首先庆祝踩坑踩了一万个的我终于搞懂TensorBoard的原理了,是我太蠢了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
首先说明一下Tensorboard是个神马东西,官方给出的声明:TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
都是废话!就是画图的一个工具人罢了!!!
谷歌一下TensorBoard的使用方法,清一色的用Minist手写数据集那个作为案例,好多博客也是,直接上代码看的有点迷,对于我这种没用过TensorBoard的小白来说及其不友好!!
接下来是TensorBoard的使用步骤:
一、 按照搭建TensorFlow神经网络的步骤来的话,在最后开始训练的时候,也就是调用modle.fit(一堆参数),或者生成器modle.fit_generator(又是一堆参数)这俩函数进行训练的时候,用回调函数callbacks来使用TensorBoard,如下:
model.fit_generator(略去一万个参数设置,
TensorBoard(又是一堆参数)])
二、将TensorBoard加入回调函数后,对它进行参数设置,主要有七个参数:
1、log_dir: 用来保存Tensorboard的日志文件等内容的位置
2、histogram_freq: 对于模型中各个层计算激活值和模型权重直方图的频率。
3、write_graph: 是否在 TensorBoard 中可视化图像。True/False
4、write_grads: 是否在 TensorBoard 中可视化梯度值直方图。True/False
5、batch_size: 用以直方图计算的传入神经元网络输入批的大小。
6、write_images: 是否在 TensorBoard中将模型权重以图片可视化。
7、update_freq: 常用的三个值为’batch’ 、 ‘epoch’ 或 整数。当使用 ‘batch’ 时,在每个 batch 之后将损失和评估值写入到 TensorBoard 中。 ‘epoch’ 类似。如果使用整数,会在每一定个样本之后将损失和评估值写入到 TensorBoard 中。
比如说用生成器调函数
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=10,
initial_epoch=0,
callbacks=[checkpoint_period, reduce_lr,TensorBoard(log_dir="MyBoard",write_grads=True,histogram_freq=0)])
三、运行训练代码,训练完成后,右击自己设置的log_dir文件夹,show in explorer,复制当前路径地址,如果训练成功当前路径下会有一个events.out开头的文件。如下:

有个问题,如果运行报错If printing histograms, validation_data must be provided, and cannot be a generator
解决办法是:histogram_freq=0,先关了别用,或者就用fit写,别用生成器。
接下来就要开始用tensorboard了!
首先cmd打开命令行,激活你的代码环境,进去你上一步复制的路径,盘符跳转就打个盘号加冒号就行,然后cd 你复制的路径

然后调用
tensorboard --logdir=你创建的文件夹名字
之后会生成一个网址,在屏幕下方,类似于http:/你的电脑名/6006,复制到浏览器打开,最好用谷歌或者火狐,然后就能查看生成的各种可视化结果了。
如果出现这个网址打不开或者图片加载不出来的问题,在上方命令后面加上--host 127.0.0.1,如下:
tensorboard --logdir=Mytensorboard --host=127.0.0.1
最后生成的就是http://127.0.0.1:6006这种,然后进去就可以了。
还有一个方法是不在cmd里面写代码,在pycharm的terminal里面写就能加载出来,很迷,我也是看的别人博客说的顺便记录一下。
四、打开网址你会看见这
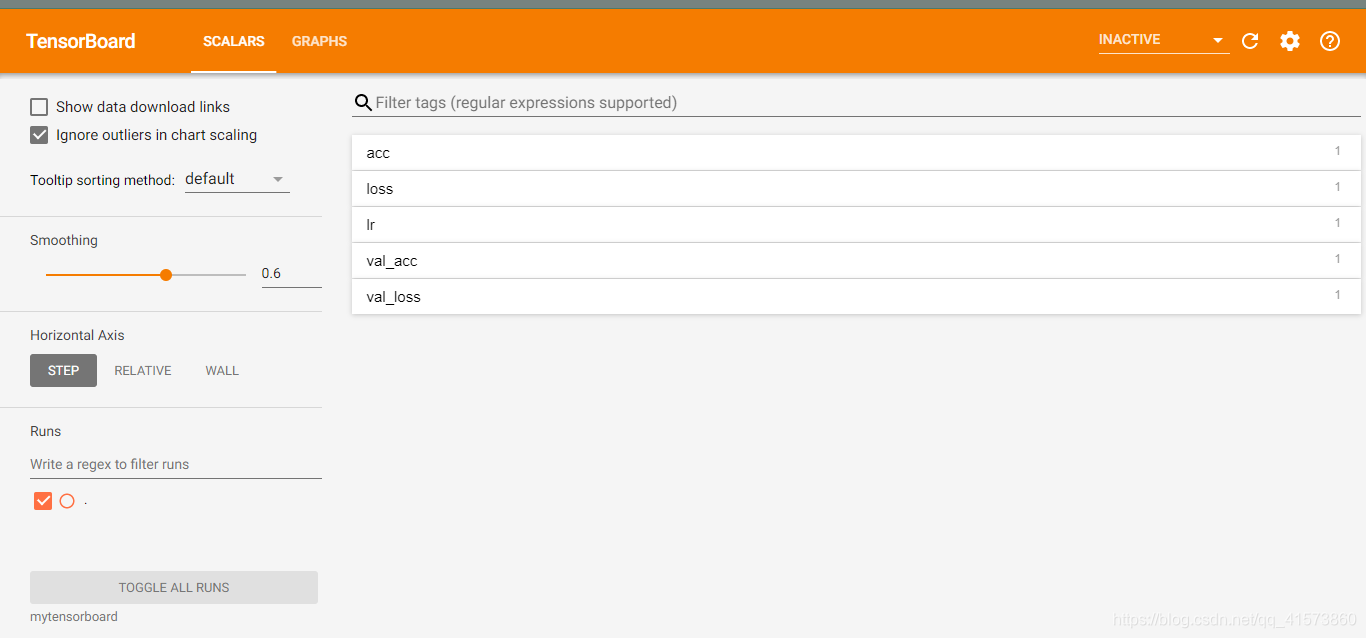
上面的图只是部分可视化功能,全部可视化功能还有很多很多,如下:

1.Scalars面板可视化
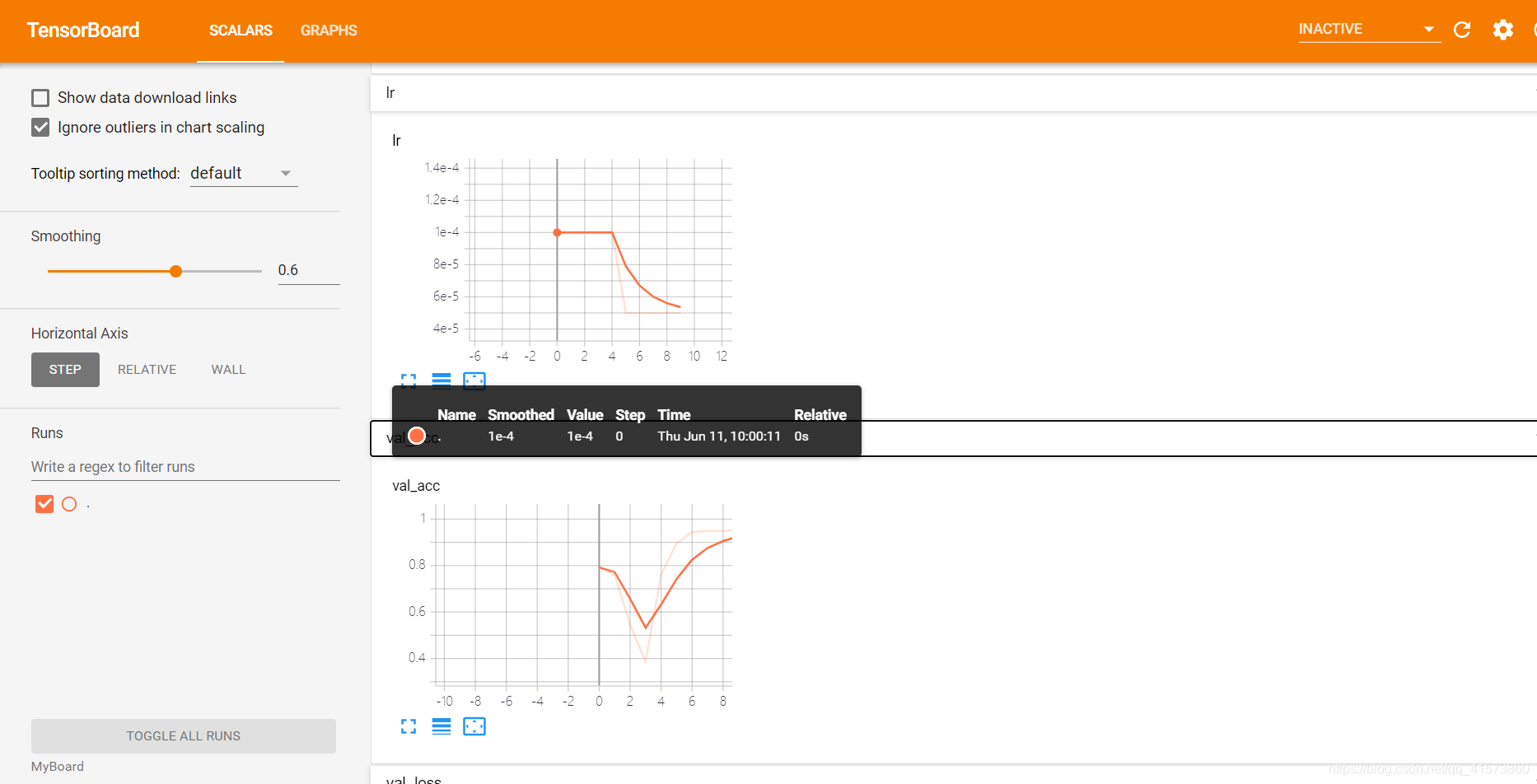
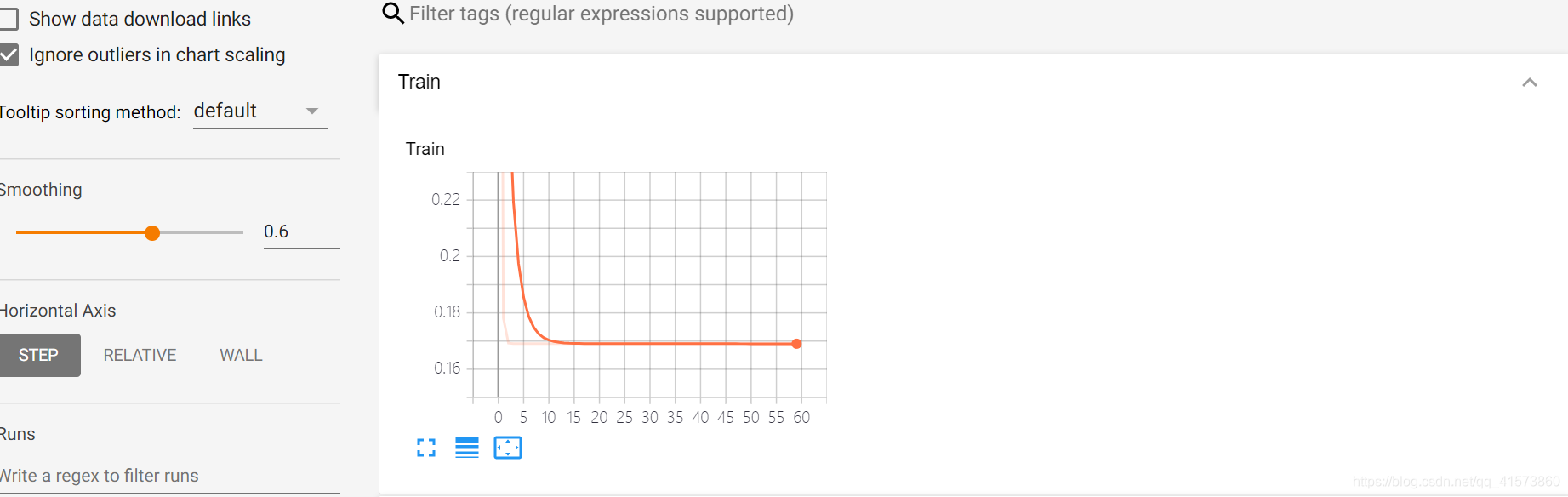
Scalars这个面板是最最长常用的面板,主要用于将神经网络训练过程中的acc(训练集准确率)val_acc(验证集准确率),loss(损失值),weight(权重)等等变化情况绘制成折线图。
它左边有一些参数设置:
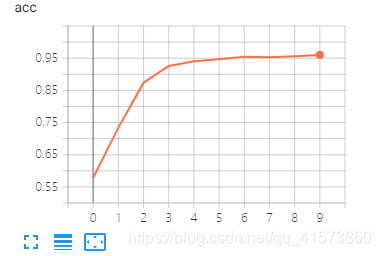
Ignore outlines in chart scaling(忽略图表缩放中的轮廓),可以消除离散值
关了:
开着:
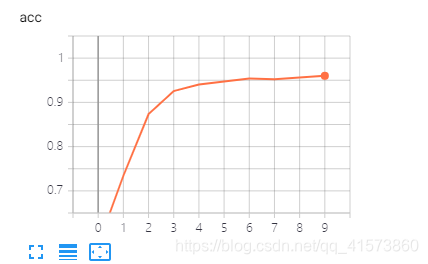
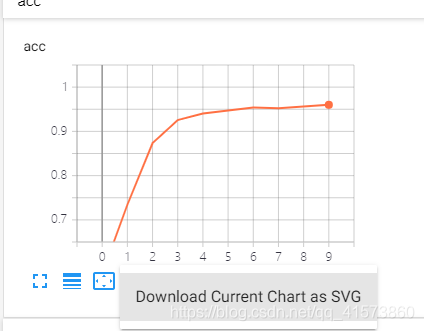
data downloadlinks(数据下载链接)
就是下面加了个下载链接
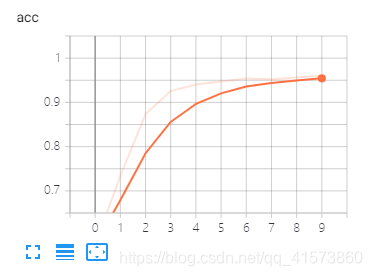
smoothing(图像的曲线平滑程度),较暗的是原曲线,值越大越平滑。
Horizontal Axis(水平轴)的表示,其中水平轴的表示分为3种(STEP代表迭代次数,RELATIVE代表按照训练集和测试集的相对值,WALL代表按照时间。
可以鼠标选中一块区域观察:
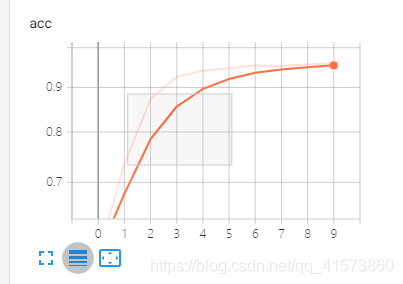
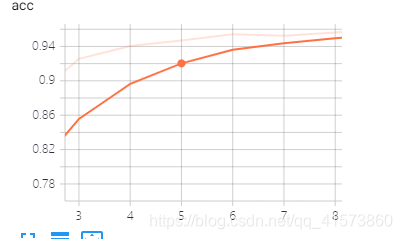
第二个按钮可以复原
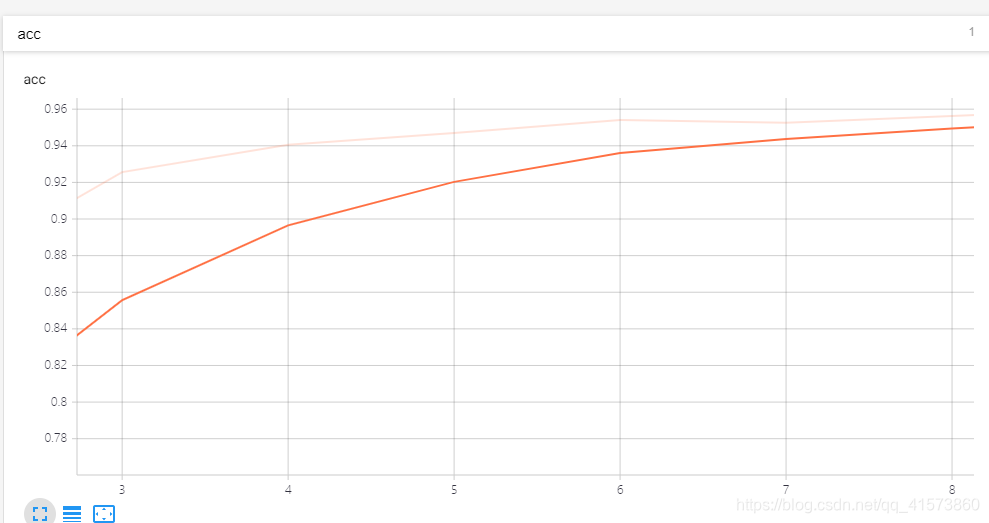
下面那三按钮可以放大图像看细节,将鼠标移到曲线上会显示该点的一些参数,具体可以自己试一试,一试就啥都会了。
2.Images面板
这个面板会展示训练数据和测试数据在进行预处理后的图片,一般我不用,因为数据量很大,加载可慢.....
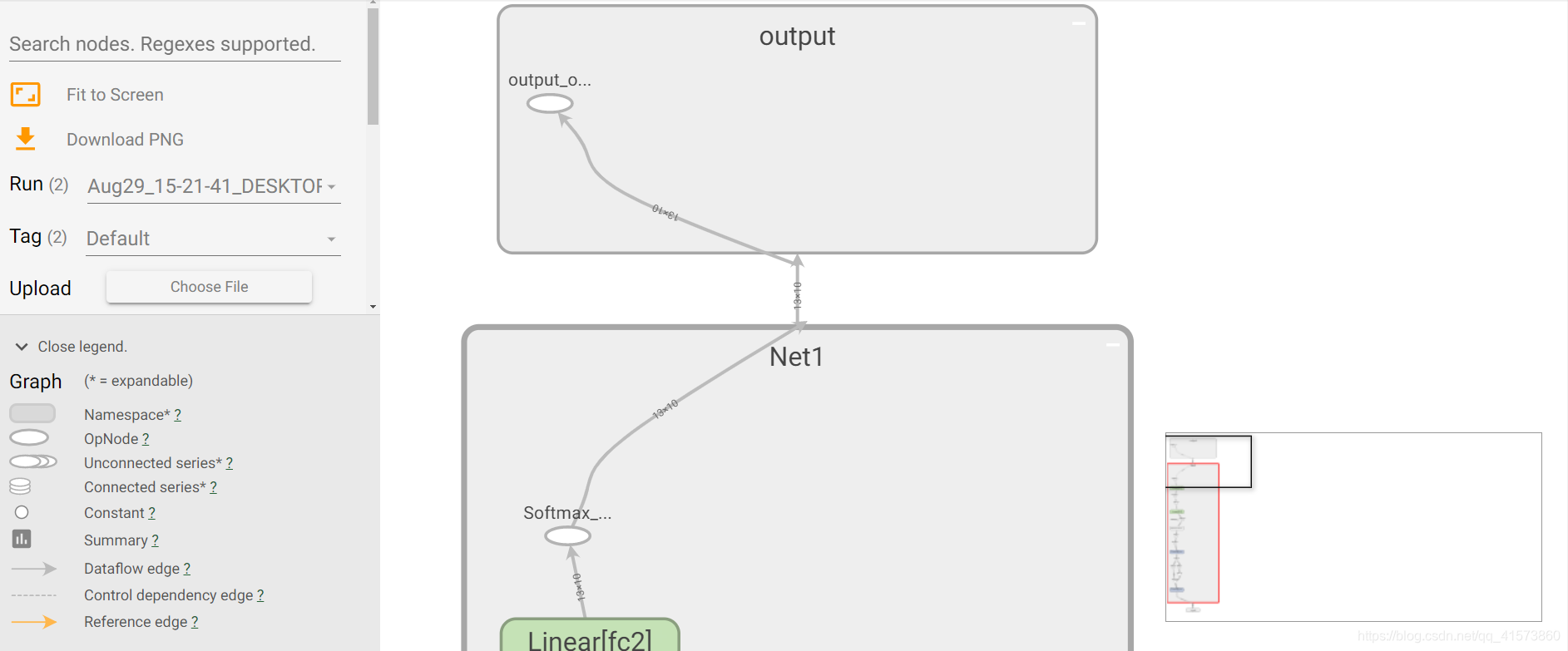
3.Graphs面板

这个面板也很常用,它里面画的都是数据流图,主要用于帮助我们理解神经网络的结构,两个节点的连线就是数据流,线的粗细表明两者之间流动的张量多少,越粗越多。右下角是缩略图,滚轮可以操作放大缩小,单击滑动区域或者在右下角选中。
在左侧可以选择迭代步骤,可以用不同的颜色来表示不同的Structrue(整个数据流图的结构),TPU Compatibility要查看模型的TPU 兼容性图,请在TensorBoard中选择“图形”选项卡,然后选择“ TPU 兼容性”选项。该图以绿色表示兼容(有效)操作,以红色表示不兼容(无效)操作,还有其他的如下:

自己可以慢慢试,其它面板暂时没用到,慢慢更新吧!
Pytorch下使用TensorBoard进行可视化
首先激活环境,然后通过命令安装tensorboardX,tensorboardX是用来提供给其他深度学习框架使用TensorBoard的一个包,TensorFlow这个做的贼好
pip install tensorboardX
还得安装TensorFlow
pip install tensorflow
非常注意的一点:这里你安装的TensorFlow版本必须要和tensorboardX一致,否则就会出现各种错误,比如生成的文件没有数据
安装好了之后就可以使用了
Scalar的使用
导包后往里面放数据就行,第一个参数是名称,第二个是y坐标,第三个是x坐标,通过add_scalar进行参数的添加。
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='scalar')
for epoch in range(100):
writer.add_scalar('scalar/test', np.random.rand(), epoch)
writer.add_scalars('scalar/scalars_test', {'xsinx': epoch * np.sin(epoch), 'xcosx': epoch * np.cos(epoch)}, epoch)
writer.close()
生成event文件后,找到对应目录,cmd进入到它的上一层,然后使用命令***是你存放文件的目录
tensorboard logdir ***

如我的就是tensorboard logdir scalar

将这个IP地址复制到浏览器打开即可,最好使用谷歌浏览器。
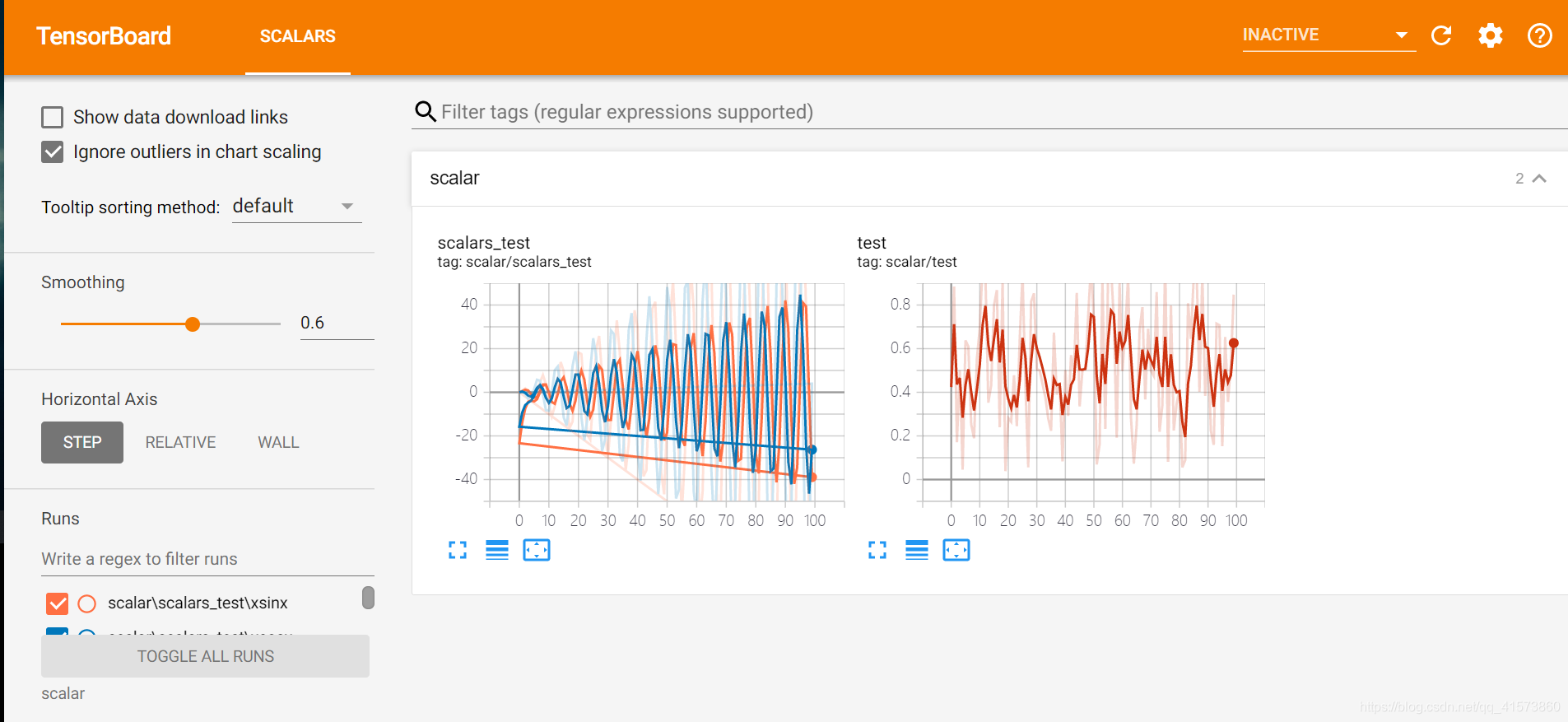
Graph的使用
导包后,通过add_graph将模型传入,并将输入也传入。
import torch
import torch.nn as nn
import torch.nn.functional as F
from tensorboardX import SummaryWriter
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.bn = nn.BatchNorm2d(20)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = self.bn(x)
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.softmax(x, dim=1)
return x
dummy_input = torch.rand(13, 1, 28, 28)
model = Net1()
with SummaryWriter(comment='Net1') as w:
w.add_graph(model, (dummy_input,))
然后就可以看见网络的流图了
生成loss
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)