大致说明
这是一个基于efficientnet模型的图像分类方案。模型融入了cbam注意力机制模块,cutmix,CrossEntropyLabelSmooth,auto_augment等tricks帮助原生的effcientnet提高对图像数据集的分类准确度。不仅如此,还使用pyqt写了gui界面,可通过界面进行待预测图片的选择,并对选择的图片进行预测。
本次使用的数据集是海洋生物数据集,包含20类海洋生物。平均分类准确度接近96%,准确率在水下生物图像分类华南赛区位列榜一。
github Code(欢迎star):https://github.com/whisperLiang/Efficientnet_pytorch_cbam_gui.git
码云 Code(欢迎star):https://gitee.com/whisperliang/Efficientnet_pytorch_cbam_gui.git
论文:Classification of fine-grained species of marine organisms based on multi-scale fusion
最近私聊的人有一点多,如果实在自己不懂部署的,本人有偿帮忙
代码模块解析
- pip-requirements.txt 需要安装的库
- convert_dataset.py 整理csv文件格式的数据集
- creat_map.py 生成对应的标签映射
- train.py 训练主函数
- test_one.py 利用训练好的模型预测一张图片
- test_all.py 预测整个test文件里的图片
- test_tta. py 预测时加入tta,但是实际效果不好,不知道哪里出了问题
- sys_gui .py 运行时生成界面,可实现单张图片的读取,以及对单张图片的预测
- utils/mymodel.py 定义三个对象,分别是加入cbam的单模型b5、原生b5、以及多尺度模型b3_b6。可以通过修改模型名字导入不同模型进行训练
- MyEfficientNet/cbam_model.py 分别是SGE模块、通道注意力模块、空间注意力模块、CBAM融入EfficienNet和原生Efficientnet
使用指导
准备训练数据集
由于之前的博客对这一部分进行了比较详细的说明,因此此处不再赘述。
博客地址:参考第一部分即可
训练过程
安装相关的库
pip install -r pip-requirements.txt
train.py文件说明
- 对于数据集的读取,由于采用了十折交叉验证,因此需要用pandas处理数据集的路径和文件名,大家仔细对照读取的csv文件即可参考自己数据集路径和文件名进行修改。
- 对于超参数的调整,可以根据自身数据集的特点以及训练过程进行调整,特别需要注意的是训练类别的确定,默认是20类,记得根据自己的数量进行修改。
训练方案
模型方面采用的是efficientnet-b5,在原始b5模型中增加了cbam注意力模块,数据增强方面使用了随机裁切、翻转、auto_augment、随机擦除以及cutmix, 损失函数采用CrossEntropyLabelSmooth,训练策略方面采用了快照集成(snapshot)思想。
第一阶段训练,图像输入尺寸为465,使用LabelSmooth和cutmix,采用带学习率自动重启的CosineAnnealingWarmRestarts方法,获得5个模型快照,选择val_acc最高的模型,作为第一阶段的训练结果。
python train.py --epochs=100 --num_class=20 --image_size=456
第二阶段训练,图像输入尺寸为465,适当调整随机裁切和随机擦除的参数,增加weight_decay,在第一阶段模型的基础上训练获得5个模型快照,选择val_acc最高的模型,作为第二阶段的训练结果。
python train1.py --batch_size=10 --lr=5e-5 --epochs=100 --num_class=20\
--image_size=456 --weight_decay=1e-4 --resize_scale=0.6 --erasing_prob=0.3\
--model_path='checkpoint/best_model_456.pth'
第三阶段训练,图像输入尺寸为465,关闭cutmix,损失函数采用CrossEntropyLoss,在第二阶段模型的基础上训练获得5个模型快照,选择val_acc最高的模型,作为最终的训练结果。
python train1.py --batch_size=10 --epochs=100 --num_class=20 --lr=1e-6 --image_size=456\
--weight_decay=1e-4 --resize_scale=0.6 --erasing_prob=0.3 --cutmix\
--label_smooth --model_path='checkpoint/best_model_456.pth'
对图片进行预测
生成label_map
由于之前的博客对这一部分进行了比较详细的说明,因此此处不再赘述。
博客地址:参考第三部分即可
单张图片预测
通过修改test_one.py第16和17行的代码对分类的总类数量和待预测图片的路径进行修改
class_num = 20
image_dir = './test/8/0ca7e485031bf869a79e12efd6fd8bea.jpg'
如果大家暂时还没有训练好的模型,可以用我训练好的模型:已经训练好的20类海洋生物分类模型
我本来是放的免费下载的,但是不知道为啥博客总是给我强加C币,所以你们只能花点钱了。
修改文件中68行,对模型路径修改。
model_ft.load_state_dict(torch.load("./checkpoint/best_model_final.pth", map_location='cpu'))
预测结果展示:
 这里我们打印出了准确率前三的类别,它的预测结果为Solenostomus paradoxus
这里我们打印出了准确率前三的类别,它的预测结果为Solenostomus paradoxus
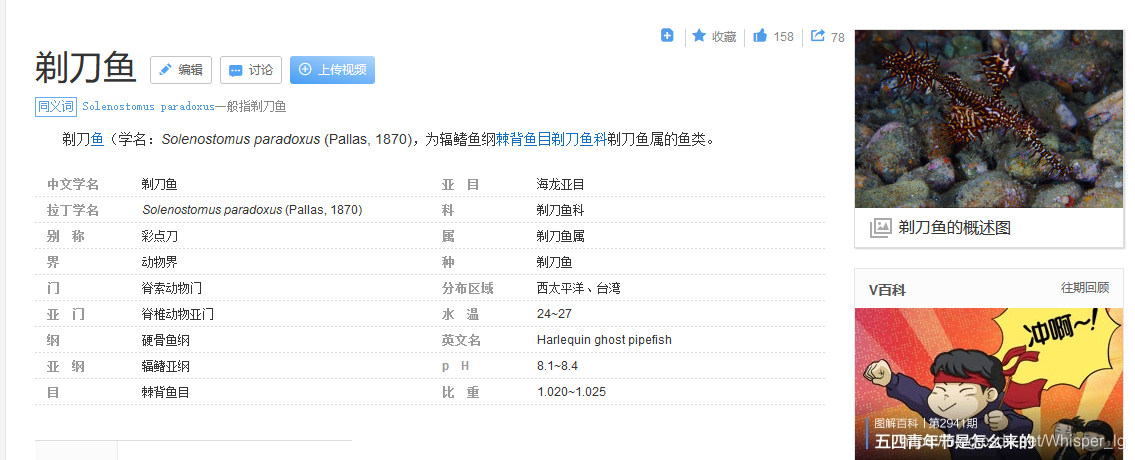

第一幅是通过预测结果百度的图片,第二幅是待预测的图片,对比图片可知结果完全正确。
文件夹里所有图片进行预测
这里我是先处理好所有待预测图片的路径,然后通过路径获取所有图片,然后对其进行预测,预测选用的平台是google colab。当时的平均精度大概是接近96%。由于需要将模型上传到google colab上需要花费比较多的时间,时间紧迫,所以这部分就不进行演示了。
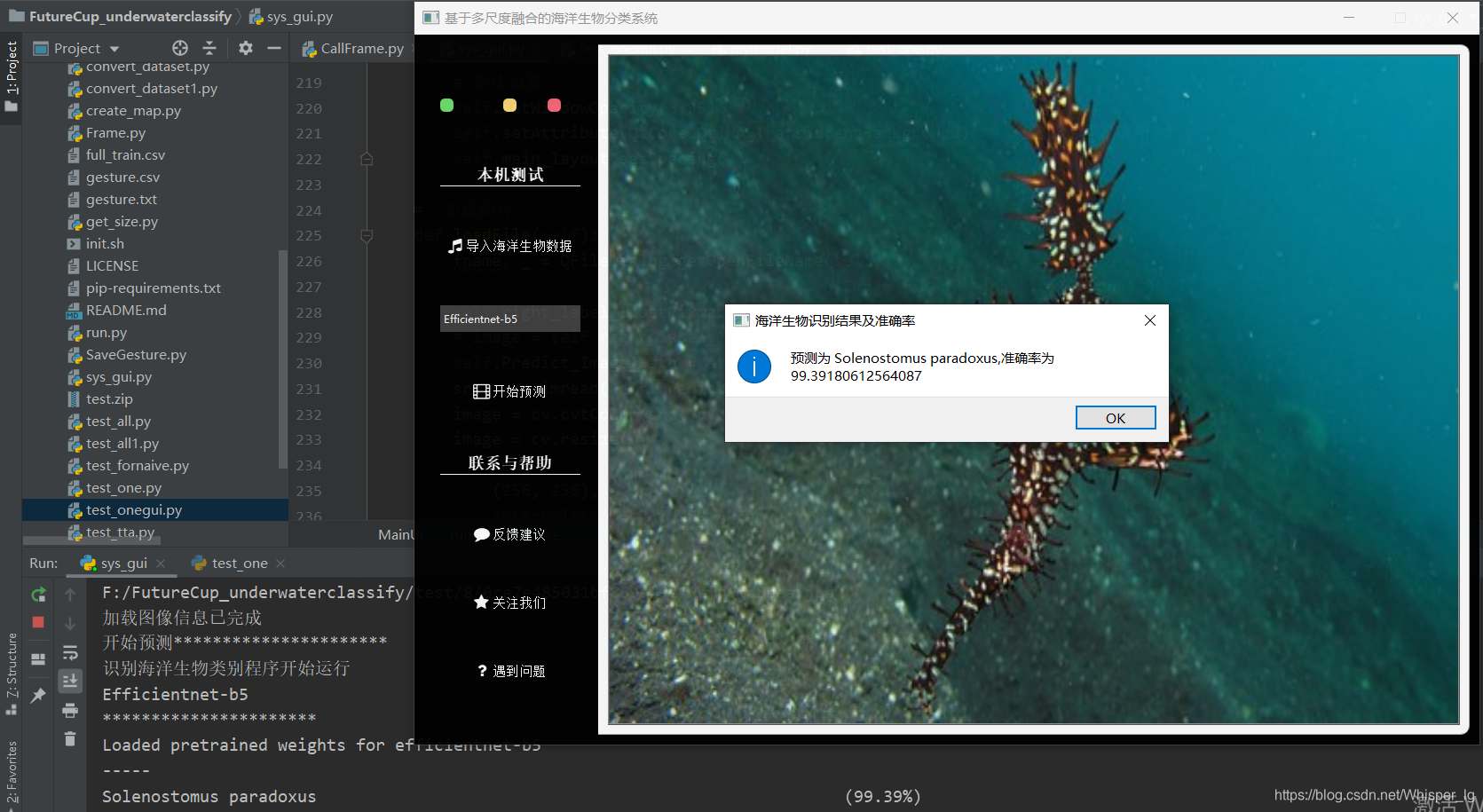
利用界面对单张图片进行预测
这里只对预测结果进行演示,需要改内部结构的,自行改动sys_gui.py。
系统初始界面

导入海洋数生物数据
 点击之后会弹出一个系统的文件夹界面,这个界面路径是自己可以修改的(255行),然后我们选择文件8里面的第一张图片,选中后图片将会显示在原来灰色的部分,控制台提醒图片加载结束。
点击之后会弹出一个系统的文件夹界面,这个界面路径是自己可以修改的(255行),然后我们选择文件8里面的第一张图片,选中后图片将会显示在原来灰色的部分,控制台提醒图片加载结束。

开始预测
点击开始预测,便会开始调用训练好的模型进行预测,预测结果将会通过弹窗的形式呈现,控制台进行相关的提示。
文件夹所有图片进行预测并将结果写入csv文件
由于之前比赛的代码没有好好保存,加上最近时间不够,所以这个功能就大家自己去完成吧,在“文件夹里所有图片进行预测”部分修改即可。大致就是将每张图片的名字和预测的结果都返回出来,然后将他们11对应的写入csv文件。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)