VFH避障/局部路径规划算法
- 1、信度栅格(Certainty Grid)
- 2、势场法(Potential Field Methods)
- 3、VFH算法的前身——VFF(Virtual Force Field Method)
- 4、VFH算法
- A 第一次data reduction和构建极坐标直方图
- B 第二次data reduction和方向控制
- C 阈值的选择
- D 速度控制
- 5、我在调试的时候,发现的问题
- 引用:
做个正直的人
本文章是我看《The Vector Field Histogram-Fast Obstacle Avoidance for Mobile Robots》论文时候的笔记,感兴趣的欢迎去看原论文。
VFH中有一些概念是从其他算法中借鉴过来的,并且VFH算法本身就是对VFF(Virtural Force Field)的一种改进,其中有很多的相似之处。所以按照原论文的思路,先介绍由CMU提出的Certainty Grid算法中的一些概念,再介绍一下势场法中的一些概念,接着介绍一下VFF算法,最后介绍最重要的VFH算法。
1、信度栅格(Certainty Grid)
CMU提出的算法中最重要的思想就是The Certainty Grid for Obstacle Representation,即用一个置信度来表示这一个位置存在障碍物的可能性有多大。至于中文名字该叫什么,难道翻译成“基于置信度栅格的障碍物表示法”?
具体来说就是,把整个地图用一幅二维的栅格(grid)地图来表示,比如大小是1024*1024。机器人的工作空间(就是局部地图)也用一个二维数组来表示,这个工作空间只包括以机器人为中心的一块正方形区域,比如30*30大小。每一个grid都有一个信度值(certainty value,CV)这一个CV值表示了这一个grid中存在障碍物的可能性有多大。CMU算法,使用一个概率函数来更新每一个CV值。比如通过超声波传感器来获取周边情况。
VFH算法中工作空间中的每一个unite不再叫做grid,而是叫做cell。
2、势场法(Potential Field Methods)
势场法我觉得肯定是一个/一群物理相当不错的人提出来的。我觉得这种方法有一种天然的美感,自然、不做作。
势场法比如人工势场法(APF),思路非常简单。可以这么理解,目标位置和障碍物会通过一种叫做场(就像磁场或者电场)的东西对我们机器人施加力的作用,所不同的是,目标位置对机器人施加的是吸引力
F
a
t
t
F_{att}
Fatt ,障碍物对机器人施加的是排斥力
F
r
e
p
F_{rep}
Frep 。并且距离越远,力就越小。根据力的分析,我们的机器人总体上是受到一个合力 R 的作用,这个力就会不断的推着我们的机器人绕过障碍物到达目标位置。
3、VFH算法的前身——VFF(Virtual Force Field Method)
VFF算法使用一个二维的笛卡尔直方图栅格区域(Cartesian histogram grid,我能怎么翻译?真的翻译不出来呀!)C来表示整个区域,和CMU方法一样,VFF的每一个cell具有一个属性CV 即
c
i
,
j
c_{i,j}
ci,j 表示这一个cell存在障碍物的可能性有多大。和CMU方法不同的是,CV建立和更新的方法更加快速。
CMU是通过传感器数据来给这一个传感器范围内的每一个grid赋予概率值,VFF则是只更新每一个传感器范围内仅仅一个cell的值。打一个比方,我们拿着手电筒照射一堵墙,很明显我们的手电筒会在墙上形成一个一定大小的圆形光斑,对待这一个光斑CMU和VFF有不同的处理方法,CMU会给整个光斑区域进行更新,而VFF只会更新位于光斑中心位置的那一个点,那其他的点怎么办?不用担心,我们的机器人是在运动的呀,虽然只更新一个点,但是点动成线,扫过去不就连续更新了嘛?看下图就清楚了。
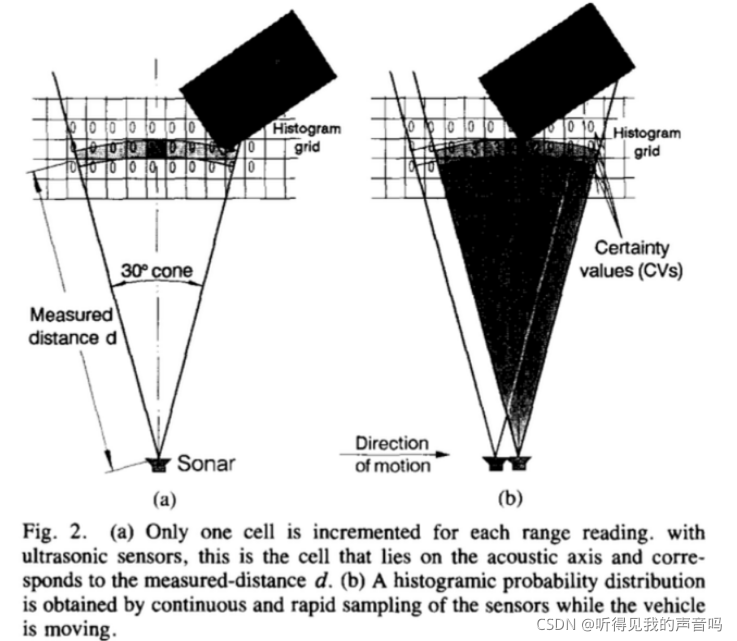
很明显,VFF的计算量大大减少,速度比较快,这也是VFF可以允许机器人进行快速、连续、光滑运动的原因。不过凡事有好就有坏,VFF此举导致丢失了很多的信息,从控制的角度来说,我们对系统信息知道的越少,就越是难以对系统进行控制,所以VFF带来了一些比较大的缺点,后面会提到。
此外,VFF还使用了势场法的思想。在机器人运动过程中,会维护一个特定大小的(比如30*30)、以机器人为中心的正方形区域,称为活跃窗口(active region),记为C*。C*中的每一个cell记为
c
i
,
j
c_{i,j}
ci,j 。其实理论上应该维护的是一个圆形,但是如果用圆形就会大大增大算法的计算量,所以就用了矩形,这样处理起来比较方便。
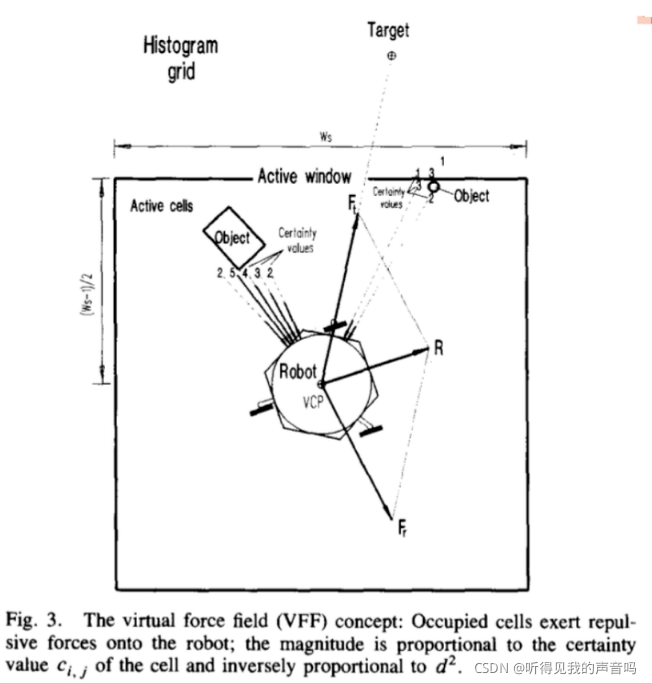
C*内的每一个
c
i
,
j
c_{i,j}
ci,j都会对机器人施加力(virtual force)
F
i
,
j
F_{i,j}
Fi,j ,这样就好象有一个力场一样推动机器人运动。
F
i
,
j
F_{i,j}
Fi,j 的大小和
c
i
,
j
c_{i,j}
ci,j 大小成正比,和
d
x
d^{x}
dx 成反比,其中d是该cell到机器人中心的距离。x一般取为2。
在每一次循环的时候,所有的
F
i
,
j
F_{i,j}
Fi,j 被求合力得到排斥力
F
r
e
p
F_{rep}
Frep 。同时目标位置对机器人的吸引力记为
F
a
t
t
F_{att}
Fatt 。
F
r
e
p
F_{rep}
Frep 和
F
a
t
t
F_{att}
Fatt 求和力得到 R ,这个R 就是推动机器人运动的那个力。
下面说说VFF算法的缺点:
- 缺点一:过不了门。当机器人试图通过一扇门的时候,来自门两边的墙的斥力把机器人推走了。
- 缺电二:由于离散性,在机器人移动过程中,C*也在不断的变化,导致机器人所受的合力R会发生大幅度的突变,给机器人的控制带来了难度。因此需要额外加入一个低通滤波器,来抑制剧烈的变化,但是这就大大减慢了系统的响应速度。
- 缺点三:当机器人试图穿越一个走廊的时候,一旦机器人偏离中心线(来自两边的斥力相互抵消的位置),机器人受力发生变化,导致机器人围绕走廊的中心线进行振荡(左右摇摆)。
4、VFH算法
正式为了改善VFF算法的那些缺点,VFF的作者们又提出了VFH算法。他们指出,VFF算法之所以会发生大幅度的振荡,就是因为在机器人移动过程中,C*也在运动,所以会有上百个cell在短时间内离开C*,同时有上百个cell在短时间内进入C*,这就会导致计算出来的合力R剧烈变化。因为如此大规模的数据在一步内(很短时间)就被处理了,其处理结果用来产生合力R,包括其大小和方向,这样实际上丢失了很多的细节信息。所以他们把这一步拆成两步来做。
相应的VFH算法分成了三层。
- 最高层用来描述机器人工作环境,包括大量的细节信息。在这一步,通过板载传感器数据采样,C被不断的更新。这一步和VFF是一样的。
- 在中间层,构造一个一维的极坐标直方图(polar histogram)H出来。H包含n个sector,每一个sector宽度为
α
\alpha
α ,所以
n
=
360
÷
α
n=360\div\alpha
n=360÷α 。随后把C*变换到H,每一个sector有一个属性
h
k
h_k
hk 来表示第k个sector的极坐标障碍物密度(polar obstacle density),我觉得就是有障碍物的概率。
- 最底层,给出控制机器人运动的参考值,Rref。
我们分为4步来介绍VFH算法,就像原论文那样。
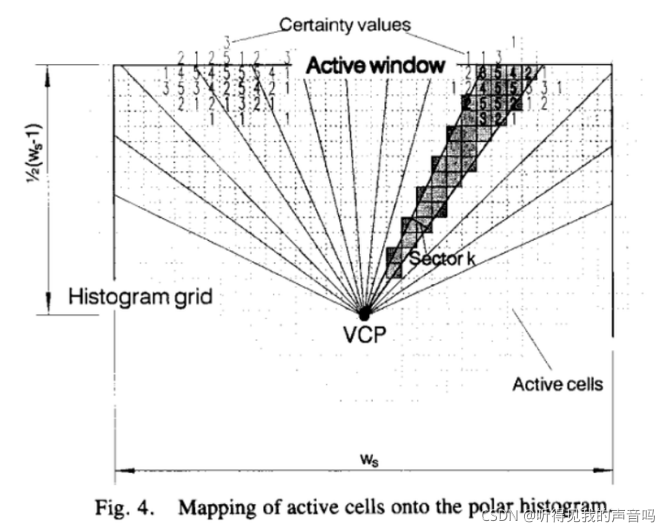
A 第一次data reduction和构建极坐标直方图
这一步的主要工作就是把C空间中的C*映射到极坐标直方图H。
在VFF中的每一个栅格,到了VFH中就成了一个向量,即以机器人的中心位置为极坐标系原点,那么这一个cell就有角度
θ
i
,
j
\theta_{i,j}
θi,j 和模
m
i
,
j
m_{i,j}
mi,j 两个属性来唯一表示。
记机器人的中心位置(VCP,vehicle center point)为
(
x
0
,
y
0
)
(x_0,y_0)
(x0,y0) ,某一个cell的位置为
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi) 。那么
c
e
l
l
i
,
j
cell_{i,j}
celli,j 的角度表示为
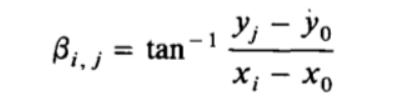
大小表示为

其中:a,b 都是正常系数;
c
i
,
j
∗
c_{i,j}^{*}
ci,j∗ 是cell(i,j)的信度值;
d
i
,
j
d_{i,j}
di,j 是cell(i,j)距离VCP的距离;
m
i
,
j
m_{i,j}
mi,j 是cell(i,j)的向量模,千万注意,cell的向量模不等于该cell到原点的距离;
(
x
0
,
y
0
)
(x_0,y_0)
(x0,y0) 是VCP的坐标;
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi) 是cell(i,j)的坐标;
β
i
,
j
\beta_{i,j}
βi,j 是cell(i,j)对应的向量的角度。
注意,a,b 应当满足如下关系
a
−
b
d
m
a
x
=
0
a-bd_{max}=0
a−bdmax=0 ,其实就是要保证正方形的工作空间的四个顶点的m值为0。因为这些点已经快离开机器人的工作空间了,这些位置的障碍物对机器人的作用应当为0。
如果我们选择
α
=
5
∘
\alpha=5^{\circ}
α=5∘ ,那么很明显就是把360分成了72个sector。不妨假设分成了n 个sector,那么sector的编号哦就是从0到n-1,对于任意一个cell(i,j)的角度
β
i
,
j
\beta_{i,j}
βi,j 可知如下关系成立:
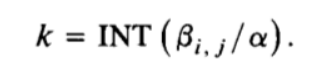
其中k是第k个sector的索引。
相应的第k个sector的
h
k
h_{k}
hk 按照如下公式计算:
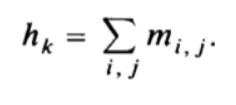
请看此图,
h
k
h_{k}
hk 的计算一目了然:
此外,由于离散的特点,在映射的时候可能出现剧烈跳变得点,为此,还需要进行平滑。使用如下式子进行平滑,其中l一般选为5:
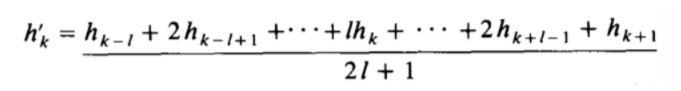
说实话这个式子我没看懂,看着像加权平均,但是仔细一看又不是。很明显结果已经被放大了若干倍,不过倒是不影响。
B 第二次data reduction和方向控制
这一步用来产生一个控制方向或者叫控制角度,
θ
\theta
θ 。
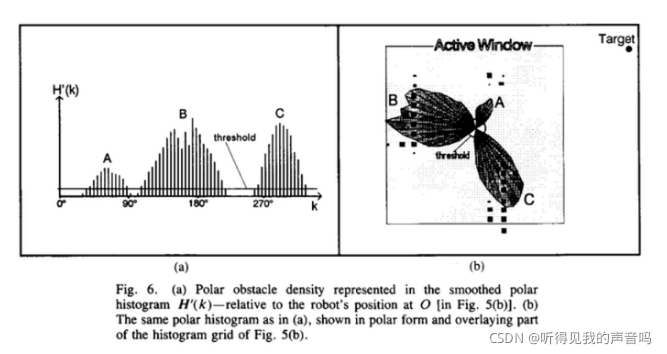
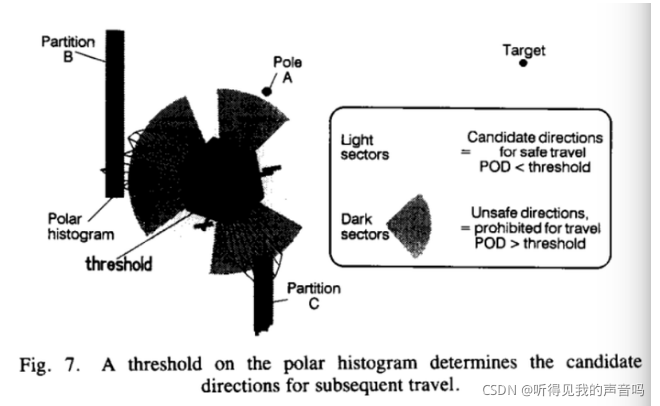
如上图所示,把我们的n个sector各自的
h
k
h_k
hk 依次描在一个表中,就成了上图6中的a。其中A、B、C三个山峰对应三个障碍物,我们的目的就是避开这些障碍物,所以我们应该选择山谷作为我们候选的前进方向。我们需要一个阈值来挑选出来那些山谷,但是我们也在其中发现存在多个山谷,那么我们该怎么杨挑选出来那一个“最好”的山谷呢?这就是这一步要做的工作。
首先,我们评估每一个山谷的宽度,我们会遇到两种情况,宽的山谷和窄的山谷。为此我们需要一个阈值
S
m
a
x
S_{max}
Smax 来判断哪些山谷是窄的山谷,哪些山谷是宽的山谷。如果这个山谷的sector个数大于
S
m
a
x
S_{max}
Smax 个,我们就认为这是一个宽的山谷。否则就是一个窄的山谷。
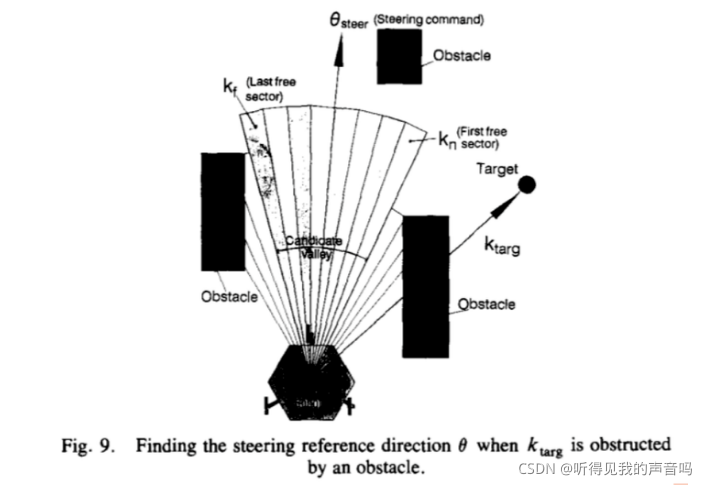
对于宽的山谷也存在两种可能:山谷两侧的两个障碍物距离比较远;或者只有一测具有障碍物,另一测十分空旷。
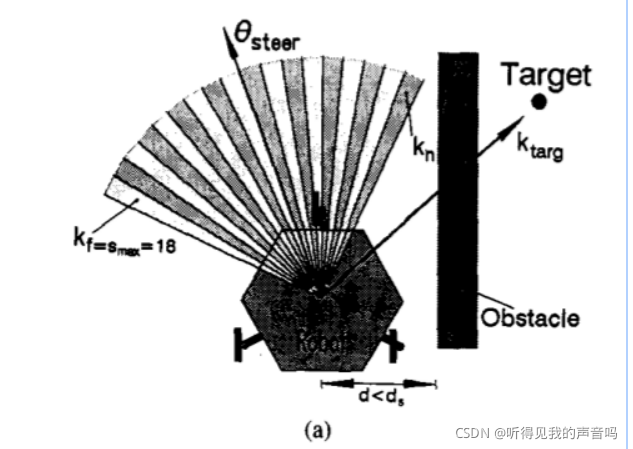

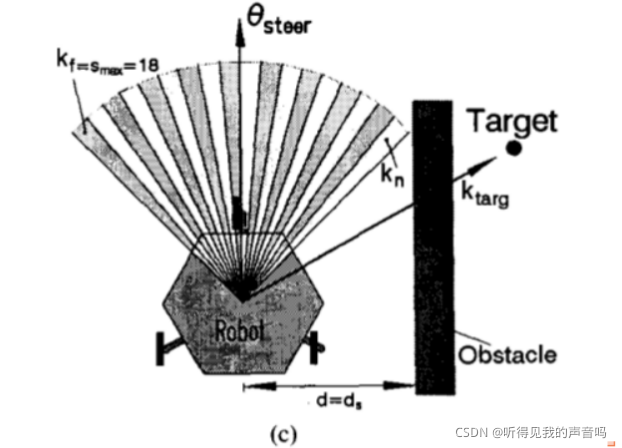
对于宽的山谷,记
k
t
a
r
g
k_{targ}
ktarg 是从VCP指向目标位置的方向,所有sector中距离
k
t
a
r
g
k_{targ}
ktarg 最近并且小于特定阈值(也就是属于某一个山谷)的那个sector记为
k
n
k_n
kn ,表示山谷的最近邻边界,我们把另一端
k
f
k_f
kf ,表示山谷的最远边界。(请看上面三幅图)宽的山谷的
k
n
k_n
kn 和
k
f
k_f
kf 满足如下关系:
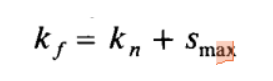
要知道我们的宽的山谷包含的sector的个数可能不只
S
m
a
x
S_{max}
Smax 个sector,为什么这里不是加上山谷的真实宽度而是加上
S
m
a
x
S_{max}
Smax 呢?因为我们不单纯是为了避障,我们还想要到达目的地呀,所以我们不能离目的地太远了,所以要加上
S
m
a
x
S_{max}
Smax ,既保证安全,又不会偏离目的地太远。
此时,我们选择的前进方向就是
k
n
k_n
kn 和
k
f
k_f
kf 的中间位置,即:
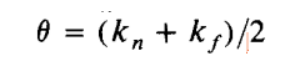
对于窄的山谷,如下图,山谷的宽度不足
S
m
a
x
S_{max}
Smax ,我们仍然选择方向为上式。
我们想一下,要穿过一扇门,就需要找到一个山谷,并选择一个合适的
θ
\theta
θ ,由此就避免了被门给推走的情况了。此外这还避免了在通过走廊时的振荡问题(真的嘛?我没有发现呀)。此外,VFH也不需要低通滤波器,因而速度比较快,允许机器人进行快速的移动。
C 阈值的选择
阈值的选择是比较重要的,
S
m
a
x
S_{max}
Smax 阈值太大,导致机器人对障碍物不够敏感。阈值太小,机器人又难以通过比较窄的通道。为此可以采用自适应动态阈值的方法。
D 速度控制
说实话,这个速度控制部分颠来倒去,我看迷糊了,总之就是既希望速度尽量小,又不希望机器人停下来。
E还是有可能陷入局部最优怎么办?
用全局路径规划器来解决。
5、我在调试的时候,发现的问题
这个算法太依赖于阈值了。说实话,不太喜欢这个算法。
在调试程序的时候发现的几个要注意的点:
1 、局部地图的大小。ros的局部地图默认分辨率是0.05m/cell,大小为80*80,也就是80*0.05=4m见方。地图太大,机器人很容易地就感知到了远处的障碍物,但是我们真的对远处的障碍物很感兴趣吗?很多时候,机器人距离附近的障碍物还是比较远的,避障还不是太重要,这时候地图太大就会干扰机器人的正常运动,此外还会导致机器人的运动变得复杂、计算量增加,甚至不断的调整自己的方向,影响了机器人的运动性能。所以机器人选择的局部地图的大小应当合适,不能太大,这会破坏机器人的运行表现;也不能太小,这会导致机器人对障碍物不够敏感,不适合快速运动。低速情况下,局部地图可以适当小一些,快速的时候,局部地图可以适当大一些。对于小体积机器人地图可以小一些;对于一些大块头,地图应当大一些,比如hit机器人,4m见方就挺好。
2 、参数vfh_threshold,也就是 S_{max} ,这一个参数用来区分哪些sector应该归入山谷,哪些sector应该归入山峰。这个值太大,机器人对障碍物不够敏感;太小,导致机器人难以通过狭窄的通道。
3 、参数vhf_detection_range,障碍物敏感距离。每个cell0.05m宽度,视机器人大小而调整,对于turtlebot来说,可以设置为7/8,也就是0.35/0.4m距离。对于hit这种大家伙,可以设置为1.4m也就是28个来试试。
4 、权重参数goal_weight、curr_direction_weight、prev_direction_weight,当机器人调整自己的前进方向的时候,不能全凭着目标方向来决定,这会让我们的机器人转来转去,光顾着调整方向了。还必须考虑到当前前进方向,然而这还是不够,我们还必须考虑到前一次方向,不能转来转去。调试的时候发现,目标方向权重太大,机器人容易转来转去,应当让当前的前进的方向比目标方向更大一些,前一次方向比目标方向还要小一些,说实话,前一次方向貌似不太重要的。
5、局部规划器更新频率是不是太重要,目前是5,,感觉不会有什么太大影响吧。
6、计算出来一次新的前进方向,就必须朝向这一个方向?不必吧。如果这个角度太小,就会发现我们的机器人来回摆头像个傻子一样,为此设定一个不灵敏区域,这一次的方向和上一次的方向相差不大就不更新方向,否则就更新。
引用:
[1]Borenstein, J, Koren, et al. The vector field histogram-fast obstacle avoidance for mobile robots[J]. Robotics and Automation, IEEE Transactions on, 1991.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)