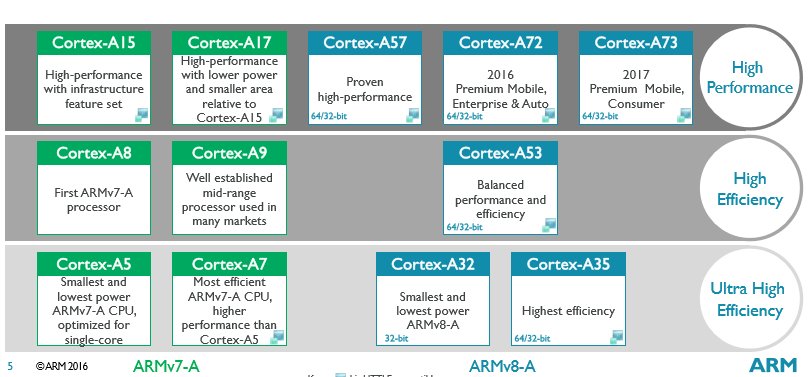
Cortex-A15最早在2010年发布,基于32位ARMv7-A架构。A15和A9同样具备乱序执行,但是Cortex-A15具备(两倍)的指令发射端口和执行资源,指令解码能力也要高出50%,动态分支预测能力更强(采用了多层级分支表缓存),指令拾取带宽更强(128 bit vs 64 bit),这些都能让A15的流水线执行具备更高的效率。除此以外,A15采用了VFPv4浮点单元设计,能执行FMA指令以及硬件除法指令,相较而言A9的峰值向量浮点性能基本上只有A15的一半。Cortex-A15处理器可以应用在智能手机、平板电脑、移动计算、高端数字家电、服务器和无线基础结构等设备上。
ARM Cortex-A8处理器,基于ARMv7-A架构,是目前使用的单核手机中最为常见的产品。Cortex-A8处理器是首款基于ARMv7体系结构的产品,能够将速度从600MHz提高到1GHz以上。Cortex-A8处理器可以满足需要在300mW以下运行的移动设备的功率优化要求;以及需要2000 Dhrystone MIPS的消费类应用领域的性能优化要求。Cortex-A8 高性能处理器目前已经非常成熟,从手机到上网本、DTV、打印机和汽车信息娱乐,Cortex-A8处理器都提供了可靠的高性能解决方案。