(自然场景OCR检测(YOLOv3+CRNN))(中文+英文模型)
前言
最近对于自然场景下的OCR比较有兴趣,所以总结了一些目前OCR现状,并且找了一个自然场景OCR的项目练练手。本人新手小白,若出现理解不当的地方,还望指出。
简介
目前的主流自然场景OCR模型:文字检测+文字识别

文字检测:解决的问题是哪里有文字,文字的范围有多大。
主要方法:
1.CTPN:水平文字检测,四个自由度,类似物体检测(常用成熟基础)。
2.目标检测:如YOLO、SSD、Mask-R-CNN。
3.Seglink:倾斜文本检测,文本框是不规则的四边形,八个自由度。
4.RRPN:允许带角度的矩形框覆盖。
5.EAST:允许带角度矩形框或任意四边形覆盖。
6.TextBox:水平矩形框。
7.TextBox++:旋转矩形框。
8.TextSnake:圆盘覆盖的方法。
文字识别:对定位好的文字区域进行识别,主要解决的问题是每个文字是什么,将图像中的文字区域进转化为字符信息。

主要方法:

1.CRNN(CNN+RNN(BLSTM)+CTC)
2.CNN+Seq2Seq+Attention
此项目采取CTPN + YOLO v3 + CRNN方式进行OCR识别,下面对该方案进行一个大致讲解(需对照源码理解)。
源码地址:https://github.com/chineseocr/chineseocr
整个项目代码(包含本人对代码详细注解):https://download.csdn.net/download/qq_39706357/13193446
一、检测文字朝向,调整文字识别倾斜角度
1.检测文字朝向(ROTATE = [0,90,180,270])
剪切图像边缘,将图像变成(224,224,3)尺寸,图像channel中心化处理,读取Angle-model(vgg16 : 5层卷积,2层全连接,最后经过softmax预测),预测文字朝向,旋转图片。
2. 调整文字识别倾斜角度
将新生成的图像进行灰度化处理,将图像缩放在一个尺度范围内(600~900),图像归一化处理(原图与归一化之后的运行结果完全一致,说明归一化不会改变图像本身的信息存储,但是通过打印出来的像素值可以发现,取值范围从0~255已经转化为0~1之间了,这个对于后续的神经网络或者卷积神经网络处理有很大的好处),进行多维百分比滤波处理,修剪(原图-模糊处理后的图像+1),裁剪边框。
计算图像每行的均值向量,得到该向量的方差。如果图像文字不存在文字倾斜(假设所有文字朝向一致),那么对应的方差应该是最大,找到方差最大对应的角度,就是文字的倾斜角度。本项目中,只取了-15到15度,主要是计算速度的影响,如果不考虑性能,可以增大修正角度。
二、检测文字区域
1.目标区域检测(text_detect)
图像预处理:关于图像中文字的标注是范围框选的,然后在每个框中对其进行宽为8,高为Box高的分割,即CTPN,每一个小框作为的true_boxes,如下图所示

1)darknet53:

上图是以输入图像256 x 256进行预训练来进行介绍的,常用的尺寸是416 x 416,都是32的倍数。(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid)。
2)feature extractor

最后的输出 feature map[y1, y2, y3] ,每个像素num_anchors*(num_classes+5)( 4个边界框偏移量,1个目标性预测)
3)变换格式
将图像的标注框true_boxes的标签,变成与预测anchor box相同的格式标签y_true
现在有很多的true_boxes,我们想要把y_true的表示分为三层,所以就需要将true_boxes分给不同的三层特征,将true_boxes与9个anchors进行iou计算,因为每层的有三个anchors,将true_boxes分给对于9个anchors中与其最大iou的anchor,所在的特征层。最后转换成y_true的表达形式,后转换成y_true的表达形式,得到的y_true是相对feature真实坐标。
preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
input:
true_boxes: array, shape=(m, T, 5) m = 批量数 T = 最大框数
input_shape:图像尺寸
anchors: array, shape=(N, 2), wh
output:
y_true = [num_layers, m, grid_shape[0], grid_shape[1], anchors_number = 3, 5+ num_classes ]
y_true的第0和1位是中心点xy,范围是(0 ~ 13/26/52),xy的值0 ~ 1(在feature map像素点中),第2和3位是宽高wh,范围是0 ~ 1,第4位是置信度1或0,第5 ~ n位是类别为1其余为0.
实现方法:设y_true是全0矩阵(np.zeros)列表,即[(m,13,13,3,6),(m,26,26,3,6),(m,52,52,3,6)],将图像中的标注框box在原图中的长宽与9个anchor box长宽进行iou计算,找出与每个标注框box iou值最大的anchor box,因为每个anchor所在的feature map和y_true[4]是固定的,找到这个anchor所在的feature map和y_true[4] (anchor在(0,1,2))中序号位置,再利用true_boxes的xy坐标,确定出其所在feature map的 grid位置(i,j),最后用true_boxes[3]去替换y_true中相应grid中的预测框中心点xy在这个gird的0~1值,wh的0 ~ 1值,confidence(置信度) = 1,所对应的类别 = 1.
4)Loss function
将预测的feature map[y1, y2, y3]与y_true送入loss function:
一、将预测的yolo_outputs (feature map[y1, y2, y3])送入yolo_head函数,输出grid(目标在grid的位置,shape:[gridxgridx1x2]), raw_pred(预测的输出,shape:[Nxgridxgridx3x(5+num_classes)]), pred_xy(预测的xy在grid上归一化的真实值,shape: [Nxgridxgridx3x2]), pred_wh(预测的wh在grid上归一化的真实值,shape: [Nxgridxgridx3x2])。
yolo_head: 1.grid:建立横纵坐标系生,跟feature map大小一致[gridxgridx1x2], grid是feature map中grid cell的左上角坐标。2. box_xy:将yolo_outputs中的xy坐标,先经过sigmoid函数,后加上偏移量,最后除以grid,也就是(sigmoid(x,y)+grid左上坐标) / grid。3. box_wh:将yolo_outputs中的wh长度,先进行e为底的幂计算,后跟anchor进行乘法计算,然后除以grid。
二、将y_true中的xywh真实值,通过上述公式换算成偏移量raw_true_xy、raw_true_wh,y_pre也为偏移量。
(1)xy_loss = confidence * box_loss_scale * 二分类的交叉熵(y_true, y_pred)
设定 box_loss_scale = 2 – wh,wh是y_true的wh,于是wh越小,box_loss_scale越大, 实际上,我们知道yolov1里作者在loss里对宽高都做了开根号处理,是为了使得大小差别比较大的边框差别减小。因为对不同大小的bbox预测中,想比于大的bbox预测偏差,小bbox预测偏差相同的尺寸对IOU影响更大,而均方误差对同样的偏差loss一样,为此取根号。例如,同样将一个 100x100 的目标与一个 10x10 的目标都预测大了 10 个像素,预测框为 110 x 110 与 20 x 20。显然第一种情况我们还可以接受,但第二种情况相当于把边界框预测大了 1 倍,但如果不使用根号函数,那么损失相同,显然加根号后对小框预测偏差10个像素带来了更大的损失。而在yolov2和v3里,损失函数进行了改进,不再简单地加根号了,而是用scale = 2 - groundtruth.w * groundtruth.h加大对小框的损失。
(2)wh_loss = confidence * box_loss_scale * 0.5 * 均方误差(y_true, y_pred))
边框回归最简单的想法就是通过平移加尺度缩放进行微调,这里虽然wh回归不是线性回归,但是当输入的 Proposal 与 Ground Truth 相差较小时,即IOU很大时(RCNN 设置的是 IoU>0.6),可以认为这种变换是一种线性变换,那么我们就可以用线性回归(线性回归就是给定输入的特征向量 X, 学习一组参数 W, 使得经过线性回归后的值跟真实值 Y(Ground Truth)非常接近. 即Y≈WX )来建模对窗口进行微调, 否则会导致训练的回归模型不work(当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然就不合理了)

所以,边框回归微调时,可以当作线性回归。
(3)confidence_loss = confidence * 二分类的交叉熵(y_true, y_pred) + (1- confidence) * 二分类的交叉熵(y_true, y_pred) * ignore_mask)
ignore_mask:即confidence为反面的mask。将目标y_true中有是否有目标转成bool型生成true_box,然后同pred_box计算iou,pred_box(13,13,3,4)与真实窗口true_box(设有j个)之间的IOU,输出为iou(13,13,3,j),best_iou(13,13,3)值是最大的iou,删掉小于阈值的BBOX,ignore_mask[b]存放的是pred_box(13,13,3,4)iou小于ignore_thresh的grid,即ignore_mask[b]=[13,13,3],如果小于ignore_thresh,其值为0;大于为1。
(4)class_loss = confidence * 二分类的交叉熵(y_true, y_pred)
为什么多分类问题用二值交叉熵解决?
里,我们可以理解为,“所有的分类都预测正确”为一个类1,否则就是另一个类0。这样就把多分类看做是二分类问题,当且仅当所有的分类都预测对时,loss最小
最后分别对loss进行简单的加总求和取均值.
loss = [‘class_loss’,‘xy_loss’,‘wh_loss’,‘confidence_loss’]
细节补充:
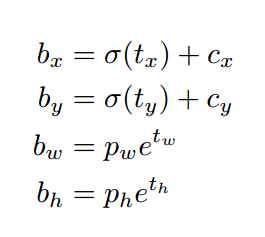
其中,Cx,Cy是feature map中grid cell的左上角坐标,在yolov3中每个grid cell在feature map中的宽和高均为1。如下图的情形时,这个bbox边界框的中心属于第二行第二列的grid cell,它的左上角坐标为(1,1),故Cx=1,Cy=1.公式中的Pw、Ph是预设的anchor box映射到feature map中的宽和高。

最终得到的边框坐标值是bx,by,bw,bh即边界框bbox相对于feature map的位置和大小,是我们需要的预测输出坐标。但我们网络实际上的学习目标是tx,ty,tw,th这4个offsets,其中tx,ty是预测的坐标偏移值,tw,th是尺度缩放,有了这4个offsets,自然可以根据之前的公式去求得真正需要的bx,by,bw,bh4个坐标。至于为何不直接学习bx,by,bw,bh呢?因为YOLO 的输出是一个卷积特征图,包含沿特征图深度的边界框属性。边界框属性由彼此堆叠的单元格预测得出。因此,如果你需要在 (5,6) 处访问该单元格的第二个边框bbox,那么你需要通过 map[5,6, (5+C): 2*(5+C)] 将其编入索引。这种格式对于输出处理过程(例如通过目标置信度进行阈值处理、添加对中心的网格偏移、应用锚点等)很不方便,因此我们求偏移量即可。那么这样就只需要求偏移量,也就可以用上面的公式求出bx,by,bw,bh,反正是等价的。另外,通过学习偏移量,就可以通过网络原始给定的anchor box坐标经过线性回归微调(平移加尺度缩放)去逐渐靠近groundtruth。
那么4个坐标tx,ty,tw,th是怎么求出来的呢?
tx = Gx – Cx ty = Gy – Cy 这样就可以直接求bbox中心距离grid cell左上角的坐标的偏移量。
w和th的公式yolov3和faster-rcnn系列是一样的,是物体所在边框的长宽和anchor box长宽之间的比率,不管Faster-RCNN还是YOLO,都不是直接回归bounding box的长宽而是尺度缩放到对数空间,是怕训练会带来不稳定的梯度。因为如果不做变换,直接预测相对形变tw,那么要求tw>0,因为你的框的宽高不可能是负数。这样,是在做一个有不等式条件约束的优化问题,没法直接用SGD来做。所以先取一个对数变换,将其不等式约束去掉,就可以了。
训练时用的groundtruth的4个坐标去做差值和比值得到tx,ty,tw,th,测试时就用预测的bbox就好了,公式修改就简单了,把Gx和Gy改为预测的x,y,Gw、Gh改为预测的w,h即可。
网络可以不断学习tx,ty,tw,th偏移量和尺度缩放,预测时使用这4个offsets求得bx,by,bw,bh即可。
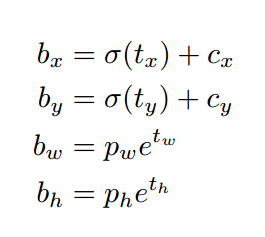
这个公式tx,ty为何要sigmoid一下啊?前面讲到了在yolov3中没有让Gx - Cx后除以Pw得到tx,而是直接Gx - Cx得到tx,这样会有问题是导致tx比较大且很可能>1.(因为没有除以Pw归一化尺度)。用sigmoid将tx,ty压缩到[0,1]区间內,可以有效的确保目标中心处于执行预测的网格单元中,防止偏移过多。举个例子,我们刚刚都知道了网络不会预测边界框中心的确切坐标而是预测与预测目标的grid cell左上角相关的偏移tx,ty。如13*13的feature map中,某个目标的中心点预测为(0.4,0.7),它的cx,cy即中心落入的grid cell坐标是(6,6),则该物体的在feature map中的中心实际坐标显然是(6.4,6.7).这种情况没毛病,但若tx,ty大于1,比如(1.2,0.7)则该物体在feature map的的中心实际坐标是(7.2,6.7),注意这时候该物体中心在这个物体所属grid cell外面了,但(6,6)这个grid cell却检测出我们这个单元格内含有目标的中心(yolo是采取物体中心归哪个grid cell整个物体就归哪个grid celll了),这样就矛盾了,因为左上角为(6,6)的grid cell负责预测这个物体,这个物体中心必须出现在这个grid cell中而不能出现在它旁边网格中,一旦tx,ty算出来大于1就会引起矛盾,因而必须归一化。
看最后两行公式,tw为何要指数呀,这就好理解了嘛,因为tw,th是log尺度缩放到对数空间了,当然要指数回来,而且这样可以保证大于0。 至于左边乘以Pw或者Ph是因为tw=log(Gw/Pw)当然应该乘回来得到真正的宽高。
记feature map大小为W,H(如13*13),可将bbox相对于整张图片的位置和大小计算出来(使4个值均处于[0,1]区间内)约束了bbox的位置预测值到[0,1]会使得模型更容易稳定训练(如果不是[0,1]区间,yolo的每个bbox的维度都是85,前5个属性是(Cx,Cy,w,h,confidence),后80个是类别概率,如果坐标不归一化,和这些概率值一起训练肯定不收敛)
只需要把之前计算的bx,bw都除以W,把by,bh都除以H。即
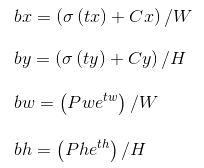
5)检测box和score
通过yolo_head将out = [y1,y2,y3]中的xywh转换成真实坐标
box_score = box_confidence * box_class_probs,box_confidence为0或者1
将box中超出图片尺寸的坐标换成在图像中对应的边缘点
box.shape = (m,4), 4是box的真实坐标(x1,y1,x2,y2),score = (m, 1)
6)预测结果

2.检测并合并proposals(TextDetector)
1. 首先过滤掉scores小于TEXT_PROPOSALS_MIN_SCORE的box
2. 进行nums,剔除掉重复的文本框
将scores展开排序,返回相应的index,将scores和boxes在水平方向上平铺,利用非极大抑制,将大于阈值的都淘汰掉,即过滤重复的box
非极大抑制:
1将所有框的得分排序,选中最高分及其对应的框
2遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除.
3从未处理的框中继续选一个得分最高的,重复上述过程。
3. 将scores进行标准化处理
data = (data-min_)/(max_-min_)
4. 合并文本行,连接文本区域变成文本行(详见代码)
TextProposalConnector.get_text_lines()
4.1) TextProposalGraphBuilder 发现可合并的文本区域
a) 创建Image.shape [ 1 ] 个[ ],shape = [batch,x,y],也就是对图像中水平方向的每个像素点,建立一个列表 [ [ ] [ ] [ ] [ ] … ] (一共x个[ ]),将每个box的x1所对应坐标的box的index插入到boxes_table的横坐标所对应的[ ]位置,构成boxes_table。
b) 计算每个index对应的box与其右侧30像素的所有box重合程度高的box的index(get_successions()函数,分别调用了MAX_HORIZONTAL_GAP,MIN_V_OVERLAPS,MIN_SIZE_SIM这三个参数作为匹配的度量),留下该index的box对应successions的box相应scores最高的index。
c) 判断当前Box的scores是否比它右侧scores最高、重叠度最好的box的左侧30像素scores最高、水平重叠度最好的box的scores还高,如果匹配成功,则将graph[index, succession_index]=True
d) 迭代查找graph中true,即从做到右依次最匹配的box,填入sub_graphs=[ ],将合并的Box的index放在一个列表里,返回这个列表sub_graphs,如[[50, 36, 58, 135, 198, 191, 204, 218, 227, 177], [52, 21, 14, 12, 9, 10, 16, 24, 120], [96, 29, 74, 171, 186, 248, 268, 277]]。
4.2) TextProposalConnector:连接文本区域
将sub_graphs列表中的Box合并,返回text_lines[文本区域的数量,8]
[0:x0(Boxes中的最小x0),1:拟合box的x0,y0坐标,取x0+offset和x1-offset,得到的lt_y, rt_y的中取最小值(offset的作用:因为存在左或者右倾斜,取最大的范围),2:x1(Boxes中的最大x1),3:拟合box的x0,y1坐标,取x0+offset和x1-offset,得到的lb_y, rb_y取最大值,4:合并的Box的平均值,5:中心点拟合函数中 x一次幂前系数,6:中心点拟合函数中 x零次幂前系数,7:box高度平均值+2.5,返回text_lines,即文本行的信息。最后再进行一个非极大抑制(因文本行较少重复,TEXT_LINE_NMS_THRESH = 0.99 ##文本行之间测iou值。)
4.3) 变换坐标(get_boxes( ))
因存在旋转,所有要将之前的文本框变成旋转的矩形,详细转换过程如下图所示

将text_lines的8个值通过get_boxes变换,生成一个(len(bboxes),[x1,y1,x2,y2,x3,y3,x4,y4])数组,四个坐标点分别为左上,右上,左下,右下。再通过sort_bo对bounding box进行排序,根据竖直方向的从上至下排序。
5. 检测结果

(上述检测结果存在些许问题,由于这张图片检测的难度较大,可以将检测的参数阈值设置高些)
最后返回[len(bboxes),[x1,y1,x2,y2,x3,y3,x4,y4]] 输入crnnRec进行文字检测
三、检测文字
1. 图像预处理
1.计算每个bounding box的角度
2.选装bounding box框出的部分,并裁剪出来
3. 把bounding box旋转到正确的方向
4. 转为灰度图
5. 送入网络识别
2. crnnOcr(test版)
1) 预处理
对图片进行按比例裁剪,裁剪出高为32的图片,处理后的图片尺寸为[1,1,32,scale×w]
2) 加载crnnOcr模型,检测出预测结果
CRNN模型:


上图为论文模型(输入图片尺寸大小为100×32),这里,我们以128×32大小的图片为例
partImg[1,128,32]先经过经过以上CNN处理,得到feature map[batch, channels, height, weight] ,cnn输出将height变成1,去掉该维度,把 width 当做LSTM 的时间 time steps, 这样就变成了 [width, batch, channels] = [16, b, 516] 对应LSTM 的输入 [n_steps, batch_size, output]
也就是将feature map的每一列或者每几列作为一个时间序列输入特征,送入RNN(双向LSTM),最后输出[T, b, n_class(5530个汉字)],最终的输出结果直观上可以想象成将128分为16份,每一份对应5530个类别的概率。
输出pre为[16,1,5530]
3) 解码
1.取5530类中,概率最大的类别[16,1,5530]->[16,1]
例如:tensor([1770, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1954])
2.将以上输出对应到汉字表解码,输出相应的文本。
转换:促销
识别结果展示





识别结果:

##########################################################
如对于上述有疑问,欢迎指出,欢迎留言
参考
yolo3 https://github.com/pjreddie/darknet.git
crnn https://github.com/meijieru/crnn.pytorch.git
ctpn https://github.com/eragonruan/text-detection-ctpn
CTPN https://github.com/tianzhi0549/CTPN
keras yolo3 https://github.com/qqwweee/keras-yolo3.git
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)