作者于6月3号已经更新了更详细的代码,也回答了一些关于代码运行的具体细节,大家可以直接去看。
以下是原文。
———————————————————————————————————————————
论文题目:《Practical Root Cause Localization for Microservice Systems via Trace Analysis》
代码链接:GitHub - NetManAIOps/TraceRCA: Practical Root Cause Localization for Microservice Systems via Trace Analysis. IWQoS 2021 https://github.com/NetManAIOps/TraceRCA不得不吐槽一下,这代码是一点注释都没啊。里面的数据处理过程和它链接里给的数据集也对不上,数据集没啥说明,代码对输入的数据格式也没说明,要自己做一些处理才能对应上,虽然才3个py文件,但是没有注释的代码真的是要人命。
https://github.com/NetManAIOps/TraceRCA不得不吐槽一下,这代码是一点注释都没啊。里面的数据处理过程和它链接里给的数据集也对不上,数据集没啥说明,代码对输入的数据格式也没说明,要自己做一些处理才能对应上,虽然才3个py文件,但是没有注释的代码真的是要人命。
TraceRCA 框架
主要思想:一个拥有较多异常痕迹和较少正常痕迹的微服务更有可能是根本原因。
主要步骤:首先,TraceRCA 使用我们的无监督多度量异常检测方法检测异常trace;然后通过fpgrowth来挖掘满足支持度阈值的频繁项集(即可疑的微服务集),根据它的支持度和置信度来计算它的JI分数;最后,计算每个微服务集里各个微服务的内置分数,并与JI值相乘,得到各微服务的分数并排序。
一、Trace Anomaly Detection
文章是通过检测异常invocations来推断异常trace的,而不是直接检测异常trace,因为trace长度是可变的,如果指定一个固定长度的trace来做检测可能会导致效率和精度都比较低。
1)Multi-Metric Invocation Anomaly Detection
在一个微服务系统中有很多的特征,然而当故障发生时并不是所有的特征都会因此受到影响。这里的调用检测分成两步:1)针对每个错误自适应地挑选有用的特征;2)再根据所选的特征检测异常调用。
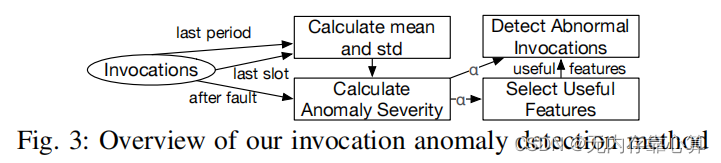
通过测试故障发生后,正常调用和异常调用的特征分布是否发生变化来判断一个特征是否有用。注意,这里是计算每一个调用的每一个特征的分布(相当于调用和特征做笛卡尔积,如果有10种调用,5个特征,那就是说要计算50个特征分布)。文章使用历史调用的均值和标准差来模拟正常调用的分布, ,
,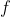 指的是某个微服务对(调用),
指的是某个微服务对(调用), 指该调用的特征值,
指该调用的特征值, 、
、 分别指该调用的历史均值和标准差,
分别指该调用的历史均值和标准差,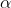 代表异常严重程度,越大,这个调用的特征可能就越不正常。文章中使用了两个阶段的历史数据来计算均值和标准差,以确保这两个值的鲁棒性和高效性。这两个阶段分别是1) in the last slot and 2) in the same slot of the last period。the last slot 指的是故障发生前几分钟内所捕获的该特征正常状态的历史数据。last period 指的是前几周或前几天的历史数据。
代表异常严重程度,越大,这个调用的特征可能就越不正常。文章中使用了两个阶段的历史数据来计算均值和标准差,以确保这两个值的鲁棒性和高效性。这两个阶段分别是1) in the last slot and 2) in the same slot of the last period。the last slot 指的是故障发生前几分钟内所捕获的该特征正常状态的历史数据。last period 指的是前几周或前几天的历史数据。
如前所述,如果一个特性是有用的,那么应该有更多的异常调用,这应该有很大的异常严重程度,关于该特征的所有调用的平均异常严重程度应该很大。那么,如果满足 ,就认为该特征是有用的。
,就认为该特征是有用的。 、
、 分别指故障发生前后的平均异常严重程度,
分别指故障发生前后的平均异常严重程度, 是给定的阈值。
是给定的阈值。
如果 ,则表明该调用的特征是异常的。只要调用的任何一个有用特征是异常的,就推断该调用的异常的。
,则表明该调用的特征是异常的。只要调用的任何一个有用特征是异常的,就推断该调用的异常的。
2)Trace anomaly inference
如果该trace中有任何一个调用是异常的,就推断该trace是异常的。
二、Suspicious Root-Cause Microservice Set Mining
先定义两个概念,支持度和置信度。支持度是指P(X|Y),X指的是通过某个微服务集的trace,Y是指所有异常的trace,这个P指的是在所有异常trace中经过该微服务集的异常trace比例。置信度是P(Y|X),指的是所有经过该微服务集的trace中,异常trace所占的比例。
文章中是通过FP-Growth来挑选频繁项集的,每个微服务集支持度要大于的阈值 才能被认为是频繁项集。然后再计算这些微服务集的JI值(即置信度和支持度的调和平均数),取出排名前k的微服务集作为最终可疑的根因微服务集。
才能被认为是频繁项集。然后再计算这些微服务集的JI值(即置信度和支持度的调和平均数),取出排名前k的微服务集作为最终可疑的根因微服务集。
三、Microservice Ranking
选出可疑的微服务集后,就要开始计算每个微服务的根因可疑分数了。将每个微服务集的JI值和微服务集里每个微服务的内置分数相乘,就得到该微服务的根因得分了。内置分数(in-set score)它是由所有包含可疑集的trace中包含微服务的异常调用的轨迹的数量的差值来计算的。例如,在可疑的微服务集{A、B}中,B的内置分数IS(B) = |3-3| = 0,IS(A) = |3-0| = 3。也就是计算在包含该微服务集的trace中,微服务作为异常调用的输入、输出数量的差值。根据下面这张图可以看到包含{A、B}的trace有3个,而这里面是异常调用(标红的箭头)且A作为输入的有3个,A作为异常调用的输出的0个,因此IS(A) = 3。同理,B作为异常调用输入的有3个,作为异常调用输出的有3个,因此IS(B) = 0。
文章认为,如果一个微服务既包含异常调用的输入、输出的数量相近的话(也就是IS值小),就认为该微服务是受到其他微服务的影响,它只是传播异常,而不是真正的异常源头。
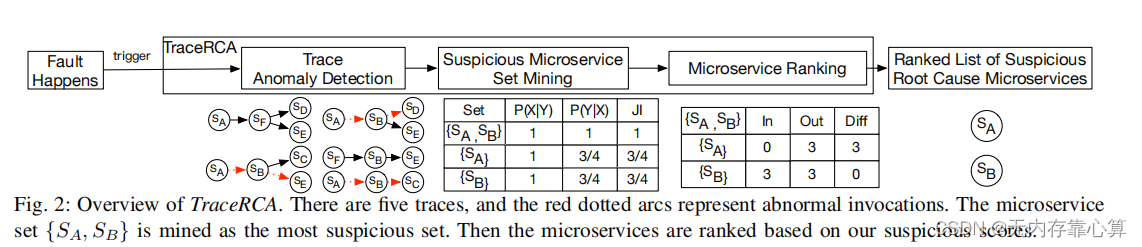
但是由于不同微服务集里可能有相同的微服务,所以这里直接取微服务得分的最大值作为该微服务最终的根因得分。然后排序下,就得到最可疑的根因微服务了。
Trace 代码
作者给的代码里面有库我找不到,所以我按照我自己的理解稍稍修改了下,应该没有太大的问题,这里面用到的函数基本上我都做了注释,没做注释的就是目前的运行中用不到的,基本上把文件路径改一下就可以直接用运行了,数据集就不上传了,作者github链接里有,直接下载然后用我代码里的data_processing.py文件处理下即可。
下载原始数据后,先data_processing.py,然后run_selecting_features.py ,再是run_anomaly_detection_invo_2.py,最后localization_mining.py。
https://github.com/chiyun1111/TraceRCA__changed.githttps://github.com/chiyun1111/TraceRCA__changed.git
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)