VINS-Mono中的DBoW2关键代码注释
在阅读VINS-Mono源码时对DBoW2中代码顺手做的注释,怕以后会忘记,在这里记录一下,注释有不当之处,望各位大神看到后多多指点。理论参考高翔的《视觉SLAM十四讲》第12章的内容。这里找回环的方法是图像与数据库的比较,ORBSLAM中采用的方法是
图像与图像直接比较。
在pose_graph包里的pose_graph_node.cpp文件中,有这么一句代码,
posegraph.loadVocabulary(vocabulary_file);
这句代码包含的信息量巨大,其实现的功能就是将support_files文件夹下的brief_k10L6.bin文件构造为词袋模型的词典。这个词典的内容以树形结构存储,大意可以用下图表示,节点存储的权重和描述子是字典的核心内容。
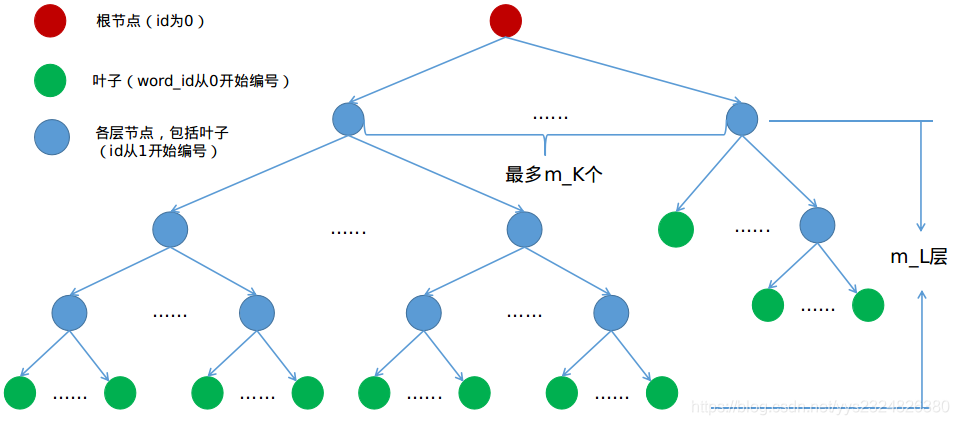
转到pose_graph.cpp文件中,
void PoseGraph::loadVocabulary(std::string voc_path)
{
voc = new BriefVocabulary(voc_path);
db.setVocabulary(*voc, false, 0);
}
typedef DBoW2::TemplatedVocabulary<DBoW2::FBrief::TDescriptor, DBoW2::FBrief>
BriefVocabulary;
typedef DBoW2::TemplatedDatabase<DBoW2::FBrief::TDescriptor, DBoW2::FBrief>
BriefDatabase;
上面的代码在DBoW文件夹下的DBoW2.h文件中,下面的代码在TemplatedVocabulary.h文件中,
template<class TDescriptor, class F>
TemplatedVocabulary<TDescriptor,F>::TemplatedVocabulary
(const std::string &filename): m_scoring_object(NULL)
{
loadBin(filename);
}
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::loadBin(const std::string &filename) {
m_words.clear();
m_nodes.clear();
std::ifstream ifStream(filename);
VINSLoop::Vocabulary voc;
voc.deserialize(ifStream);
ifStream.close();
m_k = voc.k;
m_L = voc.L;
m_scoring = (ScoringType)voc.scoringType;
m_weighting = (WeightingType)voc.weightingType;
createScoringObject();
m_nodes.resize(voc.nNodes + 1);
m_nodes[0].id = 0;
for(unsigned int i = 0; i < voc.nNodes; ++i)
{
NodeId nid = voc.nodes[i].nodeId;
NodeId pid = voc.nodes[i].parentId;
WordValue weight = voc.nodes[i].weight;
m_nodes[nid].id = nid;
m_nodes[nid].parent = pid;
m_nodes[nid].weight = weight;
m_nodes[pid].children.push_back(nid);
m_nodes[nid].descriptor = boost::dynamic_bitset<>(voc.nodes[i].descriptor, voc.nodes[i].descriptor + 4);
if (i < 5) {
std::string test;
boost::to_string(m_nodes[nid].descriptor, test);
}
}
m_words.resize(voc.nWords);
for(unsigned int i = 0; i < voc.nWords; ++i)
{
NodeId wid = (int)voc.words[i].wordId;
NodeId nid = (int)voc.words[i].nodeId;
m_nodes[nid].word_id = wid;
m_words[wid] = &m_nodes[nid];
}
}
词典构造工作完成。
下面的代码在TemplatedDatabase.h文件中
template<class TDescriptor, class F>
template<class T>
inline void TemplatedDatabase<TDescriptor, F>::setVocabulary
(const T& voc, bool use_di, int di_levels)
{
m_use_di = use_di;
m_dilevels = di_levels;
delete m_voc;
m_voc = new T(voc);
clear();
}
template<class TDescriptor, class F>
inline void TemplatedDatabase<TDescriptor, F>::clear()
{
m_ifile.resize(0);
m_ifile.resize(m_voc->size());
m_dfile.resize(0);
m_dBowfile.resize(0);
m_nentries = 0;
}
返回pose_graph.cpp文件中,
db.add(keyframe->brief_descriptors);
下面代码在TemplatedDatabase.h文件中
template<class TDescriptor, class F>
EntryId TemplatedDatabase<TDescriptor, F>::add(
const std::vector<TDescriptor> &features,
BowVector *bowvec, FeatureVector *fvec)
{
BowVector aux;
BowVector& v = (bowvec ? *bowvec : aux);
......
else
{
m_voc->transform(features, v);
return add(v);
}
}
转到TemplatedVocabulary.h文件中
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::transform(
const std::vector<TDescriptor>& features, BowVector &v) const
{
v.clear();
if(empty())
{
return;
}
LNorm norm;
bool must = m_scoring_object->mustNormalize(norm);
typename std::vector<TDescriptor>::const_iterator fit;
if(m_weighting == TF || m_weighting == TF_IDF)
{
for(fit = features.begin(); fit < features.end(); ++fit)
{
WordId id;
WordValue w;
transform(*fit, id, w);
if(w > 0) v.addWeight(id, w);
}
if(!v.empty() && !must)
{
const double nd = v.size();
for(BowVector::iterator vit = v.begin(); vit != v.end(); vit++)
vit->second /= nd;
}
}
else
{
for(fit = features.begin(); fit < features.end(); ++fit)
{
WordId id;
WordValue w;
transform(*fit, id, w);
if(w > 0) v.addIfNotExist(id, w);
}
}
if(must) v.normalize(norm);
}
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::transform(const TDescriptor &feature,
WordId &word_id, WordValue &weight, NodeId *nid, int levelsup) const
{
std::vector<NodeId> nodes;
typename std::vector<NodeId>::const_iterator nit;
const int nid_level = m_L - levelsup;
if(nid_level <= 0 && nid != NULL) *nid = 0;
NodeId final_id = 0;
int current_level = 0;
do
{
++current_level;
nodes = m_nodes[final_id].children;
final_id = nodes[0];
double best_d = F::distance(feature, m_nodes[final_id].descriptor);
for(nit = nodes.begin() + 1; nit != nodes.end(); ++nit)
{
NodeId id = *nit;
double d = F::distance(feature, m_nodes[id].descriptor);
if(d < best_d)
{
best_d = d;
final_id = id;
}
}
if(nid != NULL && current_level == nid_level)
*nid = final_id;
} while( !m_nodes[final_id].isLeaf() );
word_id = m_nodes[final_id].word_id;
weight = m_nodes[final_id].weight;
}
回到TemplatedDatabase.h文件中,
template<class TDescriptor, class F>
EntryId TemplatedDatabase<TDescriptor, F>::add(const BowVector &v,
const FeatureVector &fv)
{
EntryId entry_id = m_nentries++;
BowVector::const_iterator vit;
std::vector<unsigned int>::const_iterator iit;
if(m_use_di)
{
......
}
for(vit = v.begin(); vit != v.end(); ++vit)
{
const WordId& word_id = vit->first;
const WordValue& word_weight = vit->second;
IFRow& ifrow = m_ifile[word_id];
ifrow.push_back(IFPair(entry_id, word_weight));
}
return entry_id;
}
转到pose_graph.cpp文件中,
db.query(keyframe->brief_descriptors, ret, 4, frame_index - 50);
转到TemplatedDatabase.h文件中,
template<class TDescriptor, class F>
void TemplatedDatabase<TDescriptor, F>::query(
const std::vector<TDescriptor> &features,
QueryResults &ret, int max_results, int max_id) const
{
BowVector vec;
m_voc->transform(features, vec);
query(vec, ret, max_results, max_id);
}
template<class TDescriptor, class F>
void TemplatedDatabase<TDescriptor, F>::query(
const BowVector &vec,
QueryResults &ret, int max_results, int max_id) const
{
ret.resize(0);
switch(m_voc->getScoringType())
{
case L1_NORM:
queryL1(vec, ret, max_results, max_id);
break;
......
break;
}
}
以queryL1()函数为例,
template<class TDescriptor, class F>
void TemplatedDatabase<TDescriptor, F>::queryL1(const BowVector &vec,
QueryResults &ret, int max_results, int max_id) const
{
BowVector::const_iterator vit;
typename IFRow::const_iterator rit;
std::map<EntryId, double> pairs;
std::map<EntryId, double>::iterator pit;
for(vit = vec.begin(); vit != vec.end(); ++vit)
{
const WordId word_id = vit->first;
const WordValue& qvalue = vit->second;
const IFRow& row = m_ifile[word_id];
for(rit = row.begin(); rit != row.end(); ++rit)
{
const EntryId entry_id = rit->entry_id;
const WordValue& dvalue = rit->word_weight;
if((int)entry_id < max_id || max_id == -1 || (int)entry_id == m_nentries - 1)
{
double value = fabs(qvalue - dvalue) - fabs(qvalue) - fabs(dvalue);
pit = pairs.lower_bound(entry_id);
if(pit != pairs.end() && !(pairs.key_comp()(entry_id, pit->first)))
{
pit->second += value;
}
else
{
pairs.insert(pit,
std::map<EntryId, double>::value_type(entry_id, value));
}
}
}
}
ret.reserve(pairs.size());
for(pit = pairs.begin(); pit != pairs.end(); ++pit)
{
ret.push_back(Result(pit->first, pit->second));
}
std::sort(ret.begin(), ret.end());
if(max_results > 0 && (int)ret.size() > max_results)
ret.resize(max_results);
QueryResults::iterator qit;
for(qit = ret.begin(); qit != ret.end(); qit++)
qit->Score = -qit->Score/2.0;
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)