👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码、数据、文章讲解

💥1 概述
摘要:提出了一种基于遗传算法(ga)和随机重启爬坡(RRHC)的新型混合算法GA-RRHC,用于求解具有高灵活性(每项操作都可以由大量机器完成)的柔性作业车间调度问题(FJSSP)。特别地,不同的遗传算法交叉和简单变异算子与细胞自动机(CA)启发的邻域一起使用来执行全局搜索。该方法通过基于RRHC的局部搜索进行改进,使计算实现变得容易。在GA-RRHC中应用ca型邻域和上述两种技术进行杂交,得到了新颖的点,易于理解和实现。GA-RRHC的测试采用了文献中广泛使用的四组实验,并将其结果与使用相对百分比偏差(RPD)和Friedman检验的六种最新算法进行比较。实验表明,对于FJSSP实例,GA-RRHC算法具有较高的灵活性,是一种较有竞争力的方法。
关键词:柔性作业车间调度实例;遗传算子;局部搜索方法;元胞自动机
原文摘要:
Abstract: This work presents a novel hybrid algorithm called GA-RRHC based on genetic algorithms (GAs) and a random-restart hill-climbing (RRHC) algorithm for the optimization of the flexible job shop scheduling problem (FJSSP) with high flexibility (where every operation can be completed by a high number of machines). In particular, different GA crossover and simple mutation operators are used with a cellular automata (CA)-inspired neighborhood to perform global search. This method is refined with a local search based on RRHC, making computational implementation easy. The novel point is obtained by applying the CA-type neighborhood and hybridizing the aforementioned two techniques in the GA-RRHC, which is simple to understand and implement. The GA-RRHC is tested by taking four banks of experiments widely used in the literature and comparing their results with six recent algorithms using relative percentage deviation (RPD) and Friedman tests. The experiments demonstrate that the GA-RRHC is a competitive method compared with other recent algorithms for instances of the FJSSP with high flexibility.
Keywords: flexible job shop scheduling instances; genetic operators; local search methods; cellular automata
详细文章讲解见第4部分。
📚2 运行结果

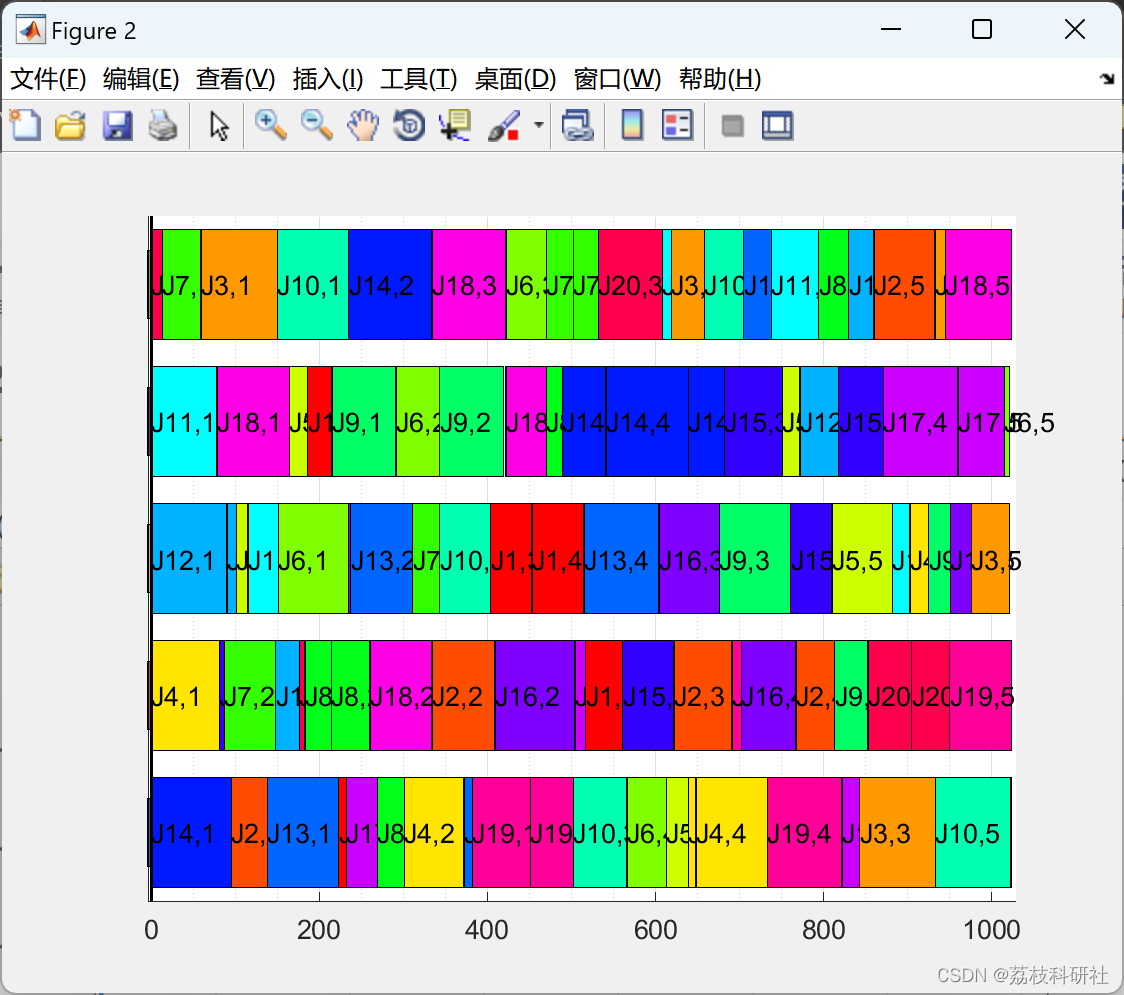
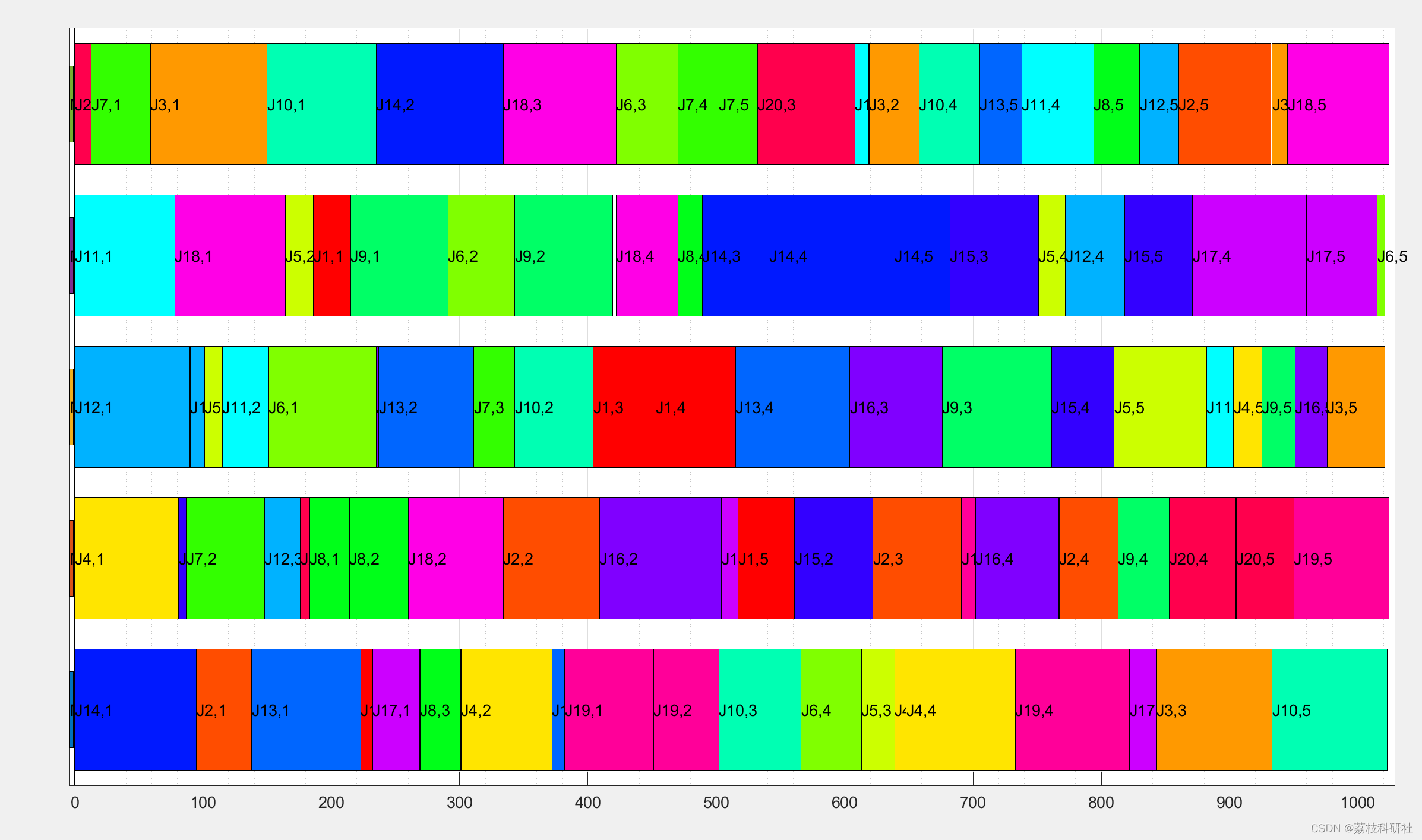
部分代码:
%Read data
function [numeroTrabajos, numeroMaquinas, numeroOperaciones, vectorNumOperaciones, vectorInicioOperaciones, vectorOperaciones, tablaTiempos, tablaMaquinasFactibles] = leerDatosProblema(nombreArchivo)
%The function reads the data table of the problem and returns the number of jobs, the number of machines,
%the vector with the number of operations per job, the vector with the previous operation number where each machine starts,
%the base vector with the number of operations per job, the base vector with the repeated operations for each job (1,...,1,2,...,2,...,n...,n...n),
%the table (operations/machines), the vector of the starting operation number of each job, the time table of each machine
%and the feasible machines for each operation
%Data format:
%in the first line there are (at least) 2 numbers: the first is the number of jobs and the second the number
%of machines (the 3rd is not necessary, it is the average number of machines per operation)
%Every row represents one job: the first number is the number of operations of that job, the second number
%(let's say k>=1) is the number of machines that can process the first operation; then according to k, there are
%k pairs of numbers (machine,processing time) that specify which are the machines and the processing times;
%then the data for the second operation and so on...
%Example: Fisher and Thompson 6x6 instance, alternate name (mt06)
%6 6 1
%6 1 3 1 1 1 3 1 2 6 1 4 7 1 6 3 1 5 6
%6 1 2 8 1 3 5 1 5 10 1 6 10 1 1 10 1 4 4
%6 1 3 5 1 4 4 1 6 8 1 1 9 1 2 1 1 5 7
%6 1 2 5 1 1 5 1 3 5 1 4 3 1 5 8 1 6 9
%6 1 3 9 1 2 3 1 5 5 1 6 4 1 1 3 1 4 1
%6 1 2 3 1 4 3 1 6 9 1 1 10 1 5 4 1 3 1
%first row = 6 jobs and 6 machines 1 machine per operation
%second row: job 1 has 6 operations, the first operation can be processed by 1 machine that is machine 3 with processing time 1.
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。

🌈4 Matlab代码、数据、文章讲解
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)