一、AA策略文件
AA中关于存储策略设置的文件主要有两个:policies.py、archappl.properties。每个appliance只有一个archappl.properties和policies.py文件,所以archappl.properties中的参数对于同一个appliance来说是固定的;而policies.py文件中可以设置多种policy(利用pvPolicyDict{}定义,详见后文),所以policies.py中的参数对于同一个appliance来说可以通过选择不同的policy来改变。
安装过程中policies.py策略文件的流动过程如下图(archappl.properties与之相同):
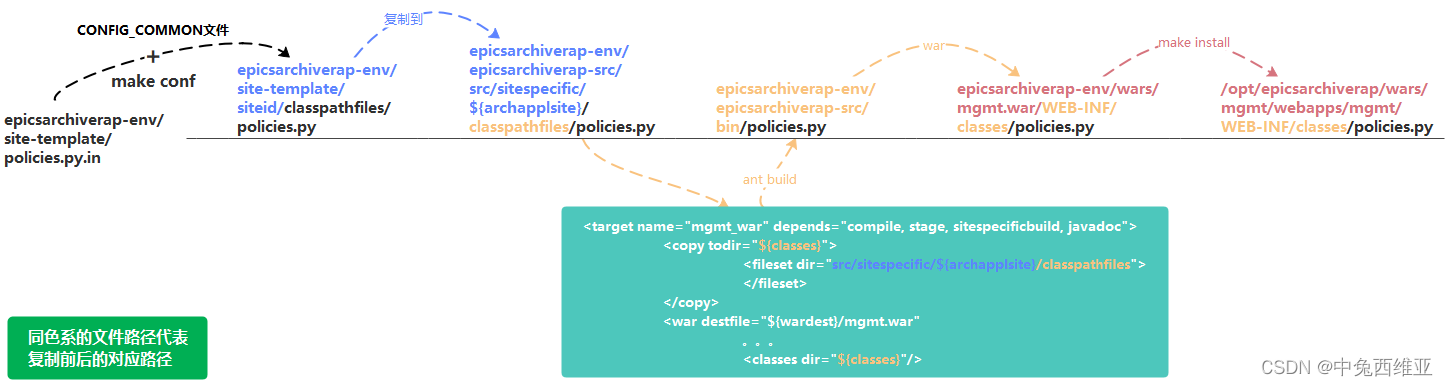
因此,若使用epicsarchiverap-env安装包进行安装,则需更改epicsarchiverap-env/
site-template/policies.py.in、archappl.properties.in 和 epicsarchiverap-env/configure/CONFIG_COMMON、CONFIG_SITE文件,从而得到最终希望的policies.py、archappl.properties文件。若直接使用epicsarchiverap-src安装包(AA安装包)安装,则直接更改epicsarchiverap-src/src/sitespecific/${archapplsite}/classpathfiles/policies.py、archappl.properties文件即可。
二、policies.py文件内容
2.1 可在policies.py中设置的属性
policies.py文件从python文件到Java类数据的转化过程如下:

policies.py相关的配置信息存放在PolicyConfig类中。epicsarchiverap-src\src\main\org\epics\archiverappliance\mgmt\policy\ExecutePolicy.java根据pvName和 pvInfo在policies.py文件中中找到相应的pvPolicyDict{},将其配置内容传递给PolicyConfig。
因此,可在policies.py的pvPolicyDict{}中定义的field(属性):
private SamplingMethod samplingMethod;
private float samplingPeriod = 1.0f;
private String[] dataStores;
private String policyName;
private String[] archiveFields;
private String appliance;
private String controlPV;
2.2 dataStores的定义
dataStores[]是一个含有3个String的列表,每个String都是一串定义了数据存储策略的URL,分别设置了STS、MTS、LTS的相关信息。
AA手册中这一段解释了dataStores的作用机制:
For example, the resulting dictionary contains a field called dataStores which is an array of StoragePlugin URL’s that can be parsed by the StoragePluginURLParser.
This is converted into a sequence of StoragePlugin’s that is used like so
- The engine webapp writes data into the first StoragePlugin in the sequence, i.e.
dataStores[0] - The ETL webapp schedules data transfers from one StoragePlugin to the next in the sequence according to their PartitionGranularity's
- When servicing a data retrieval request, the retrieval webapp retrieves data from all of the datastores and then combines them using a merge/dedup operator.
AA中的StoragePlugin是数据存储相关设置的interface,可针对它编写各种数据存储格式相对应的implement类。PlainPBStoragePlugin就是其中一种implement类,它将PV数据以块的形式进行存储,文件格式为.pb文件。
Java代码工作原理见下图:
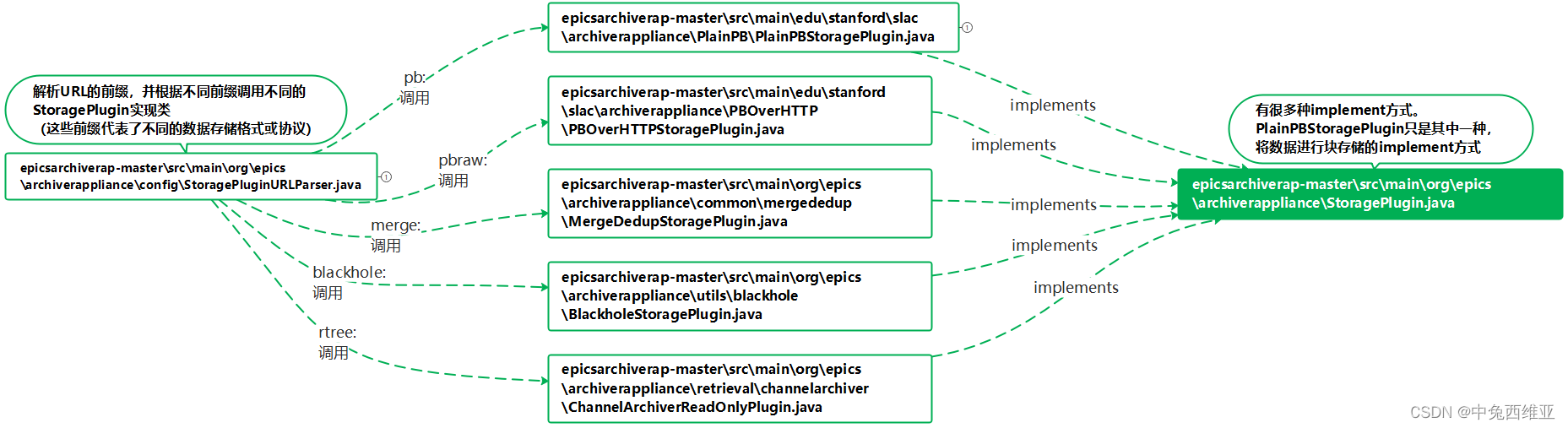
org.epics.archiverappliance.config.StoragePluginURLParser解析dataStores[]中的URL。该URL可以pb、pbraw、merge、blackhole、rtree为前缀,一般来说选择pb。根据URL中的不同前缀,调用对应的实现类中的initialize()函数来解析该URL。
对于前缀pb来说,会调用edu.stanford.slac.archiverappliance.PlainPB.PlainPBStoragePlugin类。根据PlainPBStoragePlugin.java文件可知,以pb为前缀的URL的格式为:
pb://<IP address>?name=<NAME>&rootFolder=<ROOT_FOLDER>&partitionGranularity=<PARTITION_GRANULARITY>[&hold=<HOLD>&gather=<GATHER>][&compress=<COMPRESS>][&pp=<POST_PROCESSOR>][&reducedata=<POST_PROCESSOR>][&consolidateOnShutdown=<true/false>][&etlIntoStoreIf=<NAMED_FLAG>][&etlOutofStoreIf=<NAMED_FLAG>]
其中各项的含义为:
(1)IP address(必须项):数据存储所在主机的IP,一般为localhost。
(2)name(必须项):数据存储策略的名字。
(3)rootFolder(必须项):数据存储的路径。可以使用环境变量,如“rootFolder=${ARCHAPPL_SHORT_TERM_FOLDER}”,会依次从java.system.properties (以 -D 参数传递给 JVM)、环境变量中查找ARCHAPPL_SHORT_TERM_FOLDER变量。
(4)partitionGranularity(必须项):每个单独的数据存储文件所存储的数据的时间跨度。每隔partitionGranularity所定义的时间周期,AA就会生成一个新的.pb文件用来存储下一周期内的PV。
该项可设置的值为:
PARTITION_5MIN(5*60),
PARTITION_15MIN(15*60),
PARTITION_30MIN(30*60),
PARTITION_HOUR(60*60),
PARTITION_DAY(24*60*60),
PARTITION_MONTH(31*24*60*60),
PARTITION_YEAR(366*24*60*60)
(5)hold & gather:经常一起使用。hold代表该存储路径下,一个PV的.pb文件的最大留存文件数;gather表示当一个PV的.pb文件数大于hold时,AA会将该路径下时间最靠前的.pb文件传输到下一阶段(STS -> MTS,MTS -> LTS)的.pb文件数。例如,“hold=5&gather=3”表示该存储路径下每个PV最多留存5个.pb文件,大于5个时会将时间最靠前的3个.pb文件传输到下一阶段。默认情况下,hold=0&gather=0,意味着每个PV的.pb文件刚刚存储完成即刻传输到下一阶段。(由于每个.pb文件传输到下一阶段需要一定时间,所以我们有时候能在该存储路径下看到这些.pb文件都还在。)
(6)compress:PV数据是否存储为压缩形式。可设置两个值:
NONE,
ZIP_PER_PV
一般可以不设置或设置为NONE。当设置为ZIP_PER_PV时,会自动为rootFolder加上"jar:file://"前缀修饰(若已有该前缀则不加),实际存储路径仍是rootFolder所定义的路径;rootFolder格式应类似“jar:file:///ziptest/alltext.zip!/SomeTextFile.txt”。
(7)pp:在ETL期间计算和缓存的PV数据后处理操作符列表。 数据检索时,若检索这些经过处理或运算的PV数据,则可以使用来自ETL缓存副本的数据(大大提高了检索性能); 否则,将在检索时处理或运算这些数据。 若要指定多种处理或运算方式,使用像“pp=rms&pp=mean_3600”这样的标准URL语法。 数据的处理或运算功能详见AA手册 Processing of data。
(8)reducedata:将数据存储到该路径时精简数据的方式,可指定为pp参数能够使用的任何后处理器。 例如,将LTS定义为“pb://localhost? name=LTS&rootFolder=${ARCHAPPL_LONG_TERM_FOLDER}&partitionGranularity= partition_years &reducedata=firstSample_3600”,那么ETL在把数据移入这个存储时,会对原始数据应用firstSample_3600运算符对数据进行reduce,在LTS中只存储reduce后的数据。 该参数与pp参数的区别在于,指定了reducedata时,只存储reduce后的数据,原始数据被丢弃。如果同时指定pp和reducedata,结果不可预知,因为pp指定的后处理器进行预计算和缓存需要原始数据。
(9) consolidateOnShutdown:控制ETL是否应该在AA停止时将该阶段数据全部传输到下一存储阶段( 对于使用RAMDisk作为STS的情况很有意义,避免STS中的数据丢失)。设置为true或false。
(10)etlIntoStoreIf:该参数指定的NAMED_FLAG控制ETL是否应该将数据移动到当前存储中。 若该参数指定的NAMED_FLAG为false,当前存储区域等同于blackhole(会丢失数据)。 若不设置该项,当前存储区域会接受所有进入的ETL数据。注意, 若未对该项指定相应的NAMED_FLAG,或对该项指定了某个NAMED_FLAG但未对该NAMED_FLAG赋值,该项的NAMED_FLAG默认为false,默认行为是丢失数据。 例如,指定etlIntoStoreIf=testFlag,只有当testFlag的值为true时,数据才会移动到这个存储区,否则移入当前存储区的数据会丢失。
(11)etlOutofStoreIf:该参数指定的NAMED_FLAG控制ETL是否应该将数据移出此存储。 若该参数指定的NAMED_FLAG为false,当前存储区域会一直收集而不移出数据,直到空间耗尽。 若不设置该项,当前存储区域会正常将数据移出。注意, 若未对该项指定相应的NAMED_FLAG,或对该项指定了某个NAMED_FLAG但未对该NAMED_FLAG赋值,该项的NAMED_FLAG默认为false,默认行为是一直收集而不移出数据,直到空间耗尽。例如,指定etlOutofStoreIf=testFlag,只有当testFlag的值为true时,数据才会从存储中移出。
2.3 SamplingPeriod的定义
仅在samplingMethod=SCAN模式下有意义,代表对PV进行采样存储的最小采样时间间隔。
2.4 samplingMethod的定义
samplingMethod为enum类型,有三个值可选:SCAN, MONITOR, DONT_ARCHIVE。
public enum SamplingMethod { SCAN, MONITOR, DONT_ARCHIVE }
其中SCAN, MONITOR的区别在AA手册中如下解释:
What's the difference between SCAN and MONITOR?
These are minor variations of the similar concepts in the ChannelArchiver and other archivers. Both SCAN and MONITOR use camonitors.
- For MONITOR, we estimate the number of samples based the PV's sampling period, allocate a buffer to accommodate this many samples and fill it up. The buffer's capacity is computed using something like so (see
ArchiveEngine.java:addChannel) int buffer_capacity = ((int) Math.round(Math.max((write_period/pvSamplingPeriod)*sampleBufferCapacityAdjustment, 1.0))) + 1;
- pvSamplingPeriod is the sampling_period from the PV's PVTypeInfo
- write_period is the engine's write period from archappl.properties ( where it's called secondsToBuffer ) ; this defaults to 10 seconds.
- sampleBufferCapacityAdjustment is a system-wide adjustment for the buffer side and is set in archappl.properties.
For example, if the write_period is 10 seconds, and the pvSamplingPeriod is 1 second, we would allocate 10/1 + 1 = 11 samples for the default sampleBufferCapacityAdjustment. Thus, in the case where the PV is changing at a rate greater than 1Hz, you should expect 11 samples, a gap where we run out of space and throw away samples, then 11 samples when we switch buffers and so on. For example, here's a 10Hz PV being MONITOR'ed at 1 second.Nov/22/2019 08:30:06 -08:00 -0.6954973468157408 0 0 717169462
... Buffer switch drop samples here
Nov/22/2019 08:30:15 -08:00 0.13051475393574385 0 0 717195856
Nov/22/2019 08:30:15 -08:00 0.1404225266840449 0 0 816931850
Nov/22/2019 08:30:15 -08:00 0.15031625729669593 0 0 917194635
Nov/22/2019 08:30:16 -08:00 0.1601949564088804 0 0 17161946
Nov/22/2019 08:30:16 -08:00 0.17005763615891936 0 0 117100329
Nov/22/2019 08:30:16 -08:00 0.17990331028705667 0 0 217167979
Nov/22/2019 08:30:16 -08:00 0.1897309942340842 0 0 317064449
Nov/22/2019 08:30:16 -08:00 0.19953970523979697 0 0 416941153
Nov/22/2019 08:30:16 -08:00 0.2093284624412683 0 0 516970909
Nov/22/2019 08:30:16 -08:00 0.21909628697093528 0 0 617021076
Nov/22/2019 08:30:16 -08:00 0.22884220205448483 0 0 717085134
.... Buffer switch drop samples here
Nov/22/2019 08:30:25 -08:00 0.9047907734809058 1 4 717192286
- For SCAN, the engine updates one slot/variable at whatever rate is sent from the IOC. And then a separate thread periodically picks the value of this one slot/variable every
pvSamplingPeriod seconds and writes it out to the buffers.
总结下来就是:
(1)对于MONITOR模式来说,AA中的engine服务先把camonitor到的PV数据存储到buffer中,每隔write_period时间把buffer数据写入STS中。
buffer的容量根据write_period(archappl.properties中的secondsToBuffer参数,默认=10s)、pvSamplingPeriod(policies.py中pvPolicyDict{}的samplingPeriod参数,默认=1s)、sampleBufferCapacityAdjustment(archappl.properties中的参数,默认=1)来计算确定,计算公式如下:
int buffer_capacity = ((int) Math.round(Math.max((write_period/pvSamplingPeriod)*sampleBufferCapacityAdjustment, 1.0))) + 1;
如果PV的更新频率较高,在write_period时间周期内PV的更新数据量大于buffer的容量,则会丢失一部分PV数据。所以应根据PV的更新频率合理设置以上3个参数,从而为buffer设置一个合适的容量。
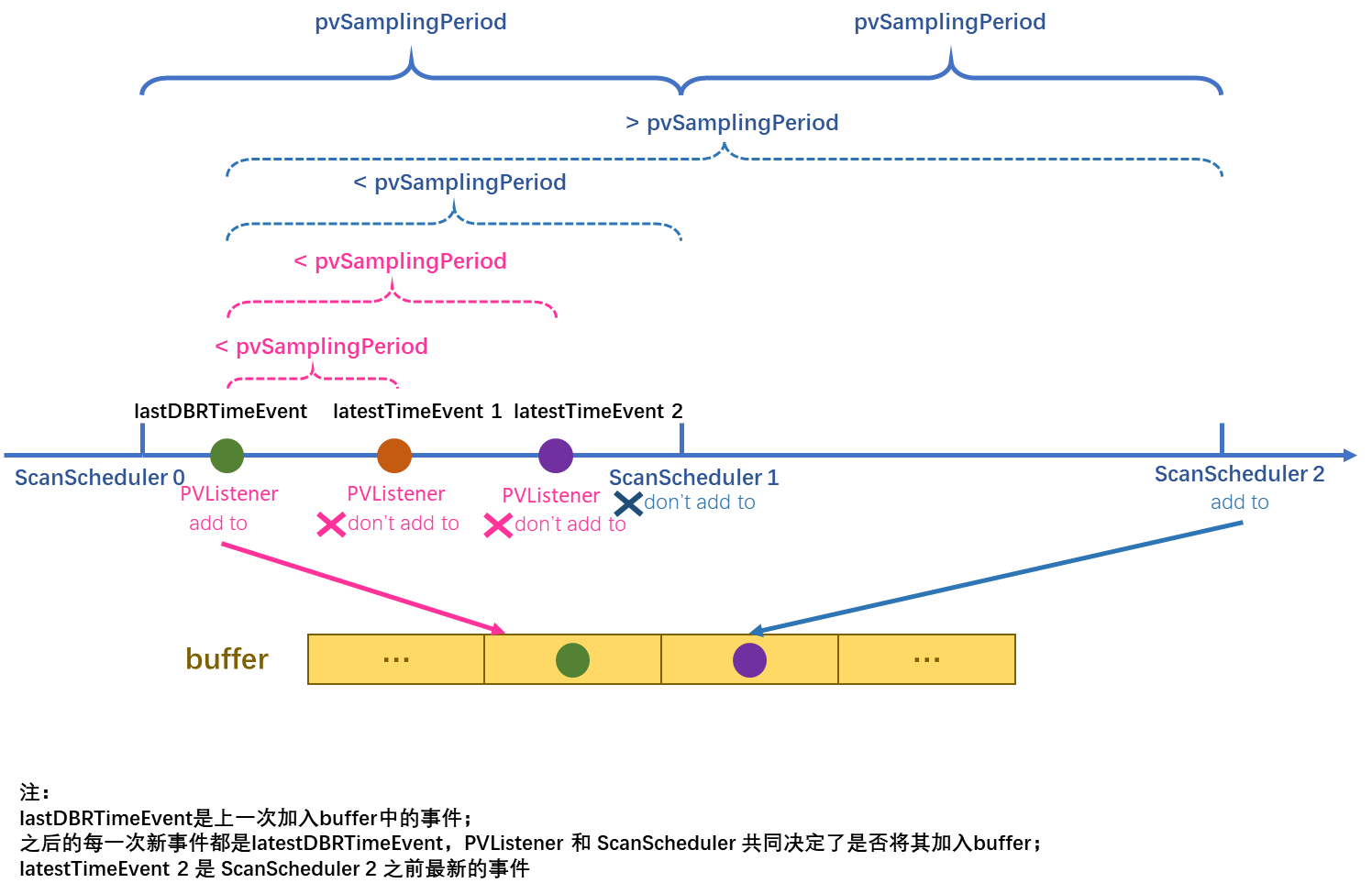
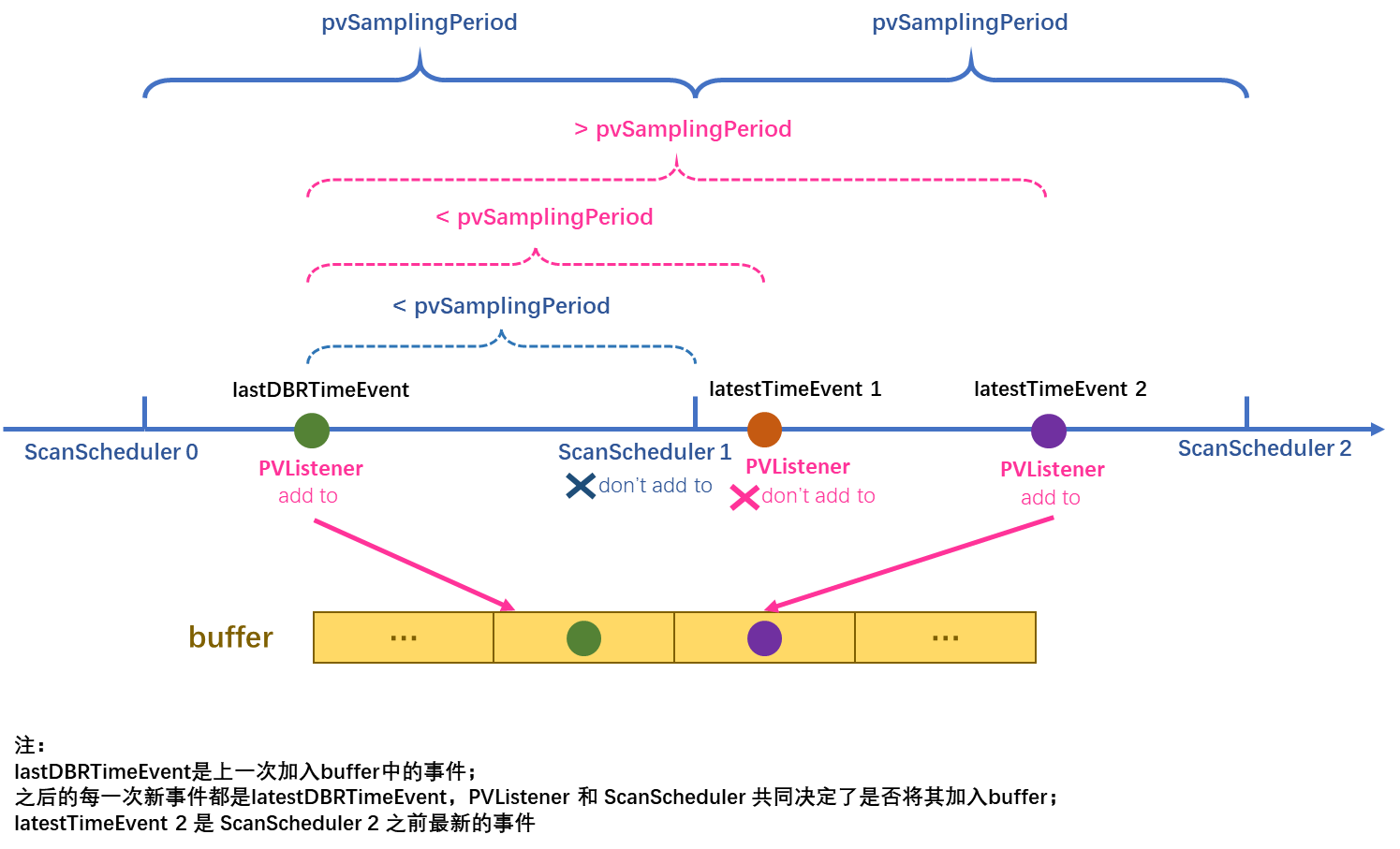
(2)对于SCAN模式来说,AA中的engine服务会使用PVListener按照至少pvSamplingPeriod的采样时间间隔对PV进行采样,把数据存储到buffer中;并单独开启一个(或多个)线程作为ScanScheduler,用来监测最新更新的PV值(但未被采样并储存到buffer中)是否距离当前采样周期时间点大于pvSamplingPeriod,若大于,则将最新更新的该PV值也存储到buffer中。
由于每个appliance只有一个archappl.properties文件,所以write_period和sampleBufferCapacityAdjustment参数对于同一个appliance是固定的;但在policies.py文件中可以对不同的policy设置相应的pvSamplingPeriod。所以,对于以较高频率更新的PV,可设置针对性的pvPolicyDict{},将其中的samplingPeriod参数设置成与该PV更新频率相匹配的时间周期。
三、archappl.properties文件内容
AA手册提到,archappl.properties文件中的参数都是AA启动前就确定的。
The configuration elements present here are configuration decisions that are made during the initial scoping of your archiving project
3.1 org.epics.archiverappliance.config.ConvertPVNameToKey.siteNameSpaceSeparators 和 siteNameSpaceTerminator
AA以块的形式存储数据,会根据PV名称和以上两个参数决定PV数据文件存储位置和文件名。
The archiver appliance stores data in chunks that have a well defined key.
The key is based on
- The PV Name
- The time partition of the chunk
For example, using the default key mapping strategy, data for the PV EIOC:LI30:MP01:HEARTBEAT for the timeframe 2012-08-24T16:xx:xx.xxxZ on an hourly partition is stored under the key EIOC/LI30/MP01/HEARTBEAT:2012_08_24_16.pb. Data for the same PV in a daily partition is stored under the key EIOC/LI30/MP01/HEARTBEAT:2012_08_24.pb for the day 2012-08-24Txx:xx:xx.xxxZ.
To use the default key mapping strategy, it is important (for performance reasons) that the PV names follow a good naming convention that distributes the chunks into many folders - see the Javadoc for more details. If the key/file structure reflecting the PV naming convention feature is not important to you, you can choose to use an alternate key mapping strategy by implementing the PVNameToKeyMapping interface and setting this property to name of the implementing class.
(1)org.epics.archiverappliance.config.ConvertPVNameToKey.siteNameSpaceSeparators:
这是一个分隔PV名称各组成部分的字符列表,根据该列表中的字符分割PV存储路径层级。它的语法必须满足Java的replaceAll regex要求。
例如:要指定包含“:”和“-”字符的列表,我们必须使用 [\\:\\-]。
(2)org.epics.archiverappliance.config.ConvertPVNameToKey.siteNameSpaceTerminator:
指定了数据存储文件中PV名称部分的结束符,该结束符后会连接时间信息。
例如,PV名以“:”结束,则该项应为 :。
3.2 org.epics.archiverappliance.config.PVTypeInfo.secondsToBuffer 和 org.epics.archiverappliance.config.PVTypeInfo.sampleBufferCapacityAdjustment
与数据存储buffer有关,详见 2.4 samplingMethod的定义 部分。
3.3 org.epics.archiverappliance.config.NamedFlags.readFromFile
指定一个定义了named flag list的文件。文件中的list对每个named flag进行了true或false的定义,若未定义则默认为false。
该参数可与 2.2 dataStores的定义 中介绍的 etlIntoStoreIf 和 etlOutofStoreIf 结合使用。
3.4 org.epics.archiverappliance.mgmt.MgmtRuntimeState.archivePVWorkflowBatchSize
AA会定期处理目前请求 Archive 的 PV 队列,为其执行初始化。
为了节省 engine 的资源,也为了控制CA搜索广播风暴,每次定期处理的 PV 数量,都会施加限制。
AA将等待处理的 PV 队列排序后,每次最多处理队列中前 archivePVWorkflowBatchSize 的 PV 数量(默认值1000)。
四、注意事项
- policies.py修改后,不需重启AA即可生效;archappl.properties修改后,需重启AA才可生效。
- 要修改某个PV的存储策略,可以直接在其detail页面点击“Change archival parameters”按钮修改;也可先删除该PV,再重新Archive(仅将PV pause掉是无法重新Archive的),并且Archive时选择存储策略。
参考文章
[1] ScheduledThreadPoolExecutor 中ScheduleAtFixedRate 和 ScheduleWithFixedDelay方法讲解
[2] 并发系列(7)之 ScheduledThreadPoolExecutor 详解
[3] 深入理解Java线程池:ScheduledThreadPoolExecutor
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)