一、LaneNet
- 论文
- 代码:github, python, tensorflow 1.15
1.1 主要过程
![[Image]](https://img-blog.csdnimg.cn/1ee2cd9d4488439790115a07b727e574.png)
- inference,分上下两个分支,如图
- Enocder-decoder stage: 图像空间编码为emb空间,方便聚类
- Binary semantic segmentation stage:语义分割,区分背景与车道线,输出二值mask
- 聚类阶段:根据E-Net阶段的结果,使用Mean-Shift算法实现聚类,获得实例分割结果.
- Fit阶段:使用二次函数对实例分割结果进行拟合
- 论文中阐述,以上输出的是每条车道线的像素集合。要根据这些像素点回归出一条车道线,传统方法是投射到BEV,然后用2阶/3阶多项式拟合,这时,变换矩阵H只计算一次,会导致非平面下的误差。因此使用H-Net以图像为输入,对每一帧预测一个含有6个参数的变换矩阵H。
- 代码中,直接load的数据集提供的相关矩阵参数.
1.2 数据集Tusimple_Lane_Detection
- 原图尺寸:720x1280
- 模型输入尺寸:256x512
- 我们的图像输入:1080x1920,需要修改代码对应位置,仍保持输入尺寸256x512
- Tusimple 数据的标注特点:
1、车道线实际上不只是道路上的标线,虚线被当作了一种实线做处理的。这里面双实线、白线、黄线这类信息也是没有被标注的。
2、每条线实际上是点序列的坐标集合,而不是区域集合 - 标注过程:将图片的下半部分,如70%的高等分为N份,然后取车道线(无论虚实)与该标注线交叉的点。因此,我们标注的话,标注车道线,然后去生成即可。需要哪些相机参数待check.
- 网上有生成自己的Tusimple类型数据集的示例代码。
1.3 测速
暂时未找到trt,测试基于python的tensorflow 1.15
- 论文和github报告速度:
- 1080Ti上,模型inference部分原文52FPS,更新为BiseNetV2后提升到78FPS.
- 对于聚类和Fit阶段,论文中4.6ms即可完成,但这受到cpu性能的影响。
- 我们的在Xavier上测速:
- inference cost time (500张平均): 0.05452s
- postprocess cost time : 0.1-0.5s
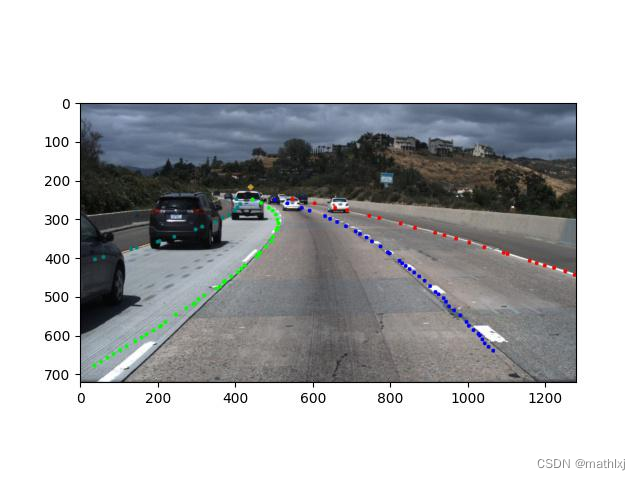
1.4 效果
我们直接使用网上根据Tusimple训练好的模型,
二、SCNN
- 论文:链接
- github:
- 官方代码,luna、matlab等
- 第三方pytorch,无pretrain model,集成了很多模型
- 第三方tensorflow
2.1 主要过程
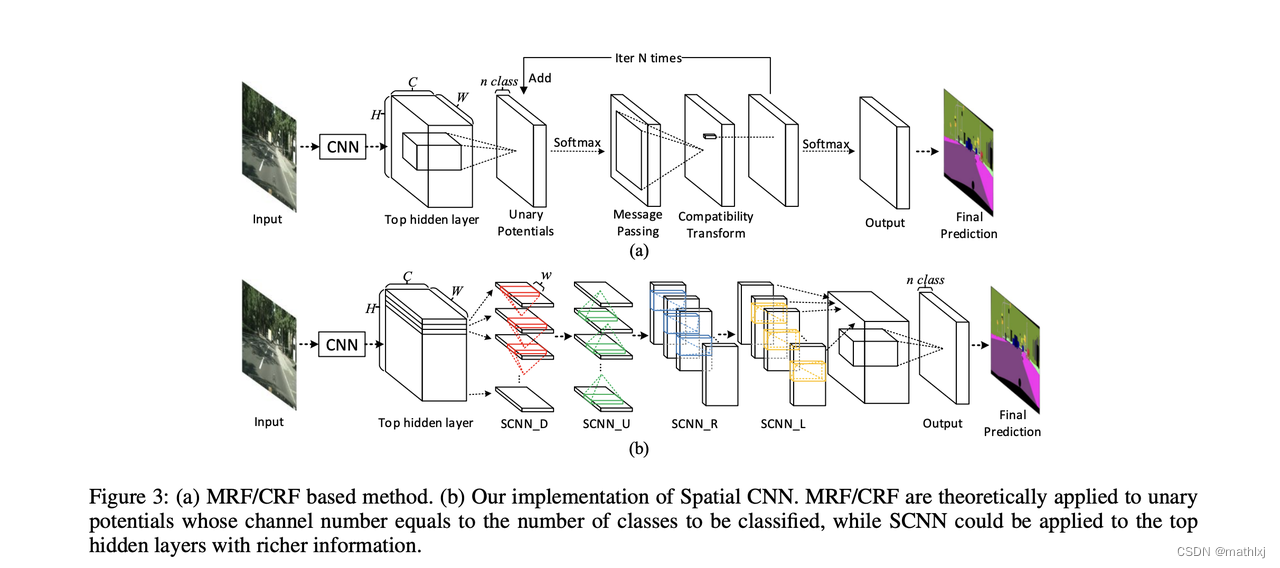
- 将传统的deep layer-by-layer convolutions替换为slice-by-slice convolutions ,这可以使得信息可以在图像的行列之间传递。
- 将lane detection定义成语义分割的任务,将每一条线通过一个预设的类别去定义,即使省去了LaneNet中cluster这种复杂操作,也可区分出不同线的实例
- 作者加了一个线的存在性判断分支,大于0.5认为是线。在prediction heatmap上每隔20行搜索相应值最高的位置,然后通过三次样条函数拟合这些points。
- 局限性
(1)通过线的实例来定义类别会导致必须设一个类别数量的上限值,只能处理车道线条数不大于上限值的情况。
(2)分割采用backbone+SCNN的结构。在paper中backbone选用的是LargeFOV(Deeplabv2),而SCNN能占到整个网络1/3左右的计算量,在实际工程应用中没法达到实时的性能。
2.2 数据集 CULane Datesets
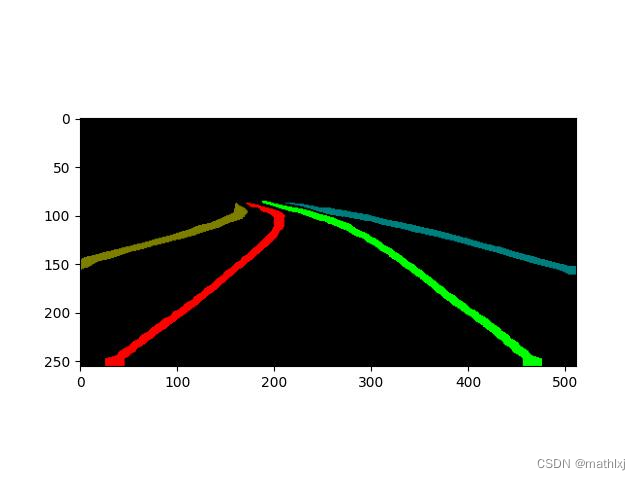
作者针对Caltech、Tusimple等数据集场景单一、数据量少、难度低等问题,用6辆车在北京不同时间录制了超过55小时,标注了133235张图片,超过Tusimple Dataset20倍的数据量。论文分成88880张作为训练集, 9675作为验证集,34680做测试集。数据集包含城市、农村高速等场景,每张图片用最多4条线进行标注[对应也是4个车道线],对向车道不标,对遮挡部分也标出来。数据集的分布如图:

注意,该数据集分辨率为800x200
2.3 测速
2.4 效果
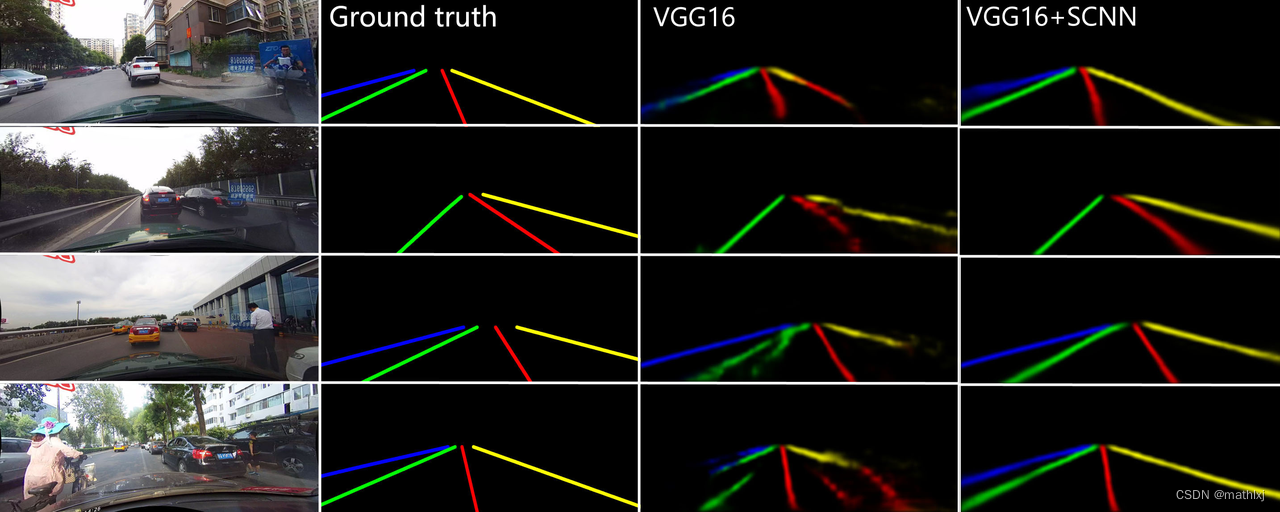
- 论文报告
三、Ultra-Fast-Lane-Detection ECCV2020
- 论文:链接
- 代码:github, python, pytorch
- 数据集:Tusimple & CULane
3.1 测速
backbone ResNet18 输入尺寸 288x800
- 论文 or github 报告
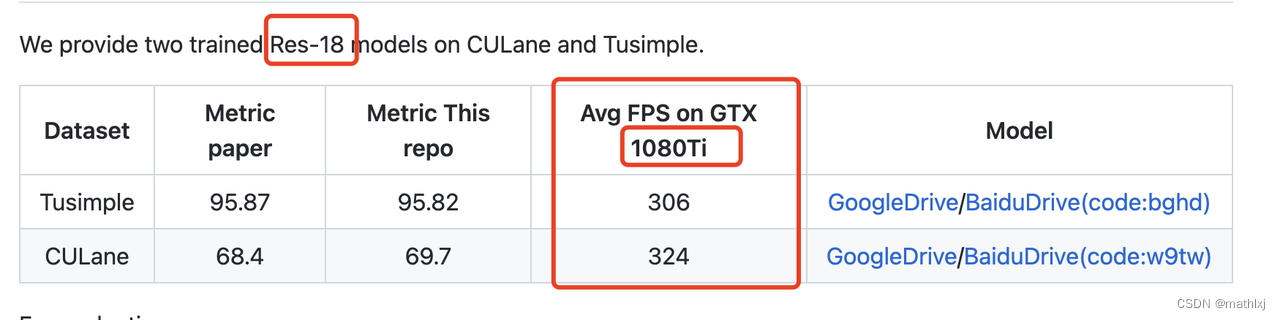
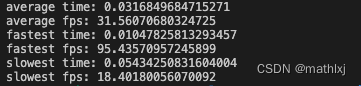
- 我们在Xavier上测速 平均31.6FPS
3.2 效果
- 论文效果

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)