进程池(multiprocess.Pool)
一、进程池概念
1.什么是进程池?
2.为什么要有进程池?
😮忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。
😒那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?
😓首先,创建进程需要消耗时间,销毁进程也需要消耗时间。
😟第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。
😥因此我们不能无限制的根据任务去开启或者结束进程。那么我们要怎么做呢?
3.进程池的概念
- 😺定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务
- 😸等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务
- 😹如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。
- 😻也就是说,进池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行
- 😼这样不会增加操作系统的调度难度,还节省了开关进程的时间,也一定程度上能够实现并发效果。
4.资源进程
- 👉预先创建好的空闲进程,管理进程(好比池子🏊)会把工作分发到空闲进程来处理。
5.管理进程🏊
😱管理进程如何有效的管理资源进程,分配任务给资源进程?
👉通过IPC,信号,信号量,消息队列,管道等进行交互。
二.进程池的使用
我们可以通过维护一个进程池来控制进程的数目, 比如使用httpd的进程模式, 可以规定最大进程数和最小进程数, multiprocessing模块Pool类可以提供指定数量的进程供用户调用
1.创建一个进程池
- 方法 :
Pool([numprocess],[initializer],[initargs]) - ps : 在多线程那篇文章中介绍另一种创建进程池方式
from concurrent.future import ProcessPoolExecutor - 参数
| 参数 | 作用 |
|---|
| numprocess | 要创建的进程数,如果省略,将默认使用cpu_count()的值 |
| initializer | 每个工作进程启动时要执行的可调用对象,默认为None |
| initargs | 传给initializer的参数组 |
2.常用方法介绍
| 方法 | 作用 |
|---|
| p.apply(func,args,kwargs) | (同步调用)在进程池工作的进程中执行func函数,后面是参数,然后返回结果,如果想要传入不同的参数并发的执行func, 就需要以不同的线程去调用p.apply()函数或者使用p.apply_async() |
| p.apply_async(func,args,kwargs) | (异步调用)在进程池工作的进程中执行func函数,后面是参数,然后返回结果, 结果是AsyncResult类的实例, 可以使用回调函数callback, 将前面funct返回的结果单做参数传给回调函数 |
| p.close( ) | 关闭进程池,防止进一步操作, 如果所有操作持续挂起,它们将在工作进程终止前完成 |
| P.jion() | 等待所有工作进程退出。此方法只能在close()或teminate()之后调用,否则报错 |
3.其他方法
以下方法运用于 pply_async() 和 map_async()的返回值, 返回值是**AsyncResul **实例的对象, 也就是该对象的方法
| 方法 | 作用 |
|---|
| obj.get( ) | 返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发 |
| obj.ready( ) | 如果调用完成,返回True |
| obj.successful( ) | 如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常 |
| obj.wait([timeout]) | 等待结果变为可用, 参数是超时时间 |
| obj.terminate( ) | 立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果对象被垃圾回收, 将自动调用这个方法 |
4.同步调用示例 (apply)
from multiprocessing import Pool
import time,os,random
def test(n):
print(f"子进程:{os.getpid()}")
time.sleep(2)
return n*random.randint(2,9)
if __name__ == '__main__':
n = os.cpu_count() # 本机CPU个数,我的是4,进程池容量个数自定义,默认CPU核数
p = Pool(processes=n) # 设置进程池进程个数,从无到有,并且以后一直只有这四个进程在执行任务
li = []
start_time = time.time()
for i in range(10):
res = p.apply(test,args=(2,)) # 创建十个个任务, 使用同步调用的方式
li.append(res)
p.close() # 先关闭进程池, 不会再有新的进程加入到pool中, 防止进一步的操作(同步调用可以不加此方法)
p.join() # 必须在close调用之后执行, 否则报错, 执行后等待所有子进程结束(同步调用可以不加此方法)
print(li) # 同步调用, 得到的就是最终结果,(异步调用得到的是对象, 需要使用get方法取值)
print(f'使用时间:{time.time()-start_time}')
'''输出
子进程:7768
子进程:16276
子进程:17544
子进程:15680
子进程:7768
子进程:16276
子进程:17544
子进程:15680
子进程:7768
子进程:16276
[4, 18, 14, 14, 12, 14, 16, 14, 6, 10]
使用时间:20.226498126983643
'''
从上面的输出结果可以看到,进程一直是那四个 : 7769、16276、17544、15680, 并且异步提交需要等待上一个任务结束拿到结果才能进行下一个任务, 所以用时 20 秒多一点
5.异步调用示例 (apply_async)
from multiprocessing import Pool
import time,os,random
def test(n):
print(f"子进程:{os.getpid()}")
time.sleep(2)
return n*n*random.randint(2,9)
if __name__ == '__main__':
n = os.cpu_count() # 本机CPU个数,我的是4,进程池容量个数自定义,默认CPU核数
p = Pool(processes=n) # 设置进程池大小, 从无到有, 并之后只有这四个进程执行任务
li = []
start_time = time.time()
for i in range(10):
res = p.apply_async(test,args=(2,)) # 开启十个任务, 使用异步调用的方式
li.append(res)
p.close() # 关闭进程池, 不会再有新的进程加入到pool中, 防止进一步的操作
p.join() # join必须在close函数之后进行, 否则报错, 执行后等待所有子进程结束
print(li) # 返回的是AsyncResul的对象[<multiprocessing.pool.ApplyResult object at 0x000002318511B408>,....]
print([i.get() for i in li]) # 使用get方法来获取异步调用的值(同步调用没有该方法),并放入列表中打印
print(f"使用时间:{time.time()-start_time}")
'''输出
子进程:8636
子进程:10828
子进程:7432
子进程:13976
子进程:8636
子进程:10828
子进程:7432
子进程:13976
子进程:8636
子进程:10828
[<multiprocessing.pool.ApplyResult object at 0x000001623059B308>,...省略]
[16, 24, 24, 24, 16, 28, 36, 28, 8, 32]
使用时间:6.301024436950684
'''
从上面结果也能看出自始至终都只有四个进程在工作 : 8636、10828、7432、13976,异步调用方式如果任务进行时遇到阻塞操作将立马接收其它异步操作中的结果, 如果进程池满了, 则只能等待任务进行完毕拿到结果, 拿到的结果是 AsyncResul 的对象, 需要使用 get 方法取值, 用时 6 秒多一点
6.服务端使用进程池来控制接入客户端进程的个数示例
from socket import *
from multiprocessing import Pool
import os
s = socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 重用IP和端口
s.bind(("127.0.0.1",8055))
s.listen(5)
def connection(conn):
print(f"当前进程:{os.getpid()}")
while 1:
try:
date = conn.recv(1024)
if len(date) == 0:break
conn.send("阿巴阿巴".encode("utf-8"))
except Exception:
break
if __name__ == '__main__':
p = Pool(2) # 不指定,默认本机CPU核数
print("connection....")
while 1:
conn,addr = s.accept()
print(f"已连上{addr}")
p.apply_async(connection,args=(conn,))
from socket import *
c = socket(AF_INET,SOCK_STREAM)
c.connect(("127.0.0.1",8055))
while 1:
msg = input("内容>>").strip()
if len(msg) == 0:continue
c.send(msg.encode("utf-8"))
date = c.recv(1024)
print(f"服务端的回复:{date.decode('utf-8')}")
四个客户端一个服务端 :

启动五台机器, 让四台客户端发送信息
前两台能发收消息, 后两台阻塞原地




服务端显示两个进程启动成功 : 8928、17584, 剩余两个阻塞

我们将前面两个客户端进程关闭, 看看进程号是否变化
关闭前两个客户端进程之后, 后两个客户端进程立马启动起来了, 并且发现PID还是原来的两个
三.回调函数 (callback)
1.什么是回调函数
将第一个函数的指针(也就是内存地址,Python中淡化了指针的概念)作为参数传给另一个函数处理, 这第一个函数就称为回调函数
2.简单示例
def foo(n):
print(f"foo输出{n}")
def Bar(i,func):
func(i)
for i in range(3):
Bar(i,foo)
'''输出
foo输出0
foo输出1
foo输出2
'''
3.回调函数应用场景
当进程池中一个任务处理完之后, 它去通知主进程自己结束了, 让主进程处理自己的结果, 于是主进程去调用另一个函数去处理该结果, 我们可以将耗时间或者阻塞的任务放入进程池, 在主进程中指定回调函数, 并由主进程负责执行, 这样主进程在执行回调函数的时候就省去了I/O的过程, 直接拿到的就是任务的结果
from multiprocessing import Pool
import os
def get(n):
print(f"get--->{os.getpid()}")
return n # 返回任务执行的结果
def set(num): # 拿到回调函数的处理结果--->num
print(f"set--->{os.getpid()} : {num**2}")
if __name__ == '__main__':
p = Pool(3)
nums = [2,3,4,1]
li = []
for i in nums:
# 异步调用,并使用callback设置回调
res = p.apply_async(get,args=(i,),callback=set)
li.append(res)
p.close() # 关闭进程池
p.join() # 等待子进程结束
print([ii.get() for ii in li]) # 使用get方法拿到结果
'''输出
get--->8388
get--->8388
set--->8768 : 4
get--->8388
set--->8768 : 9
get--->8388
set--->8768 : 16
set--->8768 : 1
[2, 3, 4, 1]
'''
from multiprocessing import Pool
import requests,os
def get_htm(url):
print(f"进程:{os.getpid()}开始获取:{url}网页")
response = requests.get(url)
if response.status_code == 200: # 如果是200,则获取成功
return {'url':url,'text':response.text}
else:
return {'url':url,'text':''} # 有些网页获取不到,设置空
def parse_htm(htm_dic):
print(f'进程:{os.getpid()}正在处理:{htm_dic["url"]}的text')
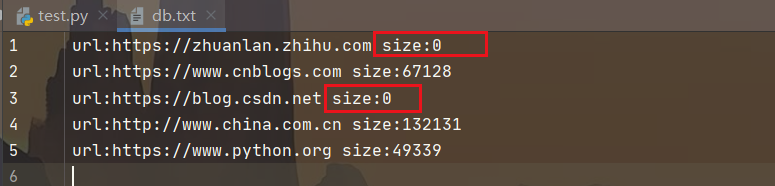
parse_data = f"url:{htm_dic['url']} size:{len(htm_dic['text'])}"
with open("./db.txt","a")as f: # 将URL和对应网页源码大小保存到文件
f.write(f"{parse_data}\n")
if __name__ == '__main__':
urls=[
'https://zhuanlan.zhihu.com',
'https://www.cnblogs.com',
'https://www.python.org',
'https://blog.csdn.net',
'http://www.china.com.cn',
]
p = Pool(3) # 设置进程池最大进程数为3
li = []
for url in urls:
# 异步调用并设置回调
res = p.apply_async(get_htm,args=(url,),callback=parse_htm)
li.append(res)
p.close() # 关闭进程池
p.join() # 等待子进程结束
print([i.get() for i in li]) # 使用get方法获取结果
'''输出
进程:11484开始获取:https://zhuanlan.zhihu.com网页
进程:17344开始获取:https://www.cnblogs.com网页
进程:2688开始获取:https://www.python.org网页
进程:11484开始获取:https://blog.csdn.net网页
进程:3928正在处理:https://zhuanlan.zhihu.com的text
进程:17344开始获取:http://www.china.com.cn网页
进程:3928正在处理:https://www.cnblogs.com的text
进程:3928正在处理:https://blog.csdn.net的text
进程:3928正在处理:http://www.china.com.cn的text
进程:3928正在处理:https://www.python.org的text
[{'url': 'https://zhuanlan.zhihu.com', 'text': ''},...一堆网页源码的bytes(省略)]
'''
4.爬取福布斯全球排行榜

from multiprocessing import Pool
import re
import requests
def get_htm(url,format1):
response = requests.get(url)
if response.status_code == 200:
return (response.text,format1)
else:
return ('',format1)
def parse_htm(res):
text,format1 = res
data_list = re.findall(format1,text)
for data in data_list:
with open("福布斯排行.txt","a",encoding="utf-8")as f:
f.write(f"排名:{data[0]},名字:{data[1]},身价:{data[2]},公司:{data[3]},国家:{data[4]}\n")
if __name__ == '__main__':
url1 = "https://www.phb123.com/renwu/fuhao/shishi.html"
format1 = re.compile(r'<td.*?"xh".*?>(\d+)<.*?title="(.*?)".*?alt.*?<td>(.*?)</td>.*?<td>(.*?)<.*?title="(.*?)"', re.S)
url_list = [url1]
for i in range(2, 16):
url_list.append(f"https://www.phb123.com/renwu/fuhao/shishi_{i}.html")
p = Pool()
li = []
for url in url_list:
res = p.apply_async(get_htm,args=(url,format1),callback=parse_htm)
li.append(res)
p.close()
p.join()
print("保存完成")


ps : 如果你就是想在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)