继续介绍文本生成图像的工作,本文给出的是CVPR 2018的文章《AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks》。它是StackGAN++的后续工作。
论文地址:https://arxiv.org/abs/1711.10485
源码地址:https://github.com/taoxugit/AttnGAN
一、相关工作
对GAN的相关理解:https://blog.csdn.net/zlrai5895/article/details/80648898
前作StackGAN的工作:http://blog.csdn.net/zlrai5895/article/details/81292167
前作StackGAN++的工作:https://blog.csdn.net/zlrai5895/article/details/81320447
二、基本思想
通过引入attentional generative network,AttnGAN可以通过关注自然语言描述中的相关单词来合成图像不同子区域的细粒度细节。此外,提出了一种deep attentional multimodal similarity model来计算细粒度图像-文本匹配损失,用于生成器的训练。
它首次表明 the layered attentional GAN 能够自动选择单词级别的condition来生成图像的不同部分。
三、 数据集
本次实验使用的数据集是加利福尼亚理工学院鸟类数据库-2011(CUB_200_2011)。
四、模型结构:
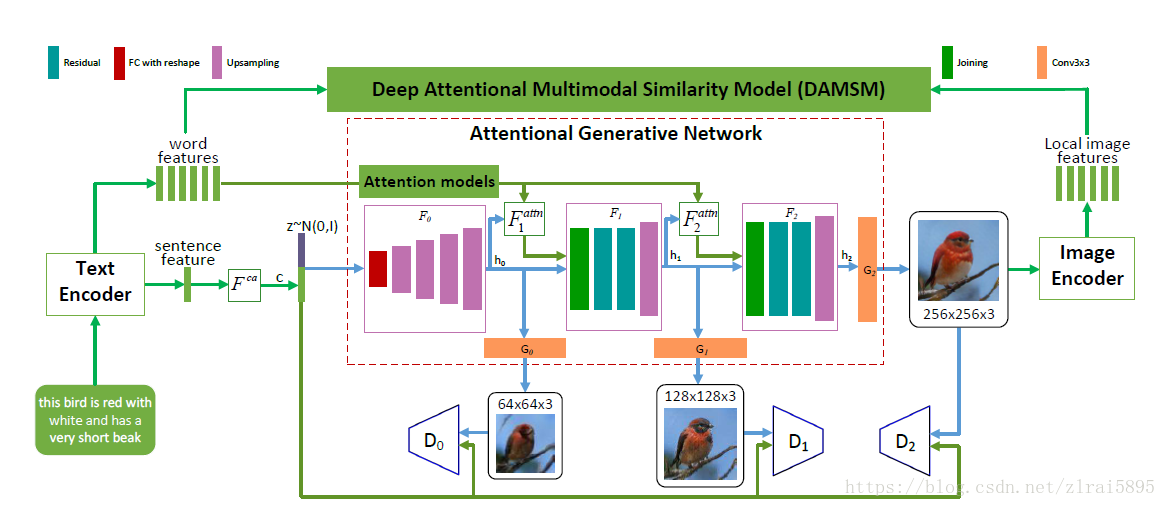
整个模型结构包括两部分
1 : attentional generative network
首先是使用text_encoder的得到sentence features 和word features.
首先是sentence features(sentence embedding)提取condition ,然后与z结合产生低分辨率的图像以及对应的图像特征h0.
每一层低分辨图像的特征被用来生成下一层的高分辨图像特征.过程如下:
word feature(e,大小为D*T) 与h0 (大小为D’*N)通过attention model ,输出大小为D’*N的张量
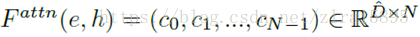
h1再进行下一层的操作.
所提出的AttnGAN的架构。 每个注意模型自动检索用于生成图像的不同子区域的条件(即,最相关的单词矢量); DAMSM为生成网络提供了细粒度的图像文本匹配损失。仍然以batch_size=2为例,配合代码对模型架构进行解析。首先载入第一个批次的数据:
imgs, captions, cap_lens, class_ids, keys = prepare_data(data)
#imgs[0]:[2,3,64,64] imgs[1]:[2,3,128,128] imgs[2]:[2,3,256,256]
#captions:[2,18] cap_lens:[2] 18,14 class_ids: [2] 87,160
#[u'087.Mallard/Mallard_0082_75954', u'160.Black_throated_Blue_Warbler/Black_Throated_Blue_Warbler_0027_104004']
可以看到相关的信息。一共两句话,id分别是87,160,每句话对应了三个尺度的图像。然后初始化语言模型的第一个隐藏态,调用text_encoder进行编码。
hidden = text_encoder.init_hidden(batch_size)
# words_embs: batch_size x nef x seq_len
# sent_emb: batch_size x nef
words_embs, sent_emb = text_encoder(captions, cap_lens, hidden)
1、text_encoder
text_encoder = RNN_ENCODER(self.n_words, nhidden=cfg.TEXT.EMBEDDING_DIM)
#self.n_words:5450 nhidden:256
class RNN_ENCODER(nn.Module):
def __init__(self, ntoken, ninput=300, drop_prob=0.5,
nhidden=128, nlayers=1, bidirectional=True):
super(RNN_ENCODER, self).__init__()
self.n_steps = cfg.TEXT.WORDS_NUM #18
self.ntoken = ntoken # size of the dictionary 5450
self.ninput = ninput # size of each embedding vector 300
self.drop_prob = drop_prob # probability of an element to be zeroed 0.5
self.nlayers = nlayers # Number of recurrent layers
self.bidirectional = bidirectional #True
self.rnn_type = cfg.RNN_TYPE
if bidirectional:
self.num_directions = 2 #双向编码
else:
self.num_directions = 1
# number of features in the hidden state
self.nhidden = nhidden // self.num_directions #128
self.define_module()
self.init_weights()
def forward(self, captions, cap_lens, hidden, mask=None):
# input: torch.LongTensor of size batch x n_steps
# --> emb: batch x n_steps x ninput
emb = self.drop(self.encoder(captions))#captions:[2,18]
#转化为嵌入向量 emb:[2,18,300]
#一共5040个单词 每每个单词用300维的向量表示
# Returns: a PackedSequence object
cap_lens = cap_lens.data.tolist() #[18,12]
emb = pack_padded_sequence(emb, cap_lens, batch_first=True)
# #hidden and memory (num_layers * num_directions, batch, hidden_size):
# tensor containing the initial hidden state for each element in batch.
# #output (batch, seq_len, hidden_size * num_directions)
# #or a PackedSequence object:
# tensor containing output features (h_t) from the last layer of RNN
output, hidden = self.rnn(emb, hidden)
# PackedSequence object
# --> (batch, seq_len, hidden_size * num_directions)
output = pad_packed_sequence(output, batch_first=True)[0]
# output = self.drop(output)
# --> batch x hidden_size*num_directions x seq_len
words_emb = output.transpose(1, 2)
# --> batch x num_directions*hidden_size
if self.rnn_type == 'LSTM':
sent_emb = hidden[0].transpose(0, 1).contiguous()
else:
sent_emb = hidden.transpose(0, 1).contiguous()
sent_emb = sent_emb.view(-1, self.nhidden * self.num_directions)
return words_emb, sent_emb
得到的word_emb为[2,256,18] sent_emb:[2,256]
num_words = words_embs.size(2) #每句话18个词
2、image_encoder
它只在最后一个生成器上被使用,作者尝试把它用在每一个生成器上,但是效果并不好,而且增加了计算成本.
image_encoder用于最后提取256*256图像的图像特征,输入是256*256的图像,输出是2048维的向量。采用的是inceptionv3的网络架构。如下所示:
image_encoder = CNN_ENCODER(cfg.TEXT.EMBEDDING_DIM)# 256
self.emb_features = conv1x1(768, self.nef) #self.enf:256
self.emb_cnn_code = nn.Linear(2048, self.nef)
def forward(self, x):
features = None
# --> fixed-size input: batch x 3 x 299 x 299
x = nn.Upsample(size=(299, 299), mode='bilinear')(x)
# 299 x 299 x 3
x = self.Conv2d_1a_3x3(x)
# 149 x 149 x 32
x = self.Conv2d_2a_3x3(x)
# 147 x 147 x 32
x = self.Conv2d_2b_3x3(x)
# 147 x 147 x 64
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 73 x 73 x 64
x = self.Conv2d_3b_1x1(x)
# 73 x 73 x 80
x = self.Conv2d_4a_3x3(x)
# 71 x 71 x 192
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 35 x 35 x 192
x = self.Mixed_5b(x)
# 35 x 35 x 256
x = self.Mixed_5c(x)
# 35 x 35 x 288
x = self.Mixed_5d(x)
# 35 x 35 x 288
x = self.Mixed_6a(x)
# 17 x 17 x 768
x = self.Mixed_6b(x)
# 17 x 17 x 768
x = self.Mixed_6c(x)
# 17 x 17 x 768
x = self.Mixed_6d(x)
# 17 x 17 x 768
x = self.Mixed_6e(x)
# 17 x 17 x 768
# image region features
features = x
# 17 x 17 x 768
x = self.Mixed_7a(x)
# 8 x 8 x 1280
x = self.Mixed_7b(x)
# 8 x 8 x 2048
x = self.Mixed_7c(x)
# 8 x 8 x 2048
x = F.avg_pool2d(x, kernel_size=8)
# 1 x 1 x 2048
# x = F.dropout(x, training=self.training)
# 1 x 1 x 2048
x = x.view(x.size(0), -1)
# 2048
# global image features
cnn_code = self.emb_cnn_code(x)
# 512
if features is not None:
features = self.emb_features(features)
return features, cnn_code
3、生成器网络
第一个生成器与StackGAN的第一个生成器相同,后面的不同。
(1)第一个生成器
输入sent_emb,得到[2,32,64,64]的h_code1和[2,3,64,64]的fake_img1。(这时候还没用到word embedding)
c_code, mu, logvar = self.ca_net(sent_emb) #由sentence_embeeding生成condition
if cfg.TREE.BRANCH_NUM > 0:
h_code1 = self.h_net1(z_code, c_code)#z+c------h0
fake_img1 = self.img_net1(h_code1) #h0---fake_img1
fake_imgs.append(fake_img1) #和stackgan++类似
if cfg.TREE.BRANCH_NUM > 0:
self.h_net1 = INIT_STAGE_G(ngf * 16, ncf)
self.img_net1 = GET_IMAGE_G(ngf)
class INIT_STAGE_G(nn.Module): #可以看出 和stackgan的第一个生成器类似
def forward(self, z_code, c_code):
"""
:param z_code: batch x cfg.GAN.Z_DIM
:param c_code: batch x cfg.TEXT.EMBEDDING_DIM
:return: batch x ngf/16 x 64 x 64
"""
c_z_code = torch.cat((c_code, z_code), 1)
# state size ngf x 4 x 4
out_code = self.fc(c_z_code)
out_code = out_code.view(-1, self.gf_dim, 4, 4)
# state size ngf/3 x 8 x 8
out_code = self.upsample1(out_code)
# state size ngf/4 x 16 x 16
out_code = self.upsample2(out_code)
# state size ngf/8 x 32 x 32
out_code32 = self.upsample3(out_code)
# state size ngf/16 x 64 x 64
out_code64 = self.upsample4(out_code32)
return out_code64
class GET_IMAGE_G(nn.Module):
def __init__(self, ngf):
super(GET_IMAGE_G, self).__init__()
self.gf_dim = ngf #32
self.img = nn.Sequential(
conv3x3(ngf, 3),
nn.Tanh()
)
def forward(self, h_code):
out_img = self.img(h_code)
return out_img
(2)后面的生成器
我们只给出第二个生成器的部分,其他生成器与它类似。输入上一层的h_code以及c_code,word_embs,mask.mask是个啥不知道,在论文和源码中均未找到解释。大小为[2,18].返回[2,32,128,128]的h_code2和[2,18,64,64]的attn。
if cfg.TREE.BRANCH_NUM > 1:
h_code2, att1 = self.h_net2(h_code1, c_code, word_embs, mask) #att1:
#h_code2:[2,32,128,128]
fake_img2 = self.img_net2(h_code2) #[2, 3, 128, 128]
fake_imgs.append(fake_img2)
if att1 is not None:
att_maps.append(att1)
if cfg.TREE.BRANCH_NUM > 1:
self.h_net2 = NEXT_STAGE_G(ngf, nef, ncf)
self.img_net2 = GET_IMAGE_G(ngf)
class NEXT_STAGE_G(nn.Module):
def __init__(self, ngf, nef, ncf):
super(NEXT_STAGE_G, self).__init__()
self.gf_dim = ngf
self.ef_dim = nef
self.cf_dim = ncf
self.num_residual = cfg.GAN.R_NUM
self.define_module()
def _make_layer(self, block, channel_num):
layers = []
for i in range(cfg.GAN.R_NUM):
layers.append(block(channel_num))
return nn.Sequential(*layers)
def define_module(self):
ngf = self.gf_dim
self.att = ATT_NET(ngf, self.ef_dim)
self.residual = self._make_layer(ResBlock, ngf * 2)
self.upsample = upBlock(ngf * 2, ngf)
def forward(self, h_code, c_code, word_embs, mask):
"""
h_code1(query): batch x idf x ih x iw (queryL=ihxiw) [2,32,64,64]
word_embs(context): batch x cdf x sourceL (sourceL=seq_len) [2,256,18]
c_code1: batch x idf x queryL [2,100]
att1: batch x sourceL x queryL
"""
self.att.applyMask(mask) #mask:[2,18]
c_code, att = self.att(h_code, word_embs) #c_code:[2,32,64,64] att:[2,18,64,64]
h_c_code = torch.cat((h_code, c_code), 1) #h_c_code:[2,64,64,64]
out_code = self.residual(h_c_code)
# state size ngf/2 x 2in_size x 2in_size
out_code = self.upsample(out_code) #[2,32,128,128]
return out_code, att
4、鉴别器网络
与StackGAN++类似,不同分辨率的图像配备了不同的鉴别器。
与StackGAN++中给出的鉴别器略有不同。每一个鉴别器比StackGAN++对应的鉴别器多出了一段相同的代码。
以D_NET64为例:
StackGAN++ :
class D_NET64(nn.Module):
def __init__(self):
super(D_NET64, self).__init__()
self.df_dim = cfg.GAN.DF_DIM #64
self.ef_dim = cfg.GAN.EMBEDDING_DIM #128
self.define_module()
def define_module(self):
ndf = self.df_dim
efg = self.ef_dim
self.img_code_s16 = encode_image_by_16times(ndf)
self.logits = nn.Sequential(
nn.Conv2d(ndf * 8, 1, kernel_size=4, stride=4),
nn.Sigmoid())
if cfg.GAN.B_CONDITION:
self.jointConv = Block3x3_leakRelu(ndf * 8 + efg, ndf * 8)
self.uncond_logits = nn.Sequential(
nn.Conv2d(ndf * 8, 1, kernel_size=4, stride=4),
nn.Sigmoid())
def forward(self, x_var, c_code=None):
x_code = self.img_code_s16(x_var)#x_var:[2,3,64,64] x_code:[2,512,4,4]
if cfg.GAN.B_CONDITION and c_code is not None:
c_code = c_code.view(-1, self.ef_dim, 1, 1)#输入c_code:[2,128] 输出c_code:[2,128,1,1]
c_code = c_code.repeat(1, 1, 4, 4)#c_code:[2,128,4,4]
# state size (ngf+egf) x 4 x 4
h_c_code = torch.cat((c_code, x_code), 1)# 输出h_c_code:[2,640,4,4]
# state size ngf x in_size x in_size
h_c_code = self.jointConv(h_c_code)#输出h_c_code:[2,512,4,4]
else:
h_c_code = x_code
output = self.logits(h_c_code)#4*4的卷积 output:[2,1,1,1]
if cfg.GAN.B_CONDITION:
out_uncond = self.uncond_logits(x_code)
return [output.view(-1), out_uncond.view(-1)]
else:
return [output.view(-1)]
AttGAN:
class D_NET64(nn.Module):
def __init__(self, b_jcu=True):
super(D_NET64, self).__init__()
ndf = cfg.GAN.DF_DIM #64
nef = cfg.TEXT.EMBEDDING_DIM #256
self.img_code_s16 = encode_image_by_16times(ndf)
if b_jcu:
self.UNCOND_DNET = D_GET_LOGITS(ndf, nef, bcondition=False)
else:
self.UNCOND_DNET = None
self.COND_DNET = D_GET_LOGITS(ndf, nef, bcondition=True)
def forward(self, x_var):
x_code4 = self.img_code_s16(x_var) # x_var:[2,32,64,64]
return x_code4 # [2,512,4,4]
其中的encode_image_by_16times()函数:
# Downsale the spatial size by a factor of 16
def encode_image_by_16times(ndf):
encode_img = nn.Sequential(
# --> state size. ndf x in_size/2 x in_size/2
nn.Conv2d(3, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# --> state size 2ndf x x in_size/4 x in_size/4
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# --> state size 4ndf x in_size/8 x in_size/8
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# --> state size 8ndf x in_size/16 x in_size/16
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True)
)
return encode_img
获得的x_code4输入D_GET_LOGITS.
class D_GET_LOGITS(nn.Module):
def __init__(self, ndf, nef, bcondition=False):
super(D_GET_LOGITS, self).__init__()
self.df_dim = ndf
self.ef_dim = nef
self.bcondition = bcondition
if self.bcondition:
self.jointConv = Block3x3_leakRelu(ndf * 8 + nef, ndf * 8)
self.outlogits = nn.Sequential(
nn.Conv2d(ndf * 8, 1, kernel_size=4, stride=4),
nn.Sigmoid())
def forward(self, h_code, c_code=None): #[2, 512, 4, 4]
if self.bcondition and c_code is not None:
# conditioning output
c_code = c_code.view(-1, self.ef_dim, 1, 1) #[c_code]:[2,256,1,1]
c_code = c_code.repeat(1, 1, 4, 4) #c_code:[2,256,4,4]
# state size (ngf+egf) x 4 x 4
h_c_code = torch.cat((h_code, c_code), 1) #[2,768,4,4]
# state size ngf x in_size x in_size
h_c_code = self.jointConv(h_c_code) #[2,512,4,4]
else:
h_c_code = h_code
output = self.outlogits(h_c_code) #[2,1,1,1]
return output.view(-1)
最终得到[2,1,1,1]的output。
5 DAMSM
这一部分被用来检测图像文本的匹配程度,生成相应的损失函数.
它包括两部分:
text_encoder和image encoder
(1)image encoder即为刚才介绍的第二部分,它的输出是一个2048维的向量,代表了整个图像的特征 . f'
此外,对输入的图像提取得到768*17*17的特征,reshape成768*289.用来代表local feature . f
289代表region的数目,768代表的是维度.
由f'得到v' 由 f得到v
(2)the text encoder
是一个双向LSTM.输出sentence embedding和word embedding (e :D*T)
详情见网络结构的第一部分.
s=e.transpose()*v
这样 就把图像和句子结合在了一起.s(i,j)代表了句子中的第i个单词和第图像中第j个区域的相关性.
最后s和h结合得到相关损失
五、损失函数和训练过程
损失函数包括三部分:
生成器损失+鉴别器损失+DAMSM损失
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)