PyTorch学习(6):优化算法
- Pytorch官方文档: https://pytorch-cn.readthedocs.io/zh/latest/
- Pytorch学习文档: https://github.com/tensor-yu/PyTorch_Tutorial
- 参考: https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-optim/#optimizer
https://zhuanlan.zhihu.com/p/87209990?from_voters_page=true
文章目录
- PyTorch学习(6):优化算法
- 1.优化算法概述
-
- 2.优化算法Torch.optim
- 3.优化器基类 Optimizer
- 1)zero_grad()
- 2)step(closure)
- 3)state_dict()
- 4)load_state_dict(state_dict)
- 5)add_param_group()
- 4.PyTorch优化器
- 1)torch.optim.SGD
- 2)torch.optim.RMSprop
- 3)torch.optim.Adam
- 4)其他优化器
- 总结
1.优化算法概述
在机器学习或者深度学习中,模型需要通过修改参数使得损失函数最小化(或最大化),优化算法就是一种调整模型参数更新的策略。
优化算法分为两大类。
1)一阶优化算法
这种算法使用各个参数的梯度值来更新参数,最常见的一阶优化算法是梯度下降。梯度下降的功能是通过寻找最小值,控制方差,更新模型参数,最终使模型收敛,网络的参数更新公式为:
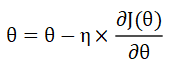
其中
η
\eta
η是学习率,
∂
J
(
θ
)
∂
θ
\frac{\partial J( \theta )}{\partial \theta }
∂θ∂J(θ)是函数的梯度。
这是深度学习里面最常用的优化方法,目前已经有各种它的变式。
2)二阶优化算法
二阶优化算法使用二阶导数来最小化或最大化损失函数,主要基于牛顿法,但是由于二阶导数的计算成本很高,所以这种方法并没有广泛使用。
2.优化算法Torch.optim
Torch.optim是一个实现各种优化算法的包,大多数常见的算法都能够直接通过这个包来调用,比如随机梯度下降,以及添加动量的随机梯度下降,自适应学习率等。在调用的时候将需要优化的参数传入,这些参数都必须是Variable,然后传入一些基本的设定,比如学习率和动量等。
下面举一个例子:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
如上所示就将模型的参数作为需要更新的参数传入优化器,设定学习率是0.01,动量是0.9的随机梯度下降,在优化之前需要先将梯度归零,即optimizer.zero_grad(),然后通过loss.backward()反向传播,自动求导得到每个参数的梯度,最后只需要optimizer.step() 就可以通过梯度做一步参数更新。
3.优化器基类 Optimizer
基类链接: https://github.com/pytorch/pytorch/blob/master/torch/optim/optimizer.py
PyTorch中所有的优化器(如:optim.Adadelta、optim.SGD、optim.RMSprop等)均是Optimizer的子类,Optimizer中定义了一些常用的方法,有zero_grad()、step(closure)、state_dict()、load_state_dict(state_dict)和add_param_group(param_group)。
1)zero_grad()
功能: 将梯度清零。
由于PyTorch不会自动清零梯度,所以在每次更新前会进行此操作。
2)step(closure)
功能: 执行一步权重更新,其中可传入参数closure(一个闭包)。一些优化算法例如Conjugate Gradient和LBFGS需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型。这个闭包应当清空梯度,计算损失,然后返回。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
3)state_dict()
功能: 获取模型当前的参数,以一个有序字典形式返回。
这个有序字典中,key是各层参数名,value就是参数值。
'state_dict': model.state_dict(),
'optimizer' : optimizer.state_dict()
4)load_state_dict(state_dict)
功能: 将state_dict中的参数加载到当前模型,常用于
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
5)add_param_group()
功能: 给optimizer管理的参数组中增加一组参数,可为该组参数定制lr,momentum,weight_decay等,在finetune中常用。
optimizer.add_param_group({'params': w3, 'lr': 0.001, 'momentum': 0.8})
4.PyTorch优化器
1)torch.optim.SGD
CLASS torch.optim.SGD(params, lr=, momentum=0, dampening=0,
weight_decay=0, nesterov=False)
功能:
实现随机梯度下降算法(momentum可选)。
Nesterov动量基于《On the importance of initialization and momentum in deep learning》中的公式。
参数:
params (iterable): 待优化参数的iterable或者是定义了参数组的dict;
lr (float): 学习率;
momentum (float, 可选): 动量因子(默认:0,通常设为0.8、0.9);
weight_decay (float, 可选): 权重衰减(L2惩罚)(默认:0)
dampening (float, 可选): 动量的抑制因子(默认:0)
nesterov (bool, 可选): 使用Nesterov动量(默认:False)
样例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
2)torch.optim.RMSprop
CLASS torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
功能:
实现RMSprop优化方法(Hinton提出)。
中心版本首次出现在《Generating Sequences With Recurrent Neural Networks》.
参数:
params (iterable): 待优化参数的iterable或者是定义了参数组的dict;
lr (float, 可选): 学习率(默认:1e-2);
momentum (float, 可选): 动量因子(默认:0);
alpha (float, 可选): 平滑常数(默认:0.99);
eps (float, 可选): 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8);
centered (bool, 可选): 如果为True,计算中心化的RMSProp,并且用它的方差预测值对梯度进行归一化;
weight_decay (float, 可选): 权重衰减(L2惩罚)(默认: 0)。
3)torch.optim.Adam
CLASS torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0,amsgrad=False)
功能:
实现Adam(Adaptive Moment Estimation))优化方法。Adam是一种自适应学习率的优化方法,Adam利用梯度的一阶矩估计和二阶矩估计动态的调整学习率。
它在《Adam: A Method for Stochastic Optimization》中被提出。
参数:
params (iterable): 待优化参数的iterable或者是定义了参数组的dict;
lr (float, 可选): 学习率(默认:1e-3);
betas (Tuple[float, float], 可选): 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999);
eps (float, 可选): 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8);
weight_decay (float, 可选): 权重衰减(L2惩罚)(默认: 0)。
4)其他优化器
目前在深度学习任务上,常用的优化器为SGD、RMSprop和Adam。其他的PyTorch官方提供的优化器可根据任务需求,查找官方文档,了解详细内容。
(1)CLASS torch.optim.ASGD(params, lr=0.01, lambd=0.0001, alpha=0.75, t0=1000000.0,
weight_decay=0)
(2)CLASS torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
(3)CLASS torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0,
initial_accumulator_value=0, eps=1e-10)
(4)CLASS torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08,
weight_decay=0.01, amsgrad=False)
(5)CLASS torch.optim.SparseAdam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08)
(6)CLASS torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08,
weight_decay=0)
(7)CLASS torch.optim.LBFGS(params, lr=1, max_iter=20, max_eval=None,
tolerance_grad=1e-07, tolerance_change=1e-09, history_size=100, line_search_fn=None)
(8)CLASS torch.optim.Rprop(params, lr=0.01, etas=(0.5, 1.2), step_sizes=(1e-06, 50))
总结
至此,对PyTorch框架的优化算法进行了简单的了解,在实际应用中建议采用Adam或RMSprop优化算法。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)