Git是怎么储存信息的
这里会用一个简单的例子让大家直观感受一下git是怎么储存信息的。
首先我们先创建两个文件
$ git init
$ echo '111' > a.txt
$ echo '222' > b.txt
$ git add *.txt
Git会将整个数据库储存在.git/目录下,如果你此时去查看.git/objects目录,你会发现仓库里面多了两个object。
$ tree .git/objects
.git/objects
├── 58
│ └── c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c
├── c2
│ └── 00906efd24ec5e783bee7f23b5d7c941b0c12c
├── info
└── pack
好奇的我们来看一下里面存的是什么东西
$ cat .git/objects/58/c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c
xKOR0a044K%
怎么是一串乱码?这是因为Git将信息压缩成二进制文件。但是不用担心,因为Git也提供了一个能够帮助你探索它的api git cat-file [-t] [-p], -t可以查看object的类型,-p可以查看object储存的具体内容。
$ git cat-file -t 58c9
blob
$ git cat-file -p 58c9
111
可以发现这个object是一个blob类型的节点,他的内容是111,也就是说这个object储存着a.txt文件的内容。
这里我们遇到第一种Git object,blob类型,它只储存的是一个文件的内容,不包括文件名等其他信息。然后将这些信息经过SHA1哈希算法得到对应的哈希值
58c9bdf9d017fcd178dc8c073cbfcbb7ff240d6c,作为这个object在Git仓库中的唯一身份证。
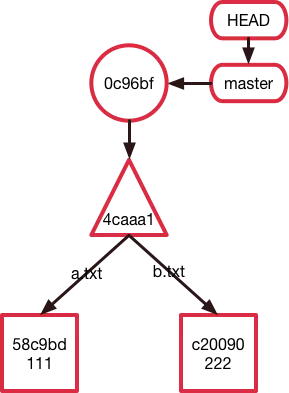
也就是说,我们此时的Git仓库是这样子的:

我们继续探索,我们创建一个commit。
$ git commit -am '[+] init'
$ tree .git/objects
.git/objects
├── 0c
│ └── 96bfc59d0f02317d002ebbf8318f46c7e47ab2
├── 4c
│ └── aaa1a9ae0b274fba9e3675f9ef071616e5b209
...
我们会发现当我们commit完成之后,Git仓库里面多出来两个object。同样使用cat-file命令,我们看看它们分别是什么类型以及具体的内容是什么。
$ git cat-file -t 4caaa1
tree
$ git cat-file -p 4caaa1
100644 blob 58c9bdf9d017fcd178dc8c0... a.txt
100644 blob c200906efd24ec5e783bee7... b.txt
这里我们遇到了第二种Git object类型——tree,它将当前的目录结构打了一个快照。从它储存的内容来看可以发现它储存了一个目录结构(类似于文件夹),以及每一个文件(或者子文件夹)的权限、类型、对应的身份证(SHA1值)、以及文件名。
此时的Git仓库是这样的:

$ git cat-file -t 0c96bf
commit
$ git cat-file -p 0c96bf
tree 4caaa1a9ae0b274fba9e3675f9ef071616e5b209
author lzane 李泽帆 1573302343 +0800
committer lzane 李泽帆 1573302343 +0800
[+] init
接着我们发现了第三种Git object类型——commit,它储存的是一个提交的信息,包括对应目录结构的快照tree的哈希值,上一个提交的哈希值(这里由于是第一个提交,所以没有父节点。在一个merge提交中还会出现多个父节点),提交的作者以及提交的具体时间,最后是该提交的信息。
此时我们去看Git仓库是这样的:

到这里我们就知道Git是怎么储存一个提交的信息的了,那有同学就会问,我们平常接触的分支信息储存在哪里呢?
$ cat .git/HEAD
ref: refs/heads/master
$ cat .git/refs/heads/master
0c96bfc59d0f02317d002ebbf8318f46c7e47ab2
在Git仓库里面,HEAD、分支、普通的Tag可以简单的理解成是一个指针,指向对应commit的SHA1值。
其实还有第四种Git object,类型是tag,在添加含附注的tag(git tag -a)的时候会新建,这里不详细介绍,有兴趣的朋友按照上文中的方法可以深入探究。
Git的三个分区
接下来我们来看一下Git的三个分区(工作目录、Index 索引区域、Git仓库),以及Git变更记录是怎么形成的。了解这三个分区和Git链的内部原理之后可以对Git的众多指令有一个“可视化”的理解,不会再经常搞混。
接着上面的例子,目前的仓库状态如下:

这里有三个区域,他们所储存的信息分别是:
-
工作目录 ( working directory ):操作系统上的文件,所有代码开发编辑都在这上面完成。
-
索引( index or staging area ):可以理解为一个暂存区域,这里面的代码会在下一次commit被提交到Git仓库。
-
Git仓库( git repository ):由Git object记录着每一次提交的快照,以及链式结构记录的提交变更历史。
我们来看一下更新一个文件的内容这个过程会发生什么事。

运行echo "333" > a.txt将a.txt的内容从111修改成333,此时如上图可以看到,此时索引区域和git仓库没有任何变化。

运行git add a.txt将a.txt加入到索引区域,此时如上图所示,git在仓库里面新建了一个blob object,储存了新的文件内容。并且更新了索引将a.txt指向了新建的blob object。
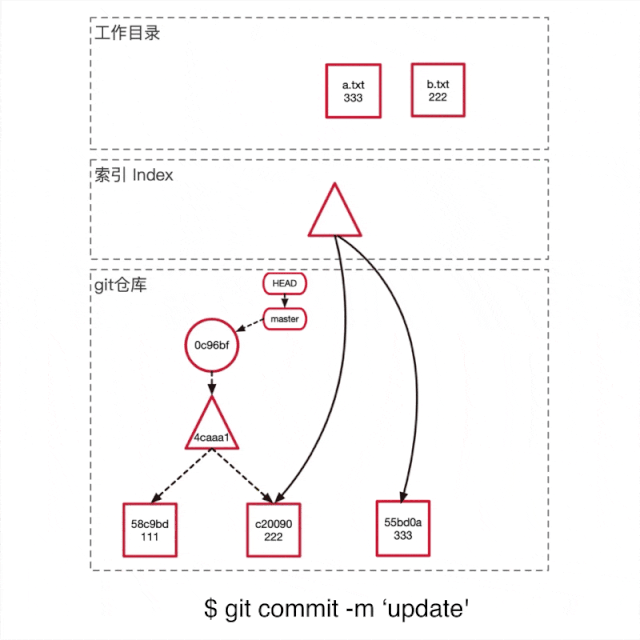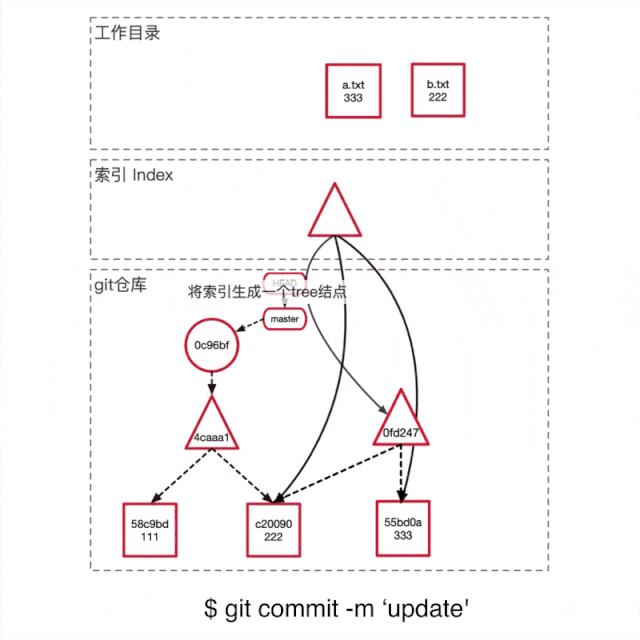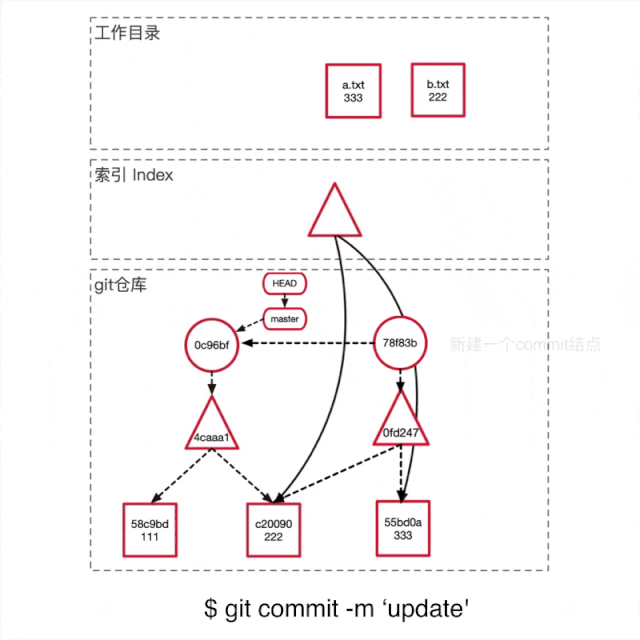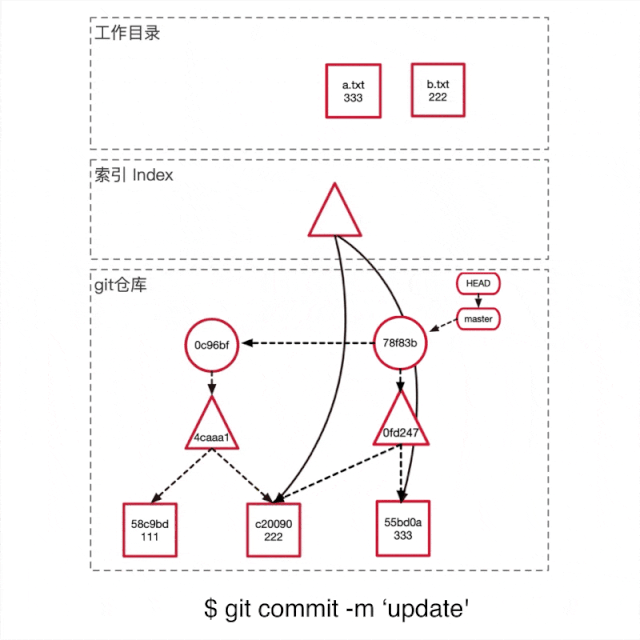
运行git commit -m 'update'提交这次修改。如上图所示
-
Git首先根据当前的索引生产一个tree object,充当新提交的一个快照。
-
创建一个新的commit object,将这次commit的信息储存起来,并且parent指向上一个commit,组成一条链记录变更历史。
-
将master分支的指针移到新的commit结点。
至此我们知道了Git的三个分区分别是什么以及他们的作用,以及历史链是怎么被建立起来的。基本上Git的大部分指令就是在操作这三个分区以及这条链。可以尝试的思考一下git的各种命令,试一下你能不能够在上图将它们“可视化”出来,这个很重要,建议尝试一下。
如果不能很好的将日常使用的指令“可视化”出来,推荐阅读 图解Git
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)