文章目录
- 什么是序列,Python序列详解(包括序列类型和常用操作)
- 序列索引
- 序列切片
- 序列相加
- 序列相乘
- 检查元素是否包含在序列中
- 和序列相关的内置函数
- Python list列表详解
- Python创建列表
- 1) 使用 [ ] 直接创建列表
- 2) 使用 list() 函数创建列表
- 访问列表元素
- Python删除列表
- Python list列表添加元素的3种方法
- Python append()方法添加元素
- Python extend()方法添加元素
- Python insert()方法插入元素
- Python list列表删除元素(4种方法)
- del:根据索引值删除元素
- pop():根据索引值删除元素
- remove():根据元素值进行删除
- clear():删除列表所有元素
- Python list列表修改元素
-
- Python list列表查找元素
-
- Python list列表使用技巧及注意事项
- Python list添加元素的方法及区别
- Python list删除操作
- Python range()快速初始化数字列表
- Python list列表实现栈和队列
- Python list实现队列
- Python list实现栈
- collections模块实现栈和队列
- Python tuple元组详解
- Python创建元组
- 1) 使用 ( ) 直接创建
- 2) 使用tuple()函数创建元组
- Python访问元组元素
- Python修改元组
- Python删除元组
- Python元组和列表的区别
- Python列表和元组的底层实现
- Python dict字典详解
- Python创建字典
- 1) 使用 { } 创建字典
- 2) 通过 fromkeys() 方法创建字典
- 3) 通过 dict() 映射函数创建字典
- Python 访问字典
- Python删除字典
- Python dict字典基本操作(包括添加、修改、删除键值对)
- Python字典添加键值对
- Python字典修改键值对
- Python字典删除键值对
- 判断字典中是否存在指定键值对
- Python dict字典方法完全攻略(全)
- keys()、values() 和 items() 方法
- copy() 方法
- update() 方法
- pop() 和 popitem() 方法
-
- setdefault() 方法
- Python set集合详解
- Python创建set集合
- 1) 使用 {} 创建
- 2) set()函数创建集合
- Python访问set集合元素
- Python删除set集合
- Python set集合基本操作(添加、删除、交集、并集、差集)
- 向 set 集合中添加元素
- 从set集合中删除元素
- Python set集合做交集、并集、差集运算
- Python set集合方法详解(全)
- 深入底层了解Python字典和集合,一眼看穿他们的本质!
-
转载于http://c.biancheng.net/python/
Python 序列(Sequence)是指按特定顺序依次排列的一组数据,它们可以占用一块连续的内存,也可以分散到多块内存中。Python 中的序列类型包括列表(list)、元组(tuple)、字典(dict)和集合(set)。
在 Python 编程中,我们既需要独立的变量来保存一份数据,也需要序列来保存大量数据。
列表(list)和元组(tuple)比较相似,它们都按顺序保存元素,所有的元素占用一块连续的内存,每个元素都有自己的索引,因此列表和元组的元素都可以通过索引(index)来访问。它们的区别在于:列表是可以修改的,而元组是不可修改的。
字典(dict)和集合(set)存储的数据都是无序的,每份元素占用不同的内存,其中字典元素以 key-value 的形式保存。
什么是序列,Python序列详解(包括序列类型和常用操作)
所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
为了更形象的认识序列,可以将它看做是一家旅店,那么店中的每个房间就如同序列存储数据的一个个内存空间,每个房间所特有的房间号就相当于索引值。也就是说,通过房间号(索引)我们可以找到这家旅店(序列)中的每个房间(内存空间)。
在 Python 中,序列类型包括字符串、列表、元组、集合和字典,这些序列支持以下几种通用的操作,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。
字符串也是一种常见的序列,它也可以直接通过索引访问字符串内的字符。
序列索引
序列中,每个元素都有属于自己的编号(索引)。从起始元素开始,索引值从 0 开始递增,如图 1 所示。

图 1 序列索引值示意图
除此之外,Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图 2 所示。

图 2 负值索引示意图
注意,在使用负值作为列序中各元素的索引值时,是从 -1 开始,而不是从 0 开始。
无论是采用正索引值,还是负索引值,都可以访问序列中的任何元素。以字符串为例,访问“C语言中文网”的首元素和尾元素,可以使用如下的代码:
str="C语言中文网"
print(str[0],"==",str[-6])
print(str[5],"==",str[-1])
输出结果为:
C == C
网 == 网
序列切片
切片操作是访问序列中元素的另一种方法,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。
序列实现切片操作的语法格式如下:
sname[start : end : step]
其中,各个参数的含义分别是:
- sname:表示序列的名称;
- start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,会默认为 0,也就是从序列的开头进行切片;
- end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度;
- step:表示在切片过程中,隔几个存储位置(包含当前位置)取一次元素,也就是说,如果 step 的值大于 1,则在进行切片去序列元素时,会“跳跃式”的取元素。如果省略设置 step 的值,则最后一个冒号就可以省略。
例如,对字符串“C语言中文网”进行切片:
str="C语言中文网"
print(str[:2])
print(str[::2])
print(str[:])
运行结果为:
C语
C言文
C语言中文网
序列相加
Python 中,支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。
这里所说的“类型相同”,指的是“+”运算符的两侧序列要么都是列表类型,要么都是元组类型,要么都是字符串。
例如,前面章节中我们已经实现用“+”运算符连接 2 个(甚至多个)字符串,如下所示:
str="c.biancheng.net"
print("C语言"+"中文网:"+str)
输出结果为:
C语言中文网:c.biancheng.net
序列相乘
Python 中,使用数字 n 乘以一个序列会生成新的序列,其内容为原来序列被重复 n 次的结果。例如:
str="C语言中文网"
print(str*3)
输出结果为:
‘C语言中文网C语言中文网C语言中文网’
比较特殊的是,列表类型在进行乘法运算时,还可以实现初始化指定长度列表的功能。例如如下的代码,将创建一个长度为 5 的列表,列表中的每个元素都是 None,表示什么都没有。
list = [None]*5
print(list)
输出结果为:
[None, None, None, None, None]
检查元素是否包含在序列中
Python 中,可以使用 in 关键字检查某元素是否为序列的成员,其语法格式为:
value in sequence
其中,value 表示要检查的元素,sequence 表示指定的序列。
例如,检查字符‘c’是否包含在字符串“c.biancheng.net”中,可以执行如下代码:
str="c.biancheng.net"
print('c'in str)
运行结果为:
True
和 in 关键字用法相同,但功能恰好相反的,还有 not in 关键字,它用来检查某个元素是否不包含在指定的序列中,比如说:
str="c.biancheng.net"
print('c' not in str)
输出结果为:
False
和序列相关的内置函数
Python提供了几个内置函数(表 3 所示),可用于实现与序列相关的一些常用操作。
| 函数 | 功能 |
|---|
| len() | 计算序列的长度,即返回序列中包含多少个元素。 |
| max() | 找出序列中的最大元素。注意,对序列使用 sum() 函数时,做加和操作的必须都是数字,不能是字符或字符串,否则该函数将抛出异常,因为解释器无法判定是要做连接操作(+ 运算符可以连接两个序列),还是做加和操作。 |
| min() | 找出序列中的最小元素。 |
| list() | 将序列转换为列表。 |
| str() | 将序列转换为字符串。 |
| sum() | 计算元素和。 |
| sorted() | 对元素进行排序。 |
| reversed() | 反向序列中的元素。 |
| enumerate() | 将序列组合为一个索引序列,多用在 for 循环中。 |
这里给大家给几个例子:
str="c.biancheng.net"
print(max(str))
print(min(str))
print(sorted(str))
输出结果为:
t
.
[’.’, ‘.’, ‘a’, ‘b’, ‘c’, ‘c’, ‘e’, ‘e’, ‘g’, ‘h’, ‘i’, ‘n’, ‘n’, ‘n’, ‘t’]
Python list列表详解
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。说到这里,一些读者可能听说过数组(Array),它就可以把多个数据挨个存储到一起,通过数组下标可以访问数组中的每个元素。
需要明确的是,Python 中没有数组,但是加入了更加强大的列表。如果把数组看做是一个集装箱,那么 Python 的列表就是一个工厂的仓库。
大部分编程语言都支持数组,比如C语言、C++、Java、PHP、JavaScript 等。
从形式上看,列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, …, elementn]
格式中,element1 ~ elementn 表示列表中的元素,个数没有限制,只要是 Python 支持的数据类型就可以。
从内容上看,列表可以存储整数、小数、字符串、列表、元组等任何类型的数据,并且同一个列表中元素的类型也可以不同。比如说:
[“http://c.biancheng.net/python/”, 1, [2,3,4] , 3.0]
可以看到,列表中同时包含字符串、整数、列表、浮点数这些数据类型。
注意,在使用列表时,虽然可以将不同类型的数据放入到同一个列表中,但通常情况下不这么做,同一列表中只放入同一类型的数据,这样可以提高程序的可读性。
另外,在其它 Python 教程中,经常用 list 代指列表,这是因为列表的数据类型就是 list,通过 type() 函数就可以知道,例如:
>>> type( [“http://c.biancheng.net/python/”, 1, [2,3,4] , 3.0] )
<class ‘list’>
可以看到,它的数据类型为 list,就表示它是一个列表。
Python创建列表
在 Python 中,创建列表的方法可分为两种,下面分别进行介绍。
1) 使用 [ ] 直接创建列表
使用[ ]创建列表后,一般使用=将它赋值给某个变量,具体格式如下:
listname = [element1 , element2 , element3 , … , elementn]
其中,listname 表示变量名,element1 ~ elementn 表示列表元素。
例如,下面定义的列表都是合法的:
num = [1, 2, 3, 4, 5, 6, 7]
name = ["C语言中文网", "http://c.biancheng.net"]
program = ["C语言", "Python", "Java"]
另外,使用此方式创建列表时,列表中元素可以有多个,也可以一个都没有,例如:
emptylist = [ ]
这表明,emptylist 是一个空列表。
2) 使用 list() 函数创建列表
除了使用[ ]创建列表外,Python 还提供了一个内置的函数 list(),使用它可以将其它数据类型转换为列表类型。例如:
#将字符串转换成列表
list1 = list("hello")
print(list1)
#将元组转换成列表
tuple1 = ('Python', 'Java', 'C++', 'JavaScript')
list2 = list(tuple1)
print(list2)
#将字典转换成列表
dict1 = {'a':100, 'b':42, 'c':9}
list3 = list(dict1)
print(list3)
#将区间转换成列表
range1 = range(1, 6)
list4 = list(range1)
print(list4)
#创建空列表
print(list())
运行结果:
[‘h’, ‘e’, ‘l’, ‘l’, ‘o’]
[‘Python’, ‘Java’, ‘C++’, ‘JavaScript’]
[‘a’, ‘b’, ‘c’]
[1, 2, 3, 4, 5]
[]
访问列表元素
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
使用索引访问列表元素的格式为:
listname[i]
其中,listname 表示列表名字,i 表示索引值。列表的索引可以是正数,也可以是负数。
使用切片访问列表元素的格式为:
listname[start : end : step]
其中,listname 表示列表名字,start 表示起始索引,end 表示结束索引,step 表示步长。
以上两种方式我们已在《Python序列》中进行了讲解,这里就不再赘述了,仅作示例演示,请看下面代码:
url = list("http://c.biancheng.net/shell/")
#使用索引访问列表中的某个元素
print(url[3]) #使用正数索引
print(url[-4]) #使用负数索引
#使用切片访问列表中的一组元素
print(url[9: 18]) #使用正数切片
print(url[9: 18: 3]) #指定步长
print(url[-6: -1]) #使用负数切片
运行结果:
p
e
[‘b’, ‘i’, ‘a’, ‘n’, ‘c’, ‘h’, ‘e’, ‘n’, ‘g’]
[‘b’, ‘n’, ‘e’]
[‘s’, ‘h’, ‘e’, ‘l’, ‘l’]
Python删除列表
对于已经创建的列表,如果不再使用,可以使用del关键字将其删除。
实际开发中并不经常使用 del 来删除列表,因为 Python 自带的垃圾回收机制会自动销毁无用的列表,即使开发者不手动删除,Python 也会自动将其回收。
del 关键字的语法格式为:
del listname
其中,listname 表示要删除列表的名称。
Python 删除列表实例演示:
intlist = [1, 45, 8, 34]
print(intlist)
del intlist
print(intlist)
运行结果:
[1, 45, 8, 34]
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 4, in
print(intlist)
NameError: name ‘intlist’ is not defined
Python list列表添加元素的3种方法
实际开发中,经常需要对 Python 列表进行更新,包括向列表中添加元素、修改表中元素以及删除元素。本节先来学习如何向列表中添加元素。
《Python序列》一节告诉我们,使用+运算符可以将多个序列连接起来;列表是序列的一种,所以也可以使用+进行连接,这样就相当于在第一个列表的末尾添加了另一个列表。
请看下面的演示:
language = ["Python", "C++", "Java"]
birthday = [1991, 1998, 1995]
info = language + birthday
print("language =", language)
print("birthday =", birthday)
print("info =", info)
运行结果:
language = [‘Python’, ‘C++’, ‘Java’]
birthday = [1991, 1998, 1995]
info = [‘Python’, ‘C++’, ‘Java’, 1991, 1998, 1995]
从运行结果可以发现,使用+会生成一个新的列表,原有的列表不会被改变。
+更多的是用来拼接列表,而且执行效率并不高,如果想在列表中插入元素,应该使用下面几个专门的方法。
Python append()方法添加元素
append() 方法用于在列表的末尾追加元素,该方法的语法格式如下:
listname.append(obj)
其中,listname 表示要添加元素的列表;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。
请看下面的演示:
l = ['Python', 'C++', 'Java']
#追加元素
l.append('PHP')
print(l)
#追加元组,整个元组被当成一个元素
t = ('JavaScript', 'C#', 'Go')
l.append(t)
print(l)
#追加列表,整个列表也被当成一个元素
l.append(['Ruby', 'SQL'])
print(l)
运行结果为:
[‘Python’, ‘C++’, ‘Java’, ‘PHP’]
[‘Python’, ‘C++’, ‘Java’, ‘PHP’, (‘JavaScript’, ‘C#’, ‘Go’)]
[‘Python’, ‘C++’, ‘Java’, ‘PHP’, (‘JavaScript’, ‘C#’, ‘Go’), [‘Ruby’, ‘SQL’]]
可以看到,当给 append() 方法传递列表或者元组时,此方法会将它们视为一个整体,作为一个元素添加到列表中,从而形成包含列表和元组的新列表。
Python extend()方法添加元素
extend() 和 append() 的不同之处在于:extend() 不会把列表或者元祖视为一个整体,而是把它们包含的元素逐个添加到列表中。
extend() 方法的语法格式如下:
listname.extend(obj)
其中,listname 指的是要添加元素的列表;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等,但不能是单个的数字。
请看下面的演示:
l = ['Python', 'C++', 'Java']
#追加元素
l.extend('C')
print(l)
#追加元组,元祖被拆分成多个元素
t = ('JavaScript', 'C#', 'Go')
l.extend(t)
print(l)
#追加列表,列表也被拆分成多个元素
l.extend(['Ruby', 'SQL'])
print(l)
运行结果:
[‘Python’, ‘C++’, ‘Java’, ‘C’]
[‘Python’, ‘C++’, ‘Java’, ‘C’, ‘JavaScript’, ‘C#’, ‘Go’]
[‘Python’, ‘C++’, ‘Java’, ‘C’, ‘JavaScript’, ‘C#’, ‘Go’, ‘Ruby’, ‘SQL’]
Python insert()方法插入元素
append() 和 extend() 方法只能在列表末尾插入元素,如果希望在列表中间某个位置插入元素,那么可以使用 insert() 方法。
insert() 的语法格式如下:
listname.insert(index , obj)
其中,index 表示指定位置的索引值。insert() 会将 obj 插入到 listname 列表第 index 个元素的位置。
当插入列表或者元祖时,insert() 也会将它们视为一个整体,作为一个元素插入到列表中,这一点和 append() 是一样的。
请看下面的演示代码:
l = ['Python', 'C++', 'Java']
#插入元素
l.insert(1, 'C')
print(l)
#插入元组,整个元祖被当成一个元素
t = ('C#', 'Go')
l.insert(2, t)
print(l)
#插入列表,整个列表被当成一个元素
l.insert(3, ['Ruby', 'SQL'])
print(l)
#插入字符串,整个字符串被当成一个元素
l.insert(0, "http://c.biancheng.net")
print(l)
输出结果为:
[‘Python’, ‘C’, ‘C++’, ‘Java’]
[‘Python’, ‘C’, (‘C#’, ‘Go’), ‘C++’, ‘Java’]
[‘Python’, ‘C’, (‘C#’, ‘Go’), [‘Ruby’, ‘SQL’], ‘C++’, ‘Java’]
[‘http://c.biancheng.net’, ‘Python’, ‘C’, (‘C#’, ‘Go’), [‘Ruby’, ‘SQL’], ‘C++’, ‘Java’]
提示,insert() 主要用来在列表的中间位置插入元素,如果你仅仅希望在列表的末尾追加元素,那我更建议使用 append() 和 extend()。
Python list列表删除元素(4种方法)
在 Python 列表中删除元素主要分为以下 3 种场景:
- 根据目标元素所在位置的索引进行删除,可以使用 del 关键字或者 pop() 方法;
- 根据元素本身的值进行删除,可使用列表(list类型)提供的 remove() 方法;
- 将列表中所有元素全部删除,可使用列表(list类型)提供的 clear() 方法。
del:根据索引值删除元素
del 是 Python 中的关键字,专门用来执行删除操作,它不仅可以删除整个列表,还可以删除列表中的某些元素。我们已经在《Python列表》中讲解了如何删除整个列表,所以本节只讲解如何删除列表元素。
del 可以删除列表中的单个元素,格式为:
del listname[index]
其中,listname 表示列表名称,index 表示元素的索引值。
del 也可以删除中间一段连续的元素,格式为:
del listname[start : end]
其中,start 表示起始索引,end 表示结束索引。del 会删除从索引 start 到 end 之间的元素,不包括 end 位置的元素。
【示例】使用 del 删除单个列表元素:
lang = ["Python", "C++", "Java", "PHP", "Ruby", "MATLAB"]
del lang[2]
print(lang)
del lang[-2]
print(lang)
运行结果:
[‘Python’, ‘C++’, ‘PHP’, ‘Ruby’, ‘MATLAB’]
[‘Python’, ‘C++’, ‘PHP’, ‘MATLAB’]
【示例】使用 del 删除一段连续的元素:
lang = ["Python", "C++", "Java", "PHP", "Ruby", "MATLAB"]
del lang[1: 4]
print(lang)
lang.extend(["SQL", "C#", "Go"])
del lang[-5: -2]
print(lang)
运行结果:
[‘Python’, ‘Ruby’, ‘MATLAB’]
[‘Python’, ‘C#’, ‘Go’]
pop():根据索引值删除元素
Python pop() 方法用来删除列表中指定索引处的元素,具体格式如下:
listname.pop(index)
其中,listname 表示列表名称,index 表示索引值。如果不写 index 参数,默认会删除列表中的最后一个元素,类似于数据结构中的“出栈”操作。
pop() 用法举例:
nums = [40, 36, 89, 2, 36, 100, 7]
nums.pop(3)
print(nums)
nums.pop()
print(nums)
运行结果:
[40, 36, 89, 36, 100, 7]
[40, 36, 89, 36, 100]
大部分编程语言都会提供和 pop() 相对应的方法,就是 push(),该方法用来将元素添加到列表的尾部,类似于数据结构中的“入栈”操作。但是 Python 是个例外,Python 并没有提供 push() 方法,因为完全可以使用 append() 来代替 push() 的功能。
remove():根据元素值进行删除
除了 del 关键字,Python 还提供了 remove() 方法,该方法会根据元素本身的值来进行删除操作。
需要注意的是,remove() 方法只会删除第一个和指定值相同的元素,而且必须保证该元素是存在的,否则会引发 ValueError 错误。
remove() 方法使用示例:
nums = [40, 36, 89, 2, 36, 100, 7]
nums.remove(36)
print(nums)
nums.remove(36)
print(nums)
nums.remove(78)
print(nums)
运行结果:
[40, 89, 2, 36, 100, 7]
[40, 89, 2, 100, 7]
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 9, in
nums.remove(78)
ValueError: list.remove(x): x not in list
最后一次删除,因为 78 不存在导致报错,所以我们在使用 remove() 删除元素时最好提前判断一下。
clear():删除列表所有元素
Python clear() 用来删除列表的所有元素,也即清空列表,请看下面的代码:
url = list("http://c.biancheng.net/python/")
url.clear()
print(url)
运行结果:
[]
Python list列表修改元素
Python 提供了两种修改列表(list)元素的方法,你可以每次修改单个元素,也可以每次修改一组元素(多个)。
修改单个元素
修改单个元素非常简单,直接对元素赋值即可。请看下面的例子:
nums = [40, 36, 89, 2, 36, 100, 7]
nums[2] = -26 #使用正数索引
nums[-3] = -66.2 #使用负数索引
print(nums)
运行结果:
[40, 36, -26, 2, -66.2, 100, 7]
使用索引得到列表元素后,通过=赋值就改变了元素的值。
修改一组元素
Python 支持通过切片语法给一组元素赋值。在进行这种操作时,如果不指定步长(step 参数),Python 就不要求新赋值的元素个数与原来的元素个数相同;这意味,该操作既可以为列表添加元素,也可以为列表删除元素。
下面的代码演示了如何修改一组元素的值:
nums = [40, 36, 89, 2, 36, 100, 7]
#修改第 1~4 个元素的值(不包括第4个元素)
nums[1: 4] = [45.25, -77, -52.5]
print(nums)
运行结果:
[40, 45.25, -77, -52.5, 36, 100, 7]
如果对空切片(slice)赋值,就相当于插入一组新的元素:
nums = [40, 36, 89, 2, 36, 100, 7]
#在4个位置插入元素
nums[4: 4] = [-77, -52.5, 999]
print(nums)
运行结果:
[40, 36, 89, 2, -77, -52.5, 999, 36, 100, 7]
使用切片语法赋值时,Python 不支持单个值,例如下面的写法就是错误的:
nums[4: 4] = -77
但是如果使用字符串赋值,Python 会自动把字符串转换成序列,其中的每个字符都是一个元素,请看下面的代码:
s = list("Hello")
s[2:4] = "XYZ"
print(s)
运行结果:
[‘H’, ‘e’, ‘X’, ‘Y’, ‘Z’, ‘o’]
使用切片语法时也可以指定步长(step 参数),但这个时候就要求所赋值的新元素的个数与原有元素的个数相同,例如:
nums = [40, 36, 89, 2, 36, 100, 7]
#步长为2,为第1、3、5个元素赋值
nums[1: 6: 2] = [0.025, -99, 20.5]
print(nums)
运行结果:
[40, 0.025, 89, -99, 36, 20.5, 7]
Python list列表查找元素
Python 列表(list)提供了 index() 和 count() 方法,它们都可以用来查找元素。
index() 方法
index() 方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素不存在,则会导致 ValueError 错误,所以在查找之前最好使用 count() 方法判断一下。
index() 的语法格式为:
listname.index(obj, start, end)
其中,listname 表示列表名称,obj 表示要查找的元素,start 表示起始位置,end 表示结束位置。
start 和 end 参数用来指定检索范围:
- start 和 end 可以都不写,此时会检索整个列表;
- 如果只写 start 不写 end,那么表示检索从 start 到末尾的元素;
- 如果 start 和 end 都写,那么表示检索 start 和 end 之间的元素。
index() 方法会返回元素所在列表中的索引值。
index() 方法使用举例:
nums = [40, 36, 89, 2, 36, 100, 7, -20.5, -999]
print( nums.index(2) )
print( nums.index(100, 3, 7) )
print( nums.index(7, 4) )
print( nums.index(55) )
运行结果:
3
5
6
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 9, in
print( nums.index(55) )
ValueError: 55 is not in list
count()方法
count() 方法用来统计某个元素在列表中出现的次数,基本语法格式为:
listname.count(obj)
其中,listname 代表列表名,obj 表示要统计的元素。
如果 count() 返回 0,就表示列表中不存在该元素,所以 count() 也可以用来判断列表中的某个元素是否存在。
count() 用法示例:
nums = [40, 36, 89, 2, 36, 100, 7, -20.5, 36]
print("36出现了%d次" % nums.count(36))
if nums.count(100):
print("列表中存在100这个元素")
else:
print("列表中不存在100这个元素")
运行结果:
36出现了3次
列表中存在100这个元素
Python list列表使用技巧及注意事项
前面章节介绍了很多关于 list 列表的操作函数,细心的读者可能会发现,有很多操作函数的功能非常相似。例如,增加元素功能的函数有 append() 和 extend(),删除元素功能的有 clear()、 remove()、pop() 和 del 关键字。
本节将通过实例演示的方式来明确各个函数的用法,以及某些函数之间的区别和在使用时的一些注意事项。
Python list添加元素的方法及区别
定义两个列表(分别是 list1 和 list3),并分别使用 +、extend()、append() 对这两个 list 进行操作,其操作的结果赋值给 l2。实例代码如下:
tt = 'hello'
list1 = [1,4,tt,3.4,"yes",[1,2]]
print(list1,id(list1))
print("1.----------------")
list3 = [6,7]
l2 = list1 + list3
print(l2,id(l2))
print("2.----------------")
l2 = list1.extend(list3)
print(l2,id(l2))
print(list1,id(list1))
print("3.----------------")
l2 = list1.append(list3)
print(l2,id(l2))
print(list1,id(list1))
输出结果为:
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2]] 2251638471496
1.----------------
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2], 6, 7] 2251645237064
2.----------------
None 1792287952
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2], 6, 7] 2251638471496
3.----------------
None 1792287952
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2], 6, 7, [6, 7]] 2251638471496
根据输出结果,可以分析出以下几个结论:
- 使用“+”号连接的列表,是将 list3 中的元素放在 list 的后面得到的 l2。并且 l2 的内存地址值与 list1 并不一样,这表明 l2 是一个重新生成的列表。
- 使用 extend 处理后得到的 l2 是 none。表明 extend 没有返回值,并不能使用链式表达式。即 extend 千万不能放在等式的右侧,这是编程时常犯的错误,一定要引起注意。
- extend 处理之后, list1 的内容与使用“+”号生成的 l2 是一样的。但 list1 的地址在操作前后并没有变化,这表明 extend 的处理仅仅是改变了 list1,而没有重新创建一个 list。从这个角度来看,extend 的效率要高于“+”号。
- 从 append 的结果可以看出,append 的作用是将 list3 整体当成一个元素追加到 list1 后面,这与 extend 和“+”号的功能完全不同,这一点也需要注意。
Python list删除操作
接下来演示有关 del 的基本用法,实例代码如下:
tt = 'hello'
list1 = [1,4,tt,3.4,"yes",[1,2]]
print(list1)
del list1[2:5]
print(list1)
del list1[2]
print(list1)
输出结果为:
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2]]
[1, 4, [1, 2]]
[1, 4]
这 3 行输出分别是 list1 的原始内容、删除一部分切片内容、删除指定索引内容。可以看到,del 关键字按照指定的位置删掉了指定的内容。
需要注意的是,在使用 del 关键字时,一定要搞清楚,删除的到底是变量还是数据。例如,下面代码演示和删除变量的方法:
tt = 'hello'
list1 = [1,4,tt,3.4,"yes",[1,2]]
l2 = list1
print(id(l2),id(list1))
del list1
print(l2)
print(list1)
运行结果如下:
1765451922248 1765451922248
[1, 4, ‘hello’, 3.4, ‘yes’, [1, 2]]
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\demo.py”, line 8, in
print(list1)
NameError: name ‘list1’ is not defined
第一行输出的内容是 l2 和 list1 的地址,可以看到它们是相同的,说明 l2 和 list1 之间的赋值仅仅是传递内存地址。接下来将 list1 删掉,并打印 l2,可以看到,l2 所指向的内存数据还是存在的,这表明 del 删除 list1 时仅仅是销毁了变量 list1,并没有删除指定的数据。
除了删除变量,其他的删除都是删除数据,比如将列表中数据全部清空,实现代码如下:
tt = 'hello'
list1 = [1,4,tt,3.4,"yes",[1,2]]
l2 = list1
l3 = l2
del l2[:]
print(l2)
print(l3)
输出结果为:
[]
[]
可以看到,l3 和 l2 执行同样的内存地址,当 l2 被清空之后,l3 的内容也被清空了。这表明内存中的数据真正改变了。
另外,在实际过程中,即便使用 del 关键字删除了指定变量,且该变量所占用的内存再没有其他变量使用,此内存空间也不会真正地被系统回收并进行二次使用,它只是会被标记为无效内存。
如果想让系统回收这些可用的内存,需要借助 gc 库中的 collect() 函数。例如:
import gc
tt = 'hello'
list1 = [1,4,tt,3.4,"yes",[1,2]]
del list1
gc.collect()
前面我们在《Python缓存机制》一节讲过,系统为了提升性能,会将一部分变量驻留在内存中。这个机制对于,多线程并发时程序产生大量占用内存的变量无法得到释放,或者某些不再需要使用的全局变量占用着大的内存,导致后续运行中出现内存不足的情况,此时就可以使用 del 关键字来回收内存,使系统的性能得以提升。同时,它可以为团队省去扩充大量内存的成本。
Python range()快速初始化数字列表
注意:本节需具备最基本的 Python 循环结构的基础,初学者可先跳过本节。
实际场景中,经常需要存储一组数字。例如在游戏中,需要跟踪每个角色的位置,还可能需要跟踪玩家的几个最高得分。在数据可视化中,处理的几乎都是由数字(如温度、距离、人口数量、经度和纬度等)组成的集合。
列表非常适合用于存储数字集合,并且 Python 提供了 range() 函数,可帮助我们高效地处理数字列表,即便列表需要包含数百万个元素,也可以快速实现。
Python range() 函数能够轻松地生成一系列的数字。例如,可以像如下这样使用 range() 来打印一系列数字:
for value in range(1,5):
print(value)
输出结果为:
1
2
3
4
注意,在这个示例程序中,range() 只是打印数字 1~4,因为range() 函数的用法是:让 Python 从指定的第一个值开始,一直数到指定的第二个值停止,但不包含第二个值(这里为 5)。
因此,如果想要上面程序打印数字 1~5,需要使用 range(1,6)。
另外需要指明的是,range() 函数的返回值并不直接是列表类型(list),例如:
>>> type([1,2,3,4,5])
<class ‘list’>
>>> type(range(1,6))
<class ‘range’>
可以看到,range() 函数的返回值类型为 range,而不是 list。而如果想要得到 range() 函数创建的数字列表,还需要借助 list() 函数,比如:
>>> list(range(1,6))
[1, 2, 3, 4, 5]
可以看到,如果将 range() 作为 list() 的参数,其输出就是一个数字列表。
不仅如此,在使用 range() 函数时,还可以指定步长。例如,下面的代码打印 1~10 内的偶数:
even_numbers = list(range(2,11,2))
print(even_numbers)
在这个示例中,函数 range() 从 2 开始数,然后不断地加 2,直到达到或超过终值,因此输出如下:
[2, 4, 6, 8, 10]
注意,即便 range() 第二个参数恰好符合条件,最终创建的数字列表中也不会包含它。
实际使用时,range() 函数常常和 Python 循环结构、推导式(后续会讲,这里先不涉及)一起使用,几乎能够创建任何需要的数字列表。
例如,创建这样一个列表,其中包含前 10 个整数(即1~10)的平方,实现代码如下:
squares = []
for value in range(1,11):
square = value**2
squares.append(square)
print(squares)
运行结果为:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Python list列表实现栈和队列
队列和栈是两种数据结构,其内部都是按照固定顺序来存放变量的,二者的区别在于对数据的存取顺序:
- 队列是,先存入的数据最先取出,即“先进先出”。
- 栈是,最后存入的数据最先取出,即“后进先出”。
考虑到 list 类型数据本身的存放就是有顺序的,而且内部元素又可以是各不相同的类型,非常适合用于队列和栈的实现。本节将演示如何使用 list 类型变量来实现队列和栈。
Python list实现队列
使用 list 列表模拟队列功能的实现方法是,定义一个 list 变量,存入数据时使用 insert() 方法,设置其第一个参数为 0,即表示每次都从最前面插入数据;读取数据时,使用 pop() 方法,即将队列的最后一个元素弹出。
如此 list 列表中数据的存取顺序就符合“先进先出”的特点。实现代码如下:
#定义一个空列表,当做队列
queue = []
#向列表中插入元素
queue.insert(0,1)
queue.insert(0,2)
queue.insert(0,"hello")
print(queue)
print("取一个元素:",queue.pop())
print("取一个元素:",queue.pop())
print("取一个元素:",queue.pop())
运行结果为:
[‘hello’, 2, 1]
取一个元素: 1
取一个元素: 2
取一个元素: hello
Python list实现栈
使用 list 列表模拟栈功能的实现方法是,使用 append() 方法存入数据;使用 pop() 方法读取数据。
append() 方法向 list 中存入数据时,每次都在最后面添加数据,这和前面程序中的 insert() 方法正好相反。
举个例子:
#定义一个空 list 当做栈
stack = []
stack.append(1)
stack.append(2)
stack.append("hello")
print(stack)
print("取一个元素:",stack.pop())
print("取一个元素:",stack.pop())
print("取一个元素:",stack.pop())
输出结果为:
[1, 2, ‘hello’]
取一个元素: hello
取一个元素: 2
取一个元素: 1
collections模块实现栈和队列
前面使用 list 实现队列的例子中,插入数据的部分是通过 insert() 方法实现的,这种方法效率并不高,因为每次从列表的开头插入一个数据,列表中所有元素都得向后移动一个位置。
这里介绍一个相对更高效的方法,即使用标准库的 collections 模块中的 deque 结构体,它被设计成在两端存入和读取都很快的特殊 list,可以用来实现栈和队列的功能。
举个例子:
queueAndStack = deque()
queueAndStack.append(1)
queueAndStack.append(2)
queueAndStack.append("hello")
print(list(queueAndStack))
#实现队列功能,从队列中取一个元素,根据先进先出原则,这里应输出 1
print(queueAndStack.popleft())
#实现栈功能,从栈里取一个元素,根据后进先出原则,这里应输出 hello
print(queueAndStack.pop())
#再次打印列表
print(list(queueAndStack))
输出结果为:
[1, 2, ‘hello’]
1
hello
[2]
Python tuple元组详解
元组(tuple)是 Python 中另一个重要的序列结构,和列表类似,元组也是由一系列按特定顺序排序的元素组成。
元组和列表(list)的不同之处在于:
- 列表的元素是可以更改的,包括修改元素值,删除和插入元素,所以列表是可变序列;
- 而元组一旦被创建,它的元素就不可更改了,所以元组是不可变序列。
元组也可以看做是不可变的列表,通常情况下,元组用于保存无需修改的内容。
从形式上看,元组的所有元素都放在一对小括号( )中,相邻元素之间用逗号,分隔,如下所示:
(element1, element2, … , elementn)
其中 element1~elementn 表示元组中的各个元素,个数没有限制,只要是 Python 支持的数据类型就可以。
从存储内容上看,元组可以存储整数、实数、字符串、列表、元组等任何类型的数据,并且在同一个元组中,元素的类型可以不同,例如:
(“c.biancheng.net”, 1, [2,‘a’], (“abc”,3.0))
在这个元组中,有多种类型的数据,包括整形、字符串、列表、元组。
另外,我们都知道,列表的数据类型是 list,那么元组的数据类型是什么呢?我们不妨通过 type() 函数来查看一下:
>>> type( (“c.biancheng.net”,1,[2,‘a’],(“abc”,3.0)) )
<class ‘tuple’>
可以看到,元组是 tuple 类型,这也是很多教程中用 tuple 指代元组的原因。
Python创建元组
Python 提供了两种创建元组的方法,下面一一进行介绍。
1) 使用 ( ) 直接创建
通过( )创建元组后,一般使用=将它赋值给某个变量,具体格式为:
tuplename = (element1, element2, …, elementn)
其中,tuplename 表示变量名,element1 ~ elementn 表示元组的元素。
例如,下面的元组都是合法的:
num = (7, 14, 21, 28, 35)
course = ("Python教程", "http://c.biancheng.net/python/")
abc = ( "Python", 19, [1,2], ('c',2.0) )
在 Python 中,元组通常都是使用一对小括号将所有元素包围起来的,但小括号不是必须的,只要将各元素用逗号隔开,Python 就会将其视为元组,请看下面的例子:
course = "Python教程", "http://c.biancheng.net/python/"
print(course)
运行结果为:
(‘Python教程’, ‘http://c.biancheng.net/python/’)
需要注意的一点是,当创建的元组中只有一个字符串类型的元素时,该元素后面必须要加一个逗号,,否则 Python 解释器会将它视为字符串。请看下面的代码:
#最后加上逗号
a =("http://c.biancheng.net/cplus/",)
print(type(a))
print(a)
#最后不加逗号
b = ("http://c.biancheng.net/socket/")
print(type(b))
print(b)
运行结果为:
<class ‘tuple’>
(‘http://c.biancheng.net/cplus/’,)
<class ‘str’>
http://c.biancheng.net/socket/
你看,只有变量 a 才是元组,后面的变量 b 是一个字符串。
2) 使用tuple()函数创建元组
除了使用( )创建元组外,Python 还提供了一个内置的函数 tuple(),用来将其它数据类型转换为元组类型。
tuple() 的语法格式如下:
tuple(data)
其中,data 表示可以转化为元组的数据,包括字符串、元组、range 对象等。
tuple() 使用示例:
#将字符串转换成元组
tup1 = tuple("hello")
print(tup1)
#将列表转换成元组
list1 = ['Python', 'Java', 'C++', 'JavaScript']
tup2 = tuple(list1)
print(tup2)
#将字典转换成元组
dict1 = {'a':100, 'b':42, 'c':9}
tup3 = tuple(dict1)
print(tup3)
#将区间转换成元组
range1 = range(1, 6)
tup4 = tuple(range1)
print(tup4)
#创建空元组
print(tuple())
运行结果为:
(‘h’, ‘e’, ‘l’, ‘l’, ‘o’)
(‘Python’, ‘Java’, ‘C++’, ‘JavaScript’)
(‘a’, ‘b’, ‘c’)
(1, 2, 3, 4, 5)
()
Python访问元组元素
和列表一样,我们可以使用索引(Index)访问元组中的某个元素(得到的是一个元素的值),也可以使用切片访问元组中的一组元素(得到的是一个新的子元组)。
使用索引访问元组元素的格式为:
tuplename[i]
其中,tuplename 表示元组名字,i 表示索引值。元组的索引可以是正数,也可以是负数。
使用切片访问元组元素的格式为:
tuplename[start : end : step]
其中,start 表示起始索引,end 表示结束索引,step 表示步长。
以上两种方式我们已在《Python序列》中进行了讲解,这里就不再赘述了,仅作示例演示,请看下面代码:
url = tuple("http://c.biancheng.net/shell/")
#使用索引访问元组中的某个元素
print(url[3]) #使用正数索引
print(url[-4]) #使用负数索引
#使用切片访问元组中的一组元素
print(url[9: 18]) #使用正数切片
print(url[9: 18: 3]) #指定步长
print(url[-6: -1]) #使用负数切片
运行结果:
p
e
(‘b’, ‘i’, ‘a’, ‘n’, ‘c’, ‘h’, ‘e’, ‘n’, ‘g’)
(‘b’, ‘n’, ‘e’)
(‘s’, ‘h’, ‘e’, ‘l’, ‘l’)
Python修改元组
前面我们已经说过,元组是不可变序列,元组中的元素不能被修改,所以我们只能创建一个新的元组去替代旧的元组。
例如,对元组变量进行重新赋值:
tup = (100, 0.5, -36, 73)
print(tup)
#对元组进行重新赋值
tup = ('Shell脚本',"http://c.biancheng.net/shell/")
print(tup)
运行结果为:
(100, 0.5, -36, 73)
(‘Shell脚本’, ‘http://c.biancheng.net/shell/’)
另外,还可以通过连接多个元组(使用+可以拼接元组)的方式向元组中添加新元素,例如:
tup1 = (100, 0.5, -36, 73)
tup2 = (3+12j, -54.6, 99)
print(tup1+tup2)
print(tup1)
print(tup2)
运行结果为:
(100, 0.5, -36, 73, (3+12j), -54.6, 99)
(100, 0.5, -36, 73)
((3+12j), -54.6, 99)
你看,使用+拼接元组以后,tup1 和 tup2 的内容没法发生改变,这说明生成的是一个新的元组。
Python删除元组
当创建的元组不再使用时,可以通过 del 关键字将其删除,例如:
tup = ('Java教程',"http://c.biancheng.net/java/")
print(tup)
del tup
print(tup)
运行结果为:
(‘Java教程’, ‘http://c.biancheng.net/java/’)
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 4, in
print(tup)
NameError: name ‘tup’ is not defined
Python 自带垃圾回收功能,会自动销毁不用的元组,所以一般不需要通过 del 来手动删除。
Python元组和列表的区别
元组和列表同属序列类型,且都可以按照特定顺序存放一组数据,数据类型不受限制,只要是 Python 支持的数据类型就可以。那么,元组和列表有哪些区别呢?
元组和列表最大的区别就是,列表中的元素可以进行任意修改,就好比是用铅笔在纸上写的字,写错了还可以擦除重写;而元组中的元素无法修改,除非将元组整体替换掉,就好比是用圆珠笔写的字,写了就擦不掉了,除非换一张纸。
可以理解为,tuple 元组是一个只读版本的 list 列表。
需要注意的是,这样的差异势必会影响两者的存储方式,我们来直接看下面的例子:
>>> listdemo = []
>>> listdemo.sizeof()
40
>>> tupleDemo = ()
>>> tupleDemo.sizeof()
24
可以看到,对于列表和元组来说,虽然它们都是空的,但元组却比列表少占用 16 个字节,这是为什么呢?
事实上,就是由于列表是动态的,它需要存储指针来指向对应的元素(占用 8 个字节)。另外,由于列表中元素可变,所以需要额外存储已经分配的长度大小(占用 8 个字节)。但是对于元组,情况就不同了,元组长度大小固定,且存储元素不可变,所以存储空间也是固定的。
读者可能会问题,既然列表这么强大,还要元组这种序列类型干什么?
通过对比列表和元组存储方式的差异,我们可以引申出这样的结论,即元组要比列表更加轻量级,所以从总体上来说,元组的性能速度要优于列表。
另外,Python 会在后台,对静态数据做一些资源缓存。通常来说,因为垃圾回收机制的存在,如果一些变量不被使用了,Python 就会回收它们所占用的内存,返还给操作系统,以便其他变量或其他应用使用。
但是对于一些静态变量(比如元组),如果它不被使用并且占用空间不大时,Python 会暂时缓存这部分内存。这样的话,当下次再创建同样大小的元组时,Python 就可以不用再向操作系统发出请求去寻找内存,而是可以直接分配之前缓存的内存空间,这样就能大大加快程序的运行速度。
下面的例子,是计算初始化一个相同元素的列表和元组分别所需的时间。我们可以看到,元组的初始化速度要比列表快 5 倍。
C:\Users\mengma>python -m timeit ‘x=(1,2,3,4,5,6)’
20000000 loops, best of 5: 9.97 nsec per loop
C:\Users\mengma>python -m timeit ‘x=[1,2,3,4,5,6]’
5000000 loops, best of 5: 50.1 nsec per loop
当然,如果你想要增加、删减或者改变元素,那么列表显然更优。因为对于元组来说,必须得通过新建一个元组来完成。
总的来说,元组确实没有列表那么多功能,但是元组依旧是很重要的序列类型之一,元组的不可替代性体现在以下这些场景中:
- 元组作为很多内置函数和序列类型方法的返回值存在,也就是说,在使用某些函数或者方法时,它的返回值会元组类型,因此你必须对元组进行处理。
- 元组比列表的访问和处理速度更快,因此,当需要对指定元素进行访问,且不涉及修改元素的操作时,建议使用元组。
- 元组可以在映射(和集合的成员)中当做“键”使用,而列表不行。这会在后续章节中作详解介绍。
Python列表和元组的底层实现
有关列表(list)和元组(tuple)的底层实现,本节分别从它们的源码来进行分析。
首先来分析 list 列表,它的具体结构如下所示:
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
有兴趣的读者,可直接阅读 list 列表实现的源码文件 listobject.h 和 listobject.c。
list 本质上是一个长度可变的连续数组。其中 ob_item 是一个指针列表,里边的每一个指针都指向列表中的元素,而 allocated 则用于存储该列表目前已被分配的空间大小。
需要注意的是,allocated 和列表的实际空间大小不同,列表实际空间大小,指的是 len(list) 返回的结果,也就是上边代码中注释中的 ob_size,表示该列表总共存储了多少个元素。而在实际情况中,为了优化存储结构,避免每次增加元素都要重新分配内存,列表预分配的空间 allocated 往往会大于 ob_size。
因此 allocated 和 ob_size 的关系是:allocated >= len(list) = ob_size >= 0。
如果当前列表分配的空间已满(即 allocated == len(list)),则会向系统请求更大的内存空间,并把原来的元素全部拷贝过去。
接下来再分析元组,如下所示为 Python 3.7 tuple 元组的具体结构:
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
有兴趣的读者,可阅读 tuple 元组实现的源码文件 tupleobject.h 和 tupleobject.c。
tuple 和 list 相似,本质也是一个数组,但是空间大小固定。不同于一般数组,Python 的 tuple 做了许多优化,来提升在程序中的效率。
举个例子,为了提高效率,避免频繁的调用系统函数 free 和 malloc 向操作系统申请和释放空间,tuple 源文件中定义了一个 free_list:
static PyTupleObject *free_list[PyTuple_MAXSAVESIZE];
所有申请过的,小于一定大小的元组,在释放的时候会被放进这个 free_list 中以供下次使用。也就是说,如果以后需要再去创建同样的 tuple,Python 就可以直接从缓存中载入。
Python dict字典详解
Python 字典(dict)是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储。相对地,列表(list)和元组(tuple)都是有序的序列,它们的元素在底层是挨着存放的。
字典类型是 Python 中唯一的映射类型。“映射”是数学中的术语,简单理解,它指的是元素之间相互对应的关系,即通过一个元素,可以唯一找到另一个元素。如图 1 所示。
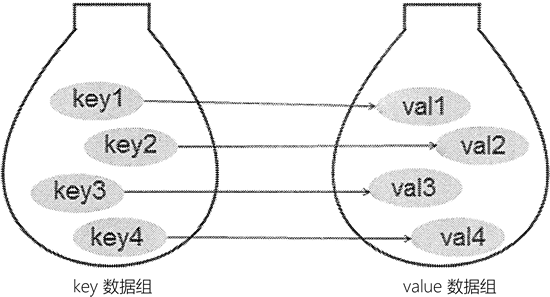
图 1 映射关系示意图
字典中,习惯将各元素对应的索引称为键(key),各个键对应的元素称为值(value),键及其关联的值称为“键值对”。
字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。
总的来说,字典类型所具有的主要特征如表 1 所示。
| 主要特征 | 解释 |
|---|
| 通过键而不是通过索引来读取元素 | 字典类型有时也称为关联数组或者散列表(hash)。它是通过键将一系列的值联系起来的,这样就可以通过键从字典中获取指定项,但不能通过索引来获取。 |
| 字典是任意数据类型的无序集合 | 和列表、元组不同,通常会将索引值 0 对应的元素称为第一个元素,而字典中的元素是无序的。 |
| 字典是可变的,并且可以任意嵌套 | 字典可以在原处增长或者缩短(无需生成一个副本),并且它支持任意深度的嵌套,即字典存储的值也可以是列表或其它的字典。 |
| 字典中的键必须唯一 | 字典中,不支持同一个键出现多次,否则只会保留最后一个键值对。 |
| 字典中的键必须不可变 | 字典中每个键值对的键是不可变的,只能使用数字、字符串或者元组,不能使用列表。 |
Python 中的字典类型相当于 Java 或者 C++ 中的 Map 对象。
和列表、元组一样,字典也有它自己的类型。Python 中,字典的数据类型为 dict,通过 type() 函数即可查看:
>>> a = {‘one’: 1, ‘two’: 2, ‘three’: 3} #a是一个字典类型
>>> type(a)
<class ‘dict’>
Python创建字典
创建字典的方式有很多,下面一一做介绍。
1) 使用 { } 创建字典
由于字典中每个元素都包含两部分,分别是键(key)和值(value),因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
dictname = {‘key’:‘value1’, ‘key2’:‘value2’, …, ‘keyn’:valuen}
其中 dictname 表示字典变量名,keyn : valuen 表示各个元素的键值对。需要注意的是,同一字典中的各个键必须唯一,不能重复。
如下代码示范了使用花括号语法创建字典:
#使用字符串作为key
scores = {'数学': 95, '英语': 92, '语文': 84}
print(scores)
#使用元组和数字作为key
dict1 = {(20, 30): 'great', 30: [1,2,3]}
print(dict1)
#创建空元组
dict2 = {}
print(dict2)
运行结果为:
{‘数学’: 95, ‘英语’: 92, ‘语文’: 84}
{(20, 30): ‘great’, 30: [1, 2, 3]}
{}
可以看到,字典的键可以是整数、字符串或者元组,只要符合唯一和不可变的特性就行;字典的值可以是 Python 支持的任意数据类型。
2) 通过 fromkeys() 方法创建字典
Python 中,还可以使用 dict 字典类型提供的 fromkeys() 方法创建带有默认值的字典,具体格式为:
dictname = dict.fromkeys(list,value=None)
其中,list 参数表示字典中所有键的列表(list);value 参数表示默认值,如果不写,则为空值 None。
请看下面的例子:
knowledge = ['语文', '数学', '英语']
scores = dict.fromkeys(knowledge, 60)
print(scores)
运行结果为:
{‘语文’: 60, ‘英语’: 60, ‘数学’: 60}
可以看到,knowledge 列表中的元素全部作为了 scores 字典的键,而各个键对应的值都是 60。这种创建方式通常用于初始化字典,设置 value 的默认值。
3) 通过 dict() 映射函数创建字典
通过 dict() 函数创建字典的写法有多种,表 2 罗列出了常用的几种方式,它们创建的都是同一个字典 a。
| 创建格式 | 注意事项 |
|---|
| a = dict(str1=value1, str2=value2, str3=value3) | str 表示字符串类型的键,value 表示键对应的值。使用此方式创建字典时,字符串不能带引号。 |
| #方式1 demo = [(‘two’,2), (‘one’,1), (‘three’,3)] #方式2 demo = [[‘two’,2], [‘one’,1], [‘three’,3]] #方式3 demo = ((‘two’,2), (‘one’,1), (‘three’,3)) #方式4 demo = ([‘two’,2], [‘one’,1], [‘three’,3]) a = dict(demo) | 向 dict() 函数传入列表或元组,而它们中的元素又各自是包含 2 个元素的列表或元组,其中第一个元素作为键,第二个元素作为值。 |
| keys = [‘one’, ‘two’, ‘three’] #还可以是字符串或元组 values = [1, 2, 3] #还可以是字符串或元组 a = dict( zip(keys, values) ) | 通过应用 dict() 函数和 zip() 函数,可将前两个列表转换为对应的字典。 |
注意,无论采用以上哪种方式创建字典,字典中各元素的键都只能是字符串、元组或数字,不能是列表。列表是可变的,不能作为键。
如果不为 dict() 函数传入任何参数,则代表创建一个空的字典,例如:
# 创建空的字典
d = dict()
print(d)
运行结果为:
{}
Python 访问字典
列表和元组是通过下标来访问元素的,而字典不同,它通过键来访问对应的值。因为字典中的元素是无序的,每个元素的位置都不固定,所以字典也不能像列表和元组那样,采用切片的方式一次性访问多个元素。
Python 访问字典元素的具体格式为:
dictname[key]
其中,dictname 表示字典变量的名字,key 表示键名。注意,键必须是存在的,否则会抛出异常。
请看下面的例子:
tup = (['two',26], ['one',88], ['three',100], ['four',-59])
dic = dict(tup)
print(dic['one']) #键存在
print(dic['five']) #键不存在
运行结果:
88
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 4, in
print(dic[‘five’]) #键不存在
KeyError: ‘five’
除了上面这种方式外,Python 更推荐使用 dict 类型提供的 get() 方法来获取指定键对应的值。当指定的键不存在时,get() 方法不会抛出异常。
get() 方法的语法格式为:
dictname.get(key[,default])
其中,dictname 表示字典变量的名字;key 表示指定的键;default 用于指定要查询的键不存在时,此方法返回的默认值,如果不手动指定,会返回 None。
get() 使用示例:
a = dict(two=0.65, one=88, three=100, four=-59)
print( a.get('one') )
运行结果:
88
注意,当键不存在时,get() 返回空值 None,如果想明确地提示用户该键不存在,那么可以手动设置 get() 的第二个参数,例如:
a = dict(two=0.65, one=88, three=100, four=-59)
print( a.get('five', '该键不存在') )
运行结果:
该键不存在
Python删除字典
和删除列表、元组一样,手动删除字典也可以使用 del 关键字,例如:
a = dict(two=0.65, one=88, three=100, four=-59)
print(a)
del a
print(a)
运行结果:
{‘two’: 0.65, ‘one’: 88, ‘three’: 100, ‘four’: -59}
Traceback (most recent call last):
File “C:\Users\mozhiyan\Desktop\demo.py”, line 4, in
print(a)
NameError: name ‘a’ is not defined
Python 自带垃圾回收功能,会自动销毁不用的字典,所以一般不需要通过 del 来手动删除。
Python dict字典基本操作(包括添加、修改、删除键值对)
由于字典属于可变序列,所以我们可以任意操作字典中的键值对(key-value)。Python 中,常见的字典操作有以下几种:
- 向现有字典中添加新的键值对。
- 修改现有字典中的键值对。
- 从现有字典中删除指定的键值对。
- 判断现有字典中是否存在指定的键值对。
初学者要牢记,字典是由一个一个的 key-value 构成的,key 是找到数据的关键,Python 对字典的操作都是通过 key 来完成的。
Python字典添加键值对
为字典添加新的键值对很简单,直接给不存在的 key 赋值即可,具体语法格式如下:
dictname[key] = value
对各个部分的说明:
- dictname 表示字典名称。
- key 表示新的键。
- value 表示新的值,只要是 Python 支持的数据类型都可以。
下面代码演示了在现有字典基础上添加新元素的过程:
a = {'数学':95}print(a)#添加新键值对a['语文'] = 89print(a)#再次添加新键值对a['英语'] = 90print(a)
运行结果:
{‘数学’: 95}
{‘数学’: 95, ‘语文’: 89}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
Python字典修改键值对
Python 字典中键(key)的名字不能被修改,我们只能修改值(value)。
字典中各元素的键必须是唯一的,因此,如果新添加元素的键与已存在元素的键相同,那么键所对应的值就会被新的值替换掉,以此达到修改元素值的目的。请看下面的代码:
a = {'数学': 95, '语文': 89, '英语': 90}print(a)a['语文'] = 100print(a)
运行结果:
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
{‘数学’: 95, ‘语文’: 100, ‘英语’: 90}
可以看到,字典中没有再添加一个{'语文':100}键值对,而是对原有键值对{'语文': 89}中的 value 做了修改。
Python字典删除键值对
如果要删除字典中的键值对,还是可以使用 del 语句。例如:
# 使用del语句删除键值对a = {'数学': 95, '语文': 89, '英语': 90}del a['语文']del a['数学']print(a)
运行结果为:
{‘英语’: 90}
判断字典中是否存在指定键值对
如果要判断字典中是否存在指定键值对,首先应判断字典中是否有对应的键。判断字典是否包含指定键值对的键,可以使用 in 或 not in 运算符。
需要指出的是,对于 dict 而言,in 或 not in 运算符都是基于 key 来判断的。
例如如下代码:
a = {'数学': 95, '语文': 89, '英语': 90}
print('数学' in a)
print('物理' in a)
运行结果为:
True
False
通过 in(或 not in)运算符,我们可以很轻易地判断出现有字典中是否包含某个键,如果存在,由于通过键可以很轻易的获取对应的值,因此很容易就能判断出字典中是否有指定的键值对。
Python dict字典方法完全攻略(全)
我们知道,Python 字典的数据类型为 dict,我们可使用 dir(dict) 来查看该类型包含哪些方法,例如:
>>> dir(dict)
[‘clear’, ‘copy’, ‘fromkeys’, ‘get’, ‘items’, ‘keys’, ‘pop’, ‘popitem’, ‘setdefault’, ‘update’, ‘values’]
这些方法中,fromkeys() 和 get() 的用法已在《Python字典》中进行了介绍,这里不再赘述,本节只给大家介绍剩下的方法。
keys()、values() 和 items() 方法
将这三个方法放在一起介绍,是因为它们都用来获取字典中的特定数据:
- keys() 方法用于返回字典中的所有键(key);
- values() 方法用于返回字典中所有键对应的值(value);
- items() 用于返回字典中所有的键值对(key-value)。
请看下面的例子:
scores = {'数学': 95, '语文': 89, '英语': 90}
print(scores.keys())
print(scores.values())
print(scores.items())
运行结果:
dict_keys([‘数学’, ‘语文’, ‘英语’])
dict_values([95, 89, 90])
dict_items([(‘数学’, 95), (‘语文’, 89), (‘英语’, 90)])
可以发现,keys()、values() 和 items() 返回值的类型分别为 dict_keys、dict_values 和 dict_items。
需要注意的是,在 Python 2.x 中,上面三个方法的返回值都是列表(list)类型。但在 Python 3.x 中,它们的返回值并不是我们常见的列表或者元组类型,因为 Python 3.x 不希望用户直接操作这几个方法的返回值。
在 Python 3.x 中如果想使用这三个方法返回的数据,一般有下面两种方案:
- 使用 list() 函数,将它们返回的数据转换成列表,例如:
a = {'数学': 95, '语文': 89, '英语': 90}
b = list(a.keys())
print(b)
运行结果为:
[‘数学’, ‘语文’, ‘英语’]
- 使用 for in 循环遍历它们的返回值,例如:
a = {'数学': 95, '语文': 89, '英语': 90}
for k in a.keys():
print(k,end=' ')
print("\n---------------")
for v in a.values():
print(v,end=' ')
print("\n---------------")
for k,v in a.items():
print("key:",k," value:",v)
运行结果为:
数学 语文 英语
---------------
95 89 90
---------------
key: 数学 value: 95
key: 语文 value: 89
key: 英语 value: 90
copy() 方法
copy() 方法返回一个字典的拷贝,也即返回一个具有相同键值对的新字典,例如:
a = {'one': 1, 'two': 2, 'three': [1,2,3]}
b = a.copy()
print(b)
运行结果为:
{‘one’: 1, ‘two’: 2, ‘three’: [1, 2, 3]}
可以看到,copy() 方法将字典 a 的数据全部拷贝给了字典 b。
注意,copy() 方法所遵循的拷贝原理,既有深拷贝,也有浅拷贝。拿拷贝字典 a 为例,copy() 方法只会对最表层的键值对进行深拷贝,也就是说,它会再申请一块内存用来存放 {‘one’: 1, ‘two’: 2, ‘three’: []};而对于某些列表类型的值来说,此方法对其做的是浅拷贝,也就是说,b 中的 [1,2,3] 的值不是自己独有,而是和 a 共有。
请看下面的例子:
a = {'one': 1, 'two': 2, 'three': [1,2,3]}
b = a.copy()
#向 a 中添加新键值对,由于b已经提前将 a 所有键值对都深拷贝过来,因此 a 添加新键值对,不会影响 b。
a['four']=100
print(a)
print(b)
#由于 b 和 a 共享[1,2,3](浅拷贝),因此移除 a 中列表中的元素,也会影响 b。
a['three'].remove(1)
print(a)
print(b)
运行结果为:
{‘one’: 1, ‘two’: 2, ‘three’: [1, 2, 3], ‘four’: 100}
{‘one’: 1, ‘two’: 2, ‘three’: [1, 2, 3]}
{‘one’: 1, ‘two’: 2, ‘three’: [2, 3], ‘four’: 100}
{‘one’: 1, ‘two’: 2, ‘three’: [2, 3]}
从运行结果不难看出,对 a 增加新键值对,b 不变;而修改 a 某键值对中列表内的元素,b也会相应改变。
update() 方法
update() 方法可以使用一个字典所包含的键值对来更新己有的字典。
在执行 update() 方法时,如果被更新的字典中己包含对应的键值对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。
请看下面的代码:
a = {'one': 1, 'two': 2, 'three': 3}
a.update({'one':4.5, 'four': 9.3})
print(a)
运行结果为:
{‘one’: 4.5, ‘two’: 2, ‘three’: 3, ‘four’: 9.3}
从运行结果可以看出,由于被更新的字典中已包含 key 为“one”的键值对,因此更新时该键值对的 value 将被改写;而被更新的字典中不包含 key 为“four”的键值对,所以更新时会为原字典增加一个新的键值对。
pop() 和 popitem() 方法
pop() 和 popitem() 都用来删除字典中的键值对,不同的是,pop() 用来删除指定的键值对,而 popitem() 用来随机删除一个键值对,它们的语法格式如下:
dictname.pop(key)
dictname.popitem()
其中,dictname 表示字典名称,key 表示键。
下面的代码演示了两个函数的用法:
a = {'数学': 95, '语文': 89, '英语': 90, '化学': 83, '生物': 98, '物理': 89}
print(a)
a.pop('化学')
print(a)
a.popitem()
print(a)
运行结果:
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘化学’: 83, ‘生物’: 98, ‘物理’: 89}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘生物’: 98, ‘物理’: 89}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘生物’: 98}
对 popitem() 的说明
其实,说 popitem() 随机删除字典中的一个键值对是不准确的,虽然字典是一种无须的列表,但键值对在底层也是有存储顺序的,popitem() 总是弹出底层中的最后一个 key-value,这和列表的 pop() 方法类似,都实现了数据结构中“出栈”的操作。
setdefault() 方法
setdefault() 方法用来返回某个 key 对应的 value,其语法格式如下:
dictname.setdefault(key, defaultvalue)
说明,dictname 表示字典名称,key 表示键,defaultvalue 表示默认值(可以不写,不写的话是 None)。
当指定的 key 不存在时,setdefault() 会先为这个不存在的 key 设置一个默认的 defaultvalue,然后再返回 defaultvalue。
也就是说,setdefault() 方法总能返回指定 key 对应的 value:
- 如果该 key 存在,那么直接返回该 key 对应的 value;
- 如果该 key 不存在,那么先为该 key 设置默认的 defaultvalue,然后再返回该 key 对应的 defaultvalue。
请看下面的代码:
a = {'数学': 95, '语文': 89, '英语': 90}
print(a)
#key不存在,指定默认值
a.setdefault('物理', 94)
print(a)
#key不存在,不指定默认值
a.setdefault('化学')
print(a)
#key存在,指定默认值
a.setdefault('数学', 100)
print(a)
运行结果为:
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘物理’: 94}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘物理’: 94, ‘化学’: None}
{‘数学’: 95, ‘语文’: 89, ‘英语’: 90, ‘物理’: 94, ‘化学’: None}
Python set集合详解
Python 中的集合,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。
从形式上看,和字典类似,Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
{element1,element2,…,elementn}
其中,elementn 表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则 Python 解释器会抛出 TypeError 错误。比如说:
>>> {{‘a’:1}}
Traceback (most recent call last):
File “<pyshell#8>”, line 1, in
{{‘a’:1}}
TypeError: unhashable type: ‘dict’
>>> {[1,2,3]}
Traceback (most recent call last):
File “<pyshell#9>”, line 1, in
{[1,2,3]}
TypeError: unhashable type: ‘list’
>>> {{1,2,3}}
Traceback (most recent call last):
File “<pyshell#10>”, line 1, in
{{1,2,3}}
TypeError: unhashable type: ‘set’
并且需要注意的是,数据必须保证是唯一的,因为集合对于每种数据元素,只会保留一份。例如:
>>> {1,2,1,(1,2,3),‘c’,‘c’}
{1, 2, ‘c’, (1, 2, 3)}
由于 Python 中的 set 集合是无序的,所以每次输出时元素的排序顺序可能都不相同。
其实,Python 中有两种集合类型,一种是 set 类型的集合,另一种是 frozenset 类型的集合,它们唯一的区别是,set 类型集合可以做添加、删除元素的操作,而 forzenset 类型集合不行。本节先介绍 set 类型集合,后续章节再介绍 forzenset 类型集合。
Python创建set集合
Python 提供了 2 种创建 set 集合的方法,分别是使用 {} 创建和使用 set() 函数将列表、元组等类型数据转换为集合。
1) 使用 {} 创建
在 Python 中,创建 set 集合可以像列表、元素和字典一样,直接将集合赋值给变量,从而实现创建集合的目的,其语法格式如下:
setname = {element1,element2,…,elementn}
其中,setname 表示集合的名称,起名时既要符合 Python 命名规范,也要避免与 Python 内置函数重名。
举个例子:
a = {1,'c',1,(1,2,3),'c'}
print(a)
运行结果为:
{1, ‘c’, (1, 2, 3)}
2) set()函数创建集合
set() 函数为 Python 的内置函数,其功能是将字符串、列表、元组、range 对象等可迭代对象转换成集合。该函数的语法格式如下:
setname = set(iteration)
其中,iteration 就表示字符串、列表、元组、range 对象等数据。
例如:
set1 = set("c.biancheng.net")
set2 = set([1,2,3,4,5])
set3 = set((1,2,3,4,5))
print("set1:",set1)
print("set2:",set2)
print("set3:",set3)
运行结果为:
set1: {‘a’, ‘g’, ‘b’, ‘c’, ‘n’, ‘h’, ‘.’, ‘t’, ‘i’, ‘e’}
set2: {1, 2, 3, 4, 5}
set3: {1, 2, 3, 4, 5}
注意,如果要创建空集合,只能使用 set() 函数实现。因为直接使用一对 {},Python 解释器会将其视为一个空字典。
Python访问set集合元素
由于集合中的元素是无序的,因此无法向列表那样使用下标访问元素。Python 中,访问集合元素最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
例如:
a = {1,'c',1,(1,2,3),'c'}
for ele in a:
print(ele,end=' ')
运行结果为:
1 c (1, 2, 3)
由于目前尚未学习循环结构,以上代码初学者只需初步了解,后续学习循环结构后自然会明白。
Python删除set集合
和其他序列类型一样,手动函数集合类型,也可以使用 del() 语句,例如:
a = {1,'c',1,(1,2,3),'c'}
print(a)
del(a)
print(a)
运行结果为:
{1, ‘c’, (1, 2, 3)}
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\1.py”, line 4, in
print(a)
NameError: name ‘a’ is not defined
Python set 集合最常用的操作是向集合中添加、删除元素,以及集合之间做交集、并集、差集等运算。受到篇幅的限制,这些知识会放到下节进行详细讲解。
Python set集合基本操作(添加、删除、交集、并集、差集)
Python set 集合最常用的操作是向集合中添加、删除元素,以及集合之间做交集、并集、差集等运算,本节将一一讲解这些操作的具体实现。
向 set 集合中添加元素
set 集合中添加元素,可以使用 set 类型提供的 add() 方法实现,该方法的语法格式为:
setname.add(element)
其中,setname 表示要添加元素的集合,element 表示要添加的元素内容。
需要注意的是,使用 add() 方法添加的元素,只能是数字、字符串、元组或者布尔类型(True 和 False)值,不能添加列表、字典、集合这类可变的数据,否则 Python 解释器会报 TypeError 错误。例如:
a = {1,2,3}
a.add((1,2))
print(a)
a.add([1,2])
print(a)
运行结果为:
{(1, 2), 1, 2, 3}
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\1.py”, line 4, in
a.add([1,2])
TypeError: unhashable type: ‘list’
从set集合中删除元素
删除现有 set 集合中的指定元素,可以使用 remove() 方法,该方法的语法格式如下:
setname.remove(element)
使用此方法删除集合中元素,需要注意的是,如果被删除元素本就不包含在集合中,则此方法会抛出 KeyError 错误,例如:
a = {1,2,3}
a.remove(1)
print(a)
a.remove(1)
print(a)
运行结果为:
{2, 3}
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\1.py”, line 4, in
a.remove(1)
KeyError: 1
上面程序中,由于集合中的元素 1 已被删除,因此当再次尝试使用 remove() 方法删除时,会引发 KeyError 错误。
如果我们不想在删除失败时令解释器提示 KeyError 错误,还可以使用 discard() 方法,此方法和 remove() 方法的用法完全相同,唯一的区别就是,当删除集合中元素失败时,此方法不会抛出任何错误。
例如:
a = {1,2,3}
a.remove(1)
print(a)
a.discard(1)
print(a)
运行结果为:
{2, 3}
{2, 3}
Python set集合做交集、并集、差集运算
集合最常做的操作就是进行交集、并集、差集以及对称差集运算,首先有必要给大家普及一下各个运算的含义。
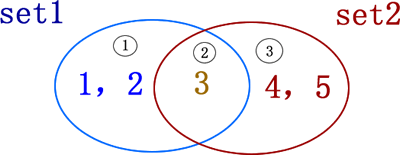
图 1 集合示意图
图 1 中,有 2 个集合,分别为 set1={1,2,3} 和 set2={3,4,5},它们既有相同的元素,也有不同的元素。以这两个集合为例,分别做不同运算的结果如表 1 所示。
| 运算操作 | Python运算符 | 含义 | 例子 |
|---|
| 交集 | & | 取两集合公共的元素 | >>> set1 & set2 {3} |
| 并集 | | | 取两集合全部的元素 | >>> set1 | set2 {1,2,3,4,5} |
| 差集 | - | 取一个集合中另一集合没有的元素 | >>> set1 - set2 {1,2} >>> set2 - set1 {4,5} |
| 对称差集 | ^ | 取集合 A 和 B 中不属于 A&B 的元素 | >>> set1 ^ set2 {1,2,4,5} |
Python set集合方法详解(全)
前面学习了 set 集合,本节来一一学习 set 类型提供的方法。首先,通过 dir(set) 命令可以查看它有哪些方法:
>>> dir(set)
[‘add’, ‘clear’, ‘copy’, ‘difference’, ‘difference_update’, ‘discard’, ‘intersection’, ‘intersection_update’, ‘isdisjoint’, ‘issubset’, ‘issuperset’, ‘pop’, ‘remove’, ‘symmetric_difference’, ‘symmetric_difference_update’, ‘union’, ‘update’]
各个方法的具体语法结构及功能如表 1 所示。
| 方法名 | 语法格式 | 功能 | 实例 |
|---|
| add() | set1.add() | 向 set1 集合中添加数字、字符串、元组或者布尔类型 | >>> set1 = {1,2,3} >>> set1.add((1,2)) >>> set1 {(1, 2), 1, 2, 3} |
| clear() | set1.clear() | 清空 set1 集合中所有元素 | >>> set1 = {1,2,3} >>> set1.clear() >>> set1 set() set()才表示空集合,{}表示的是空字典 |
| copy() | set2 = set1.copy() | 拷贝 set1 集合给 set2 | >>> set1 = {1,2,3} >>> set2 = set1.copy() >>> set1.add(4) >>> set1 {1, 2, 3, 4} >>> set1 {1, 2, 3} |
| difference() | set3 = set1.difference(set2) | 将 set1 中有而 set2 没有的元素给 set3 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set3 = set1.difference(set2) >>> set3 {1, 2} |
| difference_update() | set1.difference_update(set2) | 从 set1 中删除与 set2 相同的元素 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set1.difference_update(set2) >>> set1 {1, 2} |
| discard() | set1.discard(elem) | 删除 set1 中的 elem 元素 | >>> set1 = {1,2,3} >>> set1.discard(2) >>> set1 {1, 3} >>> set1.discard(4) {1, 3} |
| intersection() | set3 = set1.intersection(set2) | 取 set1 和 set2 的交集给 set3 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set3 = set1.intersection(set2) >>> set3 {3} |
| intersection_update() | set1.intersection_update(set2) | 取 set1和 set2 的交集,并更新给 set1 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set1.intersection_update(set2) >>> set1 {3} |
| isdisjoint() | set1.isdisjoint(set2) | 判断 set1 和 set2 是否没有交集,有交集返回 False;没有交集返回 True | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set1.isdisjoint(set2) False |
| issubset() | set1.issubset(set2) | 判断 set1 是否是 set2 的子集 | >>> set1 = {1,2,3} >>> set2 = {1,2} >>> set1.issubset(set2) False |
| issuperset() | set1.issuperset(set2) | 判断 set2 是否是 set1 的子集 | >>> set1 = {1,2,3} >>> set2 = {1,2} >>> set1.issuperset(set2) True |
| pop() | a = set1.pop() | 取 set1 中一个元素,并赋值给 a | >>> set1 = {1,2,3} >>> a = set1.pop() >>> set1 {2,3} >>> a 1 |
| remove() | set1.remove(elem) | 移除 set1 中的 elem 元素 | >>> set1 = {1,2,3} >>> set1.remove(2) >>> set1 {1, 3} >>> set1.remove(4) Traceback (most recent call last): File “<pyshell#90>”, line 1, in set1.remove(4) KeyError: 4 |
| symmetric_difference() | set3 = set1.symmetric_difference(set2) | 取 set1 和 set2 中互不相同的元素,给 set3 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set3 = set1.symmetric_difference(set2) >>> set3 {1, 2, 4} |
| symmetric_difference_update() | set1.symmetric_difference_update(set2) | 取 set1 和 set2 中互不相同的元素,并更新给 set1 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set1.symmetric_difference_update(set2) >>> set1 {1, 2, 4} |
| union() | set3 = set1.union(set2) | 取 set1 和 set2 的并集,赋给 set3 | >>> set1 = {1,2,3} >>> set2 = {3,4} >>> set3=set1.union(set2) >>> set3 {1, 2, 3, 4} |
| update() | set1.update(elem) | 添加列表或集合中的元素到 set1 | >>> set1 = {1,2,3} >>> set1.update([3,4]) >>> set1 {1,2,3,4} |
深入底层了解Python字典和集合,一眼看穿他们的本质!
字典和集合是进行过性能高度优化的数据结构,特别是对于查找、添加和删除操作。本节将结合实例介绍它们在具体场景下的性能表现,以及与列表等其他数据结构的对比。
例如,有一个存储产品信息(产品 ID、名称和价格)的列表,现在的需求是,借助某件产品的ID找出其价格。则实现代码如下:
def find_product_price(products, product_id):
for id, price in products:
if id == product_id:
return price
return None
products = [
(111, 100),
(222, 30),
(333, 150)
]
print('The price of product 222 is {}'.format(find_product_price(products, 222)))
运行结果为:
The price of product 222 is 30
在上面程序的基础上,如果列表有 n 个元素,因为查找的过程需要遍历列表,那么最坏情况下的时间复杂度就为 O(n)。即使先对列表进行排序,再使用二分查找算法,也需要 O(logn) 的时间复杂度,更何况列表的排序还需要 O(nlogn) 的时间。
但如果用字典来存储这些数据,那么查找就会非常便捷高效,只需 O(1) 的时间复杂度就可以完成,因为可以直接通过键的哈希值,找到其对应的值,而不需要对字典做遍历操作,实现代码如下:
products = {
111: 100,
222: 30,
333: 150
}
print('The price of product 222 is {}'.format(products[222]))
运行结果为:
The price of product 222 is 30
有些读者可能对时间复杂度并没有直观的认识,没关系,再给大家列举一个实例。下面的代码中,初始化了含有 100,000 个元素的产品,并分别计算出了使用列表和集合来统计产品价格数量的运行时间:
#统计时间需要用到 time 模块中的函数,了解即可
import time
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: #B
unique_price_list.append(price)
return len(unique_price_list)
id = [x for x in range(0, 100000)]
price = [x for x in range(200000, 300000)]
products = list(zip(id, price))
# 计算列表版本的时间
start_using_list = time.perf_counter()
find_unique_price_using_list(products)
end_using_list = time.perf_counter()
print("time elapse using list: {}".format(end_using_list - start_using_list))
#使用集合完成同样的工作
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
# 计算集合版本的时间
start_using_set = time.perf_counter()
find_unique_price_using_set(products)
end_using_set = time.perf_counter()
print("time elapse using set: {}".format(end_using_set - start_using_set))
运行结果为:
time elapse using list: 68.78650900000001
time elapse using set: 0.010747099999989018
可以看到,仅仅十万的数据量,两者的速度差异就如此之大。而往往企业的后台数据都有上亿乃至十亿数量级,因此如果使用了不合适的数据结构,很容易造成服务器的崩溃,不但影响用户体验,并且会给公司带来巨大的财产损失。
那么,字典和集合为什么能如此高效,特别是查找、插入和删除操作呢?
字典和集合的工作原理
字典和集合能如此高效,和它们内部的数据结构密不可分。不同于其他数据结构,字典和集合的内部结构都是一张哈希表:
- 对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素。
- 而对集合来说,哈希表内只存储单一的元素。
对于之前版本的 Python 来说,它的哈希表结构如下所示:
| 哈希值 (hash) 键 (key) 值 (value)
. | ...
0 | hash0 key0 value0
. | ...
1 | hash1 key1 value1
. | ...
2 | hash2 key2 value2
. | ...
这种结构的弊端是,随着哈希表的扩张,它会变得越来越稀疏。比如,有这样一个字典:
{‘name’: ‘mike’, ‘dob’: ‘1999-01-01’, ‘gender’: ‘male’}
那么它会存储为类似下面的形式:
entries = [
['--', '--', '--']
[-230273521, 'dob', '1999-01-01'],
['--', '--', '--'],
['--', '--', '--'],
[1231236123, 'name', 'mike'],
['--', '--', '--'],
[9371539127, 'gender', 'male']
]
显然,这样非常浪费存储空间。为了提高存储空间的利用率,现在的哈希表除了字典本身的结构,会把索引和哈希值、键、值单独分开,也就是采用如下这种结构:
Indices
----------------------------------------------------
None | index | None | None | index | None | index ...
----------------------------------------------------
Entries
--------------------
hash0 key0 value0
---------------------
hash1 key1 value1
---------------------
hash2 key2 value2
---------------------
...
---------------------
在此基础上,上面的字典在新哈希表结构下的存储形式为:
indices = [None, 1, None, None, 0, None, 2]
entries = [
[1231236123, 'name', 'mike'],
[-230273521, 'dob', '1999-01-01'],
[9371539127, 'gender', 'male']
]
通过对比可以发现,空间利用率得到很大的提高。
清楚了具体的设计结构,接下来再分析一下如何使用哈希表完成对数据的插入、查找和删除操作。
哈希表插入数据
当向字典中插入数据时,Python 会首先根据键(key)计算出对应的哈希值(通过 hash(key) 函数),而向集合中插入数据时,Python会根据该元素本身计算对应的哈希值(通过 hash(valuse) 函数)。
例如:
dic = {"name":1}
print(hash("name"))
setDemo = {1}
print(hash(1))
运行结果为:
8230115042008314683
1
得到哈希值(例如为 hash)之后,再结合字典或集合要存储数据的个数(例如 n),就可以得到该元素应该插入到哈希表中的位置(比如,可以用 hash%n 的方式)。
如果哈希表中此位置是空的,那么此元素就可以直接插入其中;反之,如果此位置已被其他元素占用,那么 Python 会比较这两个元素的哈希值和键是否相等:
- 如果相等,则表明该元素已经存在,再比较他们的值,不相等就进行更新;
- 如果不相等,这种情况称为哈希冲突(即两个元素的键不同,但求得的哈希值相同)。这种情况下,Python 会使用开放定址法、再哈希法等继续寻找哈希表中空余的位置,直到找到位置。
具体遇到哈希冲突时,各解决方法的具体含义可阅读《哈希表详解》一节做详细了解。
哈希表查找数据
在哈希表中查找数据,和插入操作类似,Python 会根据哈希值,找到该元素应该存储到哈希表中的位置,然后和该位置的元素比较其哈希值和键(集合直接比较元素值):
- 如果相等,则证明找到;
- 反之,则证明当初存储该元素时,遇到了哈希冲突,需要继续使用当初解决哈希冲突的方法进行查找,直到找到该元素或者找到空位为止。
这里的找到空位,表示哈希表中没有存储目标元素。
哈希表删除元素
对于删除操作,Python 会暂时对这个位置的元素赋于一个特殊的值,等到重新调整哈希表的大小时,再将其删除。
需要注意的是,哈希冲突的发生往往会降低字典和集合操作的速度。因此,为了保证其高效性,字典和集合内的哈希表,通常会保证其至少留有 1/3 的剩余空间。随着元素的不停插入,当剩余空间小于 1/3 时,Python 会重新获取更大的内存空间,扩充哈希表,与此同时,表内所有的元素位置都会被重新排放。
虽然哈希冲突和哈希表大小的调整,都会导致速度减缓,但是这种情况发生的次数极少。所以,平均情况下,仍能保证插入、查找和删除的时间复杂度为 O(1)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)