关键字:单链表、双链表、循环单链表、循环双链表
一、链表
1.为什么需要链表
顺序表的构建需要预先知道数据大小来申请连续的存储空间,而在进行扩充时又需要进行数据的搬迁,所以使用起来并不是很灵活。
链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
2.链表的定义
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是不像顺序表一样连续存储数据,而是在每一个节点(数据存储单元)里存放下一个节点的位置信息(即地址)。
链表的节点的结构如下:

二、单向链表
单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。
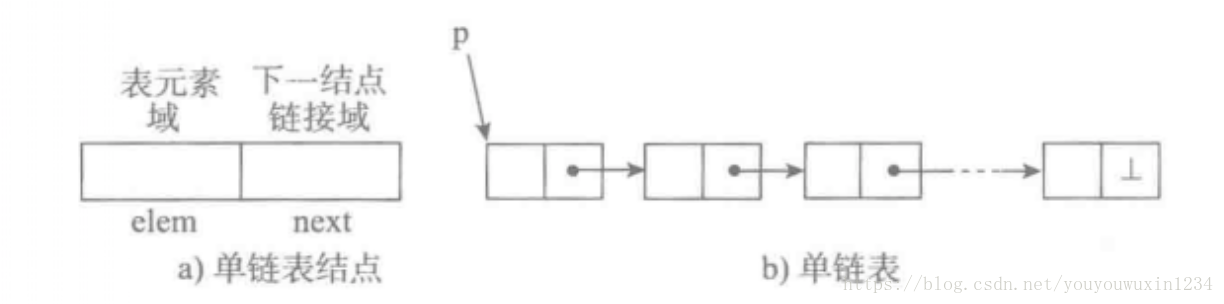
- 表元素域elem用来存放具体的数据。
- 链接域next用来存放下一个节点的位置(python中的标识)
- 变量p指向链表的头节点(首节点)的位置,从p出发能找到表中的任意节点。
节点实现
class SingleNode(object):
"""单链表的结点"""
def __init__(self,item):
self.item = item
self.next = None
单链表的操作
- is_empty() 链表是否为空
- length() 链表长度(列表当中有多少个节点)
- travel() 遍历整个链表
- add(item) 链表头部添加元素
- append(item) 链表尾部添加元素
- insert(pos, item) 指定位置添加元素
- remove(item) 删除节点
- search(item) 查找节点是否存在
单链表的实现
class SingleLinkList(object):
"""单链表"""
def __init__(self):
self._head = None
def is_empty(self):
"""判断链表是否为空"""
return self._head == None
"""第一种求链表长度的写法""" def length(self):
"""链表长度"""
# 判断特殊情况,链表是否为空 # 若为空,返回长度为0
if self.is_empty():
return 0
cur = self._head # 初始化count为0 count = 0
while cur != None:
count += 1
cur = cur.next
return count
"""第二种求链表长度的写法"""
def length(self):
"""链表长度"""
# 判断特殊情况,链表是否为空 # 若为空,返回长度为0 if self.is_empty(): return 0 # cur初始时指向头结点,相当于游标,用来移动遍历节点 cur =sel._head
# 初始化count为1 count = 1 # 当前节点的下一个节点不为None时 while cur.next != None: count += 1 cur = cur.next return countdef travel(self):
"""遍历整个链表"""
# cur初始时指向头结点,相当于游标,用来移动遍历节点 cur = self._head
while cur != None:
print (cur.item,end=" ")# end 表示不换行
cur = cur.next
print ""
头部添加元素

def add(self, item):
"""头部添加元素"""
node = SingleNode(item)
node.next = self._head
self._head = node
尾部添加元素
def append(self, item):
"""尾部添加元素"""
node = SingleNode(item)
if self.is_empty():另一种写法 if self._head == None:
self._head = node
else:
cur = self._head
while cur.next != None:
cur = cur.next
cur.next = node

# pos在指定位置插入新节点,item为新插入的节点 def insert(self, pos, item): """指定位置添加元素"""
if pos <= 0:
self.add(item)
elif pos > (self.length()-1):
self.append(item)
else:
node = SingleNode(item)
count = 0
pre = self._head
while count < (pos-1):
count += 1
pre = pre.next
node.next = pre.next
pre.next = node
删除节点

def remove(self,item):
"""删除节点"""
# cur指向头结点head cur = self._head
# 前驱结点pre初始化为None,不让pre指向任何节点 pre = None
while cur != None:
if cur.item == item:
if cur == self._head: # 或者写成if not pre:
self._head = cur.next
else:
pre.next = cur.next # 这段代码也符合要删除的节点是尾节点的情况
break #跳出while循环
else:
pre = cur
cur = cur.next
查找节点是否存在
def search(self,item):
"""链表查找节点是否存在,并返回True或者False"""
cur = self._head
while cur != None:#为什么不写cur.next != None,因为这样会丢失最后一个节点,导致其无法参与比较
if cur.item == item:
return True
else: cur = cur.next
return False
测试
if __name__ == "__main__":
ll = SingleLinkList() print(ll.is_empty()) print(ll.length())
ll.add(1)
ll.add(2)
ll.append(3)
ll.insert(2, 4)
print "length:",ll.length()
ll.travel()
print ll.search(3)
print ll.search(5)
ll.remove(1)
print "length:",ll.length()
ll.travel()
链表与顺序表的对比
链表失去了顺序表随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大,但对存储空间的使用要相对灵活。
链表与顺序表的各种操作复杂度如下所示:
| 操作 | 链表 | 顺序表 |
|---|
| 访问元素 | O(n) | O(1) |
| 在头部插入/删除 | O(1) | O(n) |
| 在尾部插入/删除 | O(n) | O(1) |
| 在中间插入/删除 | O(n) (n是要遍历的元素个数) | O(n) (n是顺序表要挪多少个位置元素) |
注意虽然表面看起来复杂度都是 O(n),但是链表和顺序表在插入和删除时进行的是完全不同的操作。链表的主要耗时操作是遍历查找,删除和插入操作本身的复杂度是O(1)。
顺序表查找很快,主要耗时的操作是拷贝覆盖。因为除了目标元素在尾部的特殊情况,顺序表进行插入和删除时需要对操作点之后的所有元素进行前后移位操作,只能通过拷贝和覆盖的方法进行。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)