一、Tesseract简介
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,github地址为:https://github.com/tesseract-ocr/
二、Tesseract源码下载
1、下载tesseract-ocr-setup-3.02.02.exe
下载地址:https://sourceforge.net/projects/tesseract-ocr-alt/files/ , 点击 “tesseract-ocr-setup-3.02.02.exe” 进行下载。
下载后,双击tesseract-ocr-setup-3.02.02.exe,进行安装。
按照操作提示,点击next。
注意,在选择组件页面,勾选 Tesseract development files。 如图:
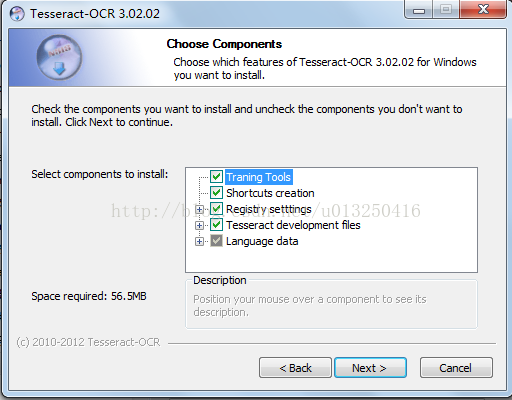
安装完成后,选择的安装目录下(D:\Program Files (x86)\Tesseract-OCR),文件夹如下:

但是,下载下来的源码是不够的。还需要下载附加lib。
2、下载tesseract-3.02.02-win32-lib-include-dirs.zip
下载地址:https://sourceforge.net/projects/tesseract-ocr-alt/files/ ,选择“tesseract-3.02.02-win32-lib-include-dirs.zip” 进行下载。
下载得到压缩包后,解压缩,目录如下:

其中,include目录中包含如下:

lib目录中包含如下:

将include 文件夹中的内容复制到 D:\Program Files (x86)\Tesseract-OCR\include 文件夹中,将lib 文件夹中的内容复制到 D:\Program Files (x86)\Tesseract-OCR\lib 文件夹中。
3、下载 tesseract_versionnumbers.props 和 leptonica_versionnumbers.props
下载地址为:https://github.com/jakesays/tesseract-vs2012/tree/master/include,将项目中包含的 tesseract_versionnumbers.props 和 leptonica_versionnumbers.props 复制到D:\Program Files (x86)\Tesseract-OCR\include 文件夹中。
至此,我们需要的资源就准备齐全了。
备注:我之前也是走了一些弯路,这是总结出来的完整资源的获得方式。以上所需要的资源的必要性,在后面Tesseract 与 VS2012 相结合的时候会提到。
三、Tesseract 在 Visual Studio 2012 中的配置
1、新建win32控制台项目
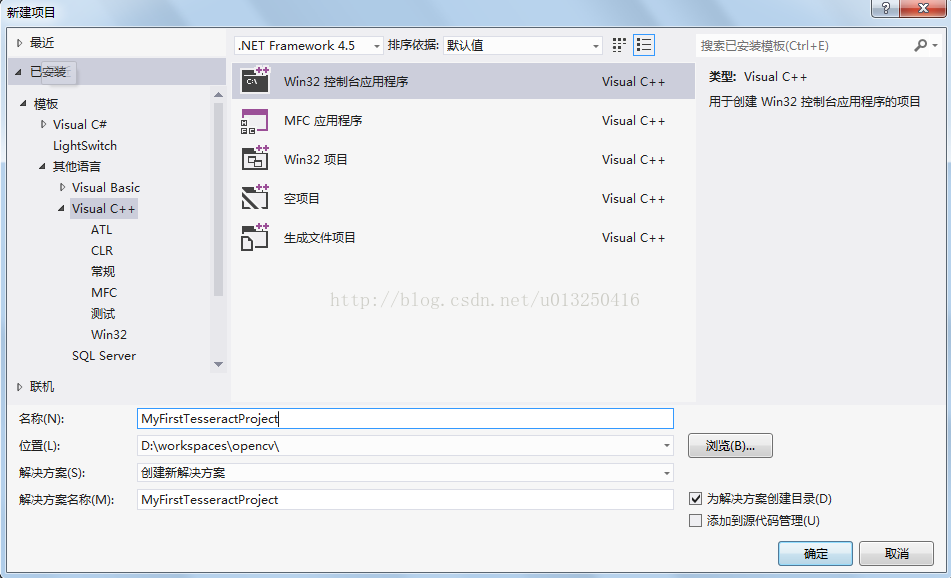
注意在附加选项中,勾选“空项目”。

2、引入头文件
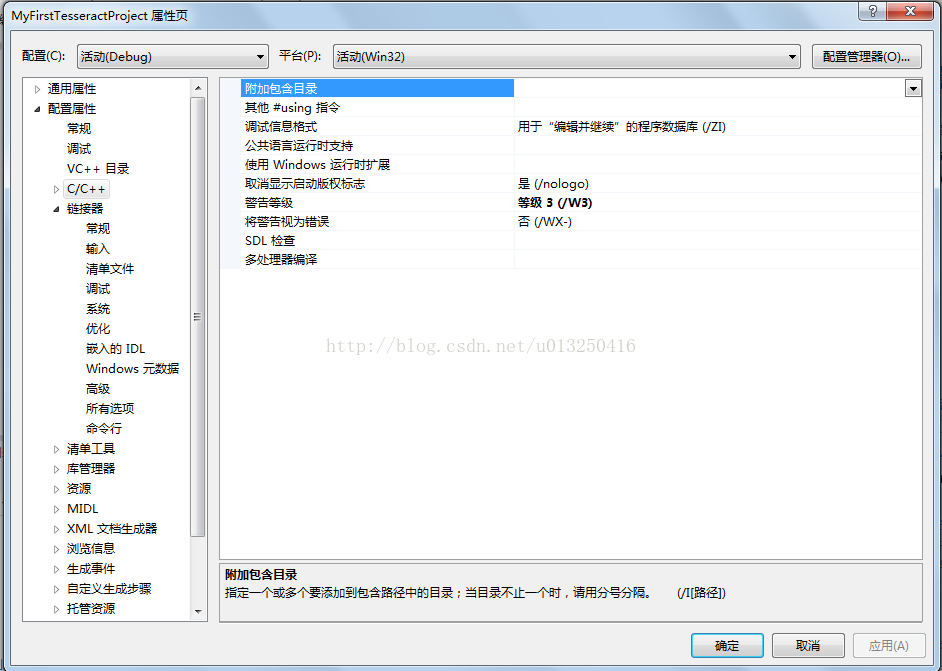
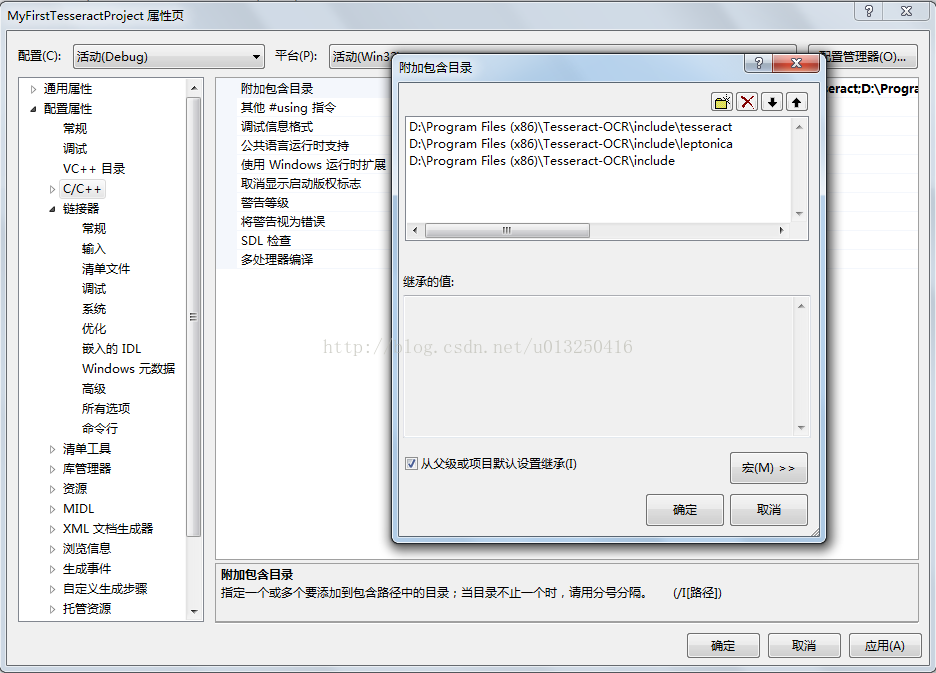
在“解决方案资源管理器” 窗口,右键 “MyFirstTesseractProject”工程 -> “属性(R)” ->“C/C++”->“常规”->“附加包含目录”中,添加如下内容:
D:\Program Files (x86)\Tesseract-OCR\include
D:\Program Files (x86)\Tesseract-OCR\include\leptonica
D:\Program Files (x86)\Tesseract-OCR\include\tesseract
如图所示:
3、引入库文件
1)添加属性表
首先将“D:\Program Files (x86)\Tesseract-OCR\include”目录 拷贝到 本地工程“MyFirstTesseractProject\MyFirstTesseractProject”目录下,如图所示:

然后进行以下设置:
在“解决方案管理器”所在区域,切换到“属性管理器”窗口;
右键“MyFirstTesseractProject”工程下面的“Debug|Win32”文件夹 –>“添加现有属性表(E)…”–>在“MyFirstTesseractProject\MyFirstTesseractProject\include”目录下找到“tesseract_versionnumbers.props”–>“打开”;
如图所示:
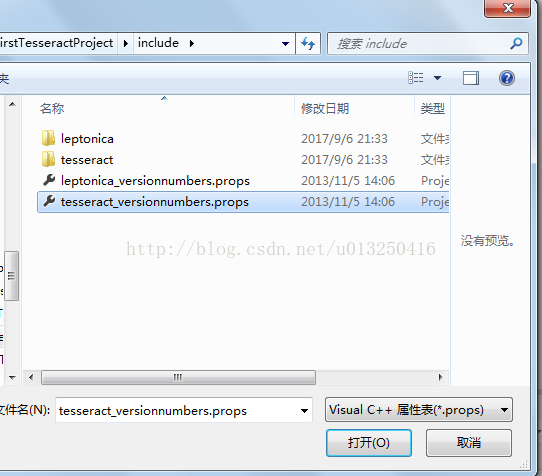
添加后如图所示:
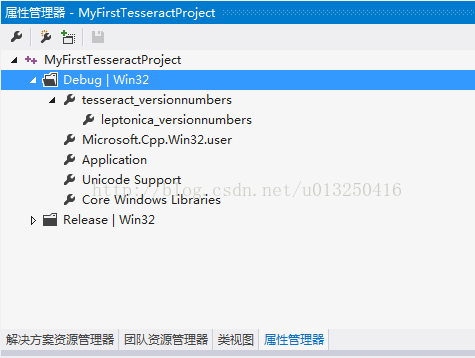
2)配置库文件
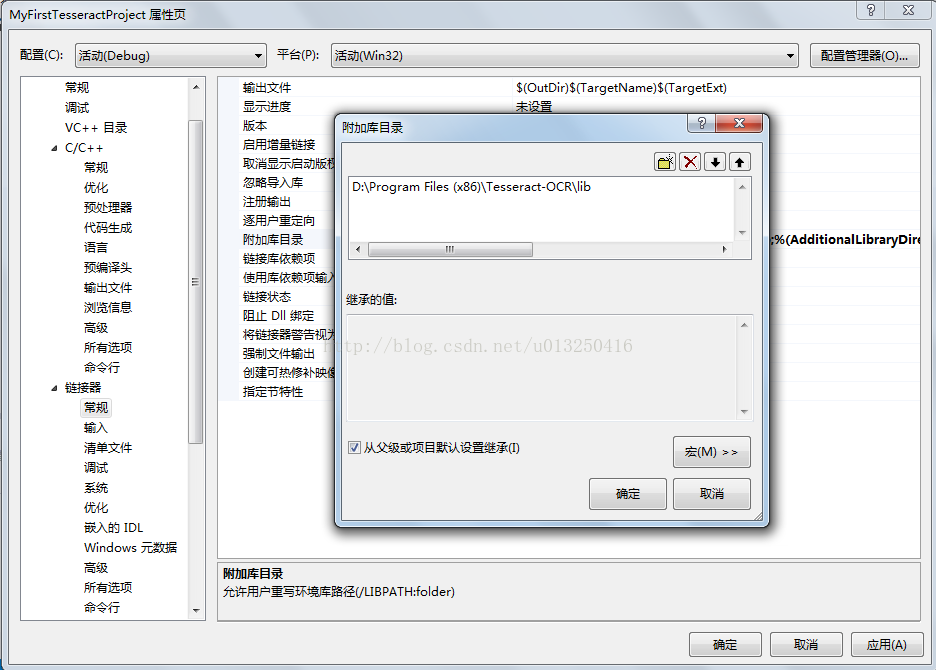
在“解决方案管理器”窗口–>右键“MyFirstTesseractProject”工程–>“属性(R)”–>“配置属性”–>“链接器”–>“常规”–>“附加库目录”中添加如下内容:
D:\Program Files (x86)\Tesseract-OCR\lib
如图所示:

4、添加预定义
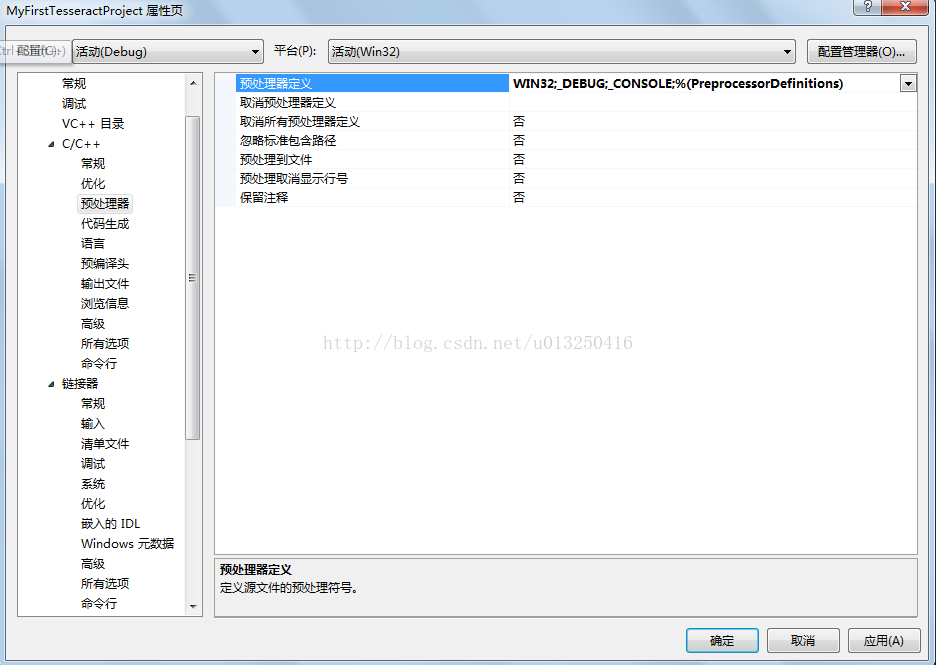
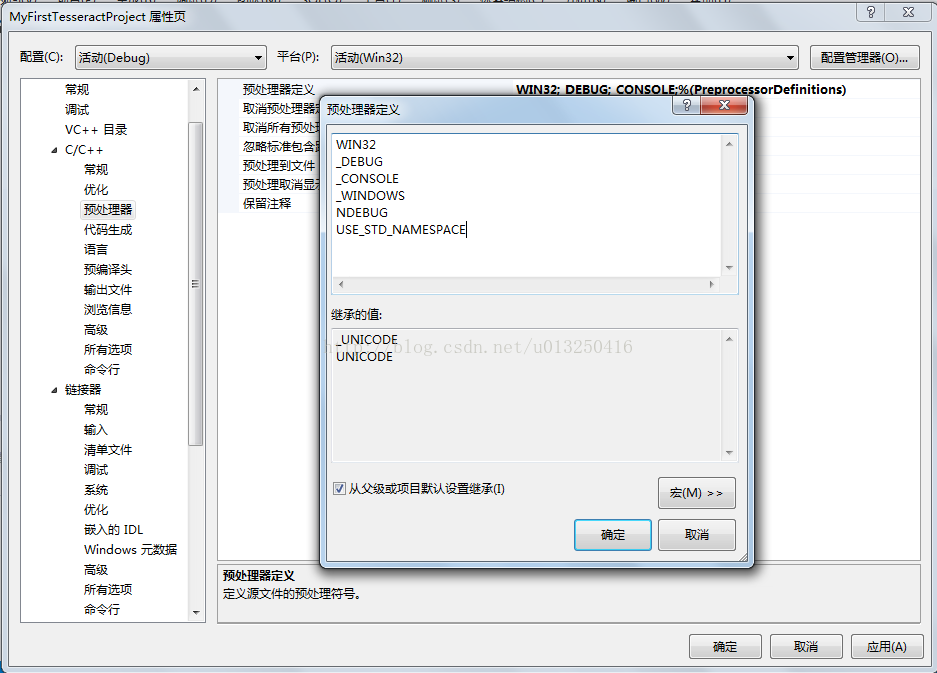
在“解决方案管理器”窗口–>右键“MyFirstTesseractProject”工程–>“属性(R)”–>“配置属性”–>“C/C++”–>“预处理器”–>“预处理器定义”–>中添加”如下列表中的“预定义”内容:
_WINDOWS
NDEBUG
USE_STD_NAMESPACE
如下图:
5、添加附加库
在“解决方案管理器”窗口–>右键“MyFirstTesseractProject”工程–>“属性(R)”–>“配置属性”–>“链接器”–>“输入”–>“附加依赖项”–>中“添加”如下列表中的“附加库”内容:
libtesseract302.lib
libtesseract302d.lib
liblept168.lib
liblept168d.lib
如图所示:


6、其他添加
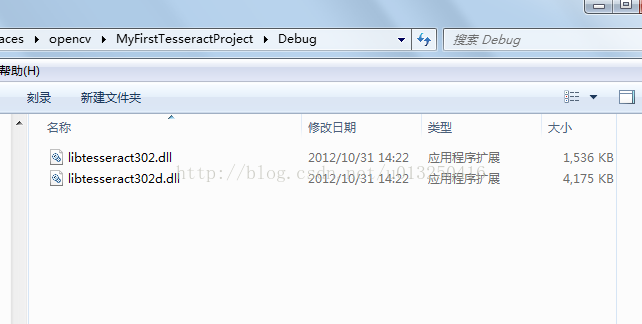
在“MyFirstTesseractProject” 目录下新建 “Debug”文件夹,将“libtesseract302.dll” 和 “libtesseract302d.dll” 拷贝到 “Debug” 文件夹下面。如图所示:

三、运行Tesseract实例
#include <baseapi.h>
#include <allheaders.h>
#include <iostream>
using namespace std;
int main(void)
{
tesseract::TessBaseAPI api;
api.Init("", "eng", tesseract::OEM_DEFAULT);
api.SetPageSegMode(static_cast<tesseract::PageSegMode>(7));
api.SetOutputName("out");
cout<<"File name:";
char image[256];
cin>>image;
PIX *pixs = pixRead(image);
STRING text_out;
api.ProcessPages(image, NULL, 0, &text_out);
cout<<text_out.string();
system("pause");
}
运行成功,运行结果如下:
给定测试图片,如图:
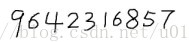
输入图片路径,得到结果:
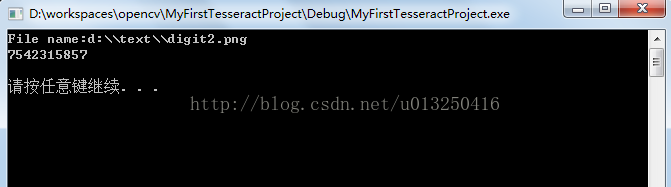
正确率有待提高。
四、总结
至此,成功在VS2012中配置了Tesseract。网上的资料比较少,下载下来的库并不完整,经过实践,总结出了在我这里可行的一套办法。我的系统是win7,64位。
同时,在实验的过程中,参考了以下博文。我觉得最大的收获是,在遇到博文上说的办法不可行的时候,根据实际情况作出了调整,并且成功跑通。
感谢:
【Tesseract】Tesseract API在VS 2013中的配置以及调用
Tutorial: How to Install Tesseract OCR 3.02.02 for Visual Studios 2008 on Windows Vista
---------------------
原文:https://blog.csdn.net/u013250416/article/details/77871203
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)