通道(时间)注意力模块
为了汇总空间特征,作者采用了全局平均池化和最大池化两种方式来分别利用不同的信息。
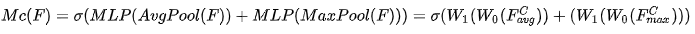
输入是一个 H×W×C 的特征 F,
- 我们先分别进行一个空间的全局平均池化和最大池化得到两个 1×1×C 的通道描述。
- 接着,再将它们分别送入一个两层的神经网络,第一层神经元个数为 C/r,激活函数为 Relu,第二层神经元个数为 C。这个两层的神经网络是共享的。
- 然后,再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc。
- 最后,拿权重系数和原来的特征 F 相乘即可得到缩放后的新特征。

实现代码如下:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
#两个 1×1×C 的通道描述
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 两层的神经网络,1x1卷积实现通道降维与升维
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes
nn.Conv2d(in_planes
# 再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
空间注意力模块
在通道注意力模块之后,我们再引入空间注意力模块来关注哪里的特征是有意义的。
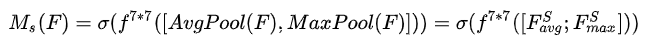
与通道注意力相似,给定一个 H×W×C 的特征 F’,
- 我们先分别进行一个通道维度的平均池化和最大池化得到两个 H×W×1 的通道描述,并将这两个描述按照通道拼接在一起。
- 然后,经过一个 7×7 的卷积层,激活函数为 Sigmoid,得到权重系数 Ms。
- 最后,拿权重系数和特征 F’ 相乘即可得到缩放后的新特征。

实现代码如下:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# avg_out和max_out 进行拼接cat后为两层,输出为一层
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
# 激活函数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)