无论安装多少次mysql,仍然会出现各种各样的错误,无可奈何,只能和mysql硬刚了!
所以最好的解决方案是查看错误日志,去解决懵逼的代码错误。
错误如图所示:
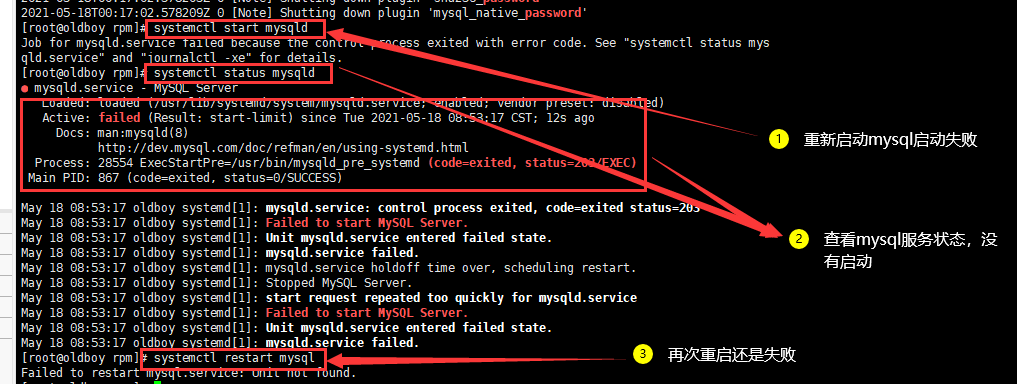
百度了好久,经过一系列的重启,修改权限,并不能精准找到错误原因,发现有说磁盘空间不足的、有说需要删除var/lib/mysql,所有文章千篇一律。
[root@oldboy ~]
[root@oldboy ~]
Failed to restart mysql.service: Unit not found.
[root@oldboy ~]
Redirecting to /bin/systemctl restart mysqld.service
Job for mysqld.service failed because the control process exited with error code. See "systemctl status mysqld.service" and "journalctl -xe" for details.
然而,无论哪种说法,都没有什么卵用,并没有都要找到一种切实符合自身问题的解决办法。
还有,我是的磁盘空间是非常充足的。
[root@oldboy ~]
Filesystem Size Used Avail Use% Mounted on
devtmpfs 486M 0 486M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 1.4M 495M 1% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/vda1 40G 8.8G 29G 24% /
tmpfs 100M 0 100M 0% /run/user/0
'''
执行的结果每列的含义:
第一列Filesystem,磁盘分区
第二列Size,磁盘分区的大小
第三列Used,已使用的空间
第四列Avail,可用的空间
第五列Use%,已使用的百分比
第六列Mounted on,挂载点
'''
不过任我怎么折腾,当我再次执行service mysql restart时,仍旧报错。

注意:接下来就要放大招了,查看mysqld日志
[root@oldboy soft]
[root@oldboy soft]
由于在远端看日志不太方便,直接将日志下载到本地。
[root@oldboy soft]
[root@oldboy log]
于是,就找到了报错信息。
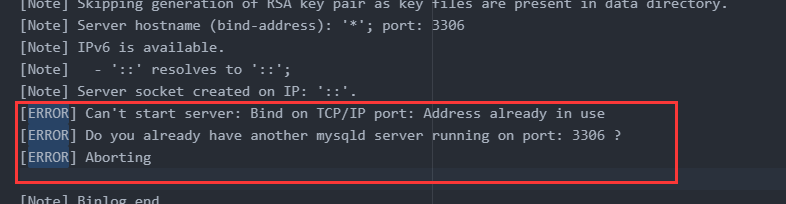
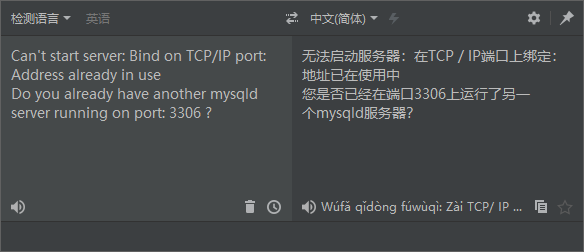
将错误翻译如下:
想着杀掉mysql相关进程
[root@oldboy etc]
重启mysql还是失败……
[root@oldboy etc]
Job for mysqld.service failed because the control process exited with error code. See "systemctl status mysqld.service" and "journalctl -xe" for details.
[root@oldboy etc]
Failed to restart mysql.service: Unit not found.
又新建了一个my.cfg文件配置文件
[root@oldboy ~]
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
保存退出重新加载配置文件
[root@oldboy ~]
还没有什么用,enennen……
查看3306端口,并没有被占用……
ss -antlp|grep 3306
netstat -apn|grep 3306
最后还是向接受现实吧!重装大法!

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)