Meta-Learning: Learning to Learn Fast
元学习: 学习如何学习【译】
原文
本文与原文基本没有区别,仅供个人学习记录(电子笔记本)。
前言:
元学习解决:遇到没有见过的任务,可根据少量样本快速学习。
常见方法:
(1)学习有效距离度量方式(基于度量)
(2)使用带有显式或隐式记忆存储的(循环)神经网络(基于模型)
(3)训练以快速学习为目标的模型(基于优化)
元学习举例
- 在没有猫的训练集上训练出来一个图片分类器,这个分类器需要在看过少数几张猫的照片后分辨出测试集的照片中有没有猫。
- 训练一个玩游戏的AI,这个AI需要快速学会如何玩一个从来没玩过的游戏。
- 一个仅在平地上训练过的机器人,需要在山坡上完成给定的任务。
一、元学习问题定义
1.A Simple View
有一个任务的分布,从这个分布中采样许多任务作为训练集。元学习模型在这个训练集上训练后,对这个空间内所有任务都具有良好表现,即使是从未见过的任务。
每个任务表示为一个数据集
D
D
D ,数据集中包括特征向量
x
x
x和标签
y
y
y,分布表示为
p
(
D
)
p(D)
p(D)。最佳元学习模型参数表示为:
θ
∗
=
a
r
g
m
i
n
θ
E
D
p
(
D
)
[
L
θ
(
D
)
]
\theta^*=arg \ \underset{\theta}{min} \ E_{D~p(D)}[L_\theta(D)]
θ∗=arg θmin ED p(D)[Lθ(D)]
上式中,每个数据集是一个数据样本。
少样本学习 是元学习在监督学习的一个实例。
数据集
D
D
D被划分为两部分,一个用于学习的 支持集 (support set)
S
S
S,和一个用于训练和测试的 预测集 (prediction set)
B
B
B,即
D
=
⟨
S
,
B
⟩
D=\langle S,B \rangle
D=⟨S,B⟩。
K-shot N-class 分类任务,即 支持集 中有
N
N
N 类数据,每类数据有
K
K
K 个带有标注的样本。
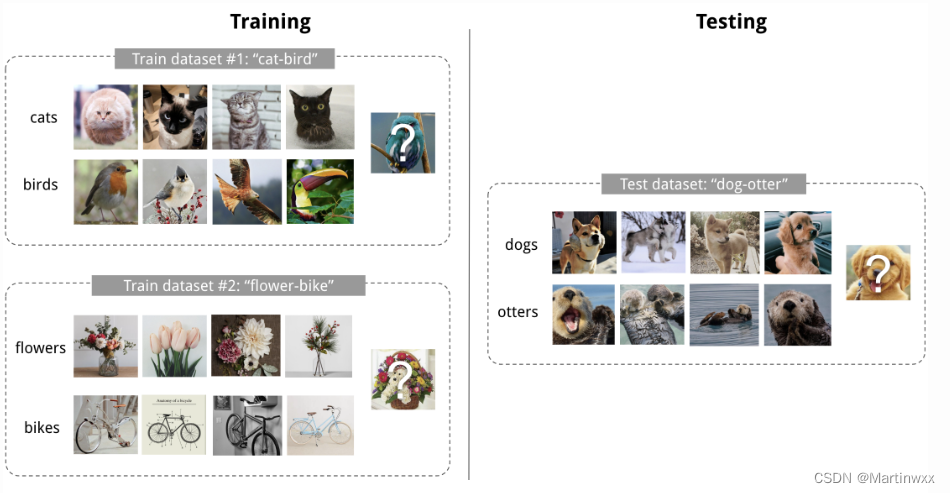
Fig.1 4-shot 2-class图像分类
2.像测试一样训练
一个数据集
D
\mathcal{D}
D包含许多对特征向量和标签,即
D
=
{
(
x
i
,
y
i
)
}
\mathcal{D}=\lbrace (x_i,y_i) \rbrace
D={(xi,yi)} 。每个标签属于一个标签类
L
\mathcal{L}
L。分类器
f
θ
f_\theta
fθ 的输入为特征向量
x
x
x ,输出是属于第
y
y
y 类的概率
P
θ
(
y
∣
x
)
P_\theta (y|x)
Pθ(y∣x) ,
θ
\theta
θ 是分类器的参数。
每次选一个
B
⊂
D
B\subset \mathcal{D}
B⊂D 作为训练的 batch ,则最佳的模型参数,应该能够最大化多组 batch 的正确标签概率之和。
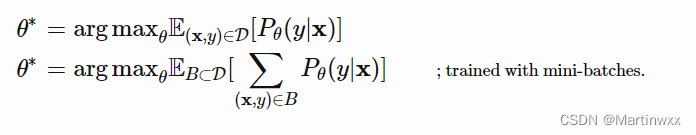
few-shot classification 目标:在小规模训练集上“快速学习”后,减少在预测集上的预测误差。
训练步骤:
- 采样一个标签的子集:
L
⊂
L
L \subset \mathcal{L}
L⊂L
- 根据采样的标签子集,采样一个support set
S
L
⊂
D
S^L \subset \mathcal{D}
SL⊂D 和一个training batch
B
L
⊂
D
B^L \subset \mathcal{D}
BL⊂D。
S
L
S^L
SL 和
B
L
B^L
BL 中的数据的标签都属于
L
L
L,即
y
∈
L
,
∀
(
x
,
y
)
∈
S
L
,
B
L
y \in L,\forall(x,y) \in S^L,B^L
y∈L,∀(x,y)∈SL,BL
- 将 support set 输入模型,进行“快速学习”,不同算法有不同学习策略,此步骤不会永久性更新模型参数。
- 将 prediction set 输入模型,计算模型在
B
L
B^L
BL 上的 loss ,根据 loss 进行反向传播更新模型参数。
可以将每一对
(
S
L
,
B
L
)
(S^L,B^L)
(SL,BL) 看做一个数据点。模型被训练出在其他数据上的扩展能力。下式中的红色部分是元学习的目标相比于监督学习的目标多出来的部分。
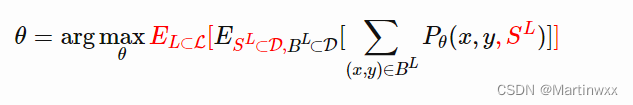
3.学习器和元学习器
meta-learning 将模型更新分为两个阶段:
1.根据给定任务,训练一个分类器
f
θ
f_\theta
fθ ,作为“学习器”模型
2.同时,训练一个元学习器
g
ϕ
g_\phi
gϕ ,根据 support set
S
S
S 学习如何更新学习器模型的参数,
θ
′
=
g
ϕ
(
θ
,
S
)
\theta'=g_\phi(\theta,S)
θ′=gϕ(θ,S)
最后的优化目标中,需要更新
θ
\theta
θ ,
ϕ
\phi
ϕ 来最大化:
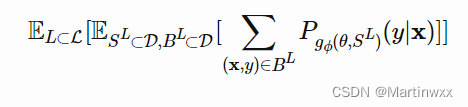
4.常见方法
基于度量(metric-based)、模型(model-based)、优化(optimization-based)

(
∗
)
k
θ
(*)k_\theta
(∗)kθ 是一个衡量
X
i
X_i
Xi 和
X
X
X 相似度的 kernel function。
二、基于度量的方法
基于度量的元学习方法的核心思想类似于最近邻算法(k-NN分类、k-means聚类) 和 核密度估计。
此类方法在已知标签的集合上预测出来的概率是support set中的样本标签的加权和。
权重由核函数(kernal function)
k
θ
k_\theta
kθ 算得,该权重代表两个数据样本之间的相似性
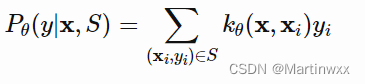
学到好的核函数对基于度量的元学习模型至关重要。
Metric learning 为针对该问题的方法,目标:需要一个不同样本之间的 metric 或者说 距离函数。
任务不同,metric定义 不同,当一定在任务空间上表示了输入之间的关系。
下列方法都显式的学习了 输入数据 的 嵌入向量(embedding vectors),并根据其设计合适的 kernel function。
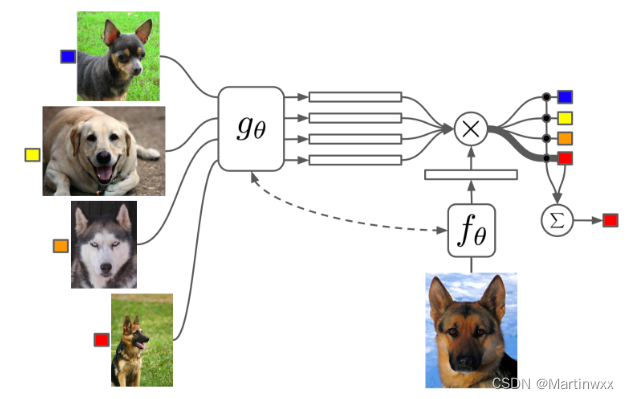
1. Convolutional Siamese Neural Network
Siamese Neural Network 最早用来解决笔记验证问题,Siamese Network 由两个神经孪生网络组成,输出被联合起来训练一个函数,学习一对输入数据之间的关系。两个网络结构相同,共享参数。
实际就是一个网络学习如何有效 embedding 才能显现一对数据之间的关系。
Koch, Zemel & Salakhutdinov (2015)
提出一种用 siamese网络 做 one-shot image classification 的方法。
①首先:训练一个图片验证 siamese网络 ,分辨两张图片是否属于同一类。
②测试:siamese网络 将 输入 和 support set 中的图片比较。
③输出:相似度最高的图片。
Fig. 2. 卷积siamese网络用于few-shot image classification的例子
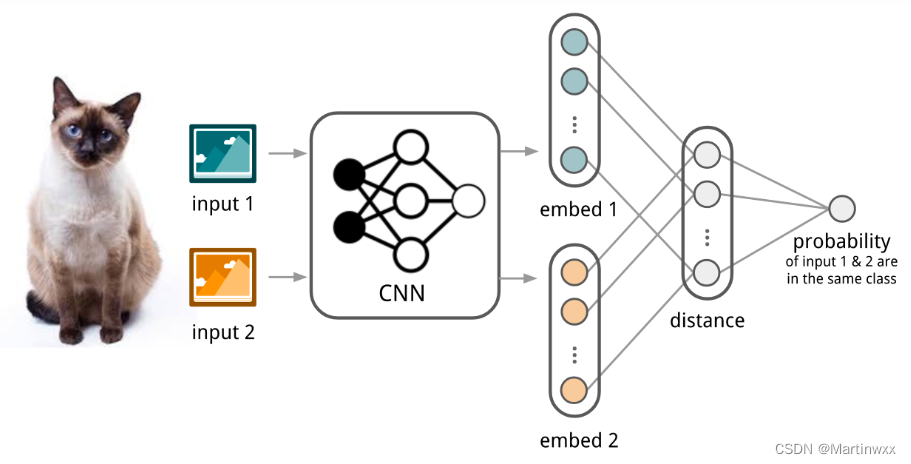
(1) 卷积siamese网络 学习一个由多个卷积层组成的embedding函数
f
θ
f_\theta
fθ ,把两张图片编码为特征向量。
(2) 两个特征向量之间的
L
1
L1
L1 距离可以表示为
f
θ
(
X
i
)
−
f
θ
(
X
j
)
f_\theta (X_i )-f_\theta(X_j)
fθ(Xi)−fθ(Xj)
(3)通过一个 linear feedforward layer 和 sigmoid 把距离转换为概率。这就是两张图片属于同一类的概率。
(4)loss函数 就是cross entropy loss,因为label是二元的。
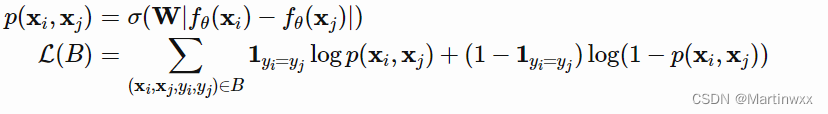
c
(
X
)
c(X)
c(X)是图片
X
X
X 的 label,
c
^
(
⋅
)
\hat{c}(\cdot)
c^(⋅) 是预测的 label。
2. Matching Networks
目标:对于每一个给定的支持集
S
=
{
x
i
,
y
i
}
i
=
1
k
S=\lbrace x_i,y_i\rbrace^k_{i=1}
S={xi,yi}i=1k (k-shot classification),分别学一个分类器
c
S
c_S
cS 。该分类器给出了,给定测试样本
X
X
X 时,输出
y
y
y 的概率分布。
该分类器的输出被定义为支持集中一系列 label 的加权和,权重由 注意力核(attention kernel)
a
(
X
,
X
i
)
a(X,X_i)
a(X,Xi) 决定,权重当与
X
X
X 和
X
i
X_i
Xi 之间的相似度成正比。
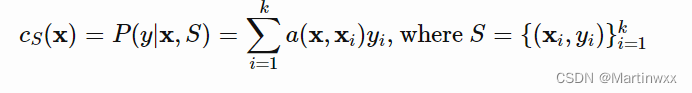
Attention kernel 由两个 embedding function
f
f
f 和
g
g
g 决定。分别用于 encoding 测试样例和支持集样本。
两个样本间注意力权重是经过 softmax归一化 后的,他们embedding vectors的cosine距离
c
o
s
i
n
e
(
⋅
)
cosine(\cdot)
cosine(⋅)。
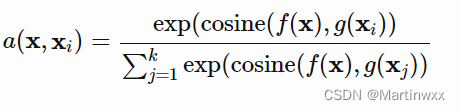
Fig. 3. Matching Networks结构
3. Simple Embedding
在简化版本,embedding function 是一个使用 单样本 作为输入的神经网络。假设
f
=
g
f=g
f=g。
4. Full Context Embeddings
Embeding vectors 对于构建一个好的分类器至关重要,只有一个数据样本作为 embedding function 的输入难以高效估计整个特征空间。
Matching Network 将整个 支持集
S
S
S 作为输入,增强 embedding 有效性,类似于给样本增加语境,让 embedding 根据样本与支持集中样本关系进行调整。
这类embedding 方法称为 全语境嵌入 。此方法对困难任务有帮助(few-shot classification on mini ImageNet),对简单任务没有提升(Omniglot)。
-
g
θ
(
X
i
,
S
)
g_\theta(X_i,S)
gθ(Xi,S) 在整个支持集
S
S
S 的语境下用一个双向 LSTM 来编码
X
i
X_i
Xi 。
-
f
θ
(
X
,
S
)
f_\theta (X,S)
fθ(X,S) 在支持集
S
S
S 上使用 read attention 机制编码测试样本
X
X
X。
(1)测试样本经过一个简单的神经网络,如 CNN ,以抽取基本特征
f
′
(
X
)
f'(X)
f′(X)。
(2)一个带有 read attention vector的 LSTM 被训练用于生成部分 hidden state :
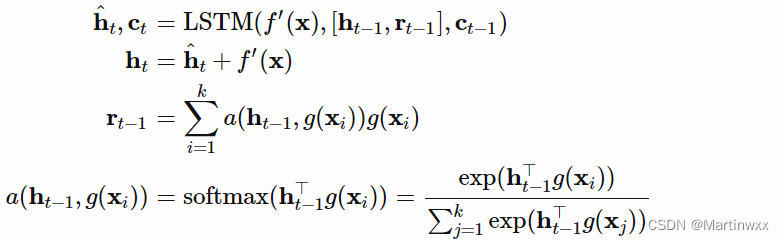
(3)做
k
k
k 步的读取
f
(
X
,
S
)
=
h
k
f(X,S)=h_k
f(X,S)=hk
Matching Networks强调训练和测试的条件应该一致。
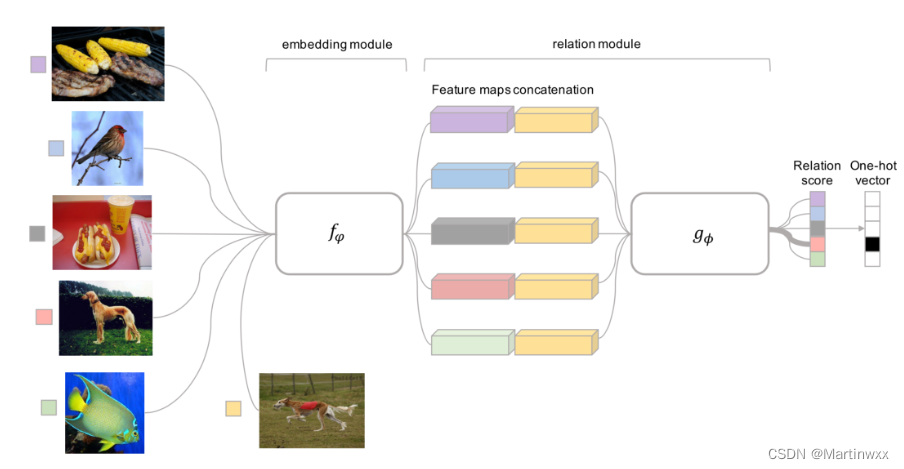
5. Relation Network
Relation Network 与 siamese network 比较像,有以下不同点:
(1)RN 两个样本间相似系数由一个CNN 分类器
g
ϕ
g_\phi
gϕ 预测,而不是 特征空间的
L
1
L1
L1 距离 。
X
i
X_i
Xi 和
X
j
X_j
Xj 间相似系数为
r
i
j
=
g
ϕ
(
[
X
i
,
X
j
]
)
r_{ij}=g_\phi([X_i,X_ j])
rij=gϕ([Xi,Xj]) ,
[
⋅
,
⋅
]
[\cdot , \cdot]
[⋅,⋅] 代表 concatenation
(2)目标优化函数是 MSE损失,而不是 cross-entropy,因为RN在预测时更倾向于把 相似系数预测过程 作为一个 regression问题,而不是 二分类问题,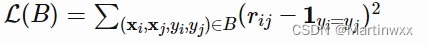
Fig. 4. Relation Network的结构,图中是一个5分类1-shot的例子
6. Prototypical Networks
Prototypical Networks 用一个嵌入函数
f
θ
f_\theta
fθ 把每个输入编码成一个
M
M
M 维特征向量,对每一类
c
∈
C
c \in \mathcal C
c∈C ,取 所有支持集样本的特征向量的平均值 作为这个类的 prototype 特征。
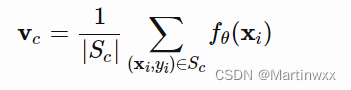
测试样本属于各类的概率分布由 特征向量 和 prototype向量 的距离 取负 后通过 softmanx 得到。
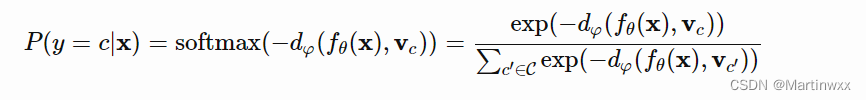
d
φ
d_\varphi
dφ 可以是任意距离函数,
φ
\varphi
φ 可导即可。本文使用平方欧氏距离 ,损失函数使用 负对数似然 :
L
(
θ
)
=
−
log
P
θ
(
y
=
c
∣
X
)
\mathcal L(\theta)=-\log{P_\theta(y=c|X)}
L(θ)=−logPθ(y=c∣X)
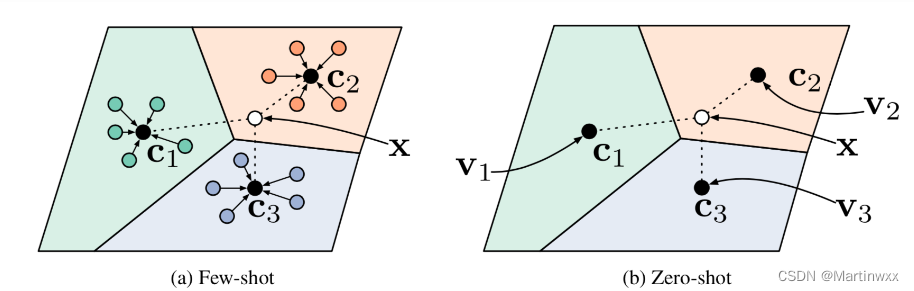
Fig. 5. 在少样本学习和无样本学习中的Prototypical networks
三、基于模型的方法
基于模型的元学习不对
P
θ
(
y
∣
X
)
P_\theta(y|X)
Pθ(y∣X) 作假设,
P
θ
(
y
∣
X
)
P_\theta(y|X)
Pθ(y∣X) 由一个快速学习模型生成,可以根据少量训练快速更新参数。
实现快速学习的两种途径:
1.设计好模型内部架构使其能快速学习
2.用另一个模型来生成快速学习模型的参数
1.Memory-Augmented Neural Networks
使用外部存储来帮助神经网络学习,如:Neural Turing Machines、Memory Networks。外部存储让神经网络更容易学到新知识并提供给以后使用,此网络称之为 MANN。
注意:只是用内部存储的循环神经网络并不是MANN,如 RNN、LSTM。
MANN 目的:仅给定及格训练样本的情况下,快速编码新的信息并适应新任务。适用于元学习。
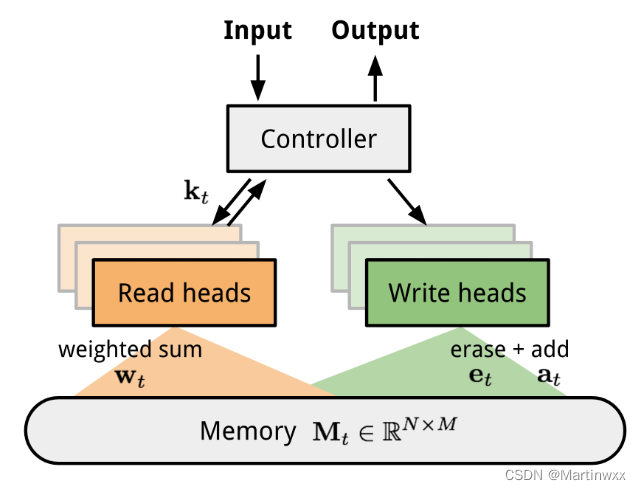
NTM (Neural Turing Machine)
由一个 控制器神经网络 和 存储器 组成。控制器学习通过 软注意力(soft attention) 读写存储器,存储器相当于一个知识库。
注意力权重由 寻址机制 生成,由询问的内容和位置共同决定。
Fig. 6. NTM的架构,t时刻的存储,
M
t
M_t
Mt是一个大小为 N×M 的矩阵,代表着N个M维的向量,每个向量是一条记录
2.MANN for Meta-Learning
Meta-Learning with Memory-Augmented Neural Networks
文中提出新的训练方式:
强迫存储器保留当前样本的信息直到对应的标签出现。在每个episode中,标签有 一步的延迟 ,即每次给出的训练对为
(
X
t
+
1
,
y
t
)
(X_{t+1} , y_t)
(Xt+1,yt) 。
Fig. 7. MANN在元学习中的任务设置
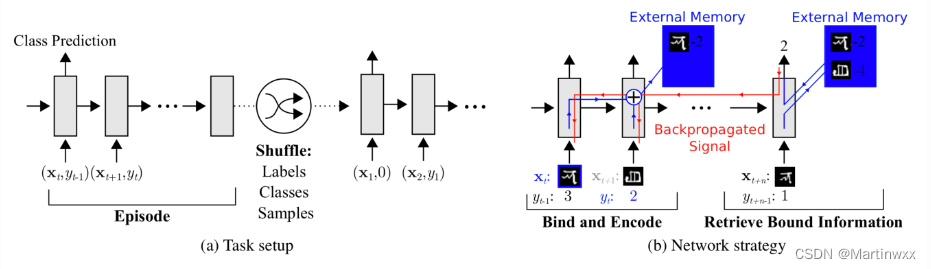
此设定帮助 MANN 学到要记住新数据集的信息,因为存储器要保留当前输入的信息,在对应标签出现时取回之前存储的信息进行预测。
3.Addressing Mechanism for Meta-Learning
作者增加了一个完全基于内容的寻址机制
》如何从存储器中取回信息?
读取注意力 (read attention) 完全由内容相似度决定。
(1)
t
t
t 时刻的输入
X
X
X,控制器生成给一个键值特征向量
k
t
k_t
kt
(2)使用类似于 NTM 的方法,计算键值特征向量和存储器中每个向量的
c
o
s
i
n
e
cosine
cosine 距离,经过 softmax归一化 ,得到读取权重向量
W
t
T
W^T_t
WtT 。读取向量
r
t
r_t
rt 是对存储器中所有向量的加权和:
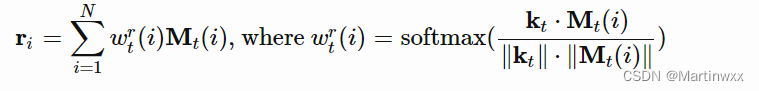
M
t
M_t
Mt 是
t
t
t 时刻的存储器矩阵,
M
t
(
i
)
M_t(i)
Mt(i) 是该矩阵中的第
i
i
i 行,即第
i
i
i 个向量。
》如何往存储器中写入信息?
MANN使用最近最少使用算法(Least Recently Used Access, LRUA) 。优先覆盖最少使用的,或者最近刚用过的存储位置。
最少使用:为了保存经常使用的信息。
最近使用:原因为刚用过的信息很有可能不会马上用到。
(1)
t
t
t 时刻的使用权重
W
t
u
W^u_t
Wtu 是当前读写向量的和,加上 上一时刻的使用权重
γ
W
t
−
1
u
\gamma W^u_{t-1}
γWt−1u ,
γ
\gamma
γ 是一个衰减系数。
(2)写入向量有之前的读取权重和之前的最少使用权重插值得到,插值参数是超参数
α
\alpha
α 的
s
i
g
m
o
i
d
\mathcal sigmoid
sigmoid。
(3)
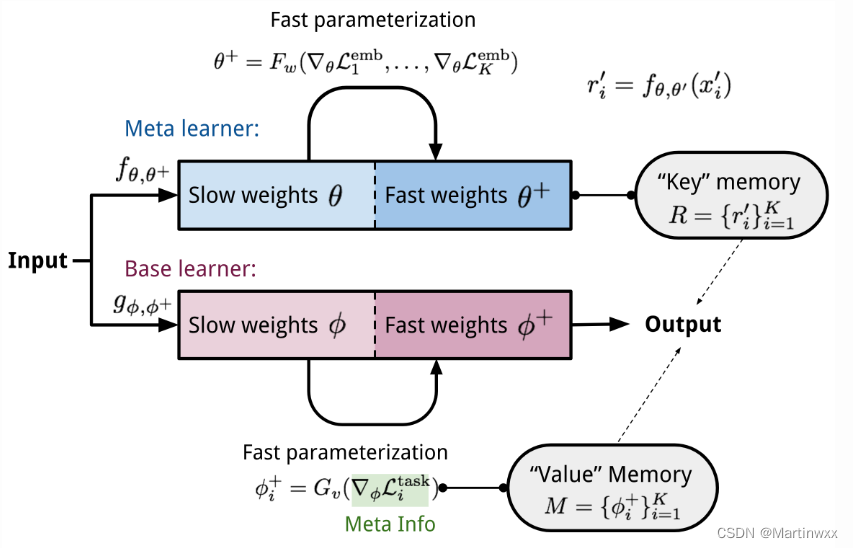
4.Meta Networks
一个专门针对 多任务间快速泛化 设计的元学习模型。
Meta Networks
Fast Weights
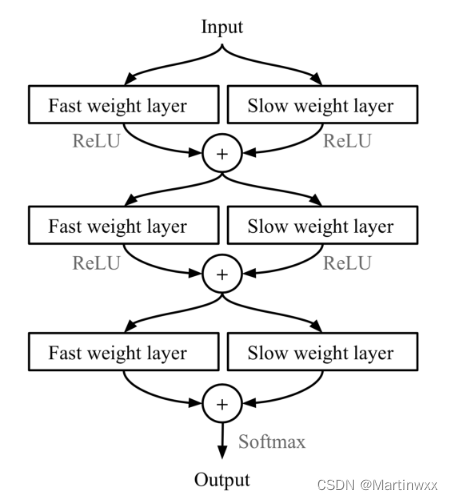
MetaNet的快速泛化能力依赖于 “快参数(Fast Weights)”,利用另外一个神经网络,预测当前神经网络的参数,预测出来的参数被称为快参数。
一般神经网络的权重是根据目标函数进行随机梯度下降更新,过程很慢,普通SGD生成的权重被称为 慢参数。
MetaNet中,损失梯度 作为 元信息 ,用于生产学习快参数的模型。慢参数和快参数 结合起来用于预测。
Fig. 8. 结合了慢参数和快参数的MLP
⊕
\oplus
⊕ is element-wise sum.
Model Components
MetaNet的关键组件:
-
f
θ
f_\theta
fθ :一个由
θ
\theta
θ 决定的编码函数,发挥元学习作用。负责将原始输入编码为特征向量。希望该编码函数可以根据其生成的特征向量判断两个输入是否属于同一类(验证任务)。
-
g
ϕ
g_\phi
gϕ : 一个由
ϕ
\phi
ϕ 决定的基学习器,完成真正的学习任务。
以上为Relation Network,在此基础增加两个快参数。
-
F
w
F_w
Fw:一个由
w
w
w 决定的 LSTM,用于学习嵌入函数
f
f
f 的快参数
θ
+
\theta^+
θ+。将
f
f
f 在验证任务上的
l
o
s
s
loss
loss 梯度作为输入。
-
G
v
G_v
Gv :一个由
v
v
v 决定的神经网络,根据基学习器
g
g
g 的
l
o
s
s
loss
loss 梯度学习其快参数
ϕ
+
\phi^+
ϕ+ 。在Meta Network 中,学习器的
l
o
s
s
loss
loss 梯度被视为任务的 元信息。
Fig.9. MetaNet的结构
训练过程

基于优化的方法
基于梯度的优化方法并不适用于仅有少量训练样本的情况,也很难在短短几步之内达到收敛.
1.LSTM Meta-Learner
使用 LSTM 的原因:
- 反向传播中基于梯度的更新和LSTM中的 cell 状态的更新有相似之处。
- 知道之前的梯度对当前的梯度更新有好处。
2.MAML
一种非常通用的优化算法,可以被用于任何基于梯度下降学习的模型。
3.First-Order MAML
上面的元优化过程依赖于二阶导数(多次迭代)。而为了加快计算,简化实现过程,一个忽略了二阶项的简化版MAML被提出了,称为 First-Order MAML (FOMAML)。
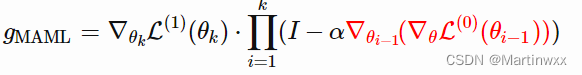
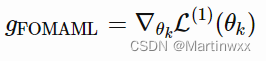
4.Reptile
一个超级简单的元学习优化算法。它跟 MAML 类似,它们都靠 梯度下降进行元优化,而且都是模型无关的算法。
Reptiled 的执行流程如下:
- 采样一个任务
- 在这个任务上进行多次梯度下降
- 把模型参数向新参数靠近
5.Reptile vs FOMAML
根据 FOMAML 与 MAML 的表现相近来看,高阶导数对于梯度更新不太重要
@article{weng2018metalearning,
title = "Meta-Learning: Learning to Learn Fast",
author = "Weng, Lilian",
journal = "lilianweng.github.io/lil-log",
year = "2018",
url = "http://lilianweng.github.io/lil-log/2018/11/29/meta-learning.html"
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)