本文相关idea的代码出自:https://blog.csdn.net/weixin_38468167/article/details/108658531
实验内容:开发MapReduce算法,实现统计分析
具体操作流程:
第一步:给windows准备好JDK环境并配置系统环境变量,系统环境变量需要设置三个地方:CLASSPATH,JAVA_HOME(jdk路径)和PATH如图.


第二步,安装IDEA2019.3.3版本,并破解(这里只需将IDEA打开,并且把idea破解包(自行下载)拖至IDEA界面即可)
安装过程过于简单就不详细介绍了
第三步,给IDEA创建新项目,选择JDK版本(注意jdk版本必须与本机一致否则后面写代码会出错),如图:

第四步,编写函数
(1)MyMainClass(main函数,驱动函数)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MyMainClass {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//指定本job所在的jar包
wordCountJob.setJarByClass(MyMainClass.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
wordCountJob.setMapperClass(MyMapClass.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(MyReduceClass.class);
//设置map阶段输出的kv数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob, "hdfs://192.168.1.24:9000/mapreduce/input/mydata1");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://192.168.1.24:9000/mapreduce/output/"));
//提交job给hadoop集群
wordCountJob.waitForCompletion(true);
}
}
注意文件输入(FileInputFormat)那里,必须和自己在hdfs下mapreduce里所创建的文件路径一致,输出同理。
创建输入文件命令:
Hdfs dfs -mkdir -p /mapreduce/input(-p表示逐级创建)
创建输出文件命令:
Hdfs dfs -mkdir -p /mapreduce/output
(2)MyMapClass(分割,map节点)
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MyMapClass extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] words=line.split(",");
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
(3)MyReduceClass(reduce节点)
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduceClass extends Reducer <Text, IntWritable,Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total=0;
//遍历value,求和
for (IntWritable value:values){
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
(4)MyPartitionerClass(分页)
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.w3c.dom.Text;
public class MyPartitioner extends Partitioner <Text, IntWritable> {
@Override
public int getPartition(Text text, IntWritable intWritable, int i) {
return Math.abs(text.hashCode())%i;
}
}
第五步,新建一份需要统计的文本命名为mydata1,命名随意,里面的内容也随意,示例如图:

上传到input文件:命令 hdfs dfs -put mydata1 /mapreduce/input(只能云端查看文件)
第六步,把函数打包成jar包(IDEA上的简单操作,如下图)


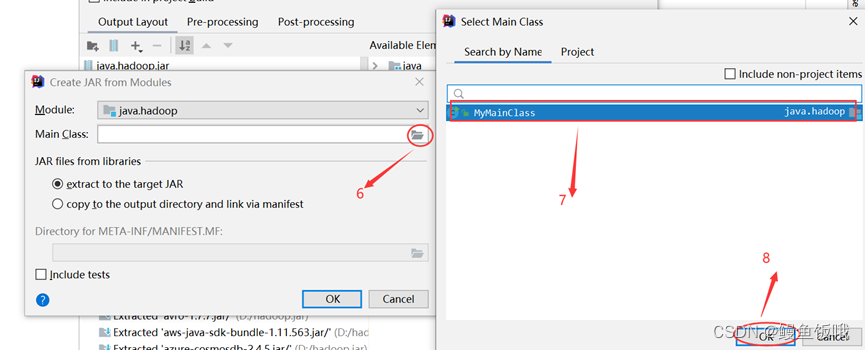
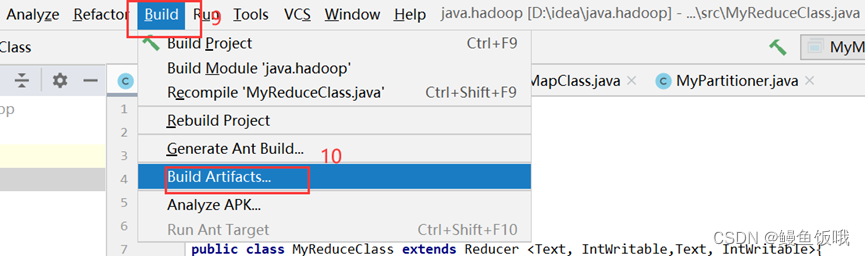
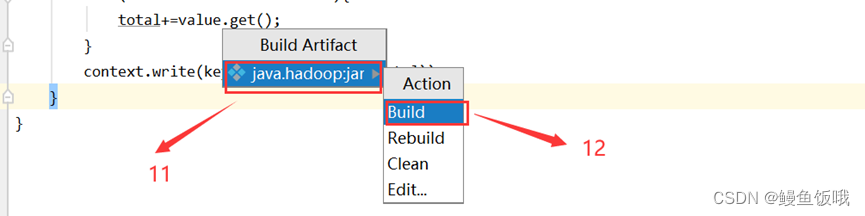
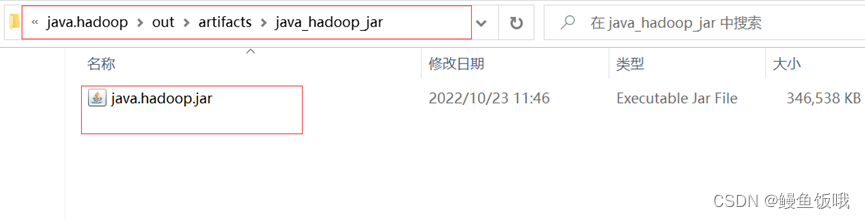
以上步骤完成就会在本地文件生成jar包,如下图:
第七步,将生成的jar包上传到hadoop(这里我用PowerShell远程传输到hadoop),命令:scp java.hadoop.jar Flume@192.168.1.24:/home/Flume(Flume为自己的用户,“:”后面是自己上传的虚拟机的路径)

第八步,启动生成的jar包程序
这里遇到一些问题,就是直接启动会报错,后来通过查询知道jar包上传时自动生成了一些文件,必须删掉,命令:zip -d java.hadoop.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF,如下图:

然后启动jar包:
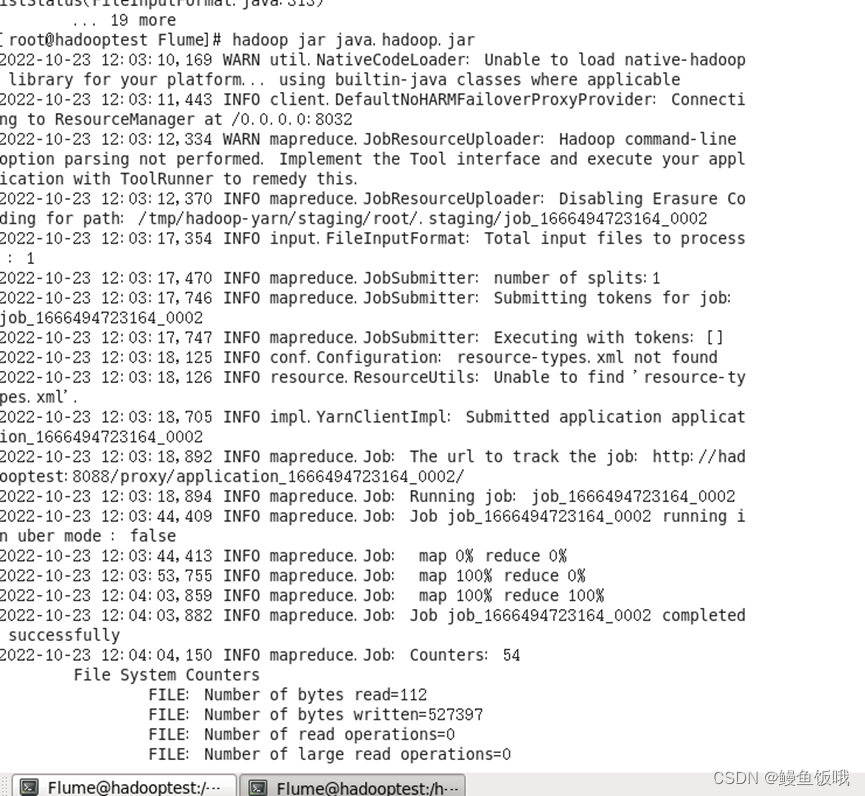
输出结果:命令:hdfs dfs -cat /mapreduce/output

端口查看:
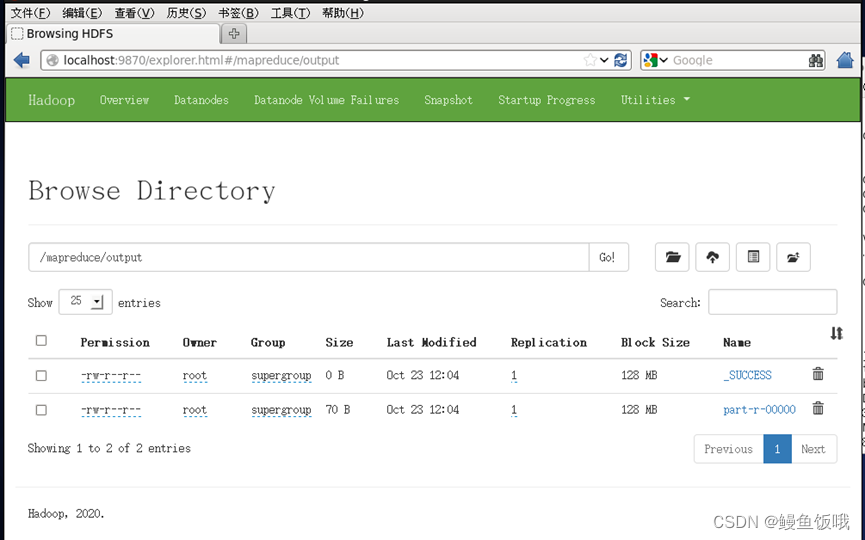 到这里就结束啦~!
到这里就结束啦~!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)