机器学习方法就是计算机根据已有的数据, 得出某个模型,然后利用此模型预测未来的一种方法。
机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。
1.回归算法
回归算法包括线性回归和逻辑回归
线性回归使用“最小二乘法”来求解,“最小二乘法”的思想是这样的,假设我们拟合出的直线代表数据的真实值,而观测到的数据代表拥有误差的值。为了尽可能减小误差的影响,需要求解一条直线使所有误差的平方和最小。最小二乘法将最优问题转化为求函数极值问题。函数极值在数学上我们一般会采用求导数为0的方法。但这种做法并不适合计算机,可能求解不出来,也可能计算量太大。
著名的“梯度下降”以及“牛顿法”就是数值计算中的经典算法,也非常适合来处理求解函数极值的问题。梯度下降法是解决回归模型中最简单且有效的方法之一。
逻辑回归属于分类算法,例如判断这封邮件是否是垃圾邮件,肿瘤是否是恶性的。
逻辑回归算法划出的分类线基本都是线性的,这意味着当两类之间的界线不是线性时,逻辑回归的表达能力就不足。
逻辑回归使用一个跃迁函数(如sigmoid函数)将任意数转化为0/1。
求解逻辑回归的损失函数使用极大似然估计方法找到损失函数,利用梯度下降法求解。
2.神经网络
神经网络包括一个输入层,一个输出层和0或多个隐藏层,每一层具有若干处理单元。
在神经网络中,每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。
求解神经网络的损失函数使用梯度下降法,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。反向传播算法是利用了神经网络的结构进行的计算。不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
神经网络发展历史:
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型MP。
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络(感知器)。但感知器连简单的异或问题都不能解决,如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。
1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题。但是神经网络仍然存在若干的问题:尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便,工程和研究人员对此多有抱怨。90年代中期,SVM的出现使神经网络进入冰河期。
2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词--“深度学习”。
3.SVM(支持向量机)
来源于统计学
一般SVM有下面三种:
- 硬间隔支持向量机(线性可分支持向量机):当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。
- 软间隔支持向量机:当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。
- 非线性支持向量机:当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
支持向量机算法从某种意义上来说是逻辑回归算法的强化:通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。
通过跟高斯“核”的结合,支持向量机可以表达出非常复杂的分类界线,从而达成很好的的分类效果。“核”事实上就是一种特殊的函数,最典型的特征就是可以将低维的空间映射到高维的空间。
对于硬间隔支持向量机,

上图为SVM的基本型,可以据此确定模型参数。(推导过程省略)
求解该基本型问题本身是一个凸二次规划(convex quadratic propgramming)问题,将该凸二次规划问题通过拉格朗日对偶性来解决。
利用拉格朗日对偶性得到对偶问题,利用KKT条件、SMO算法求解对偶问题来求出参数w、b。
优点:
SVM在中小量样本规模的时候容易得到数据和特征之间的非线性关系,可以避免使用神经网络结构选择和局部极小值问题,可解释性强,可以解决高维问题。
缺点:
SVM对缺失数据敏感,对非线性问题没有通用的解决方案,核函数的正确选择不容易,计算复杂度高,主流的算法可以达到O(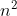 )的复杂度,这对大规模的数据是吃不消的。
)的复杂度,这对大规模的数据是吃不消的。
引用《机器学习入门好文,强烈推荐》
引用《逻辑回归(logistic regression)的本质——极大似然估计》
引用《神经网络浅讲:从神经元到深度学习》
引用《SVM》
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)