AUTOSEM:多任务学习中的自动任务选择和自动混合(一)背景知识
知识结构:
AUTOSEM: Automatic Task Selection and Mixing in Multi-Task Learning[1]
1) Supervised Learning of Universal Sentence Representations from Natural Language Inference Data[2]
2)Learning to select data for transfer learning with Bayesian Optimization[6]
(1)A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning[3]
(2)Effective Measures of Domain Similarity for Parsing[4]
(3)Domain Adaptation Using Domain Similarity- and Domain Complexity-based Instance Selection for Cross-domain Sentiment Analysis[5]
本文知识点结构如上述知识导图所示,在[1]中使用了许多已经存在的新知识[2-6],要想客观的了解[1]中的知识需要对其中所使用到的知识点、知识结构有所了解。在[2]中介绍了[1]中所使用的学习框架,这个框架主要是用来做word enbading 问题的。而[6]是一篇经典的迁移学习中使用贝叶斯优化来进行特征、数据选择的文章,给作者了很多的启发。而[3-5]又是[6]中的几个比较重要的使用方法。所以由思维导图可以看出整个文章的思想结构。
知识点总结:
这里介绍一种最新的多任务学习框架,这种方法采用了多臂赌博机架构,主任务和多个辅助任务作为多臂赌博机的各个臂,通过带汤普森优化的方法优化多臂赌博机的臂上权重。这种方式可以自动的选择对主任务有帮助的辅助任务,同时可以帮助人们通过实验间接了解不同数据之间的相似度关系。同大多数迁移学习方式采用数据之间的度量来衡量多个数据集之间的距离不同,本文介绍的方法将通过辅助任务对主任务的辅助效果作为评价标准。通过单一度量(如常用的MMD距离)或者是多个度量统一考虑以及通过学习自适应度量这三种基本方式在迁移学习中具有大量的应用,但这种方式具有一些问题:采用度量的方法找到最合适的度量再对主任务进行训练的方法没有考虑到主任务模型在训练过程中的变化问题,在一个模型训练过程中,不同阶段可能不同的辅助任务对主任务模型的帮助程度不同。同样的,在一个数据集中,不同的数据对主任务的帮助不同,我们不能使用一个固定的度量来衡量整个训练过程中辅助任务的选择。同时主任务、辅助任务的混合率也同样是一个很严重的问题,为了选择合适的混合率,我们需要进行多次的采样和实验来确定,这是一个expensive-cost 方程,对于这种问题,我们习惯于采用贝叶斯优化的方法来对模型进行优化,从而找到最合适的混合率。
基本模型:
本文基本模型引用自[2],模型输入如图1输入两个句子,通过将两个句子转化为文字向量,之后用神经网络分别提取特征,将特征进行整合之后分类即可。
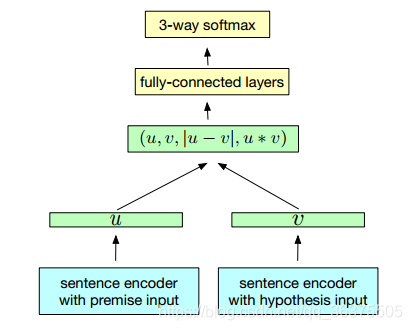
图1
与[2]中的模型不同的是,在本文中面对的是一个多任务学习问题所以对图1中的模型在分类器部分经行扩展,在全连接层之后分出多个带全连层的分类器,如图2.同时增加BLSTM层作为特征提取的工具进行分类。
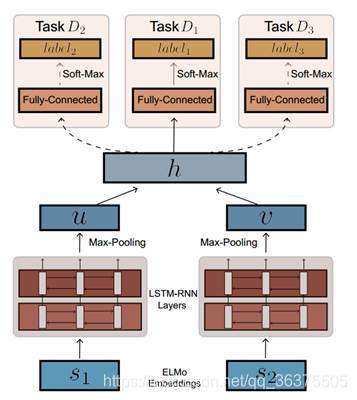
图2
贝叶斯优化:
贝叶斯优化的主要目的是与大部分机器学习算法类似,学习模型的表达形式 ,在一定范围内求一个函数的最大(小)值。
max
π
=
x
f
(
x
)
\max _{\pi=x} f(x)
maxπ=xf(x)
这类
f
(
x
)
f(x)
f(x)往往很特殊:
- 没有解析表达或者形式未知,故而没办法用跟梯度有关的优化方法;
-
f
(
x
)
f(x)
f(x) 值的确定会受到一些外界干预(如人的干预)。
贝叶斯优化算法核心步骤如下:
(1).通过样本点
D
=
{
(
x
1
:
,
y
1
:
)
}
D=\left\{\left(x_{1 :}, y_{1 :}\right)\right\}
D={(x1:,y1:)}对高斯过程 进行估计和更新。(后简称高斯过程)
(2).通过提取函数
a
(
x
)
a(x)
a(x) (acquisition function)来指导新的采样。(后简称提取函数)
高斯过程:假设我们需要估计的模型服从高斯过程,即:
f
(
x
)
∼
G
P
(
E
(
x
)
,
K
(
x
,
x
′
)
)
f(x) \sim G P\left(E(x), K\left(x, x^{\prime}\right)\right)
f(x)∼GP(E(x),K(x,x′))
这里的协方差矩阵要用到内积的核化,笔者理解为拓展了高斯过程表达其他过程的能力,毕竟在实际问题上直接假设一个过程服从高斯过程稍微有点牵强。
假设有一组样本点
D
=
{
(
x
1
:
t
,
y
1
t
)
}
D=\left\{\left(x_{1 : t}, y_{1 t}\right)\right\}
D={(x1:t,y1t)}
为了简便推导,先假设数据提前被中心化,即
f
(
x
)
∼
G
P
(
0
,
K
)
f(x) \sim G P(0, K)
f(x)∼GP(0,K),其中:
K
=
[
k
(
x
1
,
x
1
)
…
k
(
x
1
,
x
t
)
⋮
⋱
⋮
k
(
x
t
,
x
1
)
…
k
(
x
t
,
x
t
)
]
K=\left[\begin{array}{ccc}{k\left(x_{1}, x_{1}\right)} & {\dots} & {k\left(x_{1}, x_{t}\right)} \\ {\vdots} & {\ddots} & {\vdots} \\ {k\left(x_{t}, x_{1}\right)} & {\dots} & {k\left(x_{t}, x_{t}\right)}\end{array}\right]
K=⎣⎢⎡k(x1,x1)⋮k(xt,x1)…⋱…k(x1,xt)⋮k(xt,xt)⎦⎥⎤
对于一个新样本
X
t
+
1
\mathcal{X}_{t+1}
Xt+1 ,由于新样本的加入会更新高斯过程的协方差矩阵:
设
k
=
[
k
(
x
t
+
1
,
x
1
)
,
k
(
x
t
+
1
,
x
2
)
,
…
,
k
(
x
t
+
1
,
x
t
)
]
k=\left[k\left(x_{t+1}, x_{1}\right), k\left(x_{t+1}, x_{2}\right), \ldots, k\left(x_{t+1}, x_{t}\right)\right]
k=[k(xt+1,x1),k(xt+1,x2),…,k(xt+1,xt)]
协方差矩阵更新过程如下:
K
=
[
K
k
T
k
k
(
x
t
+
1
,
x
t
+
1
)
]
K=\left[\begin{array}{ll}{K} & {k^{T}} \\ {k} & {k\left(x_{t+1}, x_{t+1}\right)}\end{array}\right]
K=[KkkTk(xt+1,xt+1)]
有了更新后的协方差矩阵就可以通过前t个样本估计出
f
t
+
1
f_{t+1}
ft+1的后验概率分布:
P
(
f
t
+
1
∣
D
1
:
t
,
x
t
+
1
)
∼
N
(
μ
,
σ
2
)
μ
=
k
T
K
−
1
f
1
:
t
σ
2
=
k
(
x
t
+
1
,
x
t
+
1
)
−
k
T
K
−
1
k
\begin{array}{l}{P\left(f_{t+1} | D_{1 : t}, x_{t+1}\right) \sim N\left(\mu, \sigma^{2}\right)} \\ {\mu=k^{T} K^{-1} f_{1 : t}} \\ {\sigma^{2}=k\left(x_{t+1}, x_{t+1}\right)-k^{T} K^{-1} k}\end{array}
P(ft+1∣D1:t,xt+1)∼N(μ,σ2)μ=kTK−1f1:tσ2=k(xt+1,xt+1)−kTK−1k
从上述高斯过程可以看出,通过采样可以得到目标函数
f
(
x
)
f(x)
f(x)的概率描述。那么很自然地,我们希望通过采样来精确这种描述。我们看论文的时候经常会在论述acquisition function 的地方看到两种采样思路,一种是explore和exploit:
Explore:探索新的空间,这种采样有助于估计更准确的
f
(
x
)
f(x)
f(x);
Exploit:在已有结果附近(一般是已有最大值附近)进行采样,从而希望找到更大的
f
(
x
)
f(x)
f(x);
多臂赌博机
Multi-Armed Bandit问题是一个十分经典的强化学习(RL)问题,翻译过来为“多臂抽奖问题”。对于这个问题,我们可以将其简化为一个最优选择问题。
假设有K个选择,每个选择都会随机带来一定的收益,对每个个收益所服从的概率分布,我们可以认为是Banit一开始就设定好的。举个例子,对三臂Bandit来说,每玩一次,可以选择三个臂杆中的任意一个,那么动作集合Actions = [1, 2, 3],这里的1、2、3分别表示一号臂杆,二号臂杆和三号臂杆。掰动一号号臂杆时,获得的收益服从均匀分布U(-1, 1),也就是说收益为从-1到1的一个随机数,且收益的均值为0。那么二号臂杆和三号臂杆也同样有自己收益的概率分布,分别为正态分布N(1, 1)和均匀分布U(-2, 1)。这里所需要解决关键问题就是,如何选择动作来确保实验者能获得的收益最高。
我们可以从收益的概率分布上发现二号臂杆的收益均值最高,所以每次实验拉动二号即可,最优选择即为二号。但是对于实验者来说收益概率分布是个黑箱,并不能做出直接判断,所以我们使用RL来估计出那个最优的选择。
最简单的做法就是贪心,模型想办法计算每一个action的回报,然后选择回报最大的action进行操作。这种贪心的做法问题就是没有完全探索其它奖励概率的可能性,很容易丢掉最优解。
有一种高级贪心的策略就是按照概率epsilon进行探索,按照uniform distribution选择一个臂进行尝试,按照1-epsilon的概率选择当前情况下回报率最大的action。尽管这种做法比纯贪心的情况好,但是对于下面这种情况,我们通过探索知道action 2的概率远远小于action 1,但还是会以一定的概率反复测试action 2,加大了损失。
Thompson Sampling将多臂赌博机每一个action的回报概率看做一个Beta分布,我们给分布先验概率参数alpha和beta,那么action的回报分布可以被描述成以下函数:
f
(
x
;
α
,
β
)
=
constant
⋅
x
α
−
1
(
1
−
x
)
β
−
1
=
x
α
−
1
(
1
−
x
)
β
−
1
∫
0
1
u
α
−
1
(
1
−
u
)
β
−
1
d
u
=
Γ
(
α
+
β
)
Γ
(
α
)
Γ
(
β
)
x
α
−
1
(
1
−
x
)
β
−
1
=
1
B
(
α
,
β
)
x
α
−
1
(
1
−
x
)
β
−
1
\begin{aligned} f(x ; \alpha, \beta) &=\text { constant } \cdot x^{\alpha-1}(1-x)^{\beta-1} \\ &=\frac{x^{\alpha-1}(1-x)^{\beta-1}}{\int_{0}^{1} u^{\alpha-1}(1-u)^{\beta-1} d u} \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha) \Gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1} \\ &=\frac{1}{\mathrm{B}(\alpha, \beta)} x^{\alpha-1}(1-x)^{\beta-1} \end{aligned}
f(x;α,β)= constant ⋅xα−1(1−x)β−1=∫01uα−1(1−u)β−1duxα−1(1−x)β−1=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1=B(α,β)1xα−1(1−x)β−1
这里我们利用gamma函数对分布就行归一化处理,当我们收集到越来越多的实验结果后,我们可以对分布的参数alpha和beta进行更新:
(
α
k
,
β
k
)
←
{
(
α
k
,
β
k
)
if
x
t
≠
k
(
α
k
,
β
k
)
+
(
r
t
,
1
−
r
t
)
if
x
t
=
k
\left(\alpha_{k}, \beta_{k}\right) \leftarrow\left\{\begin{array}{ll}{\left(\alpha_{k}, \beta_{k}\right)} & {\text { if } x_{t} \neq k} \\ {\left(\alpha_{k}, \beta_{k}\right)+\left(r_{t}, 1-r_{t}\right)} & {\text { if } x_{t}=k}\end{array}\right.
(αk,βk)←{(αk,βk)(αk,βk)+(rt,1−rt) if xt̸=k if xt=k
Beta分布有很多与生俱来的性质,随着我们观测到的结果越多,分布的置信区间就越窄,比方说最开始alpha=1, beta=1,当我们观测到3次正回报,5次负回报后,(alpha, beta)=(4, 6),就产生了上图中action 3的概率分布。当我们观测到599次回报和399次零回报的动作后,(alpha, beta)=(600, 400),就产生了上图中action 1的概率分布。
我们可以在K=10的多臂赌博机上对比一下Epsilon-Greedy和Thompson Sampling的实验效果,当轮数较少时,Thompson Sampling可能会以比较大的概率进行探索,较少的情况使用最佳动作,产生比较高的regret,但是轮数上升后,Thompson Sampling的尝试收敛了,总regret数也随着收敛。
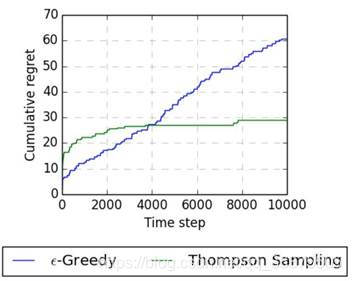
引用:
[1] Han Guo , Ramakanth Pasunuru and Mohit Bansal AUTOSEM: Automatic Task Selection and Mixing in Multi-Task Learning. arXiv:1904.04153.
[2] Alexis Conneau, Douwe Kiela, Holger Schwenk, Loic Barrault, and Antoine Bordes. 2017. Supervised learning of universal sentence representations from natural language inference data. arXiv preprint arXiv:1705.02364.
[3] Eric Brochu, Vlad M Cora, and Nando De Freitas. 2010. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv preprint arXiv:1012.2599
[4] Barbara Plank, Gertjan van Noord, Effective Measures of Domain Similarity for Parsing, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, pages 1566–1576,Portland, Oregon, June 19-24, 2011. c 2011 Association for Computational Linguistics.
[5] Robert Remus ,Domain Adaptation Using Domain Similarity- and Domain Complexity-based Instance Selection for Cross-domain Sentiment Analysis, 2012 IEEE 12th International Conference on Data Mining Workshops.
[6] Sebastian Ruder and Barbara Plank. 2017. Learning to select data for transfer learning with bayesian optimization. arXiv preprint arXiv:1707.05246.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)