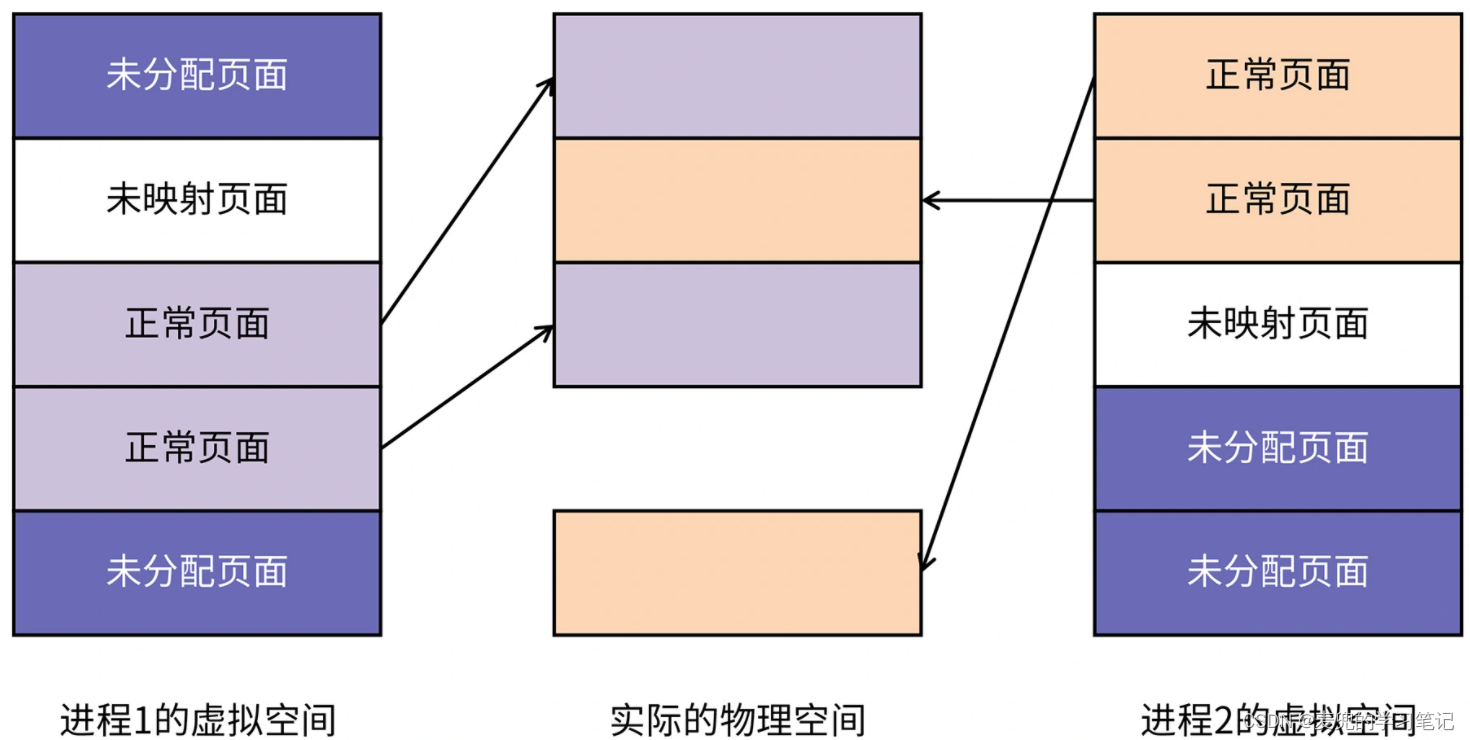
1. 首先,虚拟内存与物理内存的映射以页为单位,常见的页大小为4KB
2. 虽然虚拟内存提供了很大的地址空间,但是在进程启动后,这些空间并不是全部被使用,而是处于未分配状态
3. 当程序中通过malloc等内存分配接口获取内存时,相应的虚拟内存页面将从未分配转变为已分配但未映射状态
4. 当对这段分配到的虚拟内存进行读写时,操作系统才会在缺页异常中为他们分配物理内存,当映射关系建立后,该页面转变为正常页面
可见虚拟内存实现一个假象,让程序员觉得整个虚拟内存空间可以随时访问,但真实的数据可能不在物理内存中,而是在需要用到时才被加载到内存中,并建立虚拟内存到物理内存的映射
说明1:虚拟地址中的"虚拟",是指不存在但能看见
① 本质上,虚拟地址是一套虚拟内存分配与映射机制,真正操作的还是物理内存。所以说虚拟内存本身是不存在的
② 但是对程序员而言,能直接操作的就是虚拟地址,因此是能看见的
说明2:引入虚拟内存后,分配内存分为2级
① 首先是在进程的虚拟地址空间中分配虚拟内存
② 之后是分配物理内存,并建立虚拟内存与物理内存的映射关系
分配物理内存被推迟到对虚拟内存的访问触发缺页异常时才进行,实现了按需加载
说明3:当虚拟内存已分配但未映射时,他所对应的数据在哪里?
① 可能在磁盘上,比如文件
② 也可能是申请但未访问的内存,比如malloc分配一个数组
说明4:在虚拟内存中连续的页面,在物理内存中不必是连续的。只要维护好从虚拟内存到物理内存的映射关系,就能正确使用内存
说明5:虚拟地址空间的大小
虚拟地址空间的大小一般由处理器字宽决定,
① 对于32位处理器,寄存器是32位的,可以存储32位指针,因此能表示的地址范围为0 ~ 4GB
② 对于64位处理器,寄存器是64位的,可以存储64位指针。但是一般并不实际使用全部位数,比如只使用低48位,此时的虚拟地址空间为256TB
说明6:有不遵循局部性原理的程序吗?
① 这种局部性不好的程序是存在的,他会导致处理器频繁进入缺页异常,为其分配物理内存,从而影响性能
② 对于这种程序,在物理内存足够的情况下,应该让其使用的数据尽可能驻留在内存中
③ 可以在该程序启动时,就分配虚拟内存,并且对分配的虚拟内存空间进行一次访问,强制将未映射的页面转变为正常页面,从而降低缺页异常发生的概率
上述过程通常称为内存的commit
2.4 页表结构
2.4.1 概述
1. 上述虚拟内存和物理内存的映射关系由操作系统管理,而管理这种映射关系的数据结构就是页表
2. 映射的过程由处理器的内存管理单元(Memory Management Unit,MMU)自动完成,但是他依赖操作系统设置的页表。因此,虚拟内存是软硬件一体化设计的典型代表
2.4.2 页表

1. 页表本质上是页表项(Page Table Entry,PTE)的数组,虚拟地址空间中的每个虚拟页在页表中都有一个PTE与之对应
2. 以X86-32体系结构为例,页大小为4KB,每个页表项4B,因此将1024个页表项组成一张页表。这样一张页表的大小正好是4KB,占据一个内存页
3. 而一张页表的1024个页表项能够映射1024 * 4KB = 4MB内存
2.4.3 页目录表
如上文所述,一张页表可以映射4MB内存。为了编码更多地址,就需要更多页表。因此引入了页目录表
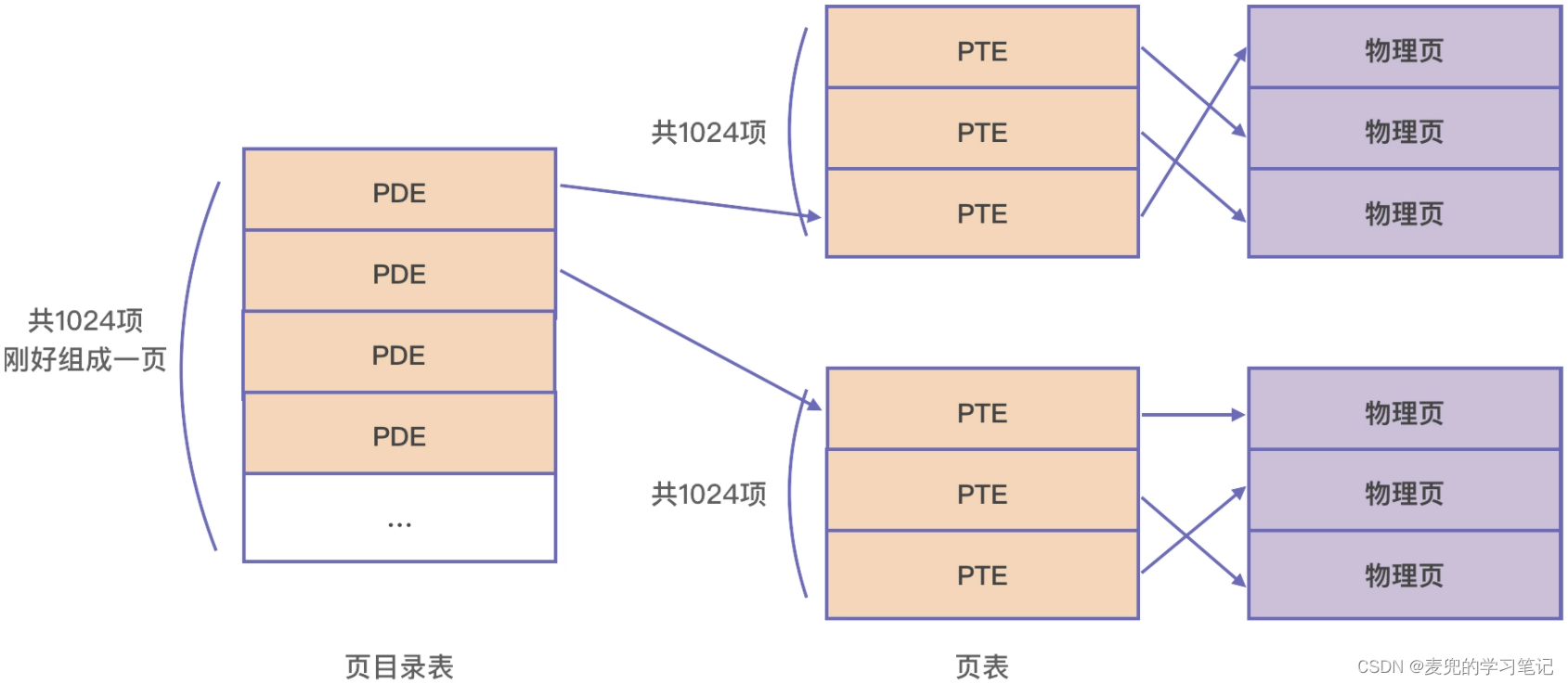
1. 页目录表中的每一项叫做页目录项(Page Directory Entry,PDE),每个PDE都对应一张页表
2. 每个页目录项也是4B,因此将1024个页目录项组成一张页目录表,可以映射1024 * 4MB = 4GB内存,可以覆盖32位处理器的虚拟地址空间
说明:使用多级页表结构,而不是使用单级页表的原因,可参考X86汇编语言从实模式到保护模式19:分页和动态页面分配_麦小兜的博客-CSDN博客_汇编page chapter 2.4.3
2.4.4 虚拟地址翻译过程
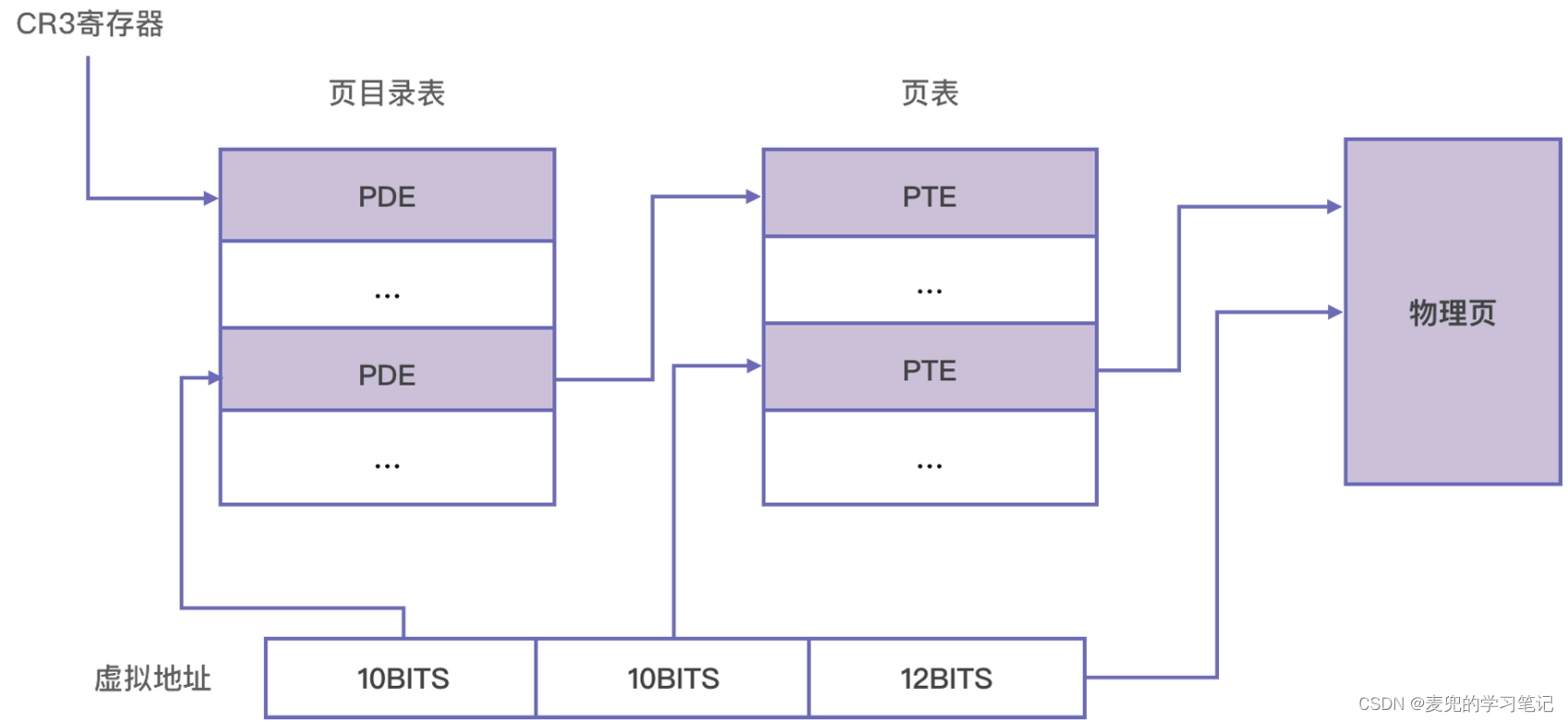
以X86-32体系结构为例,使用两级页表,并将虚拟地址划分为3段,分别作为页目录表索引、页表索引和页内偏移量
虚拟地址的翻译过程如下,
1. 确定页目录基址
每个CPU都有一个页目录基址寄存器,记录最高级页表的物理基地址。在X86-32体系结构中,就是CR3寄存器
2. 定位页目录项(PDE)
页目录物理基址 + 虚拟地址高10位 * 4 = PDE物理地址
页目录项(PDE)中记录了页表的物理地址
3. 定位页表项(PTE)
页表物理基址 + 虚拟地址中间10位 * 4 = PTE物理地址
页表项(PTE)中记录了物理页的物理地址
4. 确定物理地址
以虚拟地址低12位作为物理页中的索引
说明1:页表项(PTE)中处理记录物理页的物理地址外,还记录了一些属性(e.g. 页的读写权限、标记页是否存在),操作系统可以基于这些属性实现内存保护
说明2:每个进程都有自己的页目录表,当进程切换时,会将目标进程的页目录表物理地址加载到CR3寄存器。所以在任意时刻,只有一个进程页表是活跃的
说明3:在64位处理器上,由于虚拟地址空间更大,需要更多级的页表
以X86-64体系结构为例,PDE和PTE都是8B,所以一页之中只能存放512项,需要9位进行编码。所以虚拟地址会被分割为9 + 9 + 9 + 9 + 12共4段,而页表也是4级
由此可见,页表的级数与虚拟地址的分段是匹配的
3 页面换入换出
1. 由于程序运行符合局部性原理,对于那些没有被经常使用的内存,可以将他们换出到内存之外,比如磁盘的swap分区
2. 当物理内存足够时,操作系统会让尽可能多的页驻留在物理内存中,因为将内存中的数据写入磁盘是非常耗时的操作
说明1:极端情况下,给一个进程4KB物理内存就可以。操作系统通过对一页不断的换入换出,使得进程可以运行
说明2:虚拟内存会耗尽吗?
① 虚拟内存也是会耗尽的,也就是out of memory错误。以Linux 32位操作系统为例,用户空间只有3GB,如果程序中一次性要申请4GB内存,则虚拟内存不足
② 虽然有了虚拟内存,但是物理内存还是会耗尽的。当物理内存不足时,可以将不活跃的物理页换出到磁盘的swap分区。当swap分区耗尽时,物理内存就耗尽了
所以任何时候,及时释放申请的内存是一个好习惯
4 内存的段式管理与页式管理
说明:关于X86体系结构实模式与保护模式的相关内容,可参考X86汇编语言:从实模式到保护模式学习笔记
X86汇编语言:从实模式到保护模式学习笔记
4.1 段式管理
4.1.1 特征
1. 按功能将内存划分为不同的段,例如代码段、数据段、只读数据段、栈段等
2. 为不同的段设置不同的特权级和读写权限
4.1.2 优点
1. 按功能对内存进行划分,符合人的直观思维
2. 可以提供更好的安全性(这点依赖保护模式下段机制的检查机制)
4.1.3 缺点
1. 段长度往往是不固定的,难以以段为单位进行内存的分配和回收
4.2 页式管理
4.2.1 特征
1. 不按功能对内存进行划分,而是按固定大小将内存划分为大小相同的页
2. 无论存放数据还是代码,都需要先分配一个页,再将内容加载到页中
4.2.2 优点
1. 页大小固定,易于内存的分配与回收
2. 段式管理提供的安全性,在现代CPU中可以被页表项中的属性替代
4.3 使用现状
1. 现代操作系统都采用段式管理实现基本的权限管理(比如区分内核态和用户态),而对于内存的分配、回收和调度则依靠页式管理实现
2. 段式管理负责将逻辑地址转换为线性地址,页式管理负责将线性地址转换为物理地址。通过使用段页式混合管理模式,兼具了段式管理和页式管理的优点
说明1:现代操作系统中,一般将段描述符中的段基址设置为0,段长度设置为最大,也就是使用平坦模型
说明2:段式管理与页式管理的内存碎片
① 段式管理可以根据实际需求分配段的大小,因此段内部没有内存碎片。但是由于每个段的长度不固定,所以多个段未必能敲好使用所有的内存空间,所以段与段之间会产生内存碎片
② 页式管理中页的大小固定,即使所需内存不足一页,也会分配一页,因此页内部有内存碎片。但是页与页之间紧密排列,没有内存碎片
说明3:操作系统弱化分段机制后如何补偿
① 首先需要说明的是,X86体系结构的设计者希望大家继续使用段机制,所以基于段寄存器构造了保护模式,同时在段和页两级提供权限管理机制
但是Linux操作系统使用平坦模型绕过了段机制,且大多数体系结构都没有段基址,所以段机制逐渐被弱化。甚至在X86-64体系结构中,默认就是使用平坦模型,废弃了段描述符中的段基址和长度
② Linux内核引入vm_area_struct结构,通过软件方式进行权限管理,部分代替了段基址的权限管理工作
5 内存布局
5.1 抽象内存布局
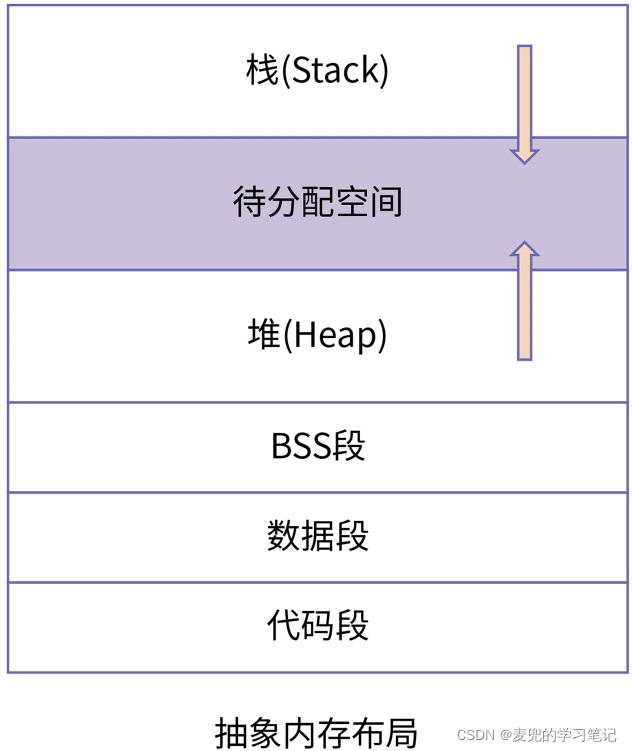
5.1.1 内存布局组成
抽象内存布局描述的是运行一个程序所需的最小功能集,对于一个典型的进程,内存布局包括如下部分
1. 代码段
存储程序的机器指令,这段区域的内存一般可读可执行,但不可写
2. 数据段
① 存储程序中已经初始化且不为0的全局变量和静态变量
② 这些变量的初值会存储在程序编译后的二进制文件中,然后被加载到内存中
3. BSS(Block Started by Symbol)段
① 存储程序中未初始化或初始化为0的全局变量和静态变量
② 由于他们的初值为0,因此不需要在程序编译后的二进制文件中存储那么多0,只需要记录他们的起止地址即可
③ 操作系统在加载程序时,会根据记录的BSS段起止地址初始化相应的内存区域
④ BSS除了Block Started by Symbol,从功能上也可以理解为Better Save Space
4. 堆 & 栈
堆空间和栈空间不是从磁盘上加载,而是在程序运行过程中申请的内存空间
说明1:Linux 0.11内核支持的a.out文件格式与内存布局,就是如上图所示
说明2:现代应用程序除了上面的内存段,还会包含如下内存区域
① 存放加载的共享库的内存空间
如果一个进程使用共享库(动态库),该共享库的代码段、数据段和BSS段也需要被加载到进程的地址空间中
② 共享内存段
可以通过系统调用映射一块匿名内存作为共享内存,用来进行进程间通信
③ 内存映射文件
可以将磁盘上的文件映射到内存中,用来进行文件编辑或以类似共享内存的方式进行进程间通信
5.1.2 磁盘程序段与内存程序段
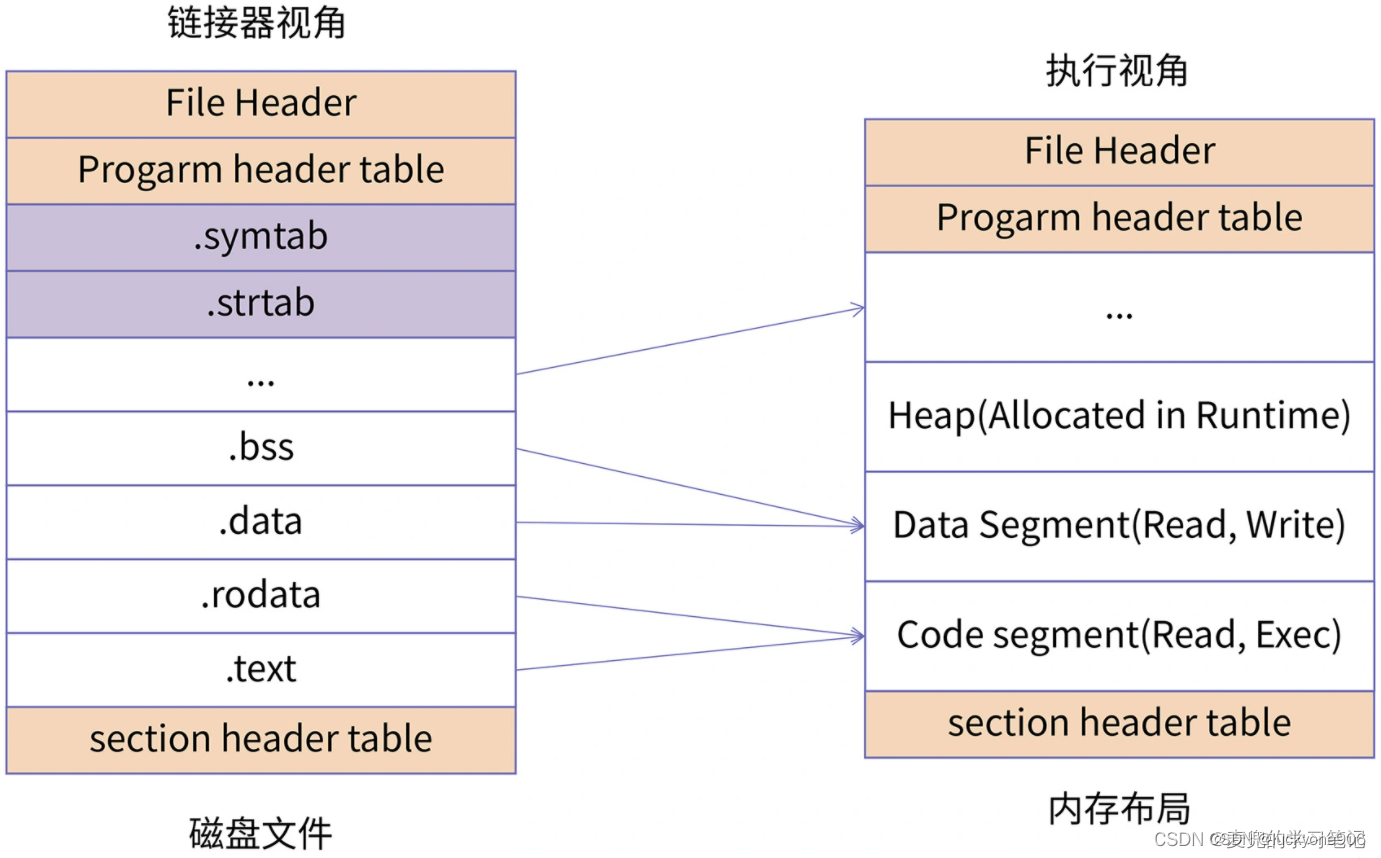
1. 上图中左边是程序在磁盘中的文件布局,右边是程序加载到内存中的内存布局
2. 对于磁盘的的程序,每个单元称为一个Section,可以通过readelf -S命令查看可执行程序中所有的Section信息
3. 对于内存镜像,每个单元称为一个Segment,可以通过readelf -l命令查看可执行程序加载到内存之后的Segment布局
说明1:Section与Segment的对应关系
① 因为Segment是将具有相同权限的Section集合在一起,为他们分配同一块内存空间,所以往往是多个Section对应一个Segment
② 对于磁盘文件中一些保存辅助信息的Section(e.g. symtab段、strtab段),不需要在内存中进行映射
说明2:Section与Segment对应关系实验
编写一个简单的hello world程序,编译后查看Section与Segment的对应关系。首先来看一下readelf命令中-S和-l选项的功能
-S:Displays the information contained in the file's section headers
-l:Displays the information contained in the file's segment headers
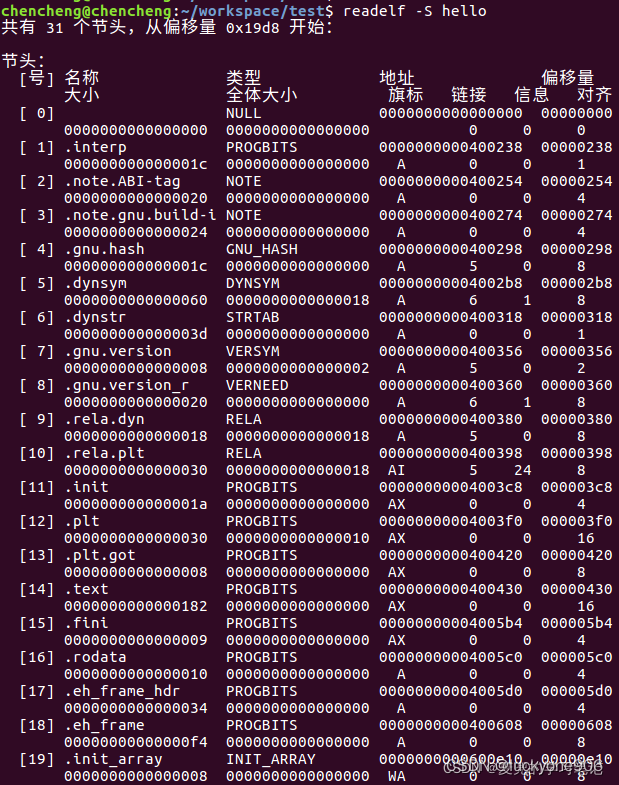
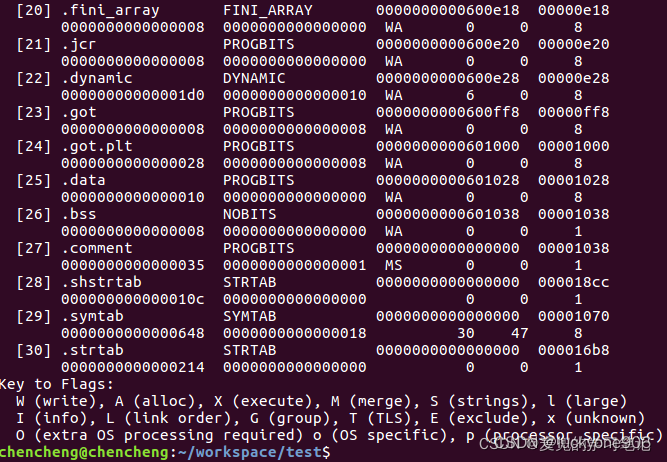
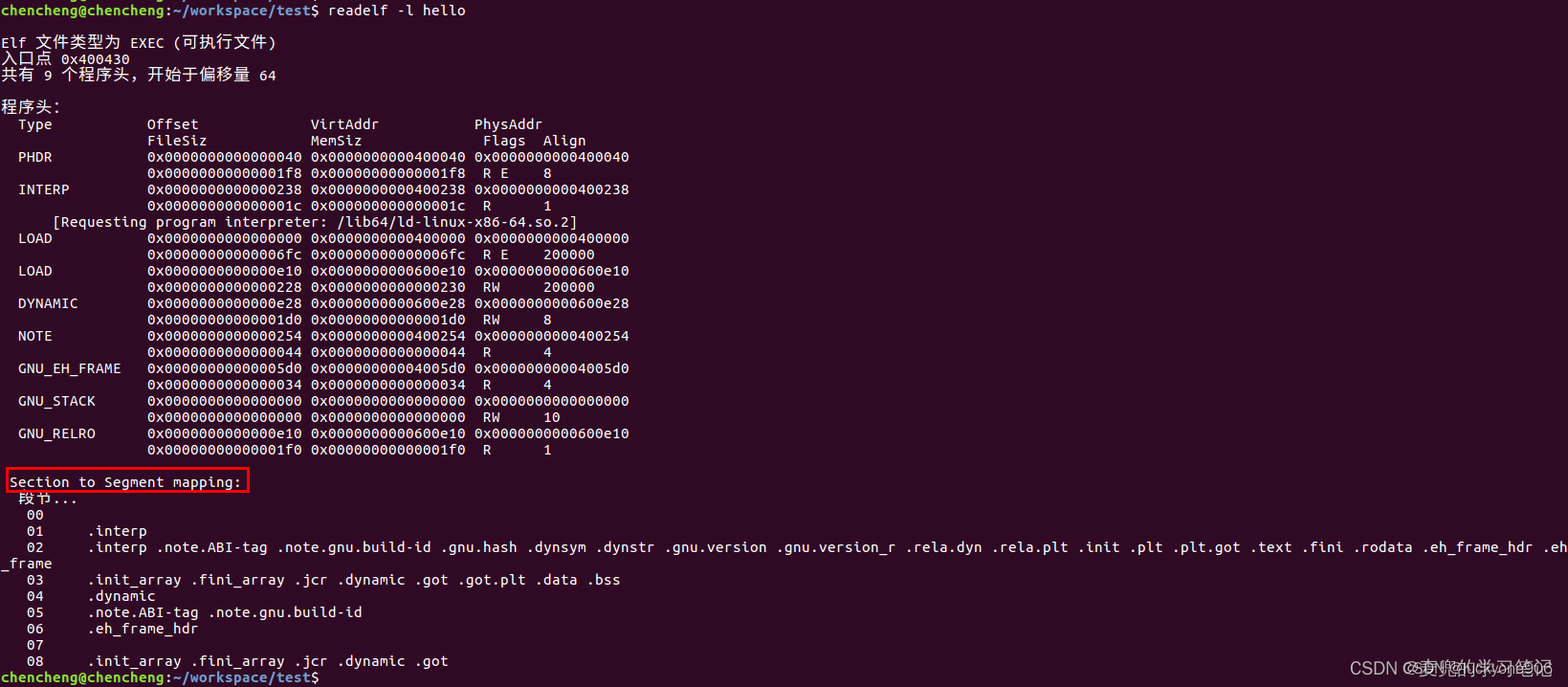
从执行结果看见,
.text段被映射到可读(R)可执行(E)的内存段
.data和.bss段被映射到可读(R)可写(W)的内存段
5.2 IA-32 + Linux的进程内存布局
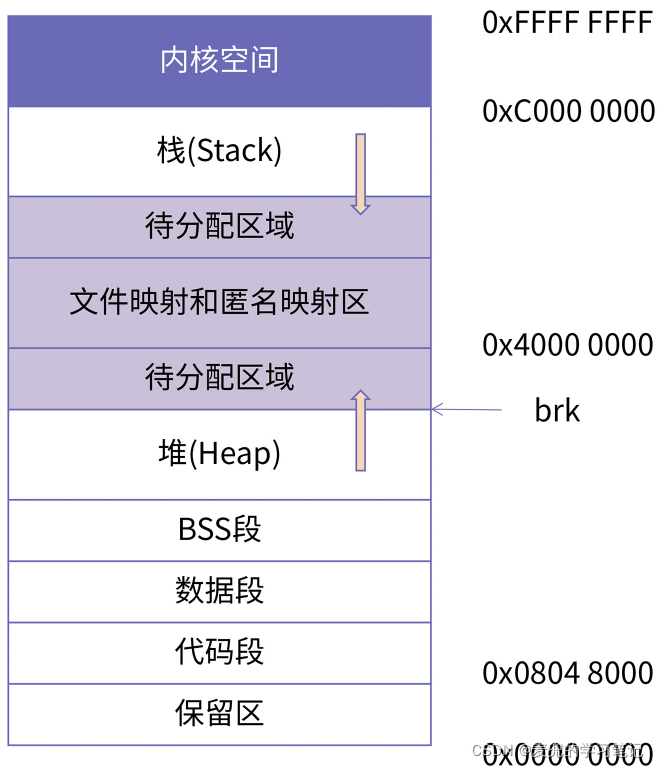
首先需要说明的是,在IA-32 + Linux的进程内存布局中,低3GB为用户空间,高1GB为内核空间,此处我们关注用户空间的组成部分
1. 保留区
① 从0地址开始的是一段不可访问的保留区,用于防止程序跑飞。这是因为在大多数系统中,一般认为一个比较小数值的地址是一个不合法地址(e.g. NULL指针)
② 此处保留区大小为0x08048000,约128MB
2. 代码段
① 从0x08048000开始是代码段
② 以上地址需要GCC在编译时不开启PIE选项
③ 代码段是从可执行文件镜像中加载到内存中
3. 数据段
① 数据段紧接在代码段之后
② 数据段也是从可执行文件镜像中加载到内存中
4. BSS段
① BSS段紧接在数据段之后
② BSS段是根据BSS段所需大小,在加载时生成的一段以0填充的内存空间
③ 由于BSS段和数据段属性相同,所以如之前的实验所示,在内存中与数据段映射在相同的Segment
5. 堆(Heap)
① 堆空间地址向上增长
② 堆的指针叫做Program break
③ 每次进程向内核申请新的堆地址时,分配的地址值增加
④ 堆的最大值会受到操作系统限制,如果耗尽就会发生out of memory错误,分配不出新的内存
6. 栈(Stack)
① 栈空间地址向下增长
② 栈的指针叫做Stack Pointer
③ 每次进程申请新的栈地址时,分配的地址值减小
7. 文件映射与匿名映射区
这里最常见的就是程序所依赖的共享库(e.g. libc.so),共享库的代码段、数据段和BSS段会被加载到这里
说明1:可以通过cat /proc/[pid]/maps命令查看指定进程的虚拟内存空间布局
示例程序如下,
将该程序在后台运行,之后查看对应进程的虚拟内存空间布局
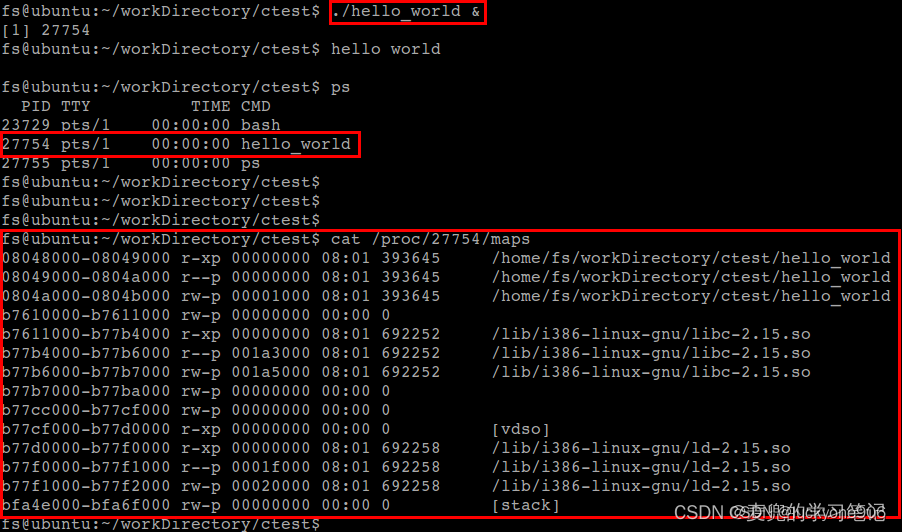
说明2:进程地址随机化
① 上述内存布局是在Linux操作系统关闭进程地址随机化时的情况,如果打开进程地址随机化,其中的堆空间、栈空间和共享库映射的地址,在每次程序运行时都会不一样
② 在实现方法上,就是内核在加载程序时,会对这些区域的起始地址增加一个随机的偏移量
③ 可以通过sysctl命令设置进程地址随机化
sudo sysctl -w kernel.ramdomize_va_space=val
# val = 0,表示关闭内存地址随机化
# val = 1,表示mmap的基地址、栈地址和VDSO的地址随机化
# val = 2,表示在1的基础上,增加堆地址随机化
补充:地址随机化是由Linux内核与GCC的PIE编译选项共同决定的,操作系统的加载器负责生成随机地址,编译器负责产生的代码地址无关(因此使能进程地址随机化,需要编译时携带PIE选项)
5.3 Intel 64 + Linux的进程内存布局

Intel 64 + Linux进程内存布局中的组成部分与Intel 32中是相同的,此处重点说明虚拟地址空间的划分
5.3.1 使用部分地址线
1. 64位处理器的理论寻址范围为2^64 = 16EB,但是目前的操作系统和应用程序往往用不到这么庞大的地址空间,因此只使用部分地址线
2. Intel 64位处理器目前支持48位虚拟地址,即寻址空间为2^48 = 256TB
3. 由于使用48位虚拟地址,所以地址的最高有效位为bit [47](从bit[0]开始)
5.3.2 canonical address
1. Intel 64位体系结构定义了canonical address的概念,即在64位模式下,如果地址位63到地址最高有效位被设置为全0或全1,那么该地址被认为是canonical form
2. 在Intel 64位体系结构中使用48位虚拟地址,因此根据canonical address的划分,地址空间天然被划分为两个区间,分别是0x0 ~ 0x00007FFFFFFFFFFF和0xFFFF800000000000 ~ 0xFFFFFFFFFFFFFFFF这2个128TB空间(即根据地址最高有效位bit [47],用该值设置到bit [63])
3. 地址空间中的其他区域均不满足canonical form,也就是上图中的非canonical空间,对这部分内存不会建立页表进行映射
4. 在实际使用中,将低128TB用作用户空间,高128TB用作内核空间
说明1:在64位操作系统中查看进程虚拟地址内存布局
使用与32位操作系统中相同的hello world程序
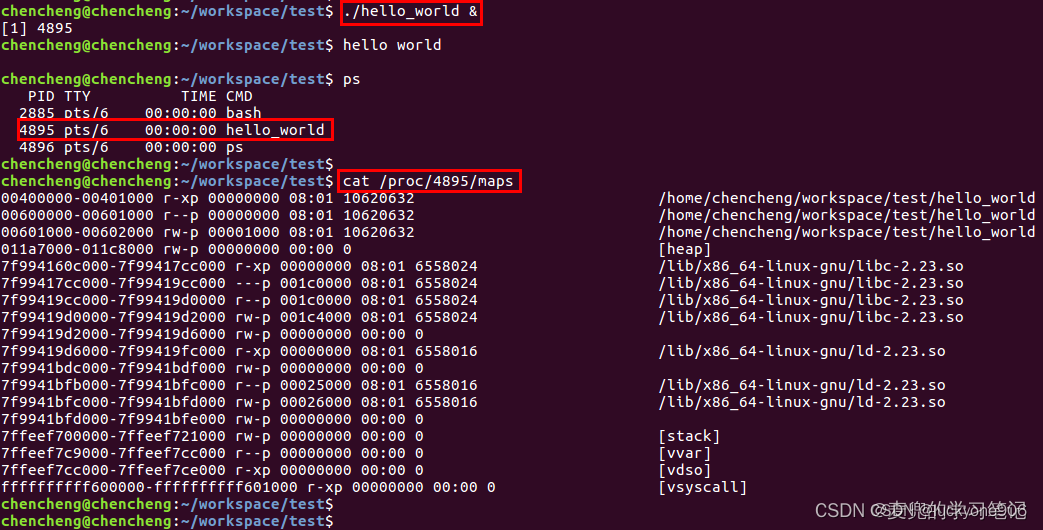
从中可以看出,在代码段(0x00400000 ~ 0x00401000)和数据段(0x00600000 ~ 0x00601000)之间存在一段空隙
对于64位应用程序,这是一段不可读写的保护区域,作用是防止程序在读写数据段时越界访问到代码段。这个保护段可以让这种越界访问行为直接崩溃,防止程序继续运行下去
/************************************************************************************
在早期的计算机中,程序都是直接运行在物理内存上的,意思是运行时访问的地址都是物理地址,而这要求程序使用的内存空间不超过物理内存的大小。
在现代计算机操作系统中,为了提高CPU的利用率计算机同时运行多个程序,为了将计算机上有限的物理内存分配给多个程序使用,并做到隔离各个程序的地址空间和提高内存利用率,操作系统应用虚拟内存机制来管理内存。
本文介绍的是一些与虚拟内存相关的概念,包括虚拟内存和物理内存之间的映射,一个进程的虚拟内存空间的划分等。
目录
1.物理内存 vs 虚拟内存
2.物理内存空间 和 虚拟内存空间
3.4GB虚拟内存
cpu位宽 vs cpu的地址总线位宽
4.虚拟内存的地址空间划分
Windows 系统下,4G虚拟地址空间被分成了 4 部分: NULL 指针区+用户区+ 64KB 禁入区+内核区。
1)NULL指针区和64KB禁入区:略
2)用户区每个进程私有使用的,大约 2GB 左右 ( 最大可以调整到 3GB,3GB模式) ,称为用户地址空间。
3)内核区是所有进程共享的,为 2GB (3GB模式下就是1GB),称为系统地址空间。
Linux下和Windows下的差不多,只不过Linux默认就是1GB内核空间:
1.保留区:
2.可执行文件映像,堆,栈,动态库
栈空间(Stack)——函数调用:
通过例子1看汇编:
例子2:(VC9,i386,Debug模式)
PS1:编译器 生成的函数 的 标准进入和退出指令序列
PS2:编译器 实现的hook技术
PS3:函数调用之调用惯例
PS4:函数调用之返回值的传递
PS5:函数调用之C++对象
堆空间(heap)——动态申请内存:
5.虚拟地址和物理地址的映射
6.物理内存和硬盘之间的置换
7.虚拟内存的重要性
8.进程的虚存空间分布——装载(程序员的自我修养-链接装载库 第6.4节)
readelf -S链接视图——25个section头
执行视图:7个program头——程序头表记录着程序头
VMA
Stack VMA[stack]
动态链接时的进程堆栈初始化信息
1.物理内存 vs 虚拟内存
物理内存就是内存条,实实在在的内存,即RAM。
虚拟内存是内存管理中的一个概念。对于一个进程来说,虚拟内存是进程运行时所有内存空间的总和,包括共享的,非共享的,存在物理内存中,存在分页内存中(分页后面会介绍),提交的,未提交的。【进程运行起来以后,虚拟内存映射=PP物理空间+DP硬盘空间+未使用使用映射的。】【虚拟内存映射的可能有一部分不在物理内存中,另外一部分在其他介质中,比如硬盘,举个例子,当你的程序需要创建一个1G的数据区,但是此时剩余500M的可用物理内存了,那么此时势必不是所有数据都能一起加载到内存(物理内存)中,势必有一部分数据要放到其他介质中(比如硬盘),待进程需要访问那部分在其他介质中的数据时,再通过调度进入物理内存。】
2.物理内存空间 和 虚拟内存空间
物理内存大小组成的地址空间就叫物理内存空间。物理内存空间表示的是实实在在的RAM物理内存,其地址空间可以看成一个由 M 个连续的字节大小的单元组成的数组,每个字节都有一个唯一的物理地址。【存储单元,也就是每个字节都有其地址,cpu进行访问的时候需要知道其地址。M就是RAM的大小】
虚拟内存大小组成的地址空间就叫虚拟内存空间。跟物理内存一样,也是有地址空间的,用地址标识哪个内存位置,也看成一个连续的字节大小的单元组成的数组。【虚拟内存空间实际上并不存在的,需要的只是虚拟内存空间到物理内存空间的映射关系的一种数据结构。】
上面说的数组的大小,就是地址空间的长度。
即地址空间是一个抽象的概念,可以想象成一个很大的数组,每个数组的元素是一个字节,而这个数组的大小就是由地址空间的地址长度决定。一般画图也是这么画的。
比如16G的物理内存条,具有0~0x3FFFFFFFF(16G)的地址长度的寻址能力。【另一方面,cpu的地址总线位宽决定了可以直接进行寻址物理内存空间最大值】
4G虚拟内存,具有0~0xFFFFFFFF的地址长度的寻址能力。
在一个系统中,物理内存空间只有一个,但是虚拟内存空间有很多个(运行着多个进程)。每个虚拟内存空间都有必须有一个映射关系对应于物理内存。【在进程启动的时候会建议一个映射关系,在运行中维护这个关系,后面会讲】
对于一般程序而言,虚拟内存空间中的很大部分的都是未使用的,【虚拟内存是4G的空间】
每个虚拟内存空间往往只能映射到很少一部分物理空间上。每个物理页(将整个物理空间划分成多个大小相等的页)可能只是被映射到一个虚拟地址空间中,也有可能存在一个物理页被映射到多个虚拟地址空间中,那么这些地址空间将共享此页面(如果在一个虚拟地址空间改写了此页面的数据,这在其他的虚拟地址空间也可以看到变化)
3.4GB虚拟内存
操作系统(32位)会为每一个新创建的进程分配一个 4GB 大小的虚拟内存,从0到2^32-1。(这里说的分配4GB的虚拟内存并不是分配4GB的空间,而是创建一个映射表。映射表存放在物理内存中。以后会介绍到一级页表和二级页表结构,这个映射表肯定加载在物理内存中,这个映射表最好是设计得当然是越小越好了)
之前一直说是4G的虚拟地址空间,那么为什么是分配一个4GB的虚拟地址空间,因为在32位操作系统下一个32位的程序的一个指针长度是 4 字节(指针即为地址,指针里面存储的数值被解释成为内存里的一个地址。64位程序指针是64位,寻址能力2^64-1), 4 字节指针(地址)的寻址能力是从 0x00000000~0xFFFFFFFF ,最大值 0xFFFFFFFF 表示的即为 4GB 大小的容量。
这个虚拟空间地址大小和 实际物理内存RAM大小没有关系。
补充:一个进程的虚拟内存的大小是由操作系统的位宽和程序是32位还是64位决定的。
下面解释一下cpu位宽和cpu地址总线位宽的以及他们的位宽大小会影响什么。
cpu位宽 vs cpu的地址总线位宽
1.我们说的16位cpu,32位cpu,64位cpu,指的都是cpu的位宽,表示的是一次能够处理的数据宽度,即一个时钟周期内cpu能处理的2进制位数,即分别是16bit,32bit和64bit。不是地址总线的数目。
(通用寄存器的宽度决定了cpu可以直接表示的数据范围。我们说的16位cpu,32位cpu,64位cpu,指的就是通用寄存器的位数(宽度)。见 汇编语言 那篇文章)
2.cpu的地址总线位宽决定了可以直接进行寻址物理内存空间。所以如果cpu的地址总线是32位的,也就是它可以寻址0~0xFFFFFFFF(4G)的物理内存空间。但是如果你的计算机上只装了512M的内存条,那么物理地址的有效部分只有0x00000000~0x1FFFFFFF,其他部分都是无效的物理地址。(这里无视一些外部的I/O设备映射到物理空间。)
3.cpu位宽不等于cpu的地址总线位宽,16位cpu的地址总线位宽可以是20位,32位cpu的地址总线可以是36位,64位cpu的地址总线位宽可以是36位或者40位(cpu能够寻址的物理地址空间为64GB或者1T)。
4.在cpu访问任何存储单元必须知道其物理地址,所以在一定程度上,cpu的地址总线宽度影响了最大支持的物理内存RAM大小(操作系统的位数也会影响,32位系统,最大就是支持4GB物理内存RAM)
32位系统最大只能支持4GB内存之由来 - Matrix海子 - 博客园
4.虚拟内存的地址空间划分
Windows 系统下,4G虚拟地址空间被分成了 4 部分: NULL 指针区+用户区+ 64KB 禁入区+内核区。
为了高效的调用和执行操作系统的各种服务,Windows会把操作系统的内核数据和代码(内核提供了各种服务供应用程序使用)映射到所有进程的进程空间中。即内核态,也称为系统空间,也可以叫做系统空间。
所以内核态只有一个,会映射到所有的进程空间中。从这个角度来看,用户空间是每个进程独立的,内核空间是共享的。

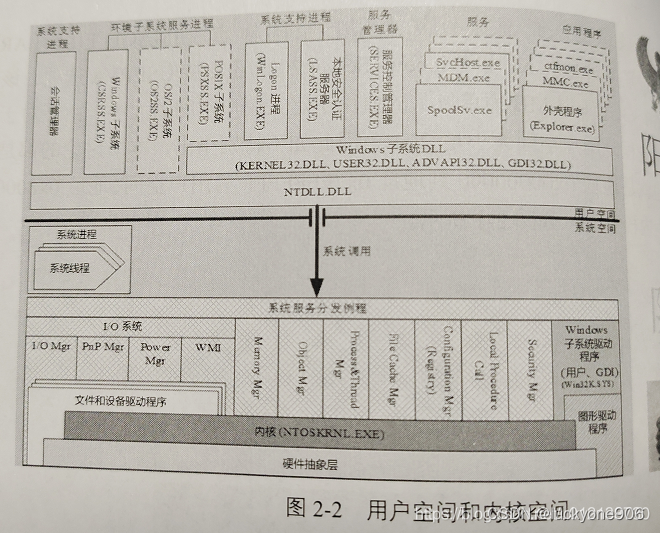
1)NULL指针区和64KB禁入区:略
2)用户区每个进程私有使用的,大约 2GB 左右 ( 最大可以调整到 3GB,3GB模式) ,称为用户地址空间。
用户区存放的是程序代码和数据, 堆, 共享库, 栈。
默认的windows配置下是2GB+2GB,称为2GB模式。可以修改windows配置,可以设置3GB用户地址空间+1GB的系统地址空间,称为3GB模式。
如上图:(以下都是用户态的,用户态的,用户态的,ntdll.dll是用户态的,而且都是共享,每个进程都是同一个虚拟地址的。一些固定的地址。)
0x80000000附近的:如系统库(ntdll.dll:windows操作系统用户层的最底层的dll,负责windows子系统与windows内核之间接口,比如堆管理器的核心接口,HeapCreate、HeapAlloc、HeapFree和HeapDestroy,向操作系统申请内存的时候WindowsAPI:VirtualAlloc进行申请。
ntdll.dll是NT内核派驻到用户空间的领事馆,ntdll.dll是用户态和内核态沟通的桥梁。用户空间的代码通过这个dll,来调用内核空间的系统服务。操作系统会在启动阶段将这个加载到内存中,并把他映射到进程空间的同一个虚拟地址。
)
0x10000000:如运行时库(msvcr90d.dll,microsoft的c运行时库,运行时库这这篇文章介绍过)
0x00400000:可执行程序映像exe,即程序代码和数据(为什么叫映像,在这个文章介绍过)
stack栈的位置:在0x00300000和exe后面都有分布。因为有多少个线程就有多少个栈,线程默认栈大小1MB,也可以启动线程的时候自行设定大小。(所以栈,是相对于线程来说的,这在调试的时候可能看出来)
heap堆的位置:在剩下的空间中进行分配。
3)内核区是所有进程共享的,为 2GB (3GB模式下就是1GB),称为系统地址空间。
内核区保存的是系统线程调度、内存管理、设备驱动等数据,这部分数据供所有的进程共享以及操作系统的使用——程序在运行的时候处于操作系统的监管下,监管进程的虚拟空间,当进程进行非法访问时强制结束程序。
(进程只能使用操作系统分配给进程的虚拟空间。错误提示“进程因非法操作需要关闭”就是访问了未经允许的地址。)
Linux下和Windows下的差不多,只不过Linux默认就是1GB内核空间:
1.保留区:
对内存中收到保护而禁止访问的内存区域的总称。在大多数操作系统中,极小的地址都是不允许访问的,如果访问了就会抛出错误。如NULL。 通常C语言将无效指针赋值为0,因为0地址上正常情况下不可能有有效的可访问的数据的。
2.可执行文件映像,堆,栈,动态库
1)可执行文件映像:装载的时候涉及到。可执行文件的装载,进程和线程,运行时库的入口函数(第六章)_u012138730的专栏-CSDN博客_运行时动态装载链接至少需要用到以下哪些函数
2)堆:应用程序动态分配的 通常在栈的下方。地址从低到高分配。
3)动态链接库(共享库)映射区。动态链接的时候介绍。Linux之前是默认从0x4000000开始装载的,但是在linux内核2.6中,共享库的装载地址已经挪到了靠近栈的位置,即0xbfxxxxxx附近。。
4)栈:用于维护函数调用的上下文。有函数调用就要用到栈。地址从高到低分配。
栈空间(Stack)——函数调用:
栈是虚拟内存空间的一段连续的地址。里面的内容是 调用函数的活动记录,记录目前为止函数调用之前的那些函数的维护信息。(函数调用,维护信息,堆栈帧,活动记录)
一个函数的活动记录(堆栈帧)可以用 ebp 和 esp 划定范围(其中参数和函数返回地址用ebp+x 可以得到,这两个也是包括在活动记录中的):
ebp和esp都是寄存器,详情看汇编指令和寄存器_u012138730的专栏-CSDN博客。
以上就是一个堆栈帧,bp指向当前的堆栈帧的底部,sp指向当前的栈帧的顶部。随着函数调用的进行以及返回,bp和sp也就是随着改变,指向新的堆栈帧或者旧的堆栈帧。
如上图,一条活动记录包括一下几个方面:
1)函数的返回地址(地址 ebp + 4)和函数的参数(地址 ebp + 8,ebp + 12等等)、
其中函数的返回地址是在call指令中push 的
其中函数的输入实参是在call之前的指令压入的
2)调用该函数之前的ebp的值(旧ebp值,上一个堆栈帧的底部的地址),目的是为了:这个函数返回的时候ebp的值可以恢复到上一个位置,回到上一个堆栈帧现场。
3)【可选】需要保持不变的寄存器的值(地址 ebp - 4,ebp - 8等等)
4)临时数据,局部变量,调试信息——扩大的栈空间中。
通过例子1看汇编:
SimpleSection.c中的func1
看func1函数的反汇编的实现(这里是.AT&T的汇编格式,看文章的最后):——其实就是创建了一个堆栈帧的过程,从ebp开始,不包括输入实参和返回地址。
前面几句的含义写到了图片上,接下去几句:
movl $0x0,(%esp) 的含义:
在esp指针寄存器指向的位置存入0x0(其实代表的是第一个参数“%d\n”,那为什是0呢,因为要重定位。这条指令就是printf函数的第一个实参,上一条指令就是printf的第二个参数参数i。相当于从右到左压入实参)
(所以printf的两个输入参数就分别存在当前堆栈帧的esp+4 和 esp 中,下面一条语句就是call了再次进入函数调用了,所以这就是之前说的,输入实参是在call之前压入的。)
可以看到.text段(代码段)的offset是0x10的地方正好是指令movl $0x0,(%esp) 中0x0的地址。(上上个图中数数,第16个字节)
需要重定位的符号是.rodata,可以看到.rodata里存的正好就是%d。
【.rodata, .data, .bss应该也是链接的时候重定位,跟普通的符号printf和func1一样,因为链接完了以后这些段的VMA已经确定了,就可以填上正确的值了。这里看的是目标文件.o,还没有重定位过】
call 15<func1+0x15>的含义:
15<func1+0x15>,就是跳转到func1+0x15 这里的的内存的地址进行执行,call指令做了两件事情:
1)把当前指令的下一条指令的地址压入栈中,即函数的返回地址。
2)进入新的函数调用了(新的函数开头都是,重复开头的ebp入栈,ebp=esp等等,像进入func1一样的——进入printf的例行操作)
leave 的含义:(相当于执行了出栈的操作,把栈恢复到函数调用以前的样子)
等价于下面两条指令:
movl %ebp %esp 恢复esp=ebp的值,即此时esp指向的是ebp的位置,就一开始的时候那样。
popl %ebp 从栈中弹出值,其实就是旧的ebp的值,赋值给ebp寄存器,即ebp = 旧ebp。弹出旧ebp以后此时esp指向的就是函数的返回地址那个位置了。对应上面活动记录的图。
ret 的含义:
等效于以下汇编指令:
popl %eip 从栈中取出函数的返回地址,并跳转到该位置执行
这个例子中没有push寄存器的值,退出的时候也就不需要pop回来。
例子2:(VC9,i386,Debug模式)
int foo()
{
return 123;
}
下面是汇编:(第四步,在debug模式下会加入调试信息,把栈空间上的内容都初始化为CC,两个连续排列的CC就是中文“烫”)
例子1是AT&T汇编格式,例子2是Intel汇编格式。
比例子1多了第3,4,6步。
以下的ps可以不用看,跟本章内容无关只是做个记录。
PS1:编译器 生成的函数 的 标准进入和退出指令序列
不知道不懂蓝色划线的原因。
PS2:编译器 实现的hook技术
钩子技术:
下面是可被替换的函数(FUNCTION)的进入指令序列:
nop指令占用一个字节,一共5个字节的nop:
比如一替换函数(REPLACEMENT_FUNCTION)如下:
替换以后如下:
进入到Function以后,先执行了jmp LABEL(这个jump是近跳指令,只占用两个字节,覆盖原来的mov edi,edi)
LABEL下是jmp 到一个新的标签即替换函数(这个jmp占5个字节,,覆盖原来nop的五个字节)
这样就实现了函数的替换了。
说实话,没有很懂,具体实际应用中的流程。
PS3:函数调用之调用惯例
函数声明的时候可以用关键字声明调用惯例,默认是cdecl(C语言中):
可以看到调用惯例规定了 :
出栈方:出栈可以是调用方,也可是函数本身(将函数实参压入栈的肯定是调用方)。上面例子中的leave就是调用方执行的。
参数传递:即调用方将实参压入栈 的 顺序 需要和函数本身 有一致的规定,这样才能取到正确的值。
名字修饰:不同的调用惯例有不同的名字修饰规则,所以,如果不一致的话,就会找不到符号了
不同的编译器对同一种调用惯例的实现也不尽相同,比如gcc和vc对于C++的thiscall(p298)
调用惯例调用方和被调用方不一致的例子:p299 ,要在动态链接中说明如何链接成功,这里先略了。
例子:
main函数:1 2-调用方对函数参数进行压栈,从右到左,4-调用方对函数参数进行出栈。
f函数也是:栈在调用完以后都栈都恢复到原来的调用之前
vs中设置默认调用惯例:
cdecl调用惯例的用途——p337变长参数。
常用的调用约定类型有__cdecl、stdcall、PASCAL、fastcall。除了fastcall可以支持以寄存器的方式来传递函数参数外,其他的都是通过堆栈的方式来传递函数参数的。(这是网上看到的,不是书里面写的)
PS4:函数调用之返回值的传递
上面的——例子2:(VC9,i386,Debug模式)——中可以看到返回值是由寄存器eax来传递的。但是如果返回值大于4个字节,不能存放在eax寄存器中应该怎么办呢——解决办法是:eax指向一个地址,返回值就存放在这个这个地址中。下面是返回是类的例子,其中 big_thing 大小为 128个字节。
typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[0] = 0;
return b;
}
int main() {
big_thing n = return_test();
return 0;
}
main函数的汇编:
int main() {
01041720 push ebp
01041721 mov ebp,esp
01041723 sub esp,258h ---》开辟258h的栈空间
01041729 push ebx
0104172A push esi
0104172B push edi
0104172C lea edi,[ebp-258h]
01041732 mov ecx,96h
01041737 mov eax,0CCCCCCCCh
0104173C rep stos dword ptr es:[edi] ----》把栈空间都初始化为cch,即汉字烫烫烫。。。 96h*4=258h。就是栈空间的大小。
big_thing n = return_test();
0104173E lea eax,[ebp-254h] ---》lea指令看文章汇编指令和寄存器_u012138730的专栏-CSDN博客
01041744 push eax ----》eax值是栈空间的最后一个地址,把eax压入栈,紧接着下面就调用call,说明把这个当作了输入参数 return_test(ebp-254h)
01041745 call return_test (010410E1h)
0104174A add esp,4 --》函数调用方负责把压栈参数还原
0104174D mov ecx,20h
01041752 mov esi,eax
01041754 lea edi,[ebp-1CCh]
0104175A rep movs dword ptr es:[edi],dword ptr [esi] ---》把eax的内容复制到ebp-1CCh中,ebp-1CCh是栈上的一个临时的地址。20h*4=80h 就是正好128字节就是big_thing的大小。rep movs指令汇编指令和寄存器_u012138730的专栏-CSDN博客
0104175C mov ecx,20h
01041761 lea esi,[ebp-1CCh]
01041767 lea edi,[n]
0104176D rep movs dword ptr es:[edi],dword ptr [esi] ---》再把临时的地址的内容复制到真正的n中。
return 0;
0104176F xor eax,eax
}
return_test的汇编
big_thing return_test()
{
01041690 push ebp
01041691 mov ebp,esp
01041693 sub esp,148h ---》开辟148h的栈空间
01041699 push ebx
0104169A push esi
0104169B push edi
0104169C lea edi,[ebp-148h]
010416A2 mov ecx,52h
010416A7 mov eax,0CCCCCCCCh
010416AC rep stos dword ptr es:[edi] ---》初始化148h的栈空间 rep stos 指令见文章 汇编指令和寄存器_u012138730的专栏-CSDN博客
big_thing b;
b.buf[0] = 0;
010416AE mov eax,1
010416B3 imul ecx,eax,0
010416B6 mov byte ptr b[ecx],0 ---》假汇编 b其实是栈空间的一个地址
return b;
010416BE mov ecx,20h
010416C3 lea esi,[b]
010416C9 mov edi,dword ptr [ebp+8] ---》ebp+8就是之前main函数调用return_test时,压入了一个作为隐形参数出入到return_test中的,在main函数的栈的地址。 (数据应该是存入 [旧的ebp-254h]的内存地址中了 )
010416CC rep movs dword ptr es:[edi],dword ptr [esi] ---》把b的内容复制到ebp+8中。
010416CE mov eax,dword ptr [ebp+8] ---》把epb+8中存的地址复制给eax,也就是main函数的中的栈空间的某个地址,也就是返回值。
}
但是如果return_test返回类型太大,main中的栈空间也无法满足要求,那么就是会使用一个临时的栈上的内存作为中转,返回值对象就会被拷贝2次。
即如果是函数的返回值大于4字节,调用的时候相当于多传入一个输入参数——一个指针,函数里面的返回值指向传入的这个指针。这个指针赋值给eax。返回以后,调用方通过这个指针获取到真正的返回值来进行使用。
PS5:函数调用之C++对象
#include <iostream>
using namespace std;
struct cpp_obj
{
cpp_obj()
{
cout << "ctor\n";
}
~cpp_obj()
{
cout << "dtor\n";
}
cpp_obj(const cpp_obj& )
{
cout << "copy ctor\n";
}
cpp_obj& operator=(const cpp_obj& rhs)
{
cout << "operator=\n";
return *this;
}
};
cpp_obj return_test()
{
cpp_obj b;
cout << "before return\n";
return b;
}
int main() {
cpp_obj n = return_test();
return 0;
}
输出:(断点下在main中的return那里,并且不启用任何优化)
把函数return_test()换成(用了返回值优化技术:Return Value Optimization RVO优化,将对象的拷贝减少一次):
cpp_obj return_test()
{
return cpp_obj();
}
输出:
总结:如果是c++对象的话,有临时对象需要调用构造和析构函数。
函数传递大尺寸的返回值,在不同编译器 ,不同平台,不同的编译参数,下都不相同,上述是win10,vs2015下的输出。
堆空间(heap)——动态申请内存:
堆占据虚拟内存空间的绝大部分,在程序运行过程中进行动态的申请,在主动放弃申请的空间之前一直有效。(栈上的数据出了函数就无效了,全局变量要在编译期间就定义好)
linux系统下堆分配,两个系统调用(就是操作系统,提供的api的调用):
1)brk——扩大或缩小数据段(data段和bss段的合称)
int brk(void* end_data_segment);
2)mmap——申请虚拟地址空间,可以申请的虚拟内存空间将映射到文件,也可以不映射到文件(不映射到文件的叫匿名空间)
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
windows系统下堆分配,的系统调用:
VirtualAlloc——空间大小必须是页的整数倍,x86系统必须是4096字节
LPVOID VirtualAlloc{
LPVOID lpAddress, // 要分配的内存区域的地址
DWORD dwSize, // 分配的大小
DWORD flAllocationType, // 分配的类型
DWORD flProtect // 该内存的初始保护属性
};
运行时库的malloc函数:
第一次先通过系统调用(申请虚拟地址空间:linux调用mmap申请,windows调用VirtualAlloc申请)申请一块大的虚拟地址空间,再在这个虚拟地址空间中根据空闲进行分配。
分配算法有:空闲链表法,位图法,对象池法
glibc的malloc:
小于64字节,采用类似于对象池的方法;
大于64,小于512字节,采用上述方法中的最佳折中策略;
大于512字节,采用最近适配算法;
大于128kb的申请,直接用mmap向操作系统申请内存。
msvc的入口函数使用了alloca(链接到入口函数的实现)
因为一开始的时候堆还没有初始化,
alloca是唯一可以不使用堆的动态分配机制,
是在栈上分配任意空间,在函数返回时候释放,跟局部变量一样。
(那跟定义局部变量有什么区别?)
5.虚拟地址和物理地址的映射
一个程序要想执行(指令被cpu执行,cpu访问内存),光有虚拟内存是不行的,必须运行在真实的内存上,所以必须在虚拟地址与物理地址间建立一种映射关系。
虚拟地址与物理地址间的映射关系由操作系统建立,当程序访问虚拟地址空间上的某个地址值时,就相当于访问了物理地址空间中的另一个值。
这种映射机制需要硬件的支持——cpu中的内存管理单元。cpu拿到一个需要虚拟地址(virtual address,VA),经过内存管理单元(Memory Management Unit, MMU)利用存放在物理内存中的映射表(页表,由操作系统管理该表的内容)动态翻译,转换成物理内存地址,进而访问物理内存。这也叫做cpu虚拟寻址方式。【对比文章开头说的,在早期的计算机中,程序都是直接运行在物理内存上的,运行时访问的地址都是物理地址】
整个的映射过程是由软件(操作系统)来设置,而实际的地址转换是由硬件(MMU)来完成。
应用程序和许多系统进程都是使用虚拟寻址。
只有操作系统内核的核心部分会使用cpu物理寻址,即地址翻译,直接使用实际的物理内存地址。
虚拟寻址中的具体的映射方案后面介绍。段机制(段描述符)和页机制(内存分页)_u012138730的专栏-CSDN博客
6.物理内存和硬盘之间的置换
当物理内存RAM不够使用的时候,操作系统会根据一些置换算法将物理内存中的数据置换到磁盘上的交换空间(swap),腾出空闲的物理内存页来存储需要在内存中运行的程序和相关数据。
前面文章说到任务管理器中的提交大小包含两部分,一部分是独占的物理内存(即专用工作集内存),另一部分是在分页文件中的独占内存映射。后者分页文件即是这里说的交换空间。
windows下分页文件叫,pagefile.sys,一般在硬盘的操作系统所在的分区中。
那么如何设置可以写入硬盘的内存大小呢——我的电脑 右键 选择【属性】,左侧栏里选择【高级系统设置】,然后点击如下图所示:正如解释的是,操作系统把这个分页文件当作RAM使用,即硬盘中的虚拟内存的概念。(70526/1024=68G)
ps: windows下有两种虚拟内存文件:
1)专用的页面文件,位于磁盘根目录,即上面说的pagefile.sys 。
2)使用文件映射机制加载过的磁盘文件,比如加载了的dll和exe,即成了映像文件(虚拟内存的映像文件)。一旦被加载到内存中,该文件就不能删除了(这是内存管理器和文件系统之间的重要约定)。所以很多有时候删除不了某文件,一般都是正在用着呢。
7.虚拟内存的重要性
1.每个进程使用的是一个一致的地址空间(从0到2^32-1),降低了程序员对内存管理的复杂性。让操作系统来完成虚拟地址空间到物理地址空间的转换。(对于程序来说,不需要关心物理地址的变化,最后被分配到哪对程序来说是透明的)
2.每个进程有自己独立的虚拟地址空间,只能访问自己的地址空间,有效地做到进程之间的隔离,保证进程的地址空间不会被其他进程破坏。(从进程角度来看,独占cpu,独占内存有单一的地址空间。)
3.提高物理内存的利用率。
8.进程的虚存空间分布——装载(程序员的自我修养-链接装载库 第6.4节)
在进程创建的时候操作系统会根据可执行文件的头部信息(记录着这个可执行文件有哪些段)将可执行文件中的段和虚拟空间之间进行映射,这个过程就是装载最重要的一步。
可执行文件从链接角度看,是按Section分段的,一般都有十几个Section,二十几个,三十几个——链接视图。
可执行文件从装载角度看,是按Segment分段的,一般就是五六七八个——执行视图。
我们可以用readelf命令看同一个执行文件(elf格式的)的两个视图:
readelf -S 命令看链接视图(也就是看段表的命令)
readelf -l 命令看执行视图
下面的例子不是书中的,是我自己电脑上之前编的一个可执行程序,angular的。然后是64位的不是32位的,书本中的例子是32位的。所以我这边看地址都是8个字节的。
readelf -S链接视图——25个section头
执行视图:7个program头——程序头表记录着程序头
程序头的类Elf32_Phdr,其数据成员对应下面打印出来的8列:(ELF的目标文件不需要被装载,所以他没有程序头表,而ELF的可执行文件和共享库文件(linux下的so文件)都有。)
只有LOAD类型的Segment是真正需要被映射到虚拟空间的。其他类型的都是在装载的时候起到辅助作用。
可以看到LOAD类型的Segment是按权限划分的:
RE的代码段
R的只读数据段
RE的数据段和BSS段(因为有BSS段,所以FileSiz 和 MemSiz不一样的大小)
可以看到其实权限相同的Section在可执行文件中的位置都是放在一起的。
对于权限相同的Section把他们的合并到一起称为一个Segment进行映射,因为从装载的角度看操作系统不关心各个段的实际内容,最关心的是权限。
ELF可执行文件被映射到虚拟空间的时候,是以系统的页长度(4K)为单位的,所以每个段在映射到虚拟空间的时候都会按页的整数倍的,多余部分占一个页。按Segment作为段进行映射明显(比按section进行映射)减少了内存的浪费。
VMA
Linux中将进程虚拟空间中的一个段叫做虚拟内存区域VMA,windows叫虚拟段VirtualSection。
上述例子中,可执行文件映射到虚拟空间的就有三个VMA。除了有实际文件映射的VMA,还有匿名虚拟空间区域AVMA。
使用命令行看进程的虚拟空间的分布情况,就看上面例子中的main(9个VMA):
第1列:VMA的地址范围 。这个例子中跟执行视图中的Virtual地址范围一样,有的例子会略有不同(6.4.4节中的段地址对齐)。
第2列:VMA的权限 最后一个p是私有,s是共享。
第3列:VMA中的Segment在映像文件中偏移。(详情看6.4.4节中描述道,VMA中的Segment和可执行文件中的Segment其实不是完全对应的)
第4列:映像文件所在设备的主设备号:次设备号
第5列:映像文件的节点号
第6列:映像文件的路径
可以看到除了前3个的 最后几列都是没有的,说明最后的都是没有映射到文件中,这种VMA也叫做匿名虚拟内存区域AVMA。(怎么没有 [heap])
Stack VMA[stack]
操作系统在进程启动前将系统环境变量和进程的运行参数提前保存到虚拟空间的栈中。
我们熟知的main()函数中的argc和argv就是从这里获取的。
动态链接时的进程堆栈初始化信息
详情看动态联接 可执行文件的装载,进程和线程,运行时库的入口函数(第六章)_u012138730的专栏-CSDN博客_运行时动态装载链接至少需要用到以下哪些函数 C/C++的编译和链接过程_u012138730的专栏-CSDN博客
进程堆栈初始化信息中包含了动态链接器所需要的一些信息:
可执行文件的段(程序头表),
可执行文件的入口地址等等。
这些辅助信息位于环境指针变量的后面,用一个辅助信息数组表示。
辅助信息结构:
辅助信息结构中的类型和值含义:
写一个小程序打印出这些数据:
9.windows打开任务管理器
内存项含义
打开任务管理--详细信息---右键 选择列,选择下面这4个。
1.工作集(内存)Working Set = 内存(专用工作集)+ 内存(共享工作集)【第2列=第3列+第4列】
工作集(内存)——进程当前正在使用的物理内存量——表示进程此时所占用的总物理内存(即占用RAM内存)。
这个值是由两部分组成专用工作集 和 共享工作集:
专用工作集内存——由该进程正在使用,而其他进程无法使用的物理内存量——是此进程独占的物理内存
共享工作集内存——由该进程正在使用,且可与其他进程共享的物理内存量——是指这个进程与其它进程共享的物理内存,比如加载了某一个dll所占用的内存。
2.提交大小 Comitted Memory——进程独占的内存
提交大小是操作系统为该进程保留的虚拟内存量。
Committed Memory is the number of bytes that have been allocated by processes, and to which the operating system has committed a RAM page frame or a page slot in the page file (or both).
Windows allocates memory for processes in two stages. In the first stage, a series of memory addresses is reserved for a process. The process may reserve more memory than it actually needs or uses at one time, just to maintain ownership of a contiguous block of addresses. At any one time, the reserved memory addresses do not necessarily represent real space in either the physical memory (RAM) or on disk. In fact, a process can reserve more memory than is available on the system.
Before a memory address can be used by a process, the address must have a corresponding data storage location in actual memory (RAM or disk). Commit memory is memory that has been associated with a reserved address, and is therefore generally unavailable to other processes. Because it may be either in RAM or on disk (in the swap file), committed memory can exceed the RAM that is installed on the system
是进程独占的内存。这个值也是包含两部分,一部分是独占的物理内存(即专用工作集内存),另一部分是在分页文件中的独占内存映射。分页文件是硬盘中的虚拟内存,当RAM物理内存资源紧张,或者有数据长时间未使用时,操作系统通常会将数据占用的物理内存先映射到页面文件(pagefile.sys)中,并拷贝数据到硬盘中,然后将本来占用的RAM空间释放。这个也就是虚拟内存技术。
下面是一个Windows API,功能是向操作系统发送请求, 将此进程的不常用的内容从物理内存中换出到分页文件中保存
EmptyWorkingSet
提交大小这部分内存在虚拟内存的线性地址中是连续的,不过在物理内存或者分页内存中,不一定是连续的。提交但未使用的内存一般都在分页内存里面,只有去使用的时候,才会换到物理内存里面。
提交大小 大于 专用工作集
3.PROCESS_MEMORY_COUNTERS 类 和 GetProcessMemoryInfo 函数
MEMORYSTATUSEX 类 和 GlobalMemoryStatusEx 函数 可以获得还可用的虚拟内存。
PROCESS_MEMORY_COUNTERS 类 和 GetProcessMemoryInfo 函数可以获得当前进程使用的内容,如下:
MEMORYSTATUSEX MemoryInfo;
memset( &MemoryInfo,0,sizeof(MEMORYSTATUSEX) );
MemoryInfo.dwLength = sizeof(MEMORYSTATUSEX);
GlobalMemoryStatusEx( &MemoryInfo );
PROCESS_MEMORY_COUNTERS pmc;
UINT uMemSwapUsed = 0;
UINT uMemPhyUsed =0;
if ( GetProcessMemoryInfo( GetCurrentProcess(), &pmc, sizeof(pmc)) )
{
uMemSwapUsed = pmc.PagefileUsage/1024/1024; // 即提交大小,进程独占内存(物理+交换)
uMemPhyUsed = pmc.WorkingSetSize/1024/1024; // 即工作集WorkingSet的大小,总占的物理内存(独占+共享)
}
CString szInfo;
szInfo.Format( "%s SVM:%u PM:%u AVM:%llu",GetTitle(),
uMemSwapUsed,
uMemPhyUsed,
MemoryInfo.ullAvailVirtual/1024/1024
);
SetConsoleTitle( szInfo );
2 其他项目含义
cpu时间是cpu在这个进程用的总时间。
当系统没有任务执行是,cpu就会执行空闲进程。空闲进程的pid总是0,他的线程数就是系统中总的cpu数目。他的运行时间cpu时间占用了绝大部分的时间。如果一个进程占用了小时以上,就算是重度的进程了。
cpu这一列指的是1s的cpu占用百分比。如果这一列的某个进程一直同一个值,可能某个线程陷入了死循环。
磁盘有关的问题:
IO读取和IO写入 次数
IO读取字节和IO写入字节 字节数
分析内存问题:
上文
其他观察进程的exe
比如process explorer
[转载]windows任务管理器中的工作设置内存,内存专用工作集,提交大小详解
10.硬件概念--存储器芯片。
存储器芯片从读写属性分类可以分为:
1)RAM 随机存储器(可读可写),必须带电存储。
A》主随机存储器(主存)
装在主板上的RAM(主板上插槽,组装电脑的时候)
装在扩展插槽上的RAM(可以扩展到多少内存,自己买内存条)
B》接口卡上的RAM
接口卡(cpu通过地址总线与扩展插槽上的接口卡相连,从而与对应外设相通信)有的需要对大批量的输入输出数据进行暂存,其上需要装RAM,最典型的为显示器的接口卡,显卡,上的RAM,称之为显存。
2)ROM 只读存储器,关机后其内容不丢失。
存储BIOS的ROM。BIOS是软件系统,由主板和各类接口卡厂商提供。通过BIOS,对对应硬件设备进行最基本的输入输出。
主板上的ROM存储系统的BIOS
显卡上的ROM存储显卡的BIOS
网卡上的ROM存储网卡的BIOS
划重点:内存中存储数据和指令用于与cpu沟通。内存是仅次于cpu的部件,性能再好的cpu,没有内存也不能工作。就像再聪明的大脑,没有了记忆也无法进行思考(摘自《汇编语言》)。
那存储器是怎么存储的呢?存储器的容量怎么表示的呢?
存储器被划分为多个存储单元,并从零开始编号。比如一个存储器有128个存储单元,编号即为0~127。
为什么要编号呢,因为编号了就相当于有地址了,cpu可以进行寻址了(通过与之相连的地址总线)。
微型机一个存储单元存1个字节(8bit,8个二进制位),所以,存储器的容量就可以表示了,128个存储单元即128字节容量。
cpu将系统中各类存储器看作一个逻辑存储器。
内存地址空间的概念。内存地址空间总是大于物理内存(物理存储器,真正的存储器芯片所提供的存储单元)的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)