前言
最近希望能仿真出一个城市的交通状态,也就是知道在不同的需求加载下城市宏观交通状态的变化情况,同时,因为我手头有车牌识别数据,因此需求将来自于车牌识别数据。
但是仿真过后发现,并不能很好的模拟真实世界,我个人认为是因为openstreetmap下载下来的路网和真实世界出入太大,导致经常出现局部交叉口堵死的情况。
接下来我就将基于sumo和车牌识别数据的城市仿真过程公开进行介绍。
如果有大佬知道如何解决基于osm数据进行sumo仿真时,和真实世界情况不符,在我的案例中是出现堵死的情况,请留言或私信我,当然对这块感兴趣的有解决想法的,我们也可以探讨一下。
根据后续研究发现osm爬取下来的路网车道数基本都偏少,因此需要增加车道数,此外需要关注time-to-teleport这个参数,这个参数是帮助解决路网死锁问题的,仿真时特别容易出现死锁情况的,因此time-to-teleport对仿真结果的影响非常大。
目标
希望用sumo对杭州市萧山区进行仿真,通过给定trips,来仿真出萧山区的交通状况。
路网
使用openstreetmap的地图作为底图,下载下来并整理成sumo需要的格式。sumo中存在一些脚本使得用户可以方便的从osm下载地图并进行格式转换。
sumo关于下载osm的介绍:https://sumo.dlr.de/ docs/Networks/Import/OpenStreetMapDownload.html
这边我选择的osm爬取方法是“Downloading a Larger Rectangular Area Using the OpenStreetMap API“,因为我希望下载有电警卡口区域的osm路网,如果对范围不要求精确的话可以使用osmWebWizard,这是一个可视化拖拽方法,可以手工拖拽指定范围。
基于osm的路网构建步骤
- 获得所需要区域的西南角和东北角点位的经纬度;比如我所需要区域的西南角和东北角点位经纬度分别是:(120.22565726848745,30.139564620975033),(120.28777679230367,30.248882870725584)。
- 构建URI,http://api.openstreetmap.org/api/0.6/map?bbox=<SW-longitude,SW-latitude,NE-longitude,NE-latitude>,因此本例中URI应该是http://api.openstreetmap.org/api/0.6/map?bbox=120.22565726848745,30.139564620975033,120.28777679230367,30.248882870725584 ;
- 官方说可以通过命令 wget.exe “http://api.openstreetmap.org/api/0.6/map?bbox=120.22565726848745,30.139564620975033,120.28777679230367,30.248882870725584” -O xiaoshan.osm.xml或者直接浏览器直接拷贝这个链接即可,我使用了浏览器拷贝链接的方式获取指定方形区域的路网;
- 下载下来的文件是xml格式,文件名自己改一下就行了,比如这边我修改成xiaoshan.osm,但是该文件也不能被sumo直接应用,需要进行格式转换;
- 格式转换使用的命令是netconvert,我这边都使用默认值,包括投影,默认会将wgs84坐标系转换为utm,这方便后续距离等的计算。使用该命令进行转换:netconvert --osm-files xiaoshan.osm -o xiaoshan.net.xml ;转换后的文件就可以用netedit打开了;
下下来基本没啥问题,但是奇怪的是不知道为啥有两条路这么长。我猜测可能是因为osm爬取的时候会把边界内的道路完整的下下来,有两条路特别长,所以出现该情况。
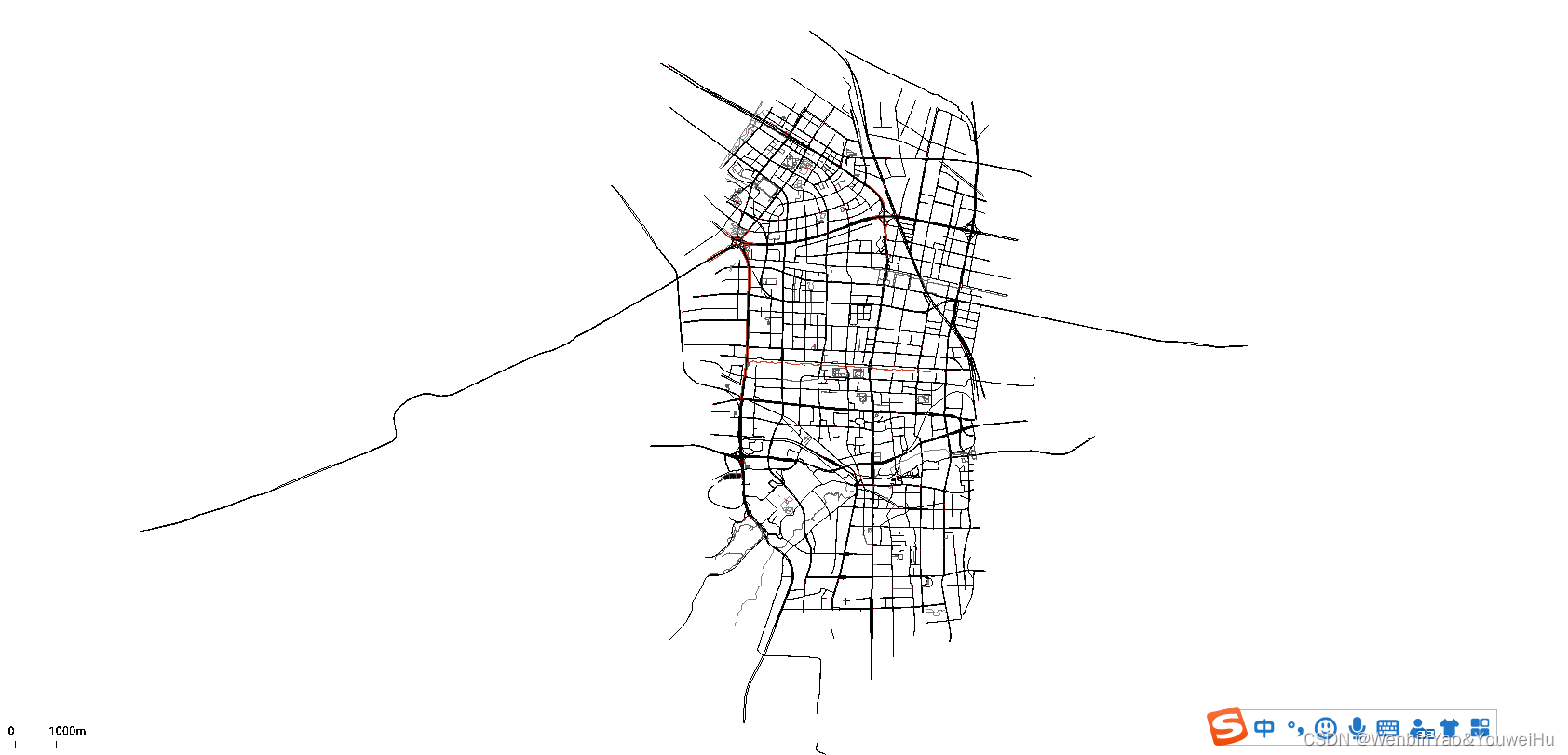
需求
由于我期望使用电警卡口来给予真实需求,在sumo中有多种方式可以模拟电警卡口给予需求,在此列举我考虑过的三种形式:
- 第一种是通过OD矩阵的形式,但是如果希望使用OD矩阵,一个前提条件必然就是需要设置好交通小区,交通小区通常有两种方式设置,一种是人为设定交通小区,一种就是栅格化,对于没有太多要求的话,栅格化往往是比较好的一种方式。
- 第二种方式是Using detector data (observation points),通过在观测点设置需求来模拟真实条件。
- 得到每辆车的trip作为需求;
可以想到第一种方式是需要对电警卡口原数据做较多处理的,第一需要划分好交通小区,第二需要基于车牌识别数据得到OD矩阵;而第二种方式相对而言需要的处理比较少;第三种方式也是处理比较少的。
Demand using detector data
首先就来探索下第二种方式,因为第二种方式相对比较简单。该种方式生成的需求要求要与检测器采集得到的交通情况相匹配,在sumo中提供了一系列的工具帮助用户完成需求生成的工作,主要是下面四种:
- dfrouter uses edge based counts
- flowrouter uses edge based counts
- jtcrouter uses turn-counts
- routeSampler uses turn-counts and edge counts (and also origin-destination counts)
每种工具都有适应的场景,具体可以参加sumo的文档:https://sumo.dlr.de/docs/Demand/Routes_from_Observation_Points.html。在我们的需求中第四种方式即routeSampler应该是最合适的,routeSampler可以设置边的流量,也可以设置好OD借助duarouter工具生成route作为输入。但是可以发现无论哪种方式,缺失肯定都是很大的,因为电警卡口数据对于某些路口只拍摄部分车道,因此流量对于edge来说肯定是偏小很多的,而对于设置OD的话也是缺失严重,因为根据之前的分析经验,绝大部分车辆只被拍摄到了一两次,根本无法生成比较可信的OD pair。
基于OD矩阵的需求
这也就是上述所说的第一种方式,在sumo中给了OD矩阵之后,必然也是需要转化为车辆的route的,因为sumo是微观仿真,是需要告诉sumo车辆轨迹的,因此如何从OD矩阵转化为车辆的轨迹就是这种方式必经的一步。
在sumo中OD也被称作为trip,route就是具体的车辆轨迹。 在我们给定trip的情况下,就需要进一步去得到route,一种最简单的得到route的方式就是使用最短路算法,也就是假设车辆都是按照最短路去走的,但是这种简单粗暴的问题会带来很多bug,因为这是静态的分配,会导致有些edge流量过大。而解决该问题的一个常见手段就是动态用户分配算法,比如Dynamic User Equilibrium,用户均衡算法不断迭代,使得每一个用户都是当前条件下的最优路线,这也就是假设每一个用户都是“自私”的,这个相对比较符合实际情况。
上述说的是OD转化为具体的route,而可以想到OD矩阵到OD中间还是需要经过一定的处理的,在sumo中该步骤是由od2trips这个命令实现的,具体逻辑sumo官方文档没有写,暂时不知道。
但是这种OD矩阵的方式同样也会造成严重的缺失,因为OD矩阵同样需要知道OD,而很多车辆只被检测一次,无法知道OD。
使用trip作为需求
根据LPR数据生成trip之后,需要进一步生成route,因为sumo是微观仿真,需要每一辆车的route才可以,通过trip生成route有很多种方式,比如最短路,用户均衡,Automatic Routing等等。
如何通过车牌识别数据得到trip是一个有意思的研究方向,而在此我将使用较为简单的方式进行,即直接用相邻被检测时间的阈值作为出行链打断标准,打断后直接得到OD,可以想到这样误差是较大的,一方面这种出行链打断方式不一定正确,第二这样得到的OD不是真正的OD,而是一次trip的首末次被检测位置。
基于车牌识别数据得到车辆trip
首先要了解下sumo中的trip文件的格式是怎么样的,我用randomTrips.py生成的一个trip文件random_trip.trips.xml的具体格式是这样的:
<?xml version="1.0" encoding="UTF-8"?>
<routes xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://sumo.dlr.de/xsd/routes_file.xsd">
<trip id="0" depart="0.00" from="F0F1" to="A2A1"/>
<trip id="1" depart="0.25" from="C2C3" to="B7A7"/>
......
</routes>
所以根据车牌识别数据生成trip文件的算法如下:
- 将电警卡口设备与edge id相匹配;
- 进行出行链打断,得到所有的车辆OD(edge id)、离开时间以及travel time;
- 生成.trip.xml文件;
但是可以想到上述方法生成的trip文件缺失是很严重的,因为有大量车辆一天只被检测到一次,无法生成OD信息,还有大量车辆漏检等等,因此通过上述方法生成的trip文件肯定是少于真实路网情况的,这是后续需要validate的一个地方。
将电警卡口设备与edge id相匹配
要想实现这一步,需要首先将sumo的network进行转换,因为现在该文件是.net.xml格式的,借助sumo中的net2geojson.py脚本将.net.xml文件转化为geojson文件。切换到sumo的tools文件夹后,执行命令:
python ./net/net2geojson.py -n E:\study_e\traffic_simu_xiaoshan\network\xiaoshan.net.xml -o E:\study_e\traffic_simu_xiaoshan\network\xiaoshan.geojson
便会生成一个geojson文件,该命令还会将坐标系转换回WGS84坐标系。
接着就可以对两个文件进行操作处理了,需要对每个电警卡口设备分析距离其最近的edge以进行匹配,可能这样匹配会有一些bug,但是这个bug对后续影响不大,因为虽然可能有一些误差,但是后续得到trip时,这些误差仅仅是使得OD可能偏离了一两条路而已。保存结果为:
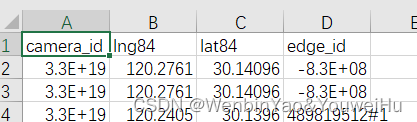
OD生成
首先通过车牌和被检测时间作为第一二索引进行排序,然后将下一行的车牌和被检测时间上移一行并拼接。然后看这一行和下一行被检测车辆是否是同一辆车,以及旅行时间是多少。按照旅行时间和是否是同一辆车为依据进行出行链打断。只保留不是同一辆车和相邻两次被检测时间大于阈值的rows,也就是只保留需要打断出行链的rows,此时保留的每一行分别是(last trip destination, this trip origin),只需要将last trip destination的信息上移一行即可,就可以得到每一次trip的OD了,将结果保存至…/data/trip_basedon_lpr.csv,数据结构为:

生成.trip.xml文件
遍历一遍OD生成中的trip文件,为每一行生成一行。结果保存至demand文件夹下,命名为xiaoshan_lpr_trip.trip.xml即可。
但是有一点需要优化,通过车牌识别数据是可以得到车辆的type的,萧山的数据中共包括三种车辆的type:Truck、Car、Bus。不同车辆的跟驰模型都是有区别的,因此需要指定每一次trip的车辆类型。每种车辆类型的参数可以人为指定,也可以直接使用sumo系统中的值,在本案例中,我们直接使用sumo中的默认值,各类型车辆的参数详见链接:https://sumo.dlr.de/docs/Vehicle_Type_Parameter_Defaults.html,vehicle type设置方法详见:https://sumo.dlr.de/docs/Definition_of_Vehicles%2C_Vehicle_Types%2C_and_Routes.html#abstract_vehicle_class。
基于trip.xml文件的需求生成
在之前已经基于车牌识别数据生成了trip.xml文件,而要想进一步生成需求也有若干方法,比如可以直接用trip作为需求,也可以基于trip进一步生成route文件。在本案例中,我们主要考虑两种方式:
- 直接使用trip.xml文件作为需求;
- 用户均衡方法进行分配,将trip.xml进一步处理为route文件;
根据官网的说明,一般第一种方式适用于下列三种情况:
- there is not enough time / computing power to wait for the dynamic user equilibrium
- changes to the net occur while the simulation is running
- vehicles need to adapt their route while running
在本案例中这三种情况似乎并不存在,唯一可能制约的是第一点,即计算量太大,但是这点也可以通过减少用户均衡分配的迭代次数来缓解,因此本案例中我们主要使用用户均衡方法进行分配,将trip.xml文件进一步处理为route文件。
sumo中有现成的脚本可以使用,Dynamic User Assignment说明链接:https://sumo.dlr.de/docs/Demand/Dynamic_User_Assignment.html。
首先,切换到输出文件的文件夹。
cd /d C:\traffic_simu_xiaoshan\demand\route
然后执行下列命令:
python "C:\Program Files (x86)\Eclipse\Sumo\tools\assign\duaIterate.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" -t "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip.trips.xml" -l 100
出现错误为:Execution of [‘C:\Program Files (x86)\Eclipse\Sumo\bin\duarouter’, ‘-c’, ‘000/iteration_000_xiaoshan_lpr_trip.duarcfg’] failed. Look into dua.log for details.
也就是在调用duarouter命令时报错了,因此需要解决duarouter命令报错的问题。
执行下列命令进行尝试:
duarouter -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" --route-files "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip.trips.xml" -o "C:\traffic_simu_xiaoshan\demand\example_route\example_routes.rou.xml"
确实出现一模一样的bug,为了解决该bug,在上述命令的后面增加–ignore-errors “true”,在此执行,确实运行成功了,但是新出现了很多warning,包括下列这些:
- The vehicle ‘浙AF06170_78642_543446’ has no valid route.
- Vehicle ‘浙AF63516_78642_543447’ is not allowed to arrive on edge ‘320835563#8’.
- The route of the vehicle ‘赣BQA790_78788_544017’ is not known.
- No connection between edge ‘578296331#2’ and edge ‘486375249’ found.
- Mandatory edge ‘154107486’ not reachable by vehicle ‘浙AE8W78_79325_546115’.
不过warnning不影响命令的成功执行,只是会导致很多trip的缺失。
但是即使duarouter成功了依然不能解决duaIterate.py失败的问题,因为duaIterate.py命令并无法传入–ignore-errors "true"这个参数,为了解决该问题,使用下述方法:
基于duaIterate.py进行用户均衡分配
为了解决本案例duaIterate.py脚本的bug,本案例使用下列的命令解决该问题;
1.首先执行该命令;
duarouter -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" --route-files "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip.trips.xml" -o "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" --ignore-errors "true"
2.第一步的命令执行后会生成first_shortestroutes.rou.xml文件,该文件其实就是第一次对短路分配的结果,这个文件里应该是没有bug的,所以后续就用这个文件作为需求的输入进一步去进行用户均衡分配,命令如下:
cd /d C:\traffic_simu_xiaoshan\demand\route;
python "C:\Program Files (x86)\Eclipse\Sumo\tools\assign\duaIterate.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" -t "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" -l 10
上述方法确实可以解决该问题,最终也生成了用户均衡的结果,但是该算法非常耗时,一次循环共包括两个步骤,第一个步骤使进行最短路分配,第二个步骤是进行仿真计算旅行时间等等。进行最短路分配共耗时6分35秒,其实还是挺快的,但是从0点仿真到12点06分共花了1个半小时,可以想到如果要循环10次,是一个不可以接受的时间,因此需要想办法进行优化。
基于车牌识别数据的需求生成优化
在之前,基于车牌识别数据的需求生成的整套流程已经实现了,但是运行时间过长,因此需要进行优化处理,在此考虑的优化方法主要是只对早晚高峰进行仿真优化,而且早晚高峰分开仿真,如此一来需要仿真的时长大大缩短了,而一般交通管理政策也仅仅针对早晚高峰实施,因此这样的一种优化思路也是有依据的。
在本案例中,早高峰设定为06:30 AM – 10:00 AM,晚高峰设定为05:00 PM – 07:30 PM(参考之前发表的part c),但是如果仅仅选取这个时间段的数据作为需求的话是会出问题的,因为之前一些遗留的车等于是完全没有考虑,为了解决该问题,我在上述时间段的基础上进一步扩展半个小时,也就是早高峰选取06:00 AM – 10:30 AM,晚高峰选取04:30 PM – 08:00 PM,但是在后续分析时,依然只取原来的晚高峰时间进行分析,也就是说把扩展时间段去掉。
首先以早高峰为例进行分析:
1.基于“OD生成”一节生成的OD文件进行分析,在生成.trips.xml文件时增加了一个时间过滤,将OD文件中早高峰/晚高峰的数据过滤出,然后保存为.trips.xml文件;python脚本主函数运行下列代码:
obj.generate_trip_file(trip_basedon_lpr_file='../data/trip_basedon_lpr.csv',
time_interval="06:00:00,10:30:00",output_file="C:\\traffic_simu_xiaoshan\\demand\\xiaoshan_lpr_trip_morning_peak.trips.xml")
2.执行命令生成进行需求的用户均衡分配,命令如下:
duarouter -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" --route-files "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip_morning_peak.trips.xml" -o "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" --ignore-errors "true"
cd /d C:\traffic_simu_xiaoshan\demand\route
python "C:\Program Files (x86)\Eclipse\Sumo\tools\assign\duaIterate.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" -r "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" -l 10
需要说明的是仿真开始和结束的时间并没有进行调整,因为早高峰前并没有需求,因此仿真速度是飞快的,实际上不修改也没关系,所以并未调整,而且不进行调整还有一个好处是仿真时间和一天的时间是相同的,这对后续的分析是有利的。
但是在仿真过程中也出现了一些bug,bug详见bug一节所示,在这里不再阐述了。为了使得用户均衡分配可以继续下去,我使用的方法是人为设定好仿真开始和结束的时间,到了结束时间也许还有车,但是也强制停止仿真,此时需要使用下列命令:
duarouter -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" --route-files "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip_morning_peak.trips.xml" -o "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" --ignore-errors "true"
cd /d C:\traffic_simu_xiaoshan\demand\route
python "C:\Program Files (x86)\Eclipse\Sumo\tools\assign\duaIterate.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" -r "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" -l 3 -b 21600 -e 39600
使用上述命令后便可以成功跑完循环,一次循环中进行最短路算法分配需要2分钟,仿真需要一个小时。我设置了循环3次,因此大概需要3个小时来得到用户均衡分配的route结果。duaIterate.py脚本完整运行一次的结果如下图所示,本例中一共运行了3个半小时。根据下图可以知道,总共分配了3次route,也仿真了3次,其中最后一次仿真是基于first_shortestroutes_002.rou.xml跑的,也就是最后ICI分配的route,因此其实不需要在对最新的route进行一次仿真了,可以直接取最后一次仿真的结果进行后续分析,当然如果最后一次仿真没有输出想要的信息,那么就需要在仿真一次。
<input>
<net-file value="C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml"/>
<route-files value="first_shortestroutes_002.rou.xml"/>
<additional-files value="../edgedata.add.xml"/>
</input>
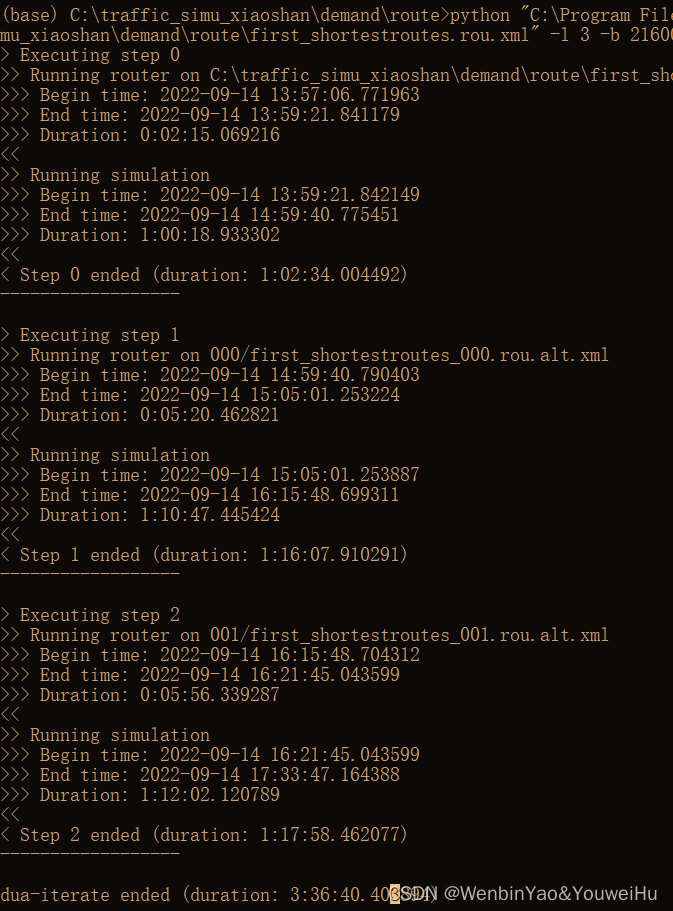
bug
- 命令行都没有bug,但是有一点奇怪的是生成最短路结束后,cmd会卡主,不再继续往下运行,也就是说仿真不会继续,但是可以看一下dua.log文件,如果已经运行完了,可以按一下crtl+C,此时便会继续往下运行。包括第一次循环执行完了也会卡主,但是按一下crtl+C就可以继续执行;最后一次没有出现该bug,直接就运行成功了,好像不去不断的看log文件就不会暂停掉。
- 第二个问题是我这边的需求设置是早上6点到早上10点半,可是在按照最短路分配好,开始仿真时,一直仿真到22:00还是没有仿真结束,也就是说虽说早上10点半之后就没有新的车辆出现了,但是已经出现在路上的车一直到晚上都没有到达目的地,这可能是多个因素造成的结果,比如车辆一直拥堵无法前进,车辆无法到达目的地等,但是具体是什么原因导致的我也不知道。
仿真分析
仿真
如**“基于车牌识别数据的需求生成优化”**一节中所说的,在进行用户均衡分配时,最后一次仿真的结果其实就可以直接作为仿真分析结果来使用,若没有全部的信息,则可以自己配置好仿真配置文件,在进行一次仿真,如果信息完备的话则不需要再进行进一步的仿真了。
用户均衡分配时,在仿真完之后有两个结果文件:
- summary_002.xml
- tripinfo_002.xml
首先看第一个summary.xml的内容是什么,看名字这个文件就是一个结果的汇总文件,其官方链接是https://sumo.dlr.de/docs/Simulation/Output/Summary.html,summary文件是每个step输出一次结果,默认就是每一秒输出一次结果,这个结果中包含着很多统计指标,具体可以看链接中所说明的,包含每一个指标的解释说明,取了一个step的summary结果在下面展示:
<step time="21600.00" loaded="1" inserted="0" running="0" waiting="0" ended="0" arrived="0" collisions="0" teleports="0" halting="0" stopped="0" meanWaitingTime="-1.00" meanTravelTime="-1.00" meanSpeed="-1.00" meanSpeedRelative="-1.00" duration="797437483"/>
- loaded:截止目前为止,从输入文件中载入的车辆数,但是这个值并不是加入到网络中的车辆,有些depart time在未来的车也会被计数进来;
- inserted:截止目前已经插入的车辆数,这个值应该就是截止目前已经插入到路网中的车辆,包括正在运行和已经结束运行的总车辆数;
- running:在当前的这个时间步,正在运行的车辆数;
- waiting:等待要插入,但是无法插入的车辆数,可能因为拥堵等原因无法插入;
- ended:已经到达目的地或被移除的车辆数总数,这个值应该是包括结束旅行和出bug的车辆数之和;
- arrived:已经到达终点的车辆数;
- collisions:发生碰撞的车辆数;
- teleports:被远距离传送的车辆数(由于拥堵或碰撞),这个指标不大清楚是什么意思;
- halting:网络中速度低于0.1m/s的车辆数,这些车不是停在那,而是由于拥堵造成的速度慢;
- stopped:停着不动的车辆;
- meanWaitingTime:截止目前为止,所有等待被插入的车辆的等待时间的平均值;
- meanTravelTime:截止当前时间步为止,所有结束仿真的车辆的平均行程时间;
- meanSpeed:当前网络中除了等待车辆外的所有车辆的平均速度;
- meanSpeedRelative:网络中除了等待车辆外所有车辆相对于限速的平均相对速度;
- duration:截止到当前的仿真耗时;
接着看第二个文件tripinfo_002.xml的内容情况,该文件的官方说明链接是:https://sumo.dlr.de/docs/Simulation/Output/TripInfo.html,借助该文件可以知道每一次trip的开始时间(depart),trip的到达时间(arrival),trip的长度(routeLength),duration(花费时间),vaporized(是否车辆被移除仿真在车辆到达终点之前)。
结果分析
summary文件的处理
对summary文件进行处理,这个文件的基本数据格式为:
<?xml version="1.0" encoding="UTF-8"?>
<summary xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://sumo.dlr.de/xsd/summary_file.xsd">
<step time="21600.00" loaded="1" inserted="0" running="0" waiting="0" ended="0" arrived="0" collisions="0" teleports="0" halting="0" stopped="0" meanWaitingTime="-1.00" meanTravelTime="-1.00" meanSpeed="-1.00" meanSpeedRelative="-1.00" duration="797437483"/>
<step time="21601.00 ..."/>
</summary>
处理时有几种思路,可以直接读取xml文件使用python进行处理,转化为dataframe格式,也可以用sumo的脚本xml2csv.py先把xml文件转化成csv,然后直接读取csv来进行分析。在此为了方便,我先将xml文件转化为csv,然后在进行后续的处理分析。执行下列命令即可,该脚本命令的详细信息可参加官方文档:https://sumo.dlr.de/docs/Tools/Xml.html
python "C:\Program Files (x86)\Eclipse\Sumo\tools\xml\xml2csv.py" "C:\traffic_simu_xiaoshan\demand\route\002\summary_002.xml" --output "C:\traffic_simu_xiaoshan\demand\route\002\summary_002.csv"
在cmd执行上述命令后就会出现一个summary_002.csv文件,这个csv文件就包含上述说明的summary的所有字段,直接对该文件进行处理即可。
描述性统计结果见下表:
| step_arrived | step_collisions | step_duration | step_ended | step_halting | step_inserted | step_loaded | step_meanSpeed | step_meanSpeedRelative | step_meanTravelTime | step_meanWaitingTime | step_running | step_stopped | step_teleports | step_time | step_waiting |
|---|
| count | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 | 18000 |
| mean | 18706.94 | 1.004 | 7.99E+08 | 18706.94 | 15610.18 | 36500.53 | 71117.85 | 2.971724 | 0.115029 | 1199.512 | 486.8998 | 17793.59 | 0 | 13284.18 | 30599.5 | 33888.1 |
| std | 10021.09 | 1.88375 | 1341549 | 10021.09 | 9738.478 | 20404.52 | 45693.2 | 4.565079 | 0.17212 | 751.7394 | 469.3451 | 10415.69 | 0 | 12158.79 | 5196.297 | 25644.36 |
| min | 0 | 0 | 7.97E+08 | 0 | 0 | 0 | 1 | -1 | -1 | -1 | -1 | 0 | 0 | 0 | 21600 | 0 |
| 25% | 10472.5 | 0 | 7.98E+08 | 10472.5 | 5526.5 | 17792.5 | 24975 | 0.39 | 0.02 | 512.095 | 73.5875 | 7320 | 0 | 1740 | 26099.75 | 5991.25 |
| 50% | 20451.5 | 0 | 7.99E+08 | 20451.5 | 18243.5 | 40999 | 77330 | 0.66 | 0.03 | 1091.585 | 290.505 | 20548 | 0 | 10260 | 30599.5 | 35905.5 |
| 75% | 27266 | 1 | 8E+08 | 27266 | 24333.25 | 54446.5 | 114619 | 3.06 | 0.12 | 1812.3 | 851.6025 | 27180.5 | 0 | 23245.5 | 35099.25 | 59056.25 |
| max | 33312 | 7 | 8.02E+08 | 33312 | 27932 | 63759 | 130967 | 19.98 | 0.75 | 2684.07 | 1553.36 | 30457 | 0 | 39086 | 39599 | 70022 |
基于summary文件的仿真效果评价
要想做validation,首先肯定是需要对仿真的效果进行评价,在本案例中,由于真实数据我只得到了每次trip的行程时间,所以这个效果评价肯定是围绕行程时间了。
行程时间均值比较
粗略判断仿真效果的话只需要计算下车牌识别数据得到的所有trip的行程时间的均值和仿真得到的所有trip的行程时间均值进行比较。
仿真数据集上得到的结果为:
萧山区仿真实验中早上06:00 - 10:00 AM所有完成trip的车辆数为28581辆,所有完成trip的车辆的平均行程时间为33.07分钟,所有被插入到网络中的车辆数为56688辆。
真实数据集上得到的结果为:
萧山区车牌识别数据得到早上06:00 - 10:00 AM所有完成trip的车辆数为144768辆,所有完成trip的车辆的平均行程时间为14.85分钟,所有被插入到网络中的车辆数为153139辆。
问题推断:
可以发现仿真结果和实际结果的差距非常之大,于是,使用gui重新仿真了下进行观察,可以看到很多路口都堵死了,车辆根本动不了,这就是为什么仿真需求比实际需求小这么多,可是行程时间却大很多,且进入路网但是无法完成行程的车辆数很多的原因,早上6点到10点一半车都是进入了路网但是无法完成行程,这些车都是在路上被堵死了。接着分析车辆在路上被堵死的原因:
- 从osm爬取的路网拓扑不正确;
- 从osm爬取的路网绝大多数路口都缺失信号灯;
- 仿真车辆在经过无信号交叉口时,并不像真实世界一样会让对方,而是尽力往前冲,因此容易堵死;
我从sumo-gui截取了下列三张图来说明这种现象,当然造成仿真不准确还有其他很多原因,比如电警和路段匹配时,由于匹配错误,导致损失了很多需求,这也是为什么,仿真需求比实际需求少这么多的原因,但是这个需求问题之后在解决,现在当务之急是需要解决无信号交叉口无序出行导致碰撞的问题。


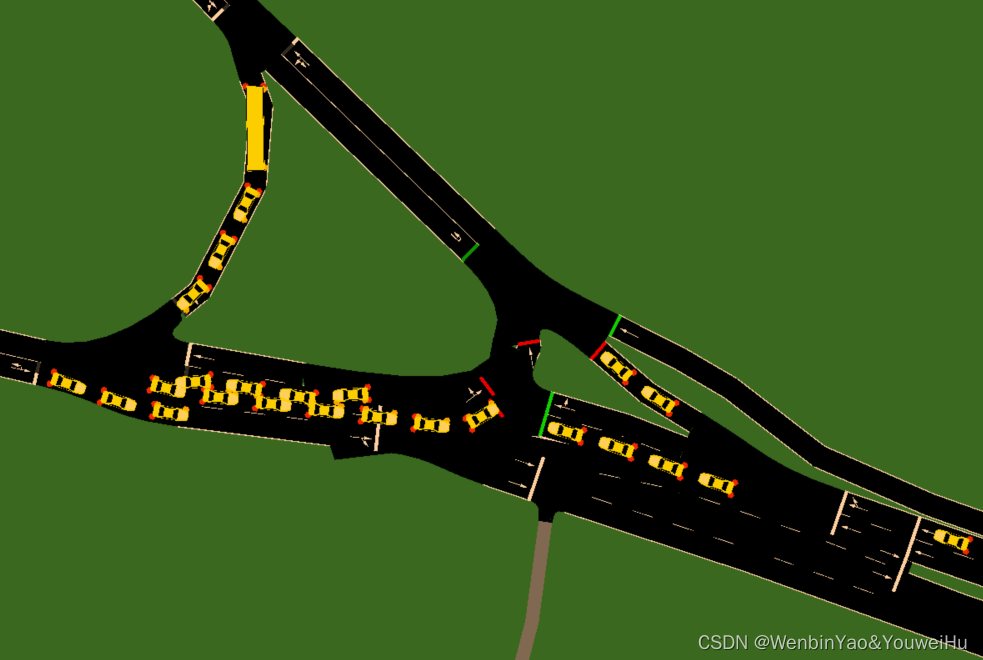
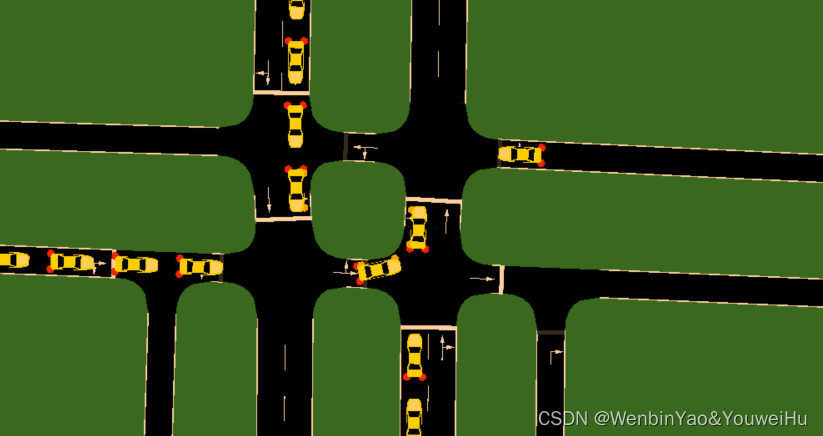
解决思路:
为了解决该问题,主要是对交叉口设置进行改进,交叉口的官方文档为:https://sumo.dlr.de/docs/Simulation/Intersections.html,在本案例中采取的解决方案是忽略交叉口内的车辆行为,即车辆一到达交叉口将直接到交叉口出口处,交叉口内的行为将被忽略,这也就不会发生碰撞了,但是对于信号交叉口等红绿灯的时间依然是会被考虑在内的,但是由于我们的拓扑缺失了很多信号灯,因此这种处理手段将会导致车辆的行程时间大幅缩短。
对路网拓扑进行–no-internal-links设置后在重新进行仿真。
- 路网拓扑设置更新,使用的命令如下:
netconvert -s "C:\traffic_simu_xiaoshan\network\xiaoshan.net.xml" -o "C:\traffic_simu_xiaoshan\network\xiaoshan_new.net.xml" --no-internal-links True
命令结束后就会生成xiaoshan_new.net.xml文件。
- 根据新的路网拓扑数据xiaoshan_new.net.xml生成geojson格式的路网数据,为设备和edge的匹配做铺垫,命令如下:
python "C:\Program Files (x86)\Eclipse\Sumo\tools\net\net2geojson.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan_new.net.xml" -o "C:\traffic_simu_xiaoshan\network\xiaoshan_new.geojson"
- 执行generate_network.py脚本的match_dev_edge函数,进行设备和edge的匹配;
- 基于车牌识别数据的OD生成可以直接调用generate_network.py脚本的get_veh_od_tratime函数,由于设备和edge重新匹配了,因此OD也需要重新生成一下;
- trips.xml文件的生成可以直接调用generate_network.py脚本的generate_trip_file函数,早高峰直接使用06:30 AM – 10:00 AM,而不再拓展半个小时(这样做,主要是为了简化,因为summary中的统计指标都是截止目前为止的统计指标,因此不往前拓展,忽略这种误差会方便后续的处理);
- 对trips进行用户均衡分配,命令如下(都是和之前一样的),现在修改优化后,仿真一次速度提升至17分钟,3次用户均衡迭代也仅仅需要1个小时而已了。
duarouter -n "C:\traffic_simu_xiaoshan\network\xiaoshan_new.net.xml" --route-files "C:\traffic_simu_xiaoshan\demand\xiaoshan_lpr_trip_morning_peak.trips.xml" -o "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" --ignore-errors "true"
cd /d C:\traffic_simu_xiaoshan\demand\route
python "C:\Program Files (x86)\Eclipse\Sumo\tools\assign\duaIterate.py" -n "C:\traffic_simu_xiaoshan\network\xiaoshan_new.net.xml" -r "C:\traffic_simu_xiaoshan\demand\route\first_shortestroutes.rou.xml" -l 3 -b 23400 -e 36000
- 结束了之后,就得到最新的summary文件,需要将summary.xml文件转化为csv文件,调用sumo的转换脚本转换一下就行了:
python "C:\Program Files (x86)\Eclipse\Sumo\tools\xml\xml2csv.py" "C:\traffic_simu_xiaoshan\demand\route\002\summary_002.xml" --output "C:\traffic_simu_xiaoshan\demand\route\002\summary_002.csv"
- summary文件转换好之后,再次进行基于summary文件的仿真效果评价,直接调用simu_result_ana.py文件就行了,main脚本如下:
obj=simu_summary_file_ana()
simu_df = obj.read_summary_file(summary_file="C:\\traffic_simu_xiaoshan\\demand\\route\\002\\summary_002.csv")
obj.comp_simu_real(simu_df=simu_df, real_df_file="C:\\traffic_simu_xiaoshan\\data\\trip_basedon_lpr.csv")
通过该方式重新评估仿真结果和车牌识别数据结果的差异,结果如下:
仿真结果:
萧山区仿真实验中早上06:30 - 10:00 AM所有完成trip的车辆数为46021辆,所有完成trip的车辆的平均行程时间为18.53分钟,所有被插入到网络中的车辆数为69291辆。
车牌识别数据结果:
萧山区车牌识别数据得到早上06:30 - 10:00 AM所有完成trip的车辆数为140825辆,所有完成trip的车辆的平均行程时间为14.96分钟,所有被插入到网络中的车辆数为147033辆。
问题推断:
可以看到,结果相对于之前有明显的改进,但是依然没有彻底解决问题,通过观察gui可以发现运行到后来基本上加起来有1/4的区域完全被堵死了。造成这个现象的原因应该还是由于从osm爬取的路网拓扑不正确导致的。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)