文章下载地址:Graphical Contrastive Losses for Scene Graph Parsing
代码地址:https://github.com/NVIDIA/ContrastiveLosses4VRD
发表地点:CVPR 2019
1 内容概括
现在常有的场景图生成方法,针对关系检测仍存在一定的问题
例如无法确定关系对应的实体,以及两个实体之间的具体关系
作者针对此问题,提出了对应的contrastive loss构建方法 以及 一个融合了三个模块的关系检测网络
通过这两个步骤的改进,作者在VG以及VRD这两个数据集上做到了sota的效果
2 研究背景
任务:Scene Graph Parsing,也就是场景图生成,输出多组三元组关系<subject, predicate, object>
现有方法:双阶段,实体检测-->关系预测,关系预测往往是一个多分类问题
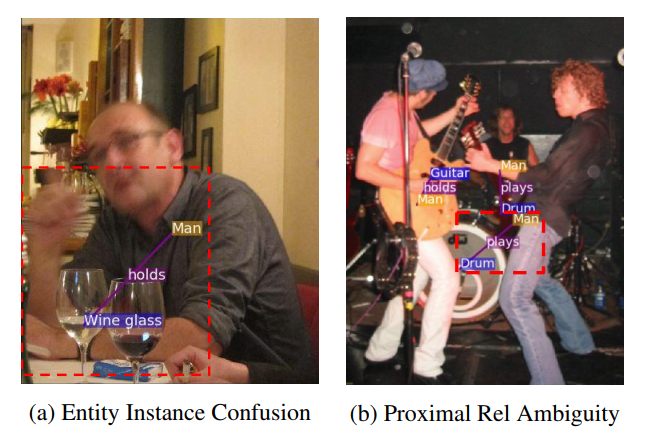
问题1:Entity Instance Confusion,例如(a)所示,有很多同样类别的subject和object,无法区分和关系相连的是哪一个实体
问题2:Proximal Relationship Ambiguity,例如(b)所示,有很多类似的关系relation,无法区分正确的关系连接方式
难点:对于所有类型的关系,可以自动学习确定视觉关系的精细细节,并明确区分相关实体和不相关实体
成果:relationship detector 关系检测网络, Graphical Contrastive Loss 损失计算方法
3 图像的对比损失
对比损失将由三部分组成
下述定义表示为subject以及object之间的关系强弱
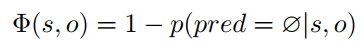
3.1 Class Agnostic Loss
对于entity pair,不论他们的关系,只从类别角度计算对比损失
拉大不同实体之间的距离,保证实体检测的准确性
类似matching问题中常用的triplet loss,最大化最小的正样例连接关系,最小化最大的负样例连接关系

最后的Loss为,其中N表示entity的类别数
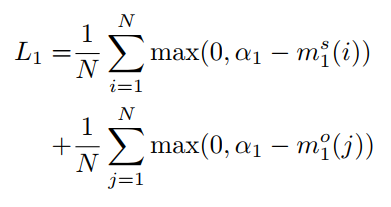
3.2 Entity Class Aware Loss
解决entity instance confusion这个问题,保证一个实体在对于多个候选类似类别的实体时,选择出对应关系对应的正确的另一个实体
这一个损失可以看作3.1的扩展,但是指定了所属的类别
即最大化所属相同类别的实体之间的距离,其中的类别由谓词关系确定,object以及subject不确定


3.3 Predicate Class Aware Loss
为了解决proximal relationship ambiguity这个问题,保证模型在有了pait-entity后可以找到准确的关系内容
这一个损失可以看作3.1的扩展,但是指定了所属的类别,与3.2不同,其中relation关系内容不确定
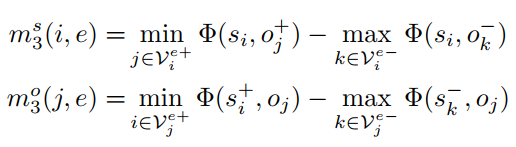
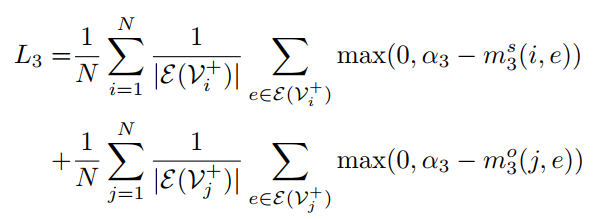
3.4 总损失
最后的训练损失就是上述三部分相加,以及predicate class的多分类问题产生的交叉熵损失

4 关系检测网络
和别的网络检测实体后直接进行分分类不同不同的地方在于,有一个分支去检测realtion对应的视觉内容

4.1 Semantic Module
这个模块计算了给定subject以及object类别后,得到pred类别的可能性

4.2 Spatical Module
从空间信息出发,作者通过使用框增量和归一化坐标对subject和object的框坐标进行编码来捕获空间信息
bounding box的归一化计算方式如下所示
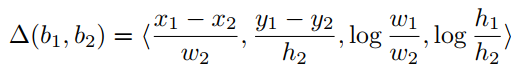
其中对应的视觉特征可以表示为

输出的视觉特征以及对应的位置信息表示为
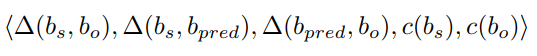
然后输入到MLP后得到谓词关系的class logit score
4.3 Visual Module
将三部分的特征通过ROI提取出来,然后利用MLP进行特征融合
最后通过softmax将三部分相加的结果进行归一化,选取最大可能性的类别

5 实验结果
作者在OpenImage Relationship Detection Challenge上超越了之前的方案,并且而在Visual Genome以及Visual Relationship Detection数据集上做到了sota的效果
在vrd上的表现如下表所示

其中detector的weights在别的数据集上进行初始化得到
具体的消融实验以及分析在文章中也很详细
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)