无监督学习论文阅读
刚开始接触这方面的内容,仅供参考。
Diversity Transfer Network for Few-Shot Learning (AAAI2020)[1]
这篇文章提出了一种新的深度聚类( DeepCluster):深度聚类采用聚类算法k-means对CNN络产生的特征进行迭代,将预测的聚类簇作为伪标签来计算损失并更新权重值。
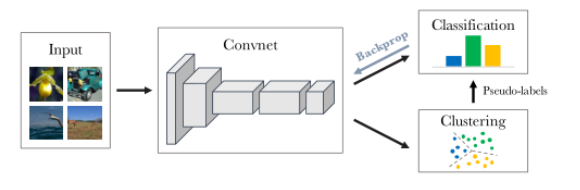
由于特征和聚类同时进行会产生平凡解,为此作者提出:
1、避免平凡解
当一个簇变空时,随机选择一个非空簇,并使用带有小随机扰动的质心作为空簇的新质心。然后,将属于非空簇的点重新分配给两个结果簇。
2、避免平凡参数
如果输入的数据分布不均匀,则学习的网络参数θ则会专门去区分它们,参数θ会导致网络只有相同的输出。解决方法是对输入数据进行重新采样使得分布均匀,或使用伪标签。
优点:可将网络的到的特征直接用于聚类,并且将聚类与分类结合,在训练中相互促进。且性能超过了当时SOTA无监督方法。
缺陷:在聚类前需要保存数据集中每个数据点的latent embedding ,这会带来大量额外的开销,内存消耗随着数据集大小而线性增长。
Unsupervised Image Classification for Deep Representation Learning[2]
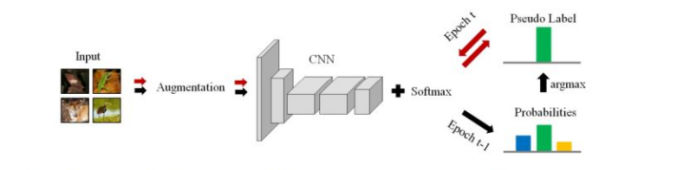
该文章基于deep clustering的无监督分类框架。
如上图所示:黑色箭头和红色箭头分别表示伪标签和特征学习的过程,两个过程反复交替实现,且当前Epoch的伪标签生成的前置过程由上一Epoch 的结果来更新,这种框架比Deep Cluster快两倍。为了解决在训练中产生的局部最优解的问题,在模型生成label时,使用不同的数据增强方式。
结果:在线性分类器上和其他无监督方法做对比,结果较接近deep cluster,优于self-supervised。

随后还做了一些更深入的实验对比,在采用其他网络结构的情况下,比simCLR和MoCov2要差,但是时间复杂度要比二者小。
**优点:**将伪标签生成和特征学习过程集合在一起,速度快于Deep Cluster,且内存开销较低。
**缺点:**在训练初期,由于CNN模型初始化是随机的,所以容易造成数据集中class为空的情况,此时需要将其余class中的数据分配给该class。
种无监督的训练方法容易陷入局部最优,所以需要在模型生成伪标签和训练的时候加入增强数据。
Local aggregation for unsupervised learning of visual embeddings(ICCV 2019)[3]
该文提出了一种新的无监督学习算法Local Agg,与DeepCluster相同之处在于同样使用迭代训练,但每次迭代的具体过程有所不同,并没有采用全局聚类,而是对样本的最近邻进行识别;其次,LA的优化了一个与DC不同的目标函数。在DC中通过神经网络将非线性的Embeddings输入到低维空间中。然后,迭代的识别每个样本在Embeddings Space的近邻(蓝色点)和背景近邻(黑色点)如下图所示,同时优化嵌入函数以增强局部聚集度,使得相似的样本距离减小,不同的样本距离增大,这个过程称为局部聚合(LA)。LA直接优化局部软聚类度量的目标函数,不需要额外的readout,大大提高了训练效率。最终在ImageNet、Places 205、PASCAL VOC中的目标检测上实现了最先进的无监督迁移学习性能。

在ImageNet数据集上实验结果如下:

优点:减少了计算所需要的开销。
缺陷:LA训练的RestNet-50,Embeddings的最近邻中,出现了错误的近邻,造成这一点的原因作者说是由于数据集的ImageNet,ill-posed造成的。
Unsupervised Learning of Probably Symmetric Deformable 3D Object(CVPR 2020)[4]
未完待续。。。。。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)