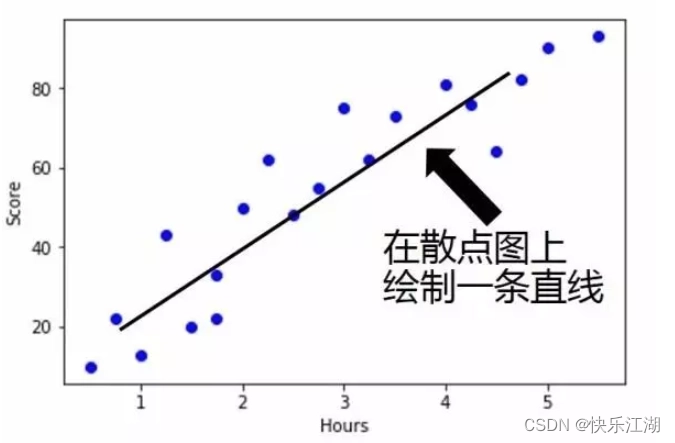
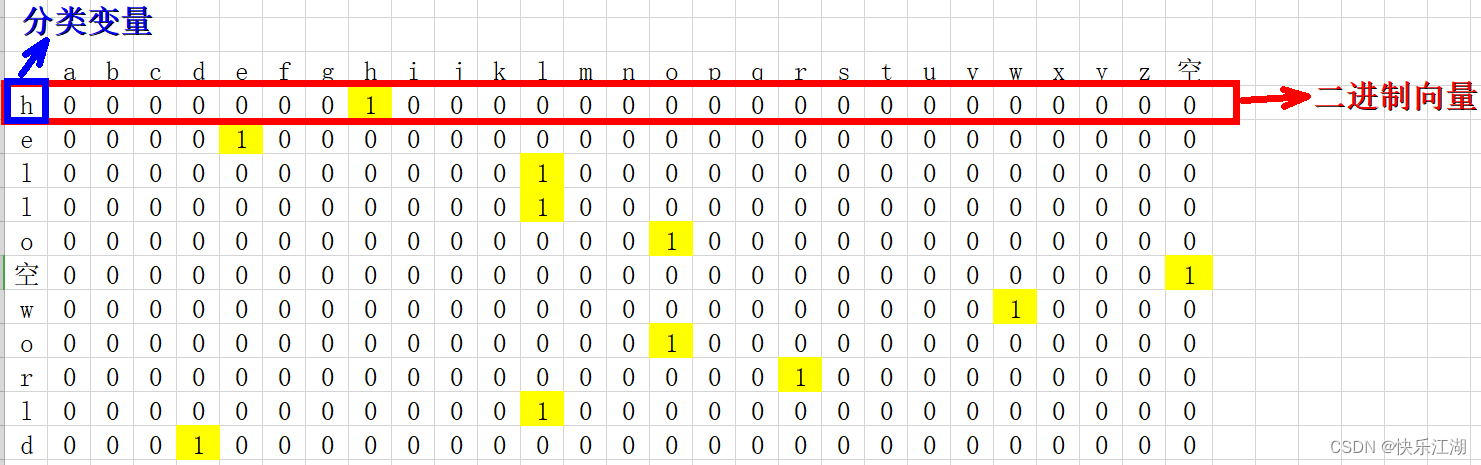
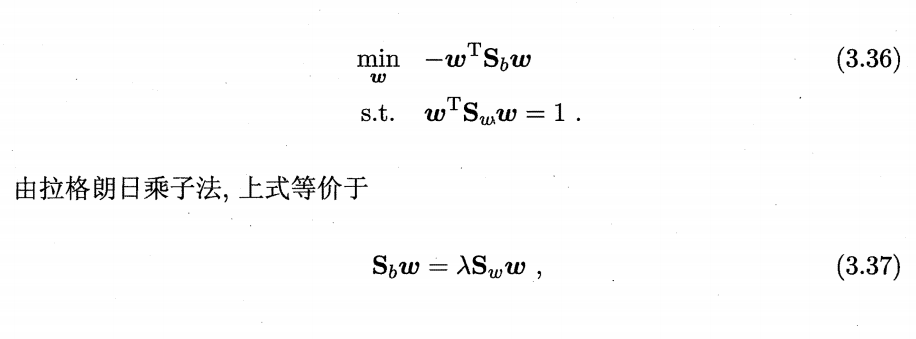线性回归:假设有
n
n
n组数据,自变量
x
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x(x_{1},x_{2},...,x_{n})
x(x1,x2,...,xn),因变量
y
(
y
1
,
y
2
,
.
.
.
,
y
n
)
y(y_{1},y_{2},...,y_{n})
y(y1,y2,...,yn),并且它们满足
f
(
x
)
=
a
x
+
b
f(x)=ax+b
f(x)=ax+b,那么线性回归的目标就是如何能让
f
(
x
)
f(x)
f(x)和
y
y
y之间的差异最小。其中衡量差异的方式即损失函数有很多种,在线性回归中主要使用均方误差,记
J
(
a
,
b
)
J(a, b)
J(a,b)为
f
(
x
)
f(x)
f(x)和
y
y
y之间的差异,则:
J
(
a
,
b
)
=
∑
i
=
1
n
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
=
∑
i
=
1
n
(
a
x
(
i
)
+
b
−
y
(
i
)
)
2
J(a, b)=\sum\limits_{i=1}^{n}(f(x^{(i)})-y^{(i)})^{2}=\sum\limits_{i=1}^{n}(ax^{(i)}+b-y^{(i)})^{2}
J(a,b)=i=1∑n(f(x(i))−y(i))2=i=1∑n(ax(i)+b−y(i))2
可以发现
J
(
a
,
b
)
J(a, b)
J(a,b)是一个二次函数,所以有最小值,因此当
J
(
a
,
b
)
J(a, b)
J(a,b)取最小值时,
f
(
x
)
f(x)
f(x)和
y
y
y的差异最小,所以关键在于确定
a
a
a和
b
b
b的值,方法有三种
分别关于
a
a
a和
b
b
b对函数
J
(
a
,
b
)
=
∑
i
=
1
n
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
=
∑
i
=
1
n
(
a
x
(
i
)
+
b
−
y
(
i
)
)
2
J(a, b)=\sum\limits_{i=1}^{n}(f(x^{(i)})-y^{(i)})^{2}=\sum\limits_{i=1}^{n}(ax^{(i)}+b-y^{(i)})^{2}
J(a,b)=i=1∑n(f(x(i))−y(i))2=i=1∑n(ax(i)+b−y(i))2求偏导,然后令其为0解出
a
a
a和
b
b
b,解得
a
=
∑
i
=
1
n
y
(
i
)
(
x
(
i
)
−
x
‾
)
∑
i
=
1
n
(
x
(
i
)
)
2
−
1
n
(
∑
i
=
1
n
x
(
i
)
)
2
a=\frac{\sum\limits_{i=1}^{n}y^{(i)}(x^{(i)}-\overline{x})}{\sum\limits_{i=1}^{n}(x^{(i)})^{2}-\frac{1}{n}(\sum\limits_{i=1}^{n}x^{(i)})^{2}}
a=i=1∑n(x(i))2−n1(i=1∑nx(i))2i=1∑ny(i)(x(i)−x)
b
=
1
n
∑
i
=
1
n
(
y
(
i
)
−
a
x
(
i
)
)
b=\frac{1}{n}\sum\limits_{i=1}^{n}(y^{(i)}-ax^{(i)})
b=n1i=1∑n(y(i)−ax(i))
B:矩阵求法(主要使用)
假设函数
h
θ
(
x
1
,
x
2
,
.
.
.
,
x
n
=
θ
0
+
θ
1
x
1
+
.
.
.
+
θ
n
−
1
x
n
−
1
h_{\theta}(x_{1}, x_{2}, ... , x_{n}=\theta_{0}+\theta_{1}x_{1}+...+\theta_{n-1}x_{n-1}
hθ(x1,x2,...,xn=θ0+θ1x1+...+θn−1xn−1的矩阵表达式为
h
θ
(
x
)
=
X
θ
h_{\theta}(x)=X\theta
hθ(x)=Xθ
X
X
X为
m
×
n
m×n
m×n维矩阵,其中
m
m
m代表样本个数,
n
n
n代表样本特征数
h
θ
(
x
)
h_{\theta}(x)
hθ(x)为
m
×
1
m×1
m×1向量,
θ
\theta
θ为
n
×
1
n×1
n×1向量
损失函数定义为
J
(
θ
)
=
1
2
(
X
θ
−
Y
)
T
(
X
θ
−
Y
)
J(\theta)=\frac{1}{2}(X\theta-Y)^{T}(X\theta-Y)
J(θ)=21(Xθ−Y)T(Xθ−Y)
Y
Y
Y是样本的输出向量,维度为
m
×
1
m×1
m×1
1
2
\frac{1}{2}
21主要是为了求导后系数为1
接下来需要对
θ
\theta
θ向量求导并令其为0
∂
∂
θ
J
(
θ
)
=
X
T
(
X
θ
−
Y
)
=
0
\frac{\partial}{\partial \theta}J(\theta)=X^{T}(X\theta-Y)=0
∂θ∂J(θ)=XT(Xθ−Y)=0
解得
θ
=
(
X
T
X
)
−
1
X
T
Y
\theta = (X^{T}X)^{-1}X^{T}Y
θ=(XTX)−1XTY
(2)极大似然估计
A:极大似然估计
极大似然估计是一种用于估计概率分布参数的统计方法。假设有一随机变量
X
X
X,其概率密度函数为
f
(
x
;
θ
)
f(x;\theta)
f(x;θ),其中
θ
\theta
θ是一个定义分布的参数向量。极大似然估计的目标是,对于一给定的数据集
x
1
,
x
2
,
.
.
.
x
n
x_{1},x_{2},...x_{n}
x1,x2,...xn找到使似然函数
L
(
θ
∣
x
)
L(\theta|x)
L(θ∣x)最大化的
θ
\theta
θ值
L
(
θ
∣
x
)
=
f
(
x
1
;
θ
)
∗
f
(
x
2
;
θ
)
∗
.
.
.
∗
f
(
x
n
;
θ
)
L(\theta|x)=f(x_{1};\theta)*f(x_{2};\theta)*...*f(x_{n};\theta)
L(θ∣x)=f(x1;θ)∗f(x2;θ)∗...∗f(xn;θ)
似然函数是指在给定的
θ
\theta
θ值下观察到给定数据
x
1
,
x
2
,
.
.
.
x
n
x_{1},x_{2},...x_{n}
x1,x2,...xn的概率极大似然估计意味着找到使观察到的数据最可能出现的参数
θ
\theta
θ。在数学上,我们可以将
θ
\theta
θ的极大似然估计表示为
a
r
g
m
a
x
=
(
L
(
θ
∣
x
)
)
argmax=(L(\theta|x))
argmax=(L(θ∣x))
这意味着我们需要找到使似然函数最大化的
θ
\theta
θ值。在实际使用时,使用对数似然函数
log
(
L
(
θ
∣
x
)
)
\log(L(\theta|x))
log(L(θ∣x))往往更容易,因为它是似然的单调函数,具有相同的最大值。对数似然函数定义为:
log
(
L
(
θ
∣
x
)
)
=
log
(
f
(
x
1
;
θ
)
)
+
log
(
f
(
x
2
;
θ
)
)
+
.
.
.
+
log
(
f
(
x
n
;
θ
)
)
\log(L(\theta|x))=\log(f(x_{1};\theta))+\log(f(x_{2};\theta))+...+\log(f(x_{n};\theta))
log(L(θ∣x))=log(f(x1;θ))+log(f(x2;θ))+...+log(f(xn;θ))
假设我们有一堆输入和输出组成的数据集,表示为
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
n
,
y
n
)
{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)}
(x1,y1),(x2,y2),…,(xn,yn),我们假设输入和输出之间存在着线性关系,由方程
y
=
m
x
+
b
y=mx+b
y=mx+b给出。我们的目标是找到可以最佳拟合数据的
m
m
m和
b
b
b
为了使用极大似然估计,我们做出以下假设
预测值
y
^
\hat{{y}}
y^和真实值
y
y
y之间的误差满足正态分布(均值为0,方差为
σ
2
\sigma^2
σ2)
误差是独立同分布的
基于这些假设,似然函数可以写成下面这样
其中
y
^
i
=
m
x
i
+
b
\hat{y}_i = mx_i + b
y^i=mxi+b是
y
i
y_i
yi的预测值
L
(
m
,
b
∣
{
x
i
,
y
i
}
)
=
∏
i
=
1
n
1
2
π
σ
2
exp
(
−
(
y
i
−
y
i
^
)
2
2
σ
2
)
L(m,b|\{x_{i},y_{i}\})=\prod_{i=1}^{n}\frac{1}{\sqrt{ 2\pi \sigma^{2} }}\exp(-\frac{(y_{i}-\hat{y_{i}})^{2}}{2\sigma^{2}})
L(m,b∣{xi,yi})=i=1∏n2πσ21exp(−2σ2(yi−yi^)2) 取似然函数的负对数,我们就得到了负对数似然函数
−
ln
L
(
m
,
b
∣
{
x
i
,
y
i
}
)
=
n
2
ln
(
2
π
σ
2
)
+
1
2
σ
2
∑
i
=
1
n
(
y
i
−
m
x
i
−
b
)
2
-\ln L(m,b|\{x_{i},y_{i}\})=\frac{n}{2}\ln(2\pi \sigma^{2})+\frac{1}{2\sigma^{2}}\sum_{i=1}^{n}(y_{i}-mx_{i}-b)^{2}
−lnL(m,b∣{xi,yi})=2nln(2πσ2)+2σ21i=1∑n(yi−mxi−b)2
我们的目标是找到最小化负对数似然函数的
m
m
m和
b
b
b的值。这可以用梯度下降法来完成,这涉及到迭代更新
m
m
m和
b
b
b的值,直到收敛
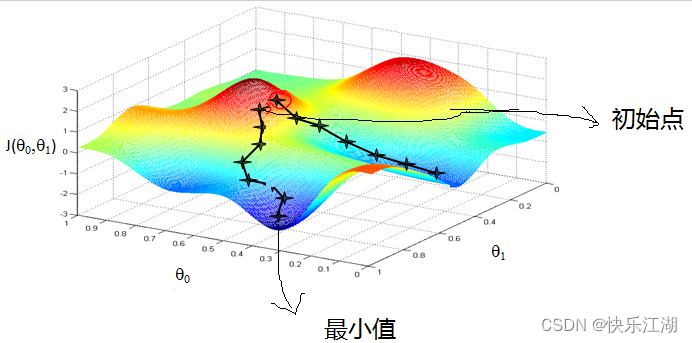
下面介绍梯度下降
(3)梯度下降
A:梯度
梯度:对多元函数的各参数求偏导,然后把求得的各个参数的偏导数以向量的形式写出来,就是梯度
注意:当函数是一元函数,梯度就是导数
例如函数
f
(
x
,
y
)
f(x, y)
f(x,y)分别对
x
x
x和
y
y
y求偏导数,求得的梯度向量就是
(
∂
f
∂
x
,
∂
f
∂
y
)
(\frac{\partial f}{\partial x}, \frac{\partial f}{\partial y})
(∂x∂f,∂y∂f),简写为
g
r
a
d
f
(
x
,
y
)
grad\quad f(x, y)
gradf(x,y)
梯度下降算法:假设有
n
n
n组数据,自变量
x
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x(x_{1},x_{2},...,x_{n})
x(x1,x2,...,xn),因变量
y
(
y
1
,
y
2
,
.
.
.
,
y
n
)
y(y_{1},y_{2},...,y_{n})
y(y1,y2,...,yn),并且它们满足
f
(
x
)
=
a
x
f(x)=ax
f(x)=ax,记
J
(
a
)
J(a)
J(a)为
f
(
x
)
f(x)
f(x)和
y
y
y之间的差异,也即
J
(
a
,
)
=
∑
i
=
1
n
(
f
(
x
(
i
)
)
−
y
(
i
)
)
2
=
∑
i
=
1
n
(
a
x
(
i
)
−
y
(
i
)
)
2
J(a,)=\sum\limits_{i=1}^{n}(f(x^{(i)})-y^{(i)})^{2}=\sum\limits_{i=1}^{n}(ax^{(i)}-y^{(i)})^{2}
J(a,)=i=1∑n(f(x(i))−y(i))2=i=1∑n(ax(i)−y(i))2
在梯度下降算法中,需要给参数
a
a
a给一个预设值,然后逐步修改
a
a
a,直到
J
(
a
)
J(a)
J(a)取到最小值时,确定
a
a
a的值。梯度下降公式如下
r
e
p
e
a
t
{
a
:
=
a
−
α
∂
J
(
a
)
∂
a
}
repeat\{a := a-\alpha \frac{\partial J(a)}{\partial a}\}
repeat{a:=a−α∂a∂J(a)}
对于线性回归,假设函数表示为
h
θ
(
x
1
,
x
2
,
.
.
,
x
n
)
=
θ
0
+
θ
1
x
1
+
.
.
.
+
θ
n
x
n
∣
h_{\theta}(x_{1},x_{2},..,x_{n})=\theta_{0}+\theta_{1}x_{1}+...+\theta_{n}x_{n}|
hθ(x1,x2,..,xn)=θ0+θ1x1+...+θnxn∣,为了简化我们可以增加一个特征
x
0
=
1
x_{0}=1
x0=1,这样
h
θ
(
x
0
,
x
1
,
.
.
.
,
x
n
)
=
∑
i
=
0
n
θ
i
x
i
h_{\theta}(x_{0},x_{1},...,x_{n})=\sum\limits_{i=0}^{n}\theta_{i}x_{i}
hθ(x0,x1,...,xn)=i=0∑nθixi
对于上面的假设函数,其损失函数为
J
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
=
1
2
m
∑
j
=
1
n
(
h
θ
(
x
0
j
,
x
1
j
,
.
.
.
,
x
n
j
)
−
y
j
)
J(\theta_{0},\theta_{1},...,\theta_{n})=\frac{1}{2m}\sum\limits_{j=1}^{n}(h_{\theta}(x_{0}^{j},x_{1}^{j},...,x_{n}^{j})-y_{j})
J(θ0,θ1,...,θn)=2m1j=1∑n(hθ(x0j,x1j,...,xnj)−yj)
对于二分类任务来说,其输出标记为
y
∈
{
0
,
1
}
y\in\{0,1\}
y∈{0,1},而前文所说线性回归模型产生的预测值
z
=
w
T
x
+
B
z=w^{T}x+B
z=wTx+B为实值,产生了矛盾。因此我们需要将实值
z
z
z转化为
0
/
1
0/1
0/1值,最理想的便是“单位阶跃函数”
y
=
{
0
,
z
<
0
0.5
,
z
=
0
1
,
z
>
0
y=\left\{\begin{array}{cc} 0, & z<0 \\ 0.5, & z=0 \\ 1, & z>0 \end{array}\right.
y=⎩⎨⎧0,0.5,1,z<0z=0z>0
但问题是单位阶跃函数并不连续,其关于
x
x
x的导数为0,所以难以使用梯度下降法进行优化更新,因此需要一个可以在
(
0
,
1
)
(0,1)
(0,1)之间平滑过度的函数。而对数几率函数就是一个这样比较合适的函数
y
=
1
1
+
e
−
z
y=\frac{1}{1+e^{-z}}
y=1+e−z1
对数几率函数是一种“Sigmoid”函数,它将
z
z
z转化为一个接近0或1的
y
y
y值,并且其输出值在
z
=
0
z=0
z=0处很陡。将对数几率函数代入广义线性模型
y
=
g
−
1
(
w
T
x
+
b
)
y=g^{-1}(w^{T}x+b)
y=g−1(wTx+b)中,可得
y
=
1
1
+
e
−
(
w
T
x
+
b
)
y=\frac{1}{1+e^{-(w^{T}x+b)}}
y=1+e−(wTx+b)1
可变化为
ln
y
1
−
y
=
w
T
x
+
b
\ln \frac{y}{1-y}=w^{T}x+b
ln1−yy=wTx+b 若将
y
y
y视为样本
x
x
x作为正例的可能性,则
1
−
y
1-y
1−y就是其为反例的可能性,如下两者之比称之为几率
y
1
−
y
\frac{y}{1-y}
1−yy
几率反映了
x
x
x作为正例的相对可能性,对几率取对数则得到对数几率
ln
y
1
−
y
\ln \frac{y}{1-y}
ln1−yy
(2)利用极大似然估计推导损失函数
此部分借助周志华机器学习
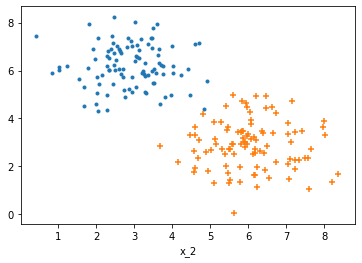
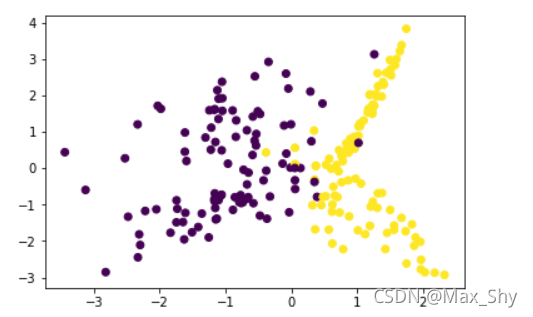
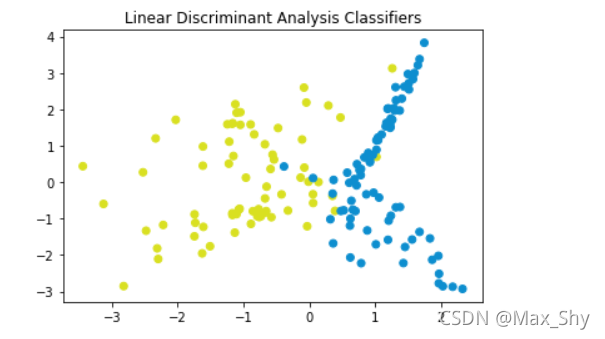
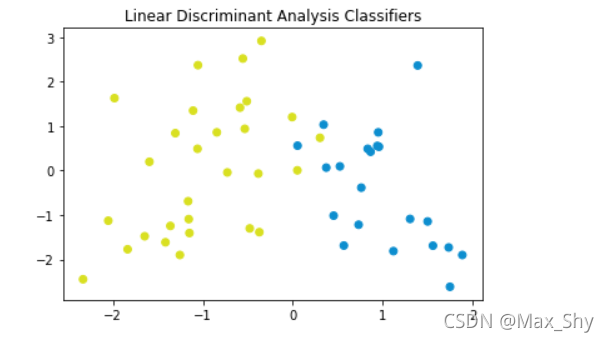
(3)实例:二分类问题
导入必要的库
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1234)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_classification