《MUTAN: Multimodal Tucker Fusion for Visual Question Answering》阅读笔记
一、研究背景
Bilinear models在视觉问答(VQA)任务中进行信息融合提供了一个吸引人的框架。 它们有助于学习question meaning 和 visual concepts in the image之间的高层次关系,但它们存在高维度问题。 论文引入MUTAN,a multimodal tensor-based Tucker decomposition ,有效地参数化visual和text表示之间的双线性相互作用。 除了Tucker framework之外,还设计了一种基于矩阵的低阶分解来明确约束交互等级。 使用MUTAN,可以控制合并方案的复杂性,同时保持良好的可解释融合关系。
二、文章贡献
1、VQA的新融合方案依赖于基于Tucker张量的分解,包括分解为三个矩阵和核心张量。 论文中证明了MUTAN融合方案推广了最新的双线性模型,即MCB [5]和MLB [8],同时具有更强的表现力;
2、Additional structured sparsity 约束核心张量以进一步控制模型参数的数量。 这在训练期间充当正则化器并防止过度拟合,使我们能够更灵活地调整输入/输出预测;
3、在最常使用的数据集VQA上取得很好的结果, 文中还表明MUTAN在相同的设置的条件下,结果优于MCB 和MLB ,并且当与MLB结合时可以进一步提高性能,验证两种方法之间的互补可能性。
三、实验模型
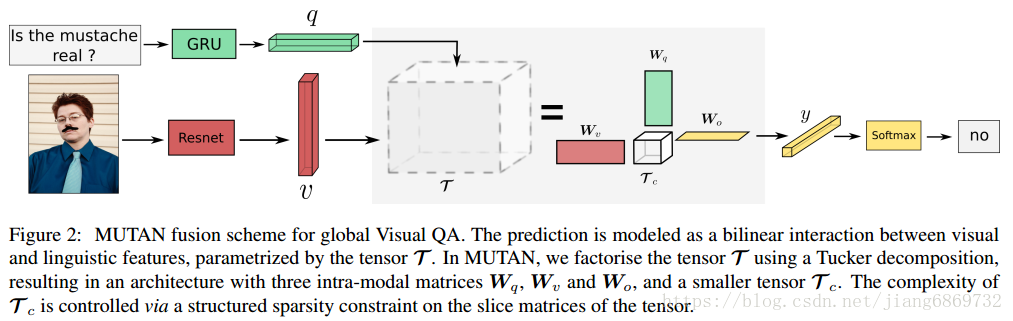
text特征提取: fully convolutional neural network(ResNet-152) 提取图像特征,得到v;
**image特征提取:**a GRU recurrent network 提取文本特征,得到q;
Fusion and Bilinear models

在MUTAN中,我们使用Tucker decomposition对全张量T进行分解。 通过构造第二张量T c来完成我们的分解(见图2中的灰色框),以保持输入/输出维度的灵活性,同时保持参数的数量易处理。
Tucker decomposition


Multimodal Tucker Fusion



Tensor sparsity



四、实验结论
我们的模型将Tucker decomposition与low-rank matrix constraint相结合。 它旨在控制full bilinear交互的复杂性。 MUTAN将交互张量分解为可解释的元素,并允许轻松控制模型的表达性。 我们还展示了Tucker分解框架如何概括最具竞争力的VQA架构。 MUTAN在最新的VQA数据集上进行评估,达到了最新技术水平。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)