官方解释A byte buffer,一个字节缓冲区。
一. 使用方法
-
ByteBuffer 初始状态是写模式, 使用IO流即可写入数据,如: channel.read()
-
如果需要读取ByteBuffer中的数据调用filp()方法切换即可
-
从ByteBuffer中读取数据有很多API 最常用的有 ByteBuffer.get()方法
-
读取完成之后调用 clear()或者compact()切换至写模式
-
日常使用中重复 1~4步骤以节省服务器内存空间
二. ByteBuffer结构
- ByteBuffer 有以下属性
capacity
position
limit - 写模式下,
position是写入位置,limit等于容量
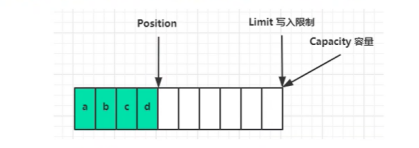
flip动作发生后, position切换为读取位置, limit切换为读取限制
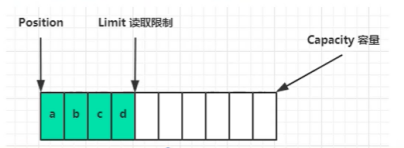
- 读取了4个字节之后的状态如下

clear动作发生之后
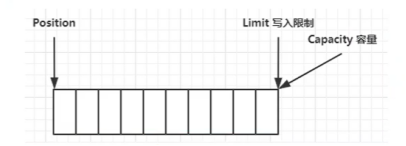
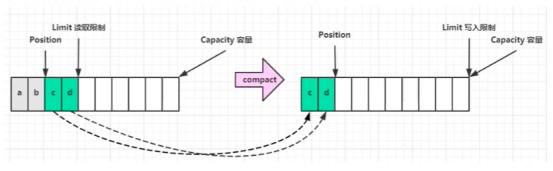
- 还可以使用
compact()方法进行切换读写模式
三. ByteBuffer 源码分析

- ByteBuffer的基础属性继承自Buffer, 其中
mark <= position <= limit <= capacity 四个属性代表的意思与上文介绍的一样,标记 <= 位置 <= 限制 <= 容量 - 如图↓, 我们最常使用的
allocate()方法其实就是设置一个大于零的内存容器

其默认值分别为↓
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}
HeapByteBuffer是ByteBuffer的其中一个子类, 有兴趣的可以去翻一下源码
同时还有另外一种方法创建ByteBuffer, 生成的ByteBuffer本质上不是一个类型的对象
System.err.println(ByteBuffer.allocate(16).getClass());
System.err.println(ByteBuffer.allocateDirect(16).getClass());
- ByteBuffer还有一些自己独有的属性, 这其中就包含了最具有代表性的
read()事件

hb用于接收byte数组生成ByteBuffer
offset: 数组偏移量, 用来告诉ByteBuffer从数组的哪个地方开始读取生成, offset不可以小于 0
isReadOnly: 用来判断当前的ByteBuffer数组是否是只读模式, 如果需要切换则需要调用想用的方法
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)