最近在学习怎么分布式Tensorflow训练深度学习模型,看官网教程看的云里雾里,最终结合着其它资料,终于对分布式Tensorflow有了些初步了解.
gRPC (google remote procedure call)
分布式Tensorflow底层的通信是gRPC
gRPC首先是一个RPC,即远程过程调用,通俗的解释是:假设你在本机上执行一段代码num=add(a,b),它调用了一个过程 call,然后返回了一个值num,你感觉这段代码只是在本机上执行的, 但实际情况是,本机上的add方法是将参数打包发送给服务器,然后服务器运行服务器端的add方法,返回的结果再将数据打包返回给客户端.
Cluster.Job.Task
Job是Task的集合.
Cluster是Job的集合
为什么要分成Cluster,Job,和Task呢?
首先,我们介绍一下Task:Task就是主机上的一个进程,在大多数情况下,一个机器上只运行一个Task.
为什么Job是Task的集合呢? 在分布式深度学习框架中,我们一般把Job划分为Parameter和Worker,Parameter Job是管理参数的存储和更新工作.Worker Job是来运行ops.如果参数的数量太大,一台机器处理不了,这就要需要多个Tasks.
Cluster 是 Jobs 的集合: Cluster(集群),就是我们用的集群系统了
如何创建集群
从上面的描述我们可以知道,组成Cluster的基本单位是Task(动态上理解,主机上的一个进程,从静态的角度理解,Task就是我们写的代码).我们只需编写Task代码,然后将代码运行在不同的主机上,这样就构成了Cluster(集群)
如何编写Task代码
首先,Task需要知道集群上都有哪些主机,以及它们都监听什么端口.tf.train.ClusterSpec()就是用来描述这个.
tf.train.ClusterSpec({
"worker": [
"worker_task0.example.com:2222",
"worker_task1.example.com:2222",
"worker_task2.example.com:2222"
],
"ps": [
"ps_task0.example.com:2222",
"ps_task1.example.com:2222"
]})
这个ClusterSec告诉我们,我们这个Cluster(集群)有两个Job(worker.ps),worker中有三个Task(即,有三个Task执行Tensorflow op操作)
然后,将ClusterSpec当作参数传入到 tf.train.Server()中,同时指定此Task的Job_name和task_index.
server = tf.train.Server(cluster, job_name=jobName, task_index=taskIndex)
下面代码描述的是,一个cluster中有一个Job,叫做(worker), 这个job有两个task,这两个task是运行在两个主机上的
cluster = tf.train.ClusterSpec({"worker": ["10.1.1.1:2222", "10.1.1.2:3333"]})
server = tf.train.Server(cluster, job_name="local", task_index=0)
cluster = tf.train.ClusterSpec({"worker": ["10.1.1.1:2222", "10.1.1.2:3333"]})
server = tf.train.Server(cluster, job_name="local", task_index=1)
tf.trian.Server干了些什么呢?
首先,一个tf.train.Server包含了: 本地设备(GPUs,CPUs)的集合,可以连接到到其它task的ip:port(存储在cluster中), 还有一个session target用来执行分布操作.还有最重要的一点就是,它创建了一个服务器,监听port端口,如果有数据传过来,他就会在本地执行(启动session target,调用本地设备执行运算),然后结果返回给调用者.
我们继续来写我们的task代码:在你的model中指定分布式设备
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
with tf.device("/job:ps/task:1"):
weights_2 = tf.Variable(...)
biases_2 = tf.Variable(...)
with tf.device("/job:worker/task:0"):
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
with tf.device("/job:worker/task:1"):
input, labels = ...
layer_1 = tf.nn.relu(tf.matmul(input, weights_1) + biases_1)
logits = tf.nn.relu(tf.matmul(layer_1, weights_2) + biases_2)
train_op = ...
with tf.Session("grpc://10.1.1.2:3333") as sess:
for _ in range(10000):
sess.run(train_op)
with tf.Session("grpc://..")是指定gprc://..为master,master将op分发给对应的task
写分布式程序时,我们需要关注一下问题:
(1) 使用In-graph replication还是Between-graph replication
In-graph replication:一个client(显示调用tf::Session的进程),将里面的参数和ops指定给对应的job去完成.数据分发只由一个client完成.
Between-graph replication:下面的代码就是这种形式,有很多独立的client,各个client构建了相同的graph(包含参数,通过使用tf.train.replica_device_setter,将这些参数映射到ps_server上.)
(2)同步训练,还是异步训练
Synchronous training:在这种方式中,每个graph的副本读取相同的parameter的值,并行的计算gradients,然后将所有计算完的gradients放在一起处理.Tensorlfow提供了函数(tf.train.SyncReplicasOptimizer)来处理这个问题(在Between-graph replication情况下),在In-graph replication将所有的gradients平均就可以了
Asynchronous training:自己计算完gradient就去更新paramenter,不同replica之间不会去协调进度
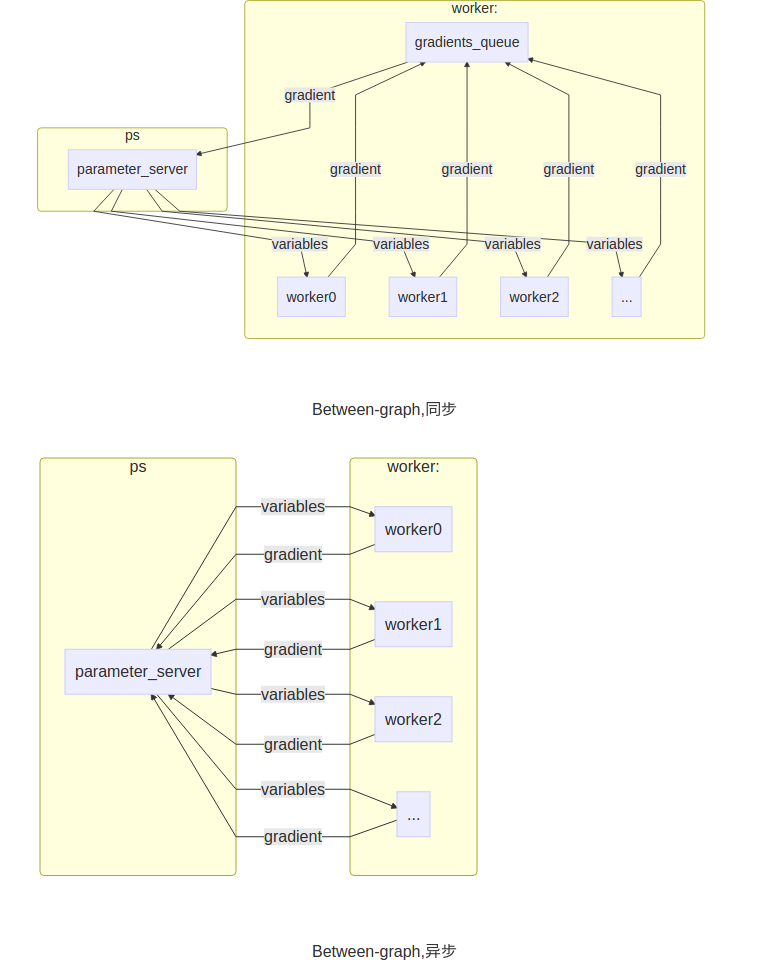
(3)
一个完整的例子,来自官网链接:
import tensorflow as tf
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
由于是相同的代码运行在不同的主机上,所以要传入job_name和task_index加以区分,而ps_hosts和worker_hosts对于所有主机来说,都是一样的,用来描述集群的
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
if FLAGS.job_name == "ps":
server.join()
我们都知道,服务器进程如果执行完的话,服务器就会关闭.为了是我们的ps_server能够一直处于监听状态,我们需要使用server.join().这时,进程就会block在这里.至于为什么ps_server刚创建就join呢:原因是因为下面的代码会将参数指定给ps_server保管,所以ps_server静静的监听就好了.
elif FLAGS.job_name == "worker":
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
tf.train.replica_device_setter(ps_tasks=0, ps_device='/job:ps', worker_device='/job:worker', merge_devices=True, cluster=None, ps_ops=None)),返回值可以被tf.device使用,指明下面代码中variable和ops放置的设备.
example:
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
with tf.device(tf.replica_device_setter(cluster=cluster_spec)):
v1 = tf.Variable(...)
v2 = tf.Variable(...)
v3 = tf.Variable(...)
这个例子是没有指定参数worker_device和ps_device的,你可以手动指定
继续代码注释,下面就是,模型的定义了
loss = ...
global_step = tf.Variable(0)
train_op = tf.train.AdagradOptimizer(0.01).minimize(
loss, global_step=global_step)
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
logdir="/tmp/train_logs",
init_op=init_op,
summary_op=summary_op,
saver=saver,
global_step=global_step,
save_model_secs=600)
with sv.managed_session(server.target) as sess:
step = 0
while not sv.should_stop() and step < 1000000:
_, step = sess.run([train_op, global_step])
sv.stop()
考虑一个场景(Between-graph),我们有一个parameter server(存放着参数的副本),有好几个worker server(分别保存着相同的graph的副本).更通俗的说,我们有10台电脑,其中一台作为parameter server,其余九台作为worker server.因为同一个程序在10台电脑上同时运行(不同电脑,job_name,task_index不同),所以每个worker server上都有我们建立的graph的副本(replica).这时我们可以使用Supervisor帮助我们管理各个process.Supervisor的is_chief参数很重要,它指明用哪个task进行参数的初始化工作.sv.managed_session(server.target)创建一个被sv管理的session
if __name__ == "__main__":
tf.app.run()
To start the trainer with two parameter servers and two workers, use the following command line (assuming the script is called trainer.py):
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=0
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=ps --task_index=1
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=0
$ python trainer.py \
--ps_hosts=ps0.example.com:2222,ps1.example.com:2222 \
--worker_hosts=worker0.example.com:2222,worker1.example.com:2222 \
--job_name=worker --task_index=1
可以看出,我们只需要写一个程序,在不同的主机上,传入不同的参数使其运行
参考博客:
[1] http://weibo.com/ttarticle/p/show?id=2309403987407065210809
[2] http://weibo.com/ttarticle/p/show?id=2309403988813608274928
[3] http://blog.csdn.net/luodongri/article/details/52596780
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)