
全球计算机视觉三大顶会之一 CVPR 2019 (IEEE Conference on Computer Visionand Pattern Recognition)将于 6 月 16-20 在美国洛杉矶如期而至。届时,旷视首席科学家、研究院院长孙剑博士将带领团队远赴盛会,助力计算机视觉技术的交流与落地。在此之前,旷视每周会推出一篇 CVPR'19 接收论文解读文章。本文是第 6篇,提出了一种新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位。

论文名称:Bounding Box Regression with Uncertainty for Accurate Object Detection
论文链接:https://arxiv.org/abs/1809.08545
导语
简介
方法
实验
消融实验
准确的目标检测
在 PASCAL VOC 2007 上的实验
结论
参考文献
往期解读
导语
大规模目标检测数据集会尽可能清晰地定义基本 ground truth 边界框。但是,可以观察到在标记边界框时仍会存在模糊不清的现象。
旷视研究院在本文中提出了一种全新的边界框回归损失,可用于同时学习边界框变换和定位方差。据介绍,这种新损失能极大地提升多种架构的定位准确度,而且几乎不会有额外的计算成本。所学习到的定位方差也能帮助在非极大值抑制(NMS)期间融合相邻的边界框,进一步提升定位的效果。
实验结果表明这种新方法比之前最佳的边界框优化方法更优。研究员已公开相关代码和模型:github.com/yihui-he/KL-Loss
简介
ImageNet、MS-COCO 和 CrowdHuman 等大规模目标检测数据集都会尽可能清晰地定义基本 ground truth 边界框。
但是,可以观察到一些案例中的基本 ground truth 边界框原本就是模糊的,这会让边界框回归函数的学习更加困难。图 1 (a)(c) 是 MS-COCO 中两个边界框标记不准确的示例。当存在遮挡时,边界框的范围会更不清晰,比如来自 YouTube-BoundingBoxes 的图 1(d)。
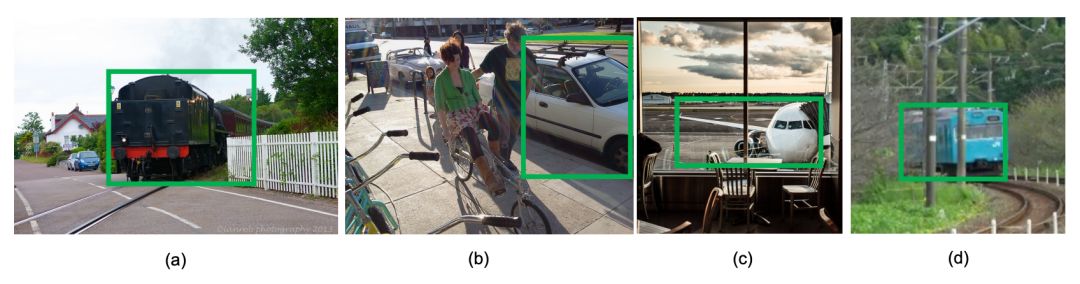
▲ 图1:边界框标注模糊的示例。(a,c) 是标注不准确,(b) 是存在遮挡,(d) 则是因为遮挡导致目标边界框本身并不清晰
目标检测是一种多任务学习问题,包含目标定位和目标分类。当前最佳的目标检测器(比如 Faster RCNN、Cascade R-CNN 和 Mask R-CNN)都依靠边界框回归来定位目标。
但是,传统的边界框回归损失(即平滑 L1 损失)没有考虑到基本 ground truth 边界框的模糊性。此外,人们通常假设当分类分数较高时,边界框回归是准确的,但事实并非总是如此,如图 2 所示。
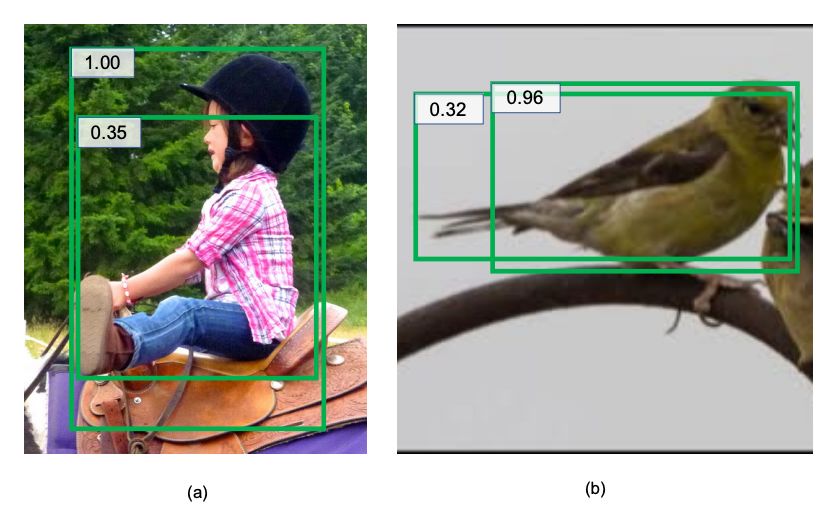
▲ 图2:VGG-16 Faster RCNN 在 MS-COCO 上的失败案例。(a) 两个边界框都不准确;(b)有较高分类分数的边界框的左边界是不准确的。
针对这些问题,本文提出了一种全新的边界框回归损失——KL 损失,用于同时学习边界框回归和定位的不确定性。
具体来说,为了获取边界框预测的不确定性,研究员首先将边界框预测和基本 ground truth 边界框分别建模为高斯分布(Gaussian distribution)和狄拉克 δ 函数(Dirac delta function)。而新提出的边界框回归损失则被定义为预测分布和基本 ground truth 分布之间的 KL 距离。
使用 KL 损失进行学习有三大优势:
1. 可以成功获取数据集中的模糊性。让边界框回归器在模糊边界框上得到的损失更小。
2. 所学习到的方差可用于后处理阶段。研究者提出了方差投票(variance voting)方法,可在非极大值抑制(NMS)期间使用由预测的方差加权的临近位置来投票得到边界框的位置。
3. 所学习到的概率分布是可解释的。因为其反映了边界框预测的不确定性,所以可能有助于自动驾驶和机器人等下游应用。
方法
下面将具体介绍这种新的损失函数和方差投票方法。
边界框参数化
在介绍新方法之前,先看看边界框参数化。本文提出基于 Faster R-CNN 或 Mask R-CNN 等两级式目标检测器(如图 3)分别回归边界框的边界。研究者将边界框表示成了一个四维向量,其中每一维都是框边界的位置。本文采用的参数化方案是 (x1, y1, x2, y2) 坐标(对角线),而非 R-CNN 使用的那种 (x, y, w, h) 坐标。
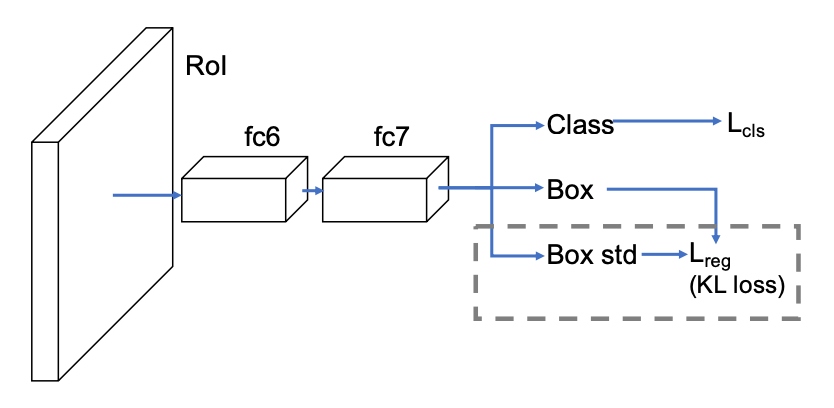
▲ 图3:本文提出的用于估计定位置信度的网络架构。不同于两级式检测网络的标准 Fast R-CNN head,这个架构是估计边界框位置以及标准差,这会在新提出的 KL 损失得到考虑。
该网络的目标是在估计位置的同时估计定位置信度。形式上讲,该网络预测的是一个概率分布,而不只是边界框位置。尽管该分布可能更复杂,可能是多变量高斯分布或高斯混合分布,但该论文为了简单起见假设坐标是相互独立的且使用了单变量高斯分布。
另外,基本 ground truth 边界框也被形式化了一个高斯分布——狄拉克 δ 函数。
使用KL损失的边界框回归
在这里,目标定位的目标是在样本上最小化预测分布和基本 ground truth 分布之间的 KL 距离。这个 KL 距离即为边界框回归的损失函数 L_reg。而分类损失则保持不变。
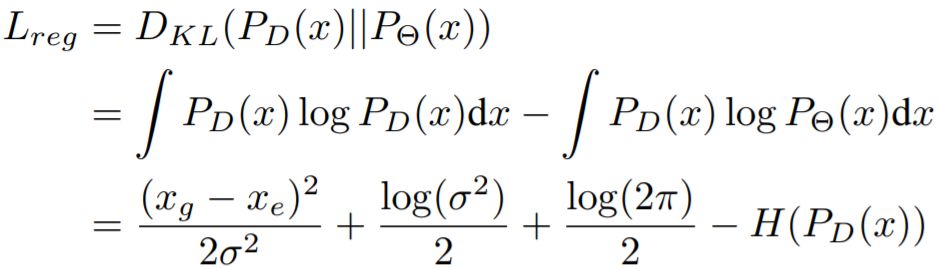
其中,x_g 为基本 ground truth 边界框位置,x_e 为估计的边界框位置,D_KL 是 KL 距离,σ 是标准差,P_D 是基本 ground truth 狄拉克 δ 函数,P_Θ 是预测的高斯分布,Θ 是一组可学习的参数。
如图 4 所示,当 x_e 不准确时,网络会预测得到更大的方差 σ²,使 L_reg 更低。
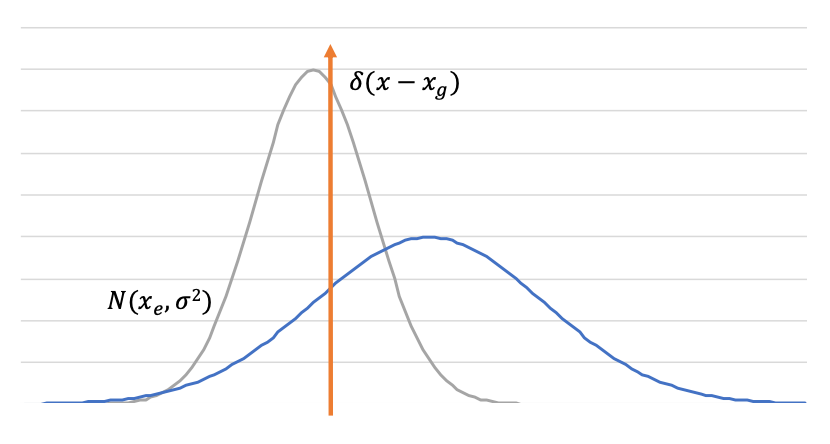
▲ 图4:蓝色和灰色的高斯分布是估计结果。橙色表示狄拉克 δ 函数,是基本 ground truth 边界框的分布。
方差投票
在获得预测位置的方差后,可根据所学习到的邻近边界框的方差直观地投票选择候选边界框位置。
如算法 1 所示,其代码基于 NMS,但有三行不一样。

本文是在标准 NMS 或 soft-NMS 的过程中投票所选框的位置。在选择了有最大分数的检测结果后,再根据它及其邻近边界框计算它本身的新位置。本文受 soft-NMS 的启发为更近的以及有更低不确定性的边界框分配了更高的权重。
在投票期间权重更低的邻近边界框包含两类:(1)高方差的边界框;(2)与所选边界框的 IoU 较小的边界框。投票不涉及分类分数,因为更低分数的框可能有更高的定位置信度。图 5 给出了方差投票的图示。使用方差投票可以避免图 2 中提到的那两类检测问题。

▲ 图5:VGG-16 Faster R-CNN 在 MS-COCO 上的方差投票结果。每个边界框中的绿色文本框对应于预测的标准差 σ。
实验
旷视研究员基于 MS-COCO 和 PASCAL VOC 2007 数据集进行了实验。实验配置细节如下:
使用了 4 个 GPU
训练流程和批大小根据线性缩放规则进行调整
VGG-CNN-M-1024 和 VGG-16 的实现基于 Caffe;ResNet-50 FPN 和 Mask R-CNN 的实现基于 Detectron
VGG-16 Faster R-CNN 遵照 py-faster-rcnn(github.com/rbgirshick/py-faster-rcnn),在 train2014 上训练,在 val2014 上测试;其它目标检测网络的训练和测试分别在 train2017 和 val2017 上完成
σ_t 设为 0.02
除非另有说明,否则所有超参数都是默认设置(github.com/facebookresearch/Detectron)
消融实验
研究者基于 VGG-16 Faster R-CNN 评估了每个模块对整体结果的贡献,包括 KL 损失、soft-NMS 和方差投票。表 1 给出了详细结果。可以看到,每新增一项改进,都能实现结果的进一步提升。
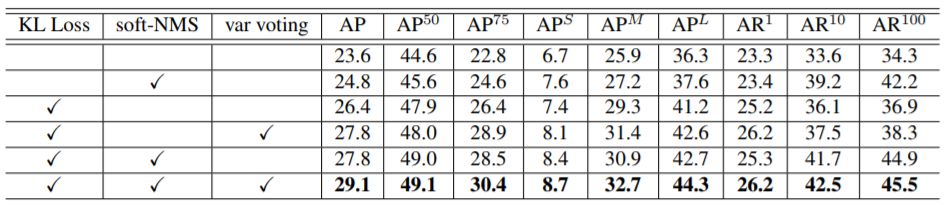
▲ 表1:使用 VGG-16 Faster R-CNN 在 MS-COCO 数据集上检验每个模块的贡献
准确的目标检测
表 4 总结了在 ResNet-50-FPN Mask R-CNN 上不同方法对准确目标检测的效果。使用 KL 损失,网络可以在训练阶段学习调节模糊边界框的梯度。

▲ 表4:在 MS-COCO 上,不同方法对准确目标检测的效果
旷视研究员还在特征金字塔网络(ResNet-50 FPN)上进行了评估,如表 6 所示。
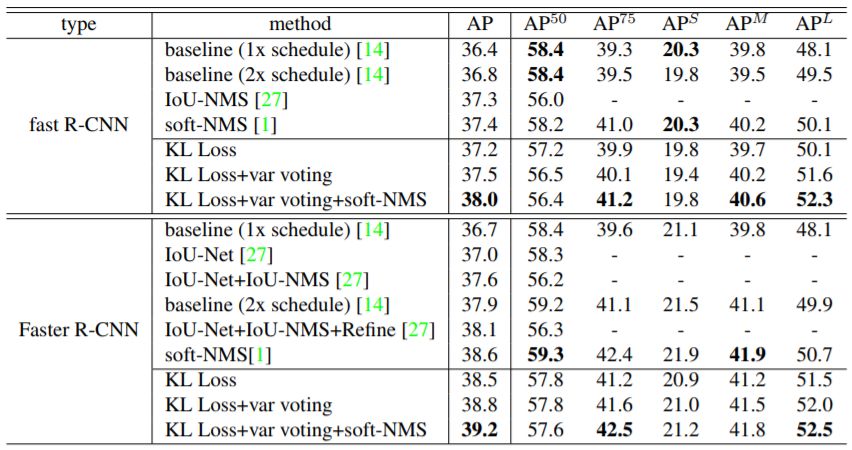
▲ 表6:FPN ResNet-50 在 MS-COCO 上的表现对比
在PASCAL VOC 2007上的实验
尽管本文是针对大规模目标检测提出了这一方法,但也可将该方法用于更小型的数据集。研究者使用 Faster R-CNN 在 PASCAL VOC 2007 上进行了实验,该数据集包含约 5000 张 voc_2007_trainval 图像和 5000 张 voc_2007_test 测试图像,涉及 20 个目标类别。所测试的骨干网络为 VGG-CNN-M-1024 和 VGG-16。
结果见表 5,研究员也额外比较了 soft-NMS 和二次无约束二元优化(QUBO)。QUBO 的结果包含 greedy 求解器和经典的 tabu 求解器(二者的惩罚项都经过了人工调整,以得到更好的性能)。可以看到,QUBO 比标准 NMS 要差得多,尽管有研究认为其在行人检测上效果更好。研究者猜测 QUBO 更擅长检测行人的原因是此时边界框遮挡的情况更多。
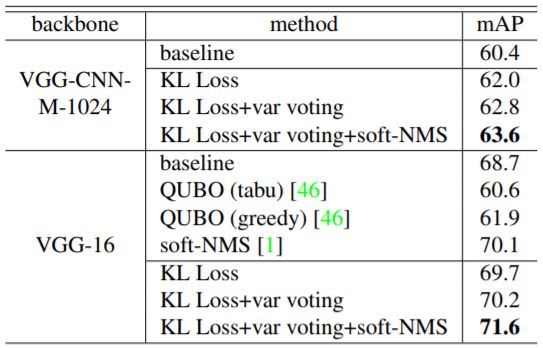
▲ 表5:不同方法在 PASCAL VOC 2007 上的结果
结论
大规模目标检测数据集中的不确定性可能有碍当前最佳目标检测器的表现。分类置信度并不总是与定位置信度强烈相关。这篇论文提出了一种全新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位。使用 KL 损失进行训练,网络可学习预测每个坐标的定位方差。所得到的方差可实现方差投票,从而优化所选择的边界框。实验结果也表明了这些新方法的有效性。
传送门
欢迎各位同学加入旷视研究院基础模型(Model)组,简历可以投递给 Model 组负责人张祥雨。
邮箱:zhangxiangyu@megvii.com
参考文献
[42] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015. 1, 2, 3, 7
[17]Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´ shick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 2980–2988. IEEE, 2017. 1, 2, 3, 5
[27]Borui Jiang, Ruixuan Luo, Jiayuan Mao, Tete Xiao, and Yuning Jiang. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), pages 784–799, 2018. 2, 7, 8
[28]Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In Advances in neural information processing systems, pages 5574–5584, 2017. 2
[29]Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. arXiv preprint arXiv:1705.07115, 3, 2017. 2
往期解读:
CVPR 2019 | 旷视提出GIF2Video:首个深度学习GIF质量提升方法
CVPR 2019 | 旷视Oral论文提出GeoNet:基于测地距离的点云分析深度网络
CVPR 2019 | 旷视提出超分辨率新方法Meta-SR:单一模型实现任意缩放因子
CVPR 2019 | 旷视实时语义分割技术DFANet:高清虚化无需双摄
CVPR 2019 | 旷视研究院提出ML-GCN:基于图卷积网络的多标签图像识别模型
点击以下标题查看更多往期内容:
CVPR 2019 | 无监督领域特定单图像去模糊
图神经网络综述:模型与应用
近期值得读的10篇GAN进展论文
小样本学习(Few-shot Learning)综述
万字综述之生成对抗网络(GAN)
可逆ResNet:极致的暴力美学
小米拍照黑科技:基于NAS的图像超分辨率算法
AAAI 2019 | 基于区域分解集成的目标检测
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐